
嘉宾 | 蒋江伟、贾扬清、李飞飞等
采访 | 赵钰莹、王一鹏
编辑 | 赵钰莹、张俊宝
上周,2022 云栖大会召开,阿里云智能总裁张建锋表示,以云为核心的新型计算体系正在形成,软件研发范式正在发生新的变革,Serverless 是其中最重要的趋势之一。
Serverless 是一个十分值得探讨的话题,伯克利早在 2019 年就预言这会是云计算下一个十年的发展方向,但时至今日,我们看到的都浅尝 FaaS 及小程序的云开发层面,并未深刻体会到 Serverless 对软件研发范式带来的改变。本届云栖大会上,阿里云宣布全面推动核心产品 Serverless 化,并预测未来 80% 的应用都是由业务人员来开发。作为一种新型生产工具,云计算的应用门槛是否已经降到了一个足够低的临界值?是否已经催生了新技术的“奇点”?
借此机会,InfoQ 与阿里云多个技术团队进行了深入交流,以了解其背后的实现逻辑、技术路线以及对业务研发带来的变革等,试图看清楚云计算技术的第二增长曲线。
云计算诞生以来,最为人熟知的比喻是数字时代的“水电煤”,但其实我们至今都未曾达到像使用“水电煤”一样使用云计算,我们还在按照“几核几 G 服务器”的模式来购买云资源,我们还停留在云计算的“汇编时代”。
那么,我们如何能进入下一个阶段,以按照理想的方式使用云计算,一如编程语言从汇编时代演变为高级语言时代。
Serverless 或许可以。Serverless 的特点之一就是按实际用量计费,更加接近“电网”模式,能让云计算从一种资源真正变成一种能力。
可能会有开发者对此嗤之以鼻:“别闹了,这个概念都玩好几年了,如果好用早就用了,还用得着等到现在。”
确实如此,我们谈 Serverless 好多年了。阿里云最早的 OSS 对象存储就是一个 Serverless 产品,只不过最近几年出现了函数计算这样通用的 Serverless 计算平台,进而能够将 Serverless 体系产品连接起来,构建一个 Serverless 应用。
2017 年到 2018 年,感官上 Serverless 的热度达到了高峰,但与绝大部分新兴技术一样,其开始进入落地艰难期。Serverless 不仅仅是一种技术,而是一种全新的架构,只要有一个环节不是 Serverless 的,对开发者而言这种模式就没有太大意义,因为还需要为这一个环节进行重新设计。这一架构需要的是自底向上的全面重塑,是整个研发链路的全面 Serverless 化。
时至今日,这一架构正在被阿里云们变为可能。
新一代云计算架构体系雏形已现
Serverless 的表现形态或许大同小异,但其底层支撑架构却千差万别,不同的架构带来了不同的性能和稳定性等。
对阿里云而言,Serverless 真正蜕变要从 CIPU 开始。
今年 6 月,阿里云发布了一款云数据中心专用处理器 CIPU(Cloud Infrastructure Processing Unit),取代 CPU 来管理和加速数据中心的计算、存储和网络资源。CIPU 向下云化管理数据中心硬件,并对计算、存储和网络资源进行加速,向上接入飞天云操作系统,将全球 数百万台服务器变成一台超级计算机,为客户提供更高性能、更低价格、更可靠的云计算服务。
在这种新型架构里面,存储、计算、网络通过这种新兴的体系架构互相之间进行通信交换,云的能力、效率、成本几方面都得到大幅改善。
以前在 CPU 用软件来管理数百万台服务器接入飞天操作系统,所有的算力都需要和飞天云操作系统耦合,给客户的算力和算力迭代都需要和飞天耦合,需要不断地做软件的适配。CIPU 的到来让算力解耦,真正变成了“即插即用的云计算”。
CIPU 诞生的目的是为了管理底层的云基础设施,包括相对应的底层的虚拟化的池化管理。2017 年,阿里云发布了第一代神龙架构,并为之专门开发了 MOC 卡,可以理解为 CIPU 最早期的雏形。
计算、存储、网络全部接入这一代的硬件架构后,能够实现数据路径全部都是硬件加速,第一次真正完整地颠覆了原来的“软件定义云”。
此外,CIPU 带来一个最明显的标志就是虚拟化的开销真正意义上降到了 0,无论是计算虚拟化还是存储、网络的全面加速。“飞天 +CIPU”的组合性能可提升 20% 以上。
在此基础上,阿里云基础设施已经广泛基于 CIPU 架构进行建设,并且构建了全栈自研的基础设施,例如自研 CPU 芯片倚天 710、磐久服务器、EIC 高性能网卡、磐久交换机、磐久液冷一体机、磐久液冷集装箱等自研硬件。
去年,阿里巴巴发布了首款“为云而生”的芯片倚天 710。目前,倚天 710 云实例已在多家互联网科技公司大规模应用,算力性价比提升超 30%,单位算力功耗降低 60%,这也是中国首款云上大规模应用的自研 CPU。
在今年双 11 期间,天猫双 11 的部分系统就平滑迁移至倚天 710 实例,提供稳定的服务。国内一些知名的科学计算、智能手机行业和互联网等领域的企业在迁移至倚天 710 实例后,性价比均得到了显著提升。
未来阿里云还将继续扩大自研 CPU 的部署规模,预计未来两年内 20% 新增算力将使用自研 CPU 芯片倚天 710。
时至今日,个别大型企业可能还在自建数据中心,在获取同等性能的情况下成本或许是可控的,但当进入 CIPU 和自研 CPU 构建的时代,企业就会发现即便付出再大的代价也无法搭建出性能可与之比拟的数据中心了。
以阿里云网络型负载均衡 NLB 为例,其单实例可以达到 1 亿并发连接,500G 吞吐,这是什么概念?一家互联网企业如果能达到这个规模,在中国是可以进入 TOP 10 的,这是阿里云调动了云上海量资源才可以实现的性能,自建的效率是很难与之媲美的,即便性能硬堆上去了,稳定性也会存在问题。
基于底层的全面重塑,我们有理由相信软件架构全面 Serverless 化的未来将至。

软件架构全面 Serverless 化的未来已至
最近几年,微服务改造逐渐完成,其带来的各个层面的复杂性已经在众多场合被反复讨论过了。以微服务为核心的互联网分布式架构,实施的复杂度较高,必须有很好的工具、平台的支撑,这是业界的共识。
对用户而言,尽可能消除非业务研发占用的时间是非常迫切的,这正是 Serverless 的核心价值。
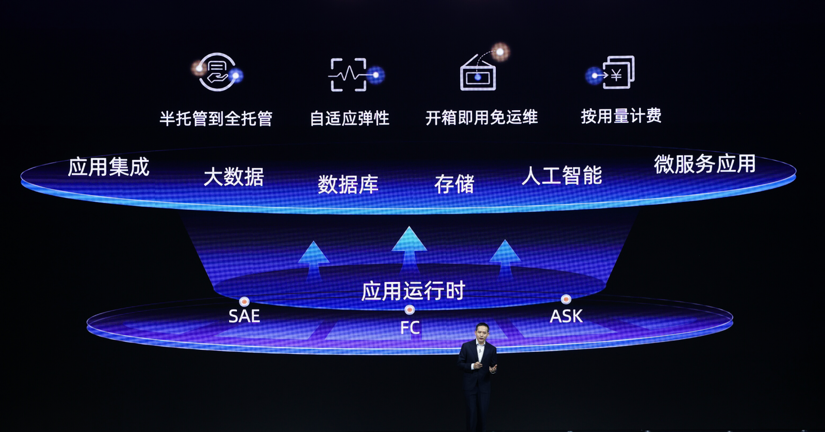
Serverless 具备三个明显的特点,一是全托管服务,这意味着客户使用抽象的服务化接口,而不是直接面对底层资源,也就没有安装、配置、维护或者更新软硬件的负担。全托管服务通常也提供了内置的容错、安全和可观测能力,用户通常不需要再重新构建这些能力。
这与我们常常提到的云托管是有很大差异的,如果采用云托管模式,实际上是在基础设施层构建应用,应用构建的抽象层次是比较低的,因此会带来大量工作,用户自己需要整合不同的组件和服务,需要进行大量的决策和实现,交付的速度会比较慢,需要考虑很多的事情,而且在运维方面有大量的重复工作。
如果采用 Serverless 的模式构建应用,也就是相当于在上层 API 的方式构建应用,粘合的逻辑和基础设施管理的工作都由云服务商来承担,用户所需要整合和决策的代价比较低,所需要考虑的主要就是如何将业务逻辑和需求与云服务进行适配来构建应用。基于非常高效的云 API 来构建应用的好处在于构建的成本极低,并且能够实现按天、按小时进行灵活交付,大大降低未来运维的负担。
二是自适应弹性,服务能够根据负载大小自动弹性伸缩,大大提升了资源使用效率。
三是开篇提到的按实际用量计费,只需根据实际的执行时间、流量或调用次数计费,降低了成本。
要想让用户用好 Serverless,单纯在应用运行时层面进行 Serverless 化是远远不够的,应用依赖的下游数据库等系统,如果没有良好的弹性,就会成为系统整体的“短板”。
全面实现 Serverless 化取决于整个研发链路上有多少云产品提供了这样的形态。阿里云是国内对 Serverless 探索最早的厂商之一,其于 2017 年推出了函数计算产品 FC,2018 年推出了 Serverless 应用引擎 SAE 和 Serverless 容器服务 ASK,2020 年开源了 Serverless Devs … 其中,函数计算日调用次数超过 200 亿次,有效支撑历年双 11 百万 QPS 洪峰,业务年均增速超 300%,整体规模位居国内首位。
截至目前,阿里云有超过 20 款核心产品提供了 Serverless 形态,在弹性速度、计费模型上帮助客户业务更好地驾驭底层算力,节约成本。其最新发布的 Serverless 应用中心提供海量的场景化模板,让 Serverless 应用全生命周期管理更简单。通过使用 Serverless 应用中心,用户在部署应用之前无需进行额外的克隆、构建、打包和发布操作,即可快速部署和管理应用,帮助用户快速联动云上的上下游服务,轻松沉淀最佳实践。
数据库:Serverless 最难攻坚的堡垒
云数据库帮助企业和开发者节省了很大一部分运维精力,但在很多场景下,工作负载并不均衡、波峰波谷差异极大,在预算有限的情况下,我们大多时候依赖持续监控和手动对数据库容量调整来满足业务所需,但这种方式耗时耗力,还可能出问题,这就是 Serverless 化大展身手的场景。
在本届云栖大会现场,阿里云数据库团队提出了云原生数据库发展的四个方向:云原生化、平台化、一体化以及智能化。Serverless 正是云原生化的体现。
云原生化意味着数据业务加速上云,用户对数据库的需求正从资源视角向能力视角演进,而这就是阿里云数据库做出 All In Serverless 决定的原因。
但是,数据库是 Serverless 最“不友好”的应用之一,数据库不仅仅是一个“stateful”的应用,而且是一个“state-heavy”的应用,包括云原生基础设施 Kubernetes 对于 stateful 应用的支持,也是等到 StatefulSet 和 operator 之后才有一个比较好的解决方案。而在这之前数据库都是作为 Serverless 对状态做解耦和状态下沉的工具,也是全栈 Serverless 解决方案中最难攻坚的一个堡垒。
要知道,数据库在使用过程中需要满足 ACID 原子性、一致性、隔离性、持久性等特性,同时在线事务型数据库,都是 OL 开头,强调了在线,这两个叠加起来,就决定了数据库实现 Serverless 化是非常有挑战的。
但是,阿里云做到了。
以阿里云的 PolarDB 为例。PolarDB Serverless 的核心就是通过 RDMA/CIPU 等实现软硬件结合,使得跨节点的内存状态实现融合,基于此实现了 PolarDB 的跨节点在线无感迁移和强一致横向扩展,突破了资源池的单机限制,大幅提升资源利用效率,降低成本。
目前,阿里云数据库的 PolarDB、AnalyticDB、RDS 等核心产品已与倚天 710、CIPU、飞天操作系统进行深度融合创新,并全面 Serverless 化,对外更好地提供一站式数据管理与服务。
在 Serverless 层面,阿里云数据库团队实现了如下三项突破:
PolarDB for MySQL 是业内首创支持跨机 Serverless 服务的云数据库,为解决 Serverless 形态下普遍存在的上限规格过低限制,PolarDB 突破了无感秒切和高性能全局一致性两大技术难点,实现了跨机无感弹升和强一致横向线性弹升,使得上限规格突破了 1000 核以上,带来了数量级的 Serverless 能力提升,最高成本下降可达 95%,使得 Serverless 技术具备支撑企业级业务的能力。
RDS MySQL 采用计算存储分离架构,5 秒完成计算资源弹升;计费粒度精确到 1 秒,Serverless 最高实现 70% 成本下降;支持实例自动启停,无负载时仅保留存储资源计费,启动平滑最快 10 秒完成;天然支持了 DataAPI 能力,可以无缝融合 FaaS 提供全栈 Serverless 的解决方案。
AnalyticDB 基于资源池化和弹性存储能力,结合 MPP 数据库架构、离在线一体化以及 Serverless 创新技术,支持海量数据毫秒 / 秒级实时分析查询,让数据分析更实时、更高效;最高节省 90% 的总拥有成本 TCO;高度兼容 MySQL/PG,无缝升级 Teradata/Oracle。
2022 年 10 月,阿里云数据库作为首家云厂商,参与了中国信通院的 Serverless 能力评测。最终凭借过硬的 Serverless 技术实力,参与评测的 PolarDB for MySQL、RDS MySQL 数据库获得事务型数据库 Serverless 能力最高「先进级」评级;AnalyticDB MySQL 和 AnalyticDB PostgreSQL 获评分析型数据库 Serverless 能力「增强级」评级。
大数据 +AI:向着 Serverless 形态不断演进
大数据相较于数据库,不仅仅是 online 和 offline 的区别。大数据最大的特性是数据非常的半结构化,很多数据需要用户写代码,而不能完全靠关系代数做 Join、Select 等,大数据是非常稀疏的,并不是每行每列都有。这种情况下如果完全用关系代数是非常低效的,这对计算性能等各个方面都提出了挑战,大数据如何处理动态性变得至关重要,这也是大数据与云计算紧密结合的原因之一。
此外,从系统角度帮助用户在不同的资源之间寻求平衡,达到最优性价比,需要与云计算的基础设施紧密结合,通过硬件实现加速。至于硬件选型层面,通用型的硬件加速是值得的,但如果是专用型,成本会急剧升高,这也是云计算非常重要的特点,是否能够利用规模性和集群去做一些事情。
以 CIPU 为核心的架构在增效降本层面有非常本质的不同,阿里云的基础设施团队已经意识到大数据和 AI 巨大的算力要求,因此 Spark、Flink 等引擎通过与之相结合可以带来更好的投入产出比。
在 Serverless 层面,大数据与 AI 业务存在明显的波峰波谷,Serverless 可以实现更好的弹性,也可以在突发的流量高峰下迅速分配资源。本届云栖大会,阿里云 ODPS 升级为一体化大数据平台,支持大规模批量计算、实时分析等服务,提供实时流式计算、机器学习等多种计算能力,可同时调度超 10 万台以上服务器规模进行并行计算。ODPS 也是目前中国唯一自研、应用最为广泛的一体化大数据平台。
2017 年,ODPS 将大规模批处理引擎 MaxCompute 以独立产品形式对外提供服务,MaxCompute 天生是 Serverless 化的,用户可以为使用的计算量计费。机器学习平台 PAI 也会朝着 Serverless 的模式演进,无论用户需要多少机器做训练,底层平台都可以将这些资源管好,阿里云并不是第一天开始做 Serverless,只是一直在试图更加精细化地帮助用户进行训练、计算和分析,高效利用算力资源。
如今,开源降低了用户的研发门槛,但要想在云上构建一套完全按量付费又具备极致弹性,同时可以对管控面进行集中化管理,屏蔽所有底层运维复杂性,又具备智能诊断能力,这对用户而言是很难的,阿里云的开源大数据平台在过去与底层基础设施团队进行了密切合作,基于神龙裸金属,加之 Kubernetes 等容器化技术、调度技术、多租户的隔离技术,网络隔离技术及相关适配,让用户做到真正的在云上开箱即用,按量按需所用,这也是阿里云大数据团队一直以来都在坚持的。
开发者在新的架构体系下如何自处?
当一项技术开始进入大规模落地阶段,我们就需要清楚的认识到,其已经从趋势成为了必然。
2020 年天猫双 11,阿里云实现了国内首例 Serverless 在核心业务场景下的大规模落地,扛住了全球最大规模的流量洪峰,创造了 Serverless 落地应用的里程碑。
今年天猫双 11,阿里云 Serverless 支撑业务场景更多,范围更广,阿里云函数计算与集团内的运维体系全面实现标准化对接,打通研发的最后一公里,首次实现了业务全链路“ FaaS + BaaS ”的 Serverless 体系化研发,覆盖淘特、淘系、阿里妈妈、1688、高德、飞猪等业务场景,支撑场景数量同比增加 2 倍,峰值流量总数同比增加 3 倍,实现了百万 QPS 的突破,人效提升 40%。本届云栖大会上,函数计算还宣布全面降价,最大幅度达 37%,更普惠的价格受到诸多开发者的青睐。
南瓜电影借助 Serverless 应用引擎 SAE 7 天内全面 Serverless 化,零门槛拥抱 K8s,轻松应对热映电影的突发流量,相比传统服务器运维模式,开发运维效率提升 70%,成本下降 40%,扩容效率提升 10 倍以上。
这样的例子还有很多,此处不一一列举,但都足以说明 Serverless 已经成为软件研发的必然。
对开发者而言,可以在 Serverless 时代充分感受云带来的弹性,充分利用云计算软硬件协同带来的优势,摆脱网络工程师、运维工程师、安全工程师等诸多标签,集中精力做最擅长的事情,云计算将物理世界的安全、网络等能力统统软件化,变成了开发者最为擅长的视角,开发者只需进行合理的整体规划就可以得到更大的效率提升,甚至是需求管理都可以在云平台实现。
此外,阿里云将内部优秀的研发流程产品化后通过云平台对外提供,开发者可以借此了解阿里巴巴内部的研发流程实践,并从中获得助力。
总的来说,在未来,Serverless 架构比服务器在成本上会更有竞争力,当开发者用了 Serverless 架构时,就已经获得了高可靠,弹性扩缩容的能力。此外,Serverless 的计费模式会更加精确,资源利用率也将逐步提升,确保做到真正的按需使用和付费。因此相比预留资源,在价格上会更有竞争力,更多的开发者会因此选择 Serverless 架构。Serverless 同样有望支持更多类型的硬件,包括 ARM 类型的 CPU、GPU 或者 FPGA 等异构硬件,给开发者提供更有性价比的计算类型。
这种架构所带来的影响会持续多久,暂时没有答案。这样一种全新的计算架构体系是否会成为众多云计算厂商争相效仿的第二技术增长曲线,至少在阿里云身上,我们看到了诚意和决心。

当下,Serverless 确实是最接近云计算最初设想的模式,唯这一点,就足以让开发者们跃跃欲试了。
采访嘉宾:
蒋江伟 阿里巴巴集团副总裁、阿里云基础产品事业部负责人
贾扬清 阿里巴巴集团副总裁、阿里云计算平台事业部负责人
李飞飞 阿里巴巴集团副总裁、阿里云数据库产品事业部负责人
其技术团队成员对本文亦有贡献。




