
作者 | 温芳 360 系统部数据开发高级工程师
一年前,360 系统部开始研究云舟项目——打破传统存算一体结构、保持近实时的弹性,云原生计算存储分离类似 Snowflake 的 DaaS 数仓平台,并支撑公司日益增多的机器学习任务 。
我们遇到的第一个挑战就是线下存储如何与云上的计算资源适配,数据依然存储到云下的 PoleFS 存储中,无法对接云上的 Serverless 弹性容器实例。我们倾向于使用 serverless 容器,因为它简单易用、极致弹性、最优成本、按需付费;但同时 Serverless 容器平台是黑盒系统,只支持公有云存储(NAS,对象存储)无法访问我们的线下数据。
第二个挑战是成本和性能的问题。即使退一步放弃云上的 Serverless 容器实例,改成使用云服务器访问(增加运维复杂度)绕过数据访问的问题,但是专线成本、GPU 利用率不高和训练速度慢,依然是无法绕过的问题。
这时,我们的目光投入到了 CNCF 旗下 Fluid 开源项目上,一款兼容 Kubernetes 的分布式数据集编排和加速引擎。经过很多调研,我们发现 Fluid 非常适用于处理如机器学习等数据密集型任务:Fluid 通过管理和调度 Runtime 实现数据集的可见性、弹性伸缩、数据迁移。同时,Fluid 还可以解决云端存储适配问题、降低专线成本,同时提高 GPU 的利用率。更难能可贵的是,Fluid 支持开源的 AlluxioRuntime 也满足了可以使用我司内部定制版 Alluxio 的要求。
因此,我们决定将 Fluid 作为云舟的数据编排层和数据管理层。接下来,本文将重点介绍我们是如何通过 Fluid 优化混合云场景下的机器学习任务数据访问。
机器学习上云痛点
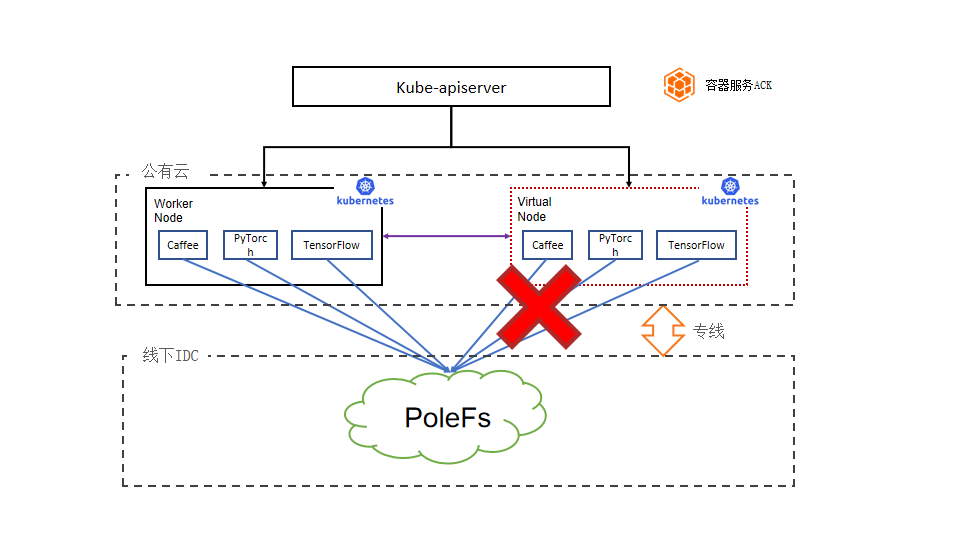
PoleFs 是 360 自研的存储解决方案,但是直接从云上计算直接访问 PoleFS 中存在多种问题,包括与云端 Serverless 容器实例的兼容性问题,由于混合云存储架构中的高数据访问延迟导致的 GPU 资源浪费,较高的专线成本,以及单点存储链路问题。
第一,访问无法适配:PoleFs 作为 360 的自研存储,无法对接云上的 Serverless 容器实例。比如阿里云的 ECI 只支持自身存储(OSS,CPFS,NAS),但无法与 PoleFs 对接。这样需要访问 PoleFs 的计算任务就无法利用到阿里云的 Serverless 容器按需弹性伸缩,免运维等能力。
第二,GPU 资源浪费:即使退一步放弃云上的 Serverless 容器实例(ECI),改成使用云服务器访问,可以绕过数据访问的问题。现有混合云场景存储分离架构导致数据访问延时高。机器学习训练的过程中不断的从 PoleFS 拉取数据,造成网络宽带高、IO 成为了瓶颈,大大降低了 GPU 的利用率,导致使用云上资源成本反而更高。
第三,专线昂贵:Kubernetes 缺乏感知数据缓存的能力。对于多次访问的数据集,性能上并没有提升,一次次的拉取数据带来额外的网络专线开销。
第四,存储单点:PoleFs 成为数据并发访问的瓶颈点。(PoleFS 是我们部门自研的分布式文件系统)。云上和云下大量的机器学习训练造成的 IO 压力比较大, 访问 PoleFs 链路成为了单点链路,一旦 PoleFS 带宽出现瓶颈或者 PloeFS 不响应则会影响所有机器学习任务。
选择 Fluid 的原因
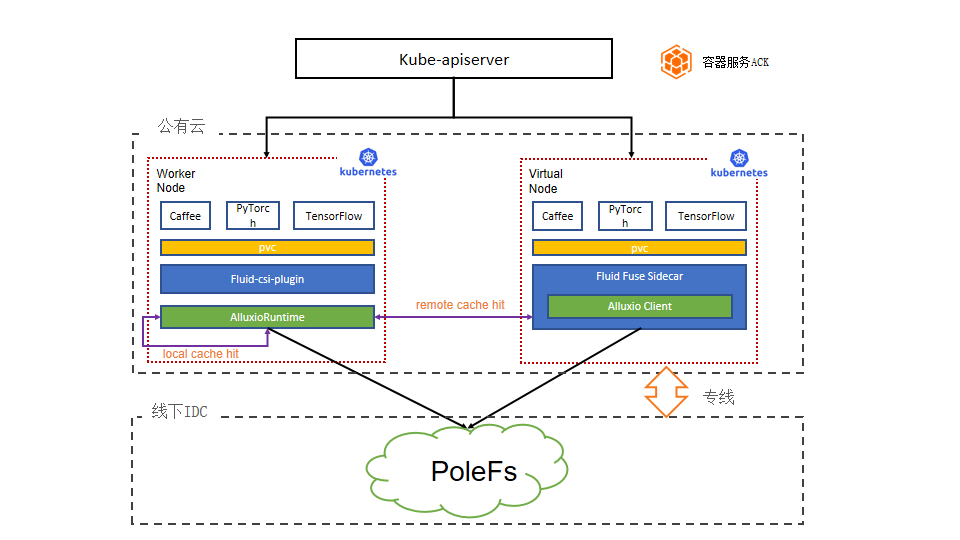
我们使用 Fluid 对优化云上计算资源访问 PoleFS,Fluid 的引入为整个项目带来了很多的优势:
应用无侵入,存储无修改实现数据接入:通过引入 Fluid,业务方无需修改应用,使用简单;对下存储团队无需修改 PoleFS 就可以实现云上计算对接 PoleFS。
数据本地性调度作业,加入 Fluid 作为缓存之后,机器学习任务只需要访问 pvc 去进行数据训练,Fluid 根据数据对任务进行调度,尽可能达到了数据本地读,减少了 IO 压力和网络压力。
数据预加载功能。fluid 具有数据预加载能力,可以在任务训练之前将所需要的数据拉取到缓存中,这样大大加快了训练速度,提高了 GPU 的利用率。
数据复用。多个任务可以共享数据缓存,避免了同一份数据拉取多次带来的网络消耗。
如何落地实践
安装部署
在阿里云上可以直接通过安装云原生 AI 套件完成 Fluid 的安装,如果在自己的数据中心使用,也可以按照如下安装方式:
1. 首先,需要创建 namespace,fluid-system;
kubectl create ns fluid-system2. 然后,从 Fluid 官网 [https://fluid-cloudnative.github.io/] 下载 Fluid 最新版本;
3. 下载完后,就可以通过 helm 进行安装;
helm install fluid fluid-<version>.tgz4. 然后,可以检验一下安装是否成功
kubectl get po -n fluid-system使用方法
首先,创建一个 pvc polefs,底层挂载存储的是 PoleFS。
¥kubectl get pvNAME CAPACITY ACCESS MODES RECLAIM POLICY STORAGECLASS STATUSpolefs 30000Gi RWX Retain polefs-storageclass Bound然后,创建 dataset,通过 mountPoint 指向 polefs-acc pvc, 此处为了满足业务要求,我们直接挂载到了根目录。由于 Fluid 支持 PVC 协议,我们可以很容易的实现 PoleFS 和云的对接。
apiVersion: data.fluid.io/v1alpha1kind: Datasetmetadata: name: polefs-accspec: mounts: - mountPoint: pvc://polefs name: / accessModes: - ReadWriteMany之后,创建 AlluxioRuntime,我们测试了 Alluxio 使用 SSD 和内存时性能对比,发现差别不大,所以我们最终选用了 SSD 做 alluxio 的缓存介质。
apiVersion: data.fluid.io/v1alpha1kind: AlluxioRuntimemetadata: name: polefs-accspec: replicas: 3 data: replicas: 1 master: jvmOptions: - -Xms20G - -Xmx20G - -XX:+UseG1GC tieredstore: levels: - mediumtype: SSD path: /ssd quota: 50Gi high: "0.99"Fluid 在拉起 alluxio 之后,会创建一个 pvc:
kubectl get pv,pvc -n wzNAME CAPACITY ACCESS MODES RECLAIM POLICY STATUSpersistentvolume/wz-polefs-acc 100Gi RWX Retain Bound NAME STATUS VOLUME CAPACITY ACCESS MODES persistentvolumeclaim/polefs-acc Bound wz-polefs-acc 100Gi RWX当看到 pvc 状态为 Bound 时,就可以直接使用了。我们的机器学习伙伴可以使用 pvc polefs-acc 访问到自己的数据。
之后,为了提升机器学习任务训练的速度,我们会先对数据进行预加载。
接下来,创建 dataload 对数据进行预加载。
apiVersion: data.fluid.io/v1alpha1kind: DataLoadmetadata: name: polefs-accspec: dataset: name: polefs-acc namespace: wz target: - path: /data/test/images数据预加载完成后,就可以方便的使用云上 ECS 和 ECI 资源,灵活的进行机器学习任务训练啦。
遇到的问题
我们司内对 alluxio 进行了定制改造,在刚刚引入 fluid 时,我们发现通过 helm 安装时,fluid 还没有支持设置自己版本的 alluxio 镜像,我们及时将我们的需求反馈给社区,社区很给力,很快就帮我们实现了这个功能。
由于我们的平台会有新的业务接入,我们的一个 fluid+alluxio 集群会跑很多业务的作业。刚开始 fluid 只支持静态挂载 dataset,一旦集群启动好就无法挂载别的路径,这样势必会影响我们新业务、新集群的接入,因此我们开发了自动挂载的功能,并提交给了 Fluid 社区。
为了平滑迁移用户作业,我们想在不改动用户作业的情况下将机器学习作业迁移到 Kubernetes 上,这时由于我们的 pole-fs 已经挂载了一层目录,导致我们再用 alluxio 挂载时会多一层目录。后来,我们通过在 dataset 设置挂载点根路径特性实现了将 pole-fs 的 pvc 挂载到了 alluxio 的根上,这样解决了我们平滑迁移的问题。
实践结果:30% 的性能提升
我们对直接 IDC 服务器访问 PoleFS 训练和加入 Fluid 作为缓存在云上训练进行了性能对比测试,该训练场景的小文件偏多、有近百万张图片。下面是性能对比图:
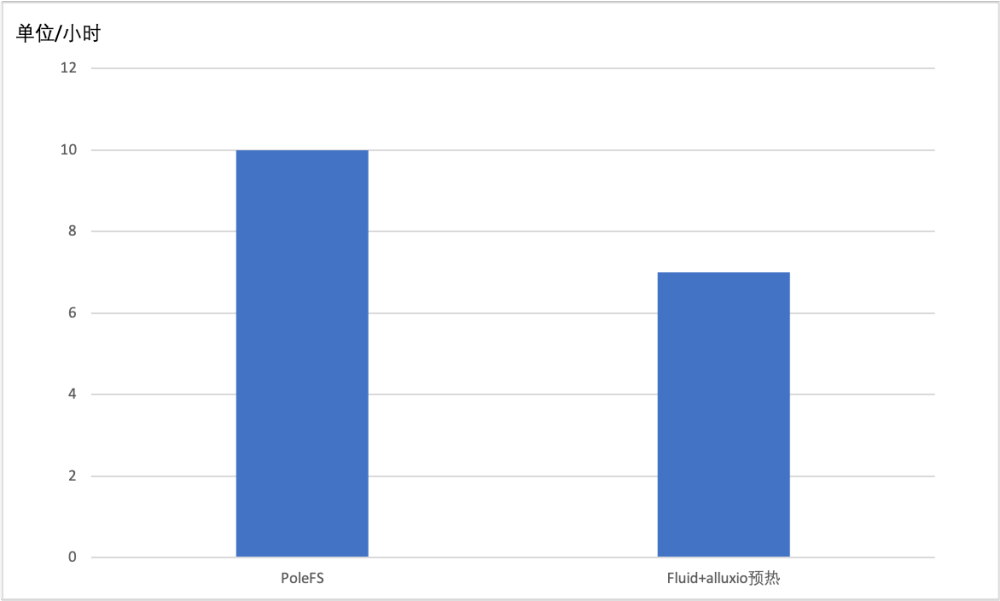
测试得出,加入 Fluid+360 优化过的 alluxio 对数据进行预热,在云上运行机器学习任务即使和在自建数据中心通过 PoleFS 直接运行机器学习任务相比,在执行效率上还有大约 30% 的提升,同时也提高了 GPU 的利用率,也减少了专线的费用开销。
通过使用 Fluid,我们可以简单安心地使用云上计算资源构建混合云平台下的机器学习平台。
哪些经验可以分享
根据实践,我们总结了以下五个方面的经验供大家参考。
选择合适的缓存节点: 使用 AlluxioRuntime 通过缓存获得更好的数据访问性能,在实际生产中我们发现并非所有节点都来做缓存性能就比较好。原因最开始云上缓存选择了不同 ECS 类型,而有些 ECS 的磁盘和网络 IO 性能不是很好,这个时候需要我们能够把缓存节点调度到同种类型的 ECS 上。Fluid 支持 dataset 的可调度性,也就是说,可以通过指定 dataset 的 nodeAffinity 来进行数据集缓存节点的调度,从而保证缓存节点可高效的提供缓存服务。
指定 Master 调度策略:alluxio 是典型的主从架构,master 作为集群的大脑,负责服务所有用户请求并管理元数据,master 的稳定性至关重要,而宿主机的磁盘、内存、网络是影响 master 稳定性的一个重要因素,因此我们通过配置 master 的 nodeselector 选择比较好的宿主机部署 master,以进一步保证 master 的稳定性。
定时数据预热: 在进行训练前的一个重要的步骤是进行数据的预热,Fluid 提供原生支持丰富策略的数据预热,可在训练前将训练文件的元数据和数据缓存到本地,可大大加速训练速度。
只读场景给 dataset 设置 readOnly:我们的训练数据集是只读的,并且在训练期间不会发生变化,此时可以通过将 dataset 设置为 readOnly,Fluid 自动开启各级缓存,包括 FUSE 层和 Alluxio 元数据缓存,这样可以避免额外开销,减少非必须的调用链路。比如避免不必要的元数据交互。而需要写 checkpoint 的,则创建一个支持读写的 dataset,应用同时挂载两个 dataset。
自动扩缩容:我们通过我们的麒麟平台在高峰期是将作业调度到 fluid 管理的 alluxio 集群,在高峰期 alluxio 的缓存容量可达 95% 以上,而在低谷期时几乎没有作业,这时我们利用了 fluid 的自动扩缩容的功能,我们配置扩缩容策略,在高峰时检测到 alluxio 缓存容量达到 90% 时扩容。低谷期时我们的 alluxio 集群基本上没有作业在运行,这时开始缩容到默认节点数。自动扩缩容功使我们更加灵活的使用通过分布式缓存提升数据访问加速能力,并且大大的节省了成本,提高了资源使用率。
总结
我们混合云器学习平台在引入 Fluid 之后,简化了云上数据访问复杂度,同时性能和成本上也达到了比较满意的效果。而且我们也看到了云上弹性资源使用自有存储在成本,效率上都有不错的收益,也打消我们之前对于混合云场景下利用云上资源扩展机器学习平台的算力受制于线下存储的顾虑。
现在 Fluid 已经成熟,在刚开始引入 Fluid 的时候,我们遇到了很多的问题,也发现了 Fluid 的一些 bug,感谢 Fluid 社区及时的修复以及对我们的需求的及时支持。感谢车漾、徐之浩和顾荣等几位老师的对我们的指导和帮助。
未来,360 团队会加大在 Fluid 开源社区的投入,也希望更多感兴趣的人加进来,一起共建 Fluid 社区。期待 Fluid 成为一流的开源产品。




