
根据论文统计分析,开发人员将很多的时间都用到了探究系统本身的源码上,因为这是确定下一步行为的基础。关于如何提升代码探究的效率,作者 Tudor Girba 给出了自己的解决方案,也就是可塑开发。
本文最初发表于 feenk 网站博客,经原作者 Tudor Girba 授权,由 InfoQ 中文站翻译分享。
我经常被问到,我所说的开发人员将大多数时间花到了探究系统本身上到底是什么意思。那么我们现在就来仔细剖析这句话。
据我所知,关于这个话题,最早的参考文献可以追溯到 1979 年 Zelkowitz、Shaw 和 Gannon 写的一本书,名字叫做“Principles of software engineering and design”。书中说大多数的开发时间都花在了维护上(67%)。

软件开发的成本(1979)
当然,在这本书中,并没有说明这个数字是如何得出的。尽管如此,它被视为一个足够重要的问题,从那之后,吸引了大量的研究关注。
那么,四十多年之后的今天,现状又如何呢?
我们来看一下 Xia、Bao、Lo、Xing、Hassan 和 Li 发布在 IEEE Transactions on Software Engineering, 44, 951-976, 2018 上,名为“Measuring Program Comprehension: A Large-Scale Field Study with Professionals”的论文。这篇论文非常有意思,因为它详细阐述了这些数字是如何获取到的。按照该论文,理解部分(Comprehension)占到了大约 58%。
现在,我们仔细看一下结果的表格。
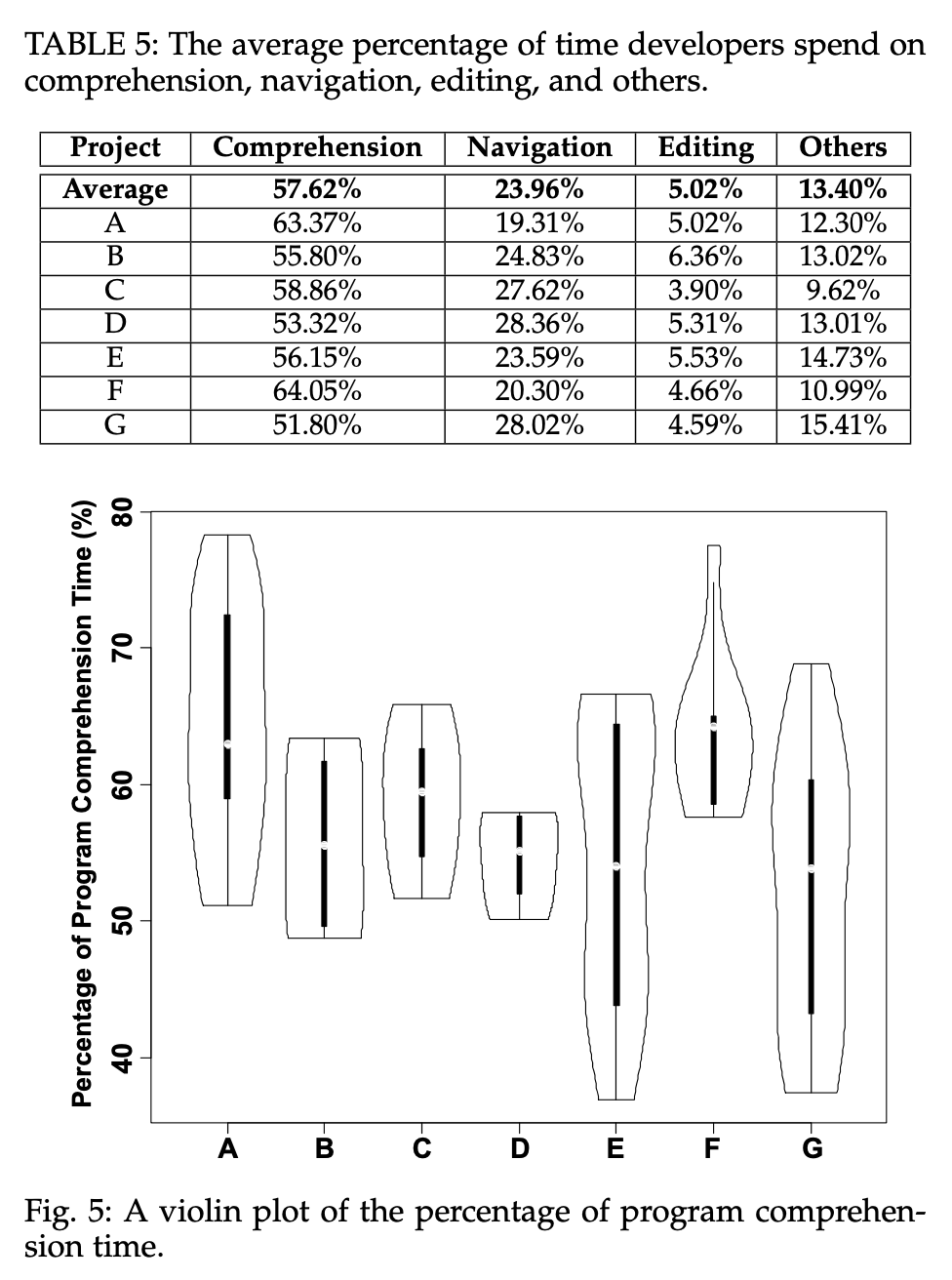
软件开发的成本(2018)
尤其是,我们关注一下表格中的第三列:它声称导航(Navigation)占到了所有工作量的 24%,在这里导航和理解是被分开计算的。
所以,我们可以看到,40 多年之后,除了学会衡量如何“计算”时间之外,并没有什么真正的改变。
那这又意味着什么呢?
的确,这是我们最大的一笔开销。如果我们想要优化自己领域中的某个事情的话,那么我们首先要去观察一下这一部分。我们会经常讨论如何构建系统,但是我们有多少次讨论“探究系统”本身呢?如果我们不谈论它,它就无法显现出来,如果无法显现出来,那我们就无法优化它。
如果我们谈论“探究系统”的时间是如何花掉的,就会注意到人们的时间用在了阅读上,正如前面的论文所示,理解本质上是通过阅读来衡量的。在大多数情况下,这两者被认为是同义词。
那么,我们该如何讨论怎样探究明白一个系统呢?
鉴于四十年来其实没有什么新的进展,所以我们应该考虑一下,也许应该以不同的方式来解决这个问题。
请耐心听我讲,现在到了有意思的地方了。那么,开发人员究竟为何要读代码呢?因为他们想要搞明白状况,从而能够知道下一步该怎么做。意图是很重要的,这就是做决策。
探究明白的时间也就是决策的时间
从这个角度来看,阅读只是从数据中收集信息的手段。它也恰好是最可能以手动的方式来实现的,所以这就为优化提供了很好的机会。
在你能够对某些事情采取一些重要的举措之前,我们首先要对其进行命名。否则的话,它就会像伏地魔一样。多年以前,我把“探究明白系统以了解下一步该做什么”所做的努力称为评估(assessment)。
当时,我就断言我们要围绕着它进行开发的优化。
在整整十年的时间内,我和我的同事一直在探索这个想法。它引导我们产生了我们现在称之为可塑开发(moldable development)的理念。
那这又是什么呢?
阅读是从数据中获取信息的一种纯手动的方式。它无法进行规模化,会导致不完整的信息和不确定性。
软件本身就已经很困难了。不了解目前的系统是什么样子的这件事不应该成为这方面中可接受的变量。关于当前系统的一张手绘图充其量只能说是一个理念。决策不应该建立在理念之上,在工程领域是不应该这样的。
一旦我们接受了系统是数据的观点,那么很明显我们就要像对待数据那样对待它。数据科学家告诉我们,首先要从问题出发,然后使用一个与上下文相匹配的工具来进行推断。
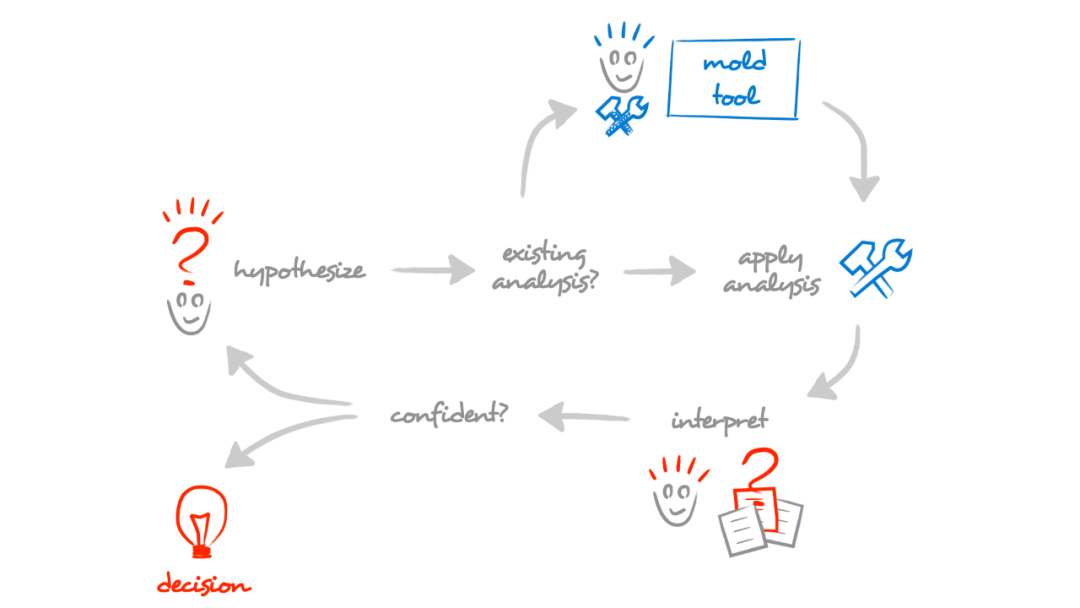
由于软件是与上下文高度关联的,我们无法预测具体的问题。我们只能预测问题的类别。为了实现这一点,可塑开发的关键理念就是在了解问题之后,工具应该是可塑的。通过这种方式,它可以处理上下文中的重要内容,也正因为如此,它可以处理阅读过程中最无聊的部分。当然,为了让它切实可行,创建自定义工具的成本必须非常小。
我认为在开发过程中构建自定义工具的流程,是软件开发的下一个重大飞跃,甚至在理想的情况下,针对每一个开发问题构建自定义工具。
在十年之后,我们不应该用阅读来衡量“探究系统”。我们应该将精力花在解决实际的问题上。为了达到这个目的,我们应该从讨论如何不读代码开始。我们必须要这样做。
我们创造了 Glamorous Toolkit,为“如何不读代码”方面提供了一个具体可行的开端。Glamorous Toolkit 是一个可塑的开发环境,使我们能够以低廉的成本创建关于软件系统的定制工具。
所以,去 gtoolkit.com 了解一下这些工具吧,感受 #MoldableDevelopment。
原文链接:
https://blog.feenk.com/developers-spend-most-of-their-time-figuri-7aj1ocjhe765vvlln8qqbuhto/




