
2016 年,我们发表了关于 Schemaless—Uber Engineering 的可扩展数据存储的博文(一、二)。在这两篇博文中,我们介绍了 Schemaless 的设计,并解释了开发它的原因。今天这篇文章我们将要讲的是 Schemaless 向通用事务性数据库 Docstore 的演化历程。
Docstore 是一个通用的多模型数据库,它在分区级别上提供了严格的序列化一致性模型,并且可以横向扩展以满足高容量工作负载。诸如 Transaction(事务)、Materialized View(物化视图)、Associations(关联)和 Change Data Capture(变更数据捕获)等功能,结合建模的灵活性和丰富的查询支持,显著提高了开发人员的工作效率,并缩短了 Uber 新应用的交付时间。
Docstore 目前已经投入生产,并服务于业务关键用例。
动机
Schemaless最初被设计为一个仅有附加的数据存储。最小的实体被称为单元格,它是不可变的。去除可变性降低了系统的复杂性,并使其不易出错。然而,随着时间的推移,我们意识到,由于限制性的 API 和建模能力,使得用户很难将其作为一个通用的数据库来使用。
Schemaless 的缺点导致了 Cassandra 的推出,它确实提供了很多灵活性和易用性。但是,Cassandra 还有其他缺点。Uber 的数据足迹很大,因此可扩展性和效率必须齐头并进。在 Uber 的规模下,我们发现,Cassandra 在操作方面不够成熟,同时它也不能提供理想的效率水平。而 Cassandra 提供的一致性,最终也阻碍了开发人员的工作效率,因为他们必须围绕着缺乏强一致性的问题进行设计,这就使得应用架构变得更加复杂。
有了开发和运行 Schemaless 和 Cassandra 的第一手经验,我们得出的结论认为,将 Schemaless 演化为一个通用的事务性数据库是最佳选择。Schemaless 历来是一个高度可靠的系统,但现在我们需要关注可用性,同时实现相似或更好的可靠性。
设计上的考虑
我们并不想构建 NoSQL 系统,相反,我们想实现两全其美:文档模型的模式灵活性和传统关系模型中的模式约束。
为了在数据上约束模式,我们在 Docstore 中设计了表。使用数据的应用程序通常采用某种结构。这意味着,它们要么利用读时模式(schema-on-read),即应用程序在读取数据时对数据进行解释;要么利用写时模式 (schema-on-write) ,确保模式是显式的,而数据库则确保数据模式的一致性。缺省情况下,我们支持后一种方法“写时模式”。
Docstore 除了上面的模式约束之外,还提供了模式灵活性,而且模式是可以演化的。Docstore 允许共存不同模式的记录,并且模式更新无需重建全表。稀疏性和对复杂嵌套数据类型的支持是 Docstore 的一流特性。
功能集
Docstore 内置了以下功能。它整合了 Uber 软件生态系统,只需点击一下按钮即可进行配置。
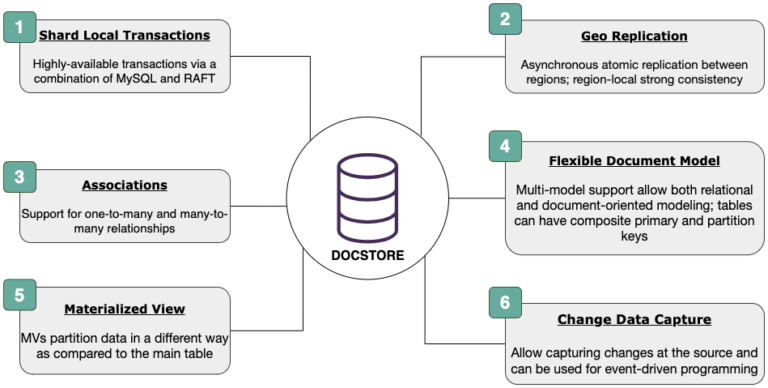
图 1:Docstore 功能
架构
Docstore 的架构是层次化的,Docstore 的部署称为实例。每个实例分为查询引擎层、存储引擎层和控制平面。
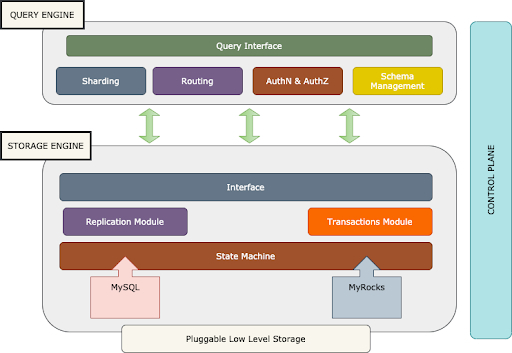
图 2:Docstrore 层次架构
查询层是无状态的,它负责将请求路由到存储层。
负责存储数据的存储引擎被组织成一组分区,数据分布在这些分区上。控制平面负责为 Docstore 分区分配分片,并根据故障事件自适应地调整分片的位置。
Docstore 具有表的概念。表看上去类似于关系型数据库表,其结构由行、列和值组成。对于 Docstore 中表的建模方式没有任何限制,Docstore 可以使用用户定义的类型将嵌套的记录存储为行。举例来说,如果数据具有与文档相似的结构,并且整个层次结构只加载一次,那么这就很有用。Docstore 还支持“关联”,允许表示一对多和多对多的关系。我们称之为“灵活的文档模型”,因为它支持对关系型和层次型的数据模型进行建模。在本系列博文的第二部分中,我们将介绍 Docstore 的数据建模。
每个表可以有一个或多个物化视图。物化视图是一种视图,它通过使用不同的列,允许以不同于主表的方式对数据进行分区。增加由非主键列进行分区的物化视图,可以有效地通过该列来查询数据,并允许不同的查询访问模式。
每个表都必须有一个主键,而主键可以由一个或多个列组成。主键标识了表中的行,并强制执行唯一约束。从内部看,主键和分区键列都存储为字节数组,并通过对键列值进行保序编码来获取值。Docstore 按照主键值的排序顺序存储行。这种方法与复合分区键相结合,可以实现复杂的查询模式,包括使用给定的分区键抓取所有行,或者使用主键的剩余部分来缩小特定查询的相关行。
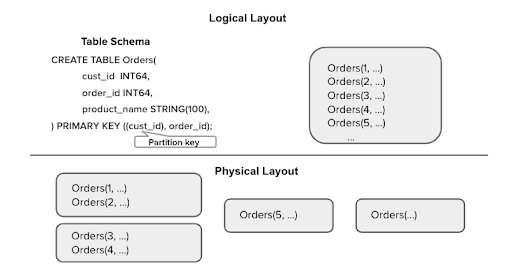
图 3:Docstore 表布局
当然,对于我们来说,下一步就是在设计过程中实现分片逻辑。表被分片并分布在多个分片上:对应用程序来说是透明的。每个分片代表表中几百 GB 的一组行,它被完整地分配到一个分区。一个分区可以包含一个或多个分片。
主要设计考虑是让应用程序通过选择键来控制数据局部性(data locality)。这就是我们在主键之外引入分区键的原因。应用程序可以选择在模式中明确定义分区键,否则,Docstore 就会使用主键来对数据进行分片。
通常情况下,每个 Docstore 实例中都有多个分区。为解决单点故障问题,分区是由 3~5 个节点组成的一组,每个节点是一个物理隔离单元,部署在一个独立的区域中。每个分区都会被复制到多个地理位置,以提供数据中心故障的恢复能力。
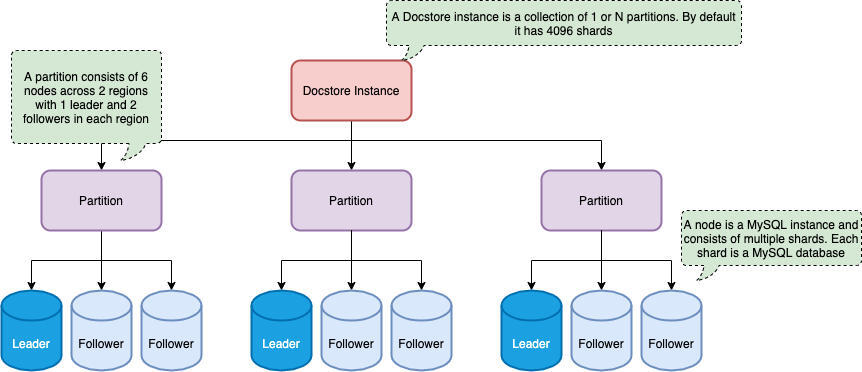
图 4:Docstore 数据分区
复制状态机
为了保证一致性,每个分区都会运行 Raft 共识协议。有一个领导者和多个跟随者。
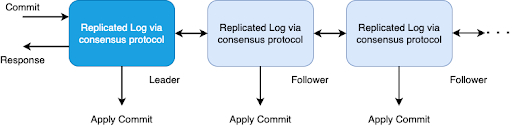
图 5:Docstore 复制状态机
所有的写入均由领导者发起。执行共识协议以保持分区中各节点复制日志的一致性。这样就确保了分区中的所有节点都以相同的顺序包含相同的写入,从而保证了可序列化。只有在达成共识的情况下,在每个节点上运行的状态机才会继续提交写入。这样就提供了一个非常好的属性,即如果对一个键的写入提交成功,则通过同一键所有后续的读取将返回该特定操作或随后某个写入操作的相同数据。
一致性模型
Docstore 在分区级别上提供了严格的可序列化一致性模型。这样用户就可以很好地了解到事务是按顺序执行的。事务的顺序是这样的:一个事务“A”在事务“B”之前启动和提交,并且始终发生在事务“B”之前。这样可以确保读操作总是从最近的写操作返回结果。用 CAP 定理的术语来说,Docstore 更倾向于一致性而不是可用性,因此它是一个 CP 系统。
事务
Docstore 使用 MySQL 作为底层数据库引擎。在复制状态机中,复制单位是一个 MySQL 事务。所有的操作都在 MySQL 事务的上下文中执行,以保证 ACID 语义。这些事务随后使用 Raft 共识协议在节点间进行复制。
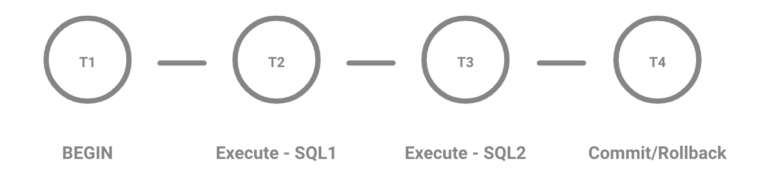
图 6:事务中的操作序列
我们依靠 MySQL 进行并发控制。要知道,MySQL 依靠行锁来实现写操作(插入、更新、删除)的并发控制,这一点很重要。这样,MySQL 就有效地序列化了对同一行的并发更新,并且当控制流到达客户端发出提交时,所有的锁都已经处理完毕。
通过图 7 的流程图,我们可以看出事务是在时间上交错的。在时间轴上,用不同位置的方框表示交错,也就是不同方框对应着不同时间的“事件”。
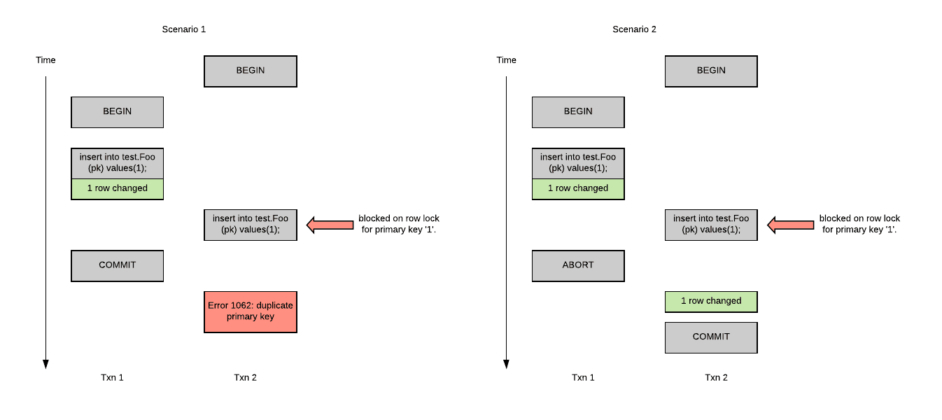
图 7:交错插入
基于 Raft 复制状态机的实现,MySQL 的事务可以以高可用的方式公开给客户端,即所有的复制体相互协调应用事务,这样,复制体之间就可以实现自动故障转移,同时即使发生故障转移,事务的 ACID 属性也会保持不变。需要注意的是,由于我们依赖于将 MySQL 的事务公开给客户端,因此集成了 MySQL 事务的所有优点和约束。
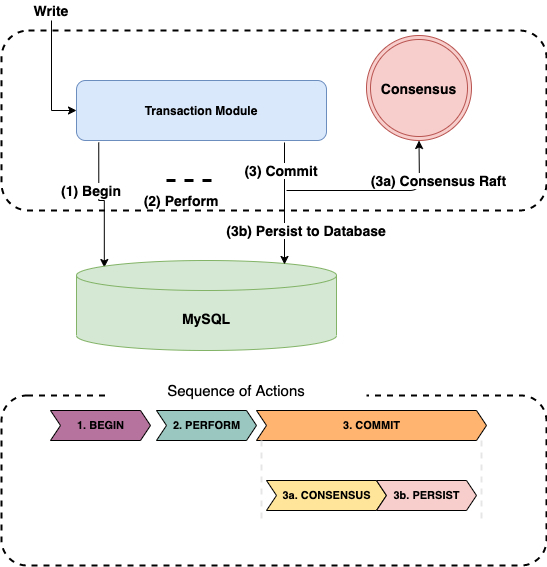
图 8:Docstore 事务流
总结
在这篇文章中,我们已经阐述了 Docstore 的起源及其背后的动机。此外,我们还深入分析了该架构,并解释了如何在 Docstore 中处理事务。在本系列博文的下一个部分,我们将重点讨论数据建模和模式管理。我们将介绍 Docstore 如何支持分层和关系模型,以及哪些类型的应用应该选择这些数据模型。我们将深入研究 Docstore 中的物化视图,这是本系列博文的第三部分,也是最后一部分。其中包括动机、物化视图刷新框架以及我们计划如何利用物化视图,尽管在查询中没有明确提及。
作者介绍:
Ovais Tariq,Uber 核心存储团队的高级经理,领导运营存储平台组,专注于提供一个世界级的平台,为 Uber 所有关键业务功能和业务线提供动力。该平台为数千万 QPS 提供服务,可用性达到 99.99% 以上,并存储了数十个 PB 的运营数据。
Deba Chatterjee,Uber 基础设施团队担任高级产品经理。在加入 Uber 之前,Deba 曾在数据库创业公司和甲骨文公司担任各种产品管理职务。在进入产品管理之前,Deba 负责管理大型数据仓库的性能。Deba 拥有宾夕法尼亚大学的技术管理硕士学位。
Himank Chaudhary,Uber Docstore 的技术负责人。主要关注领域是构建分布式数据库,随着 Uber 的超速发展而扩展。在加入 Uber 之前,他曾在雅虎的邮件后端团队建立元数据存储。Himank 拥有纽约州立大学计算机科学硕士学位,专业为分布式系统。
原文链接:




