
在设计自助开发工具产品时,通常会有一些限制——最常见的限制之一可能是规模。我们要确保我们的产品 Jit(一个安全即代码 SaaS 平台)规模化,我们不可能事后再来考虑这个问题,需要从写第一行代码开始就进行设计和处理。
我们希望工程师们能够专注于开发应用程序和提升用户体验,而不是让他们不断地被规模化等问题所困扰。在调研了能够帮助我们团队实现目标的基础设施之后,我们选择了 AWS 和基于无服务器的架构。
AWS Lambda 正在成为 SaaS 系统的热门选择,因为它的工具套件,包括支持这些系统的数据库(AWS DynamoDB),在扩展性和性能方面提供了许多好处。
它的主要优点之一是它已经是 AWS 生态系统的一部分,抽象了许多管理和维护方面的操作任务,例如维护与数据库的连接,并且只需要做很少的设置就可以在 AWS 环境中启动它。
作为一家快速增长的 SaaS 公司,我们需要基于用户和客户的反馈进行快速演化,并将其嵌入到我们的产品中。应用程序设计中的许多变更对数据结构和模式都有直接的影响。
随着应用程序设计和架构的快速演化,我们经常需要在 DynamoDB 中进行数据转换,对于现有的用户来说,我们的优先级是实现零停机数据转换。(在本文中,数据转换指的是将数据从状态 A 修改为状态 B)。
数据转换挑战
用终极格斗冠军赛运动员 Brendon Moreno 的话说:
也许不是今天,也许不是明天,也许不是下个月,但我敢保证,总有一天你会需要进行数据转换。
尽管数据转换在软件工程和数据工程中是一个已知的不变的事实,但要无缝地进行数据转换仍然是一个痛点。目前,我们还无法简单地通过可管理的编程方式在 DynamoDB 中实现数据转换,这令人感到惊讶。
虽然数据转换有很多种形式——从替换现有项的主键,到添加 / 删除属性,再到更新现有索引等等(这些只是其中的几个例子),但如果不使用临时或一次性脚本,仍然无法简单地通过可管理和可重复的方式进行这些转换。
User 表数据转换示例
下面,我们将深入探究一个使用生产数据进行数据转换的真实示例。
我们以将“FullName”字段拆分为“FirstName”和“LastName”两个字段为例。在下面的示例中,数据聚合操作将用户的名字写入表中的“FullName”字段。我们想要对 FullName 进行转换,将其分割为 FirstName 和 LastName 两个字段。
转换前

转换后

看起来很简单,对吧?事实并非如此。要实现这个简单的转换,需要在业务逻辑端执行以下这些步骤,才能成功地转换这个字段。
扫描 User 表记录;
从每个记录中提取 FullName 属性;
将 FullName 属性拆分为新的 FirstName 和 LastName 属性;
保存新记录;
清理 FullName 属性。
但在开始转换之前,我们需要考虑一些问题,例如,如何在不同的应用程序环境中执行和管理这些转换?特别是当访问每一个环境并不符合安全最佳实践时。此外,你还需要考虑服务依赖关系。例如,如果有另一个依赖于这种特定数据格式的服务,你应该怎么办?你的服务需要向后兼容,并且仍然需要向外部服务提供相同的接口。
如果在生产环境中有客户端,在修改代码之前需要问问自己——如何进行零停机的维护?
为了避免停机,你需要做好测试和验证的计划。如何测试数据转换脚本?对生产数据进行可靠的数据转换演练有哪些好的实践?
在转换数据之前,有很多事情需要考虑。
通常,这些操作在很大程度上都是手动完成的。这是一个多么容易出错、乏味的过程啊!看来我们需要一个细粒度的流程来防止出错,并帮助我们管理这些步骤。
为了避免手动出错,我们需要定义一个流程来帮助我们解决上面的挑战。
重写流程
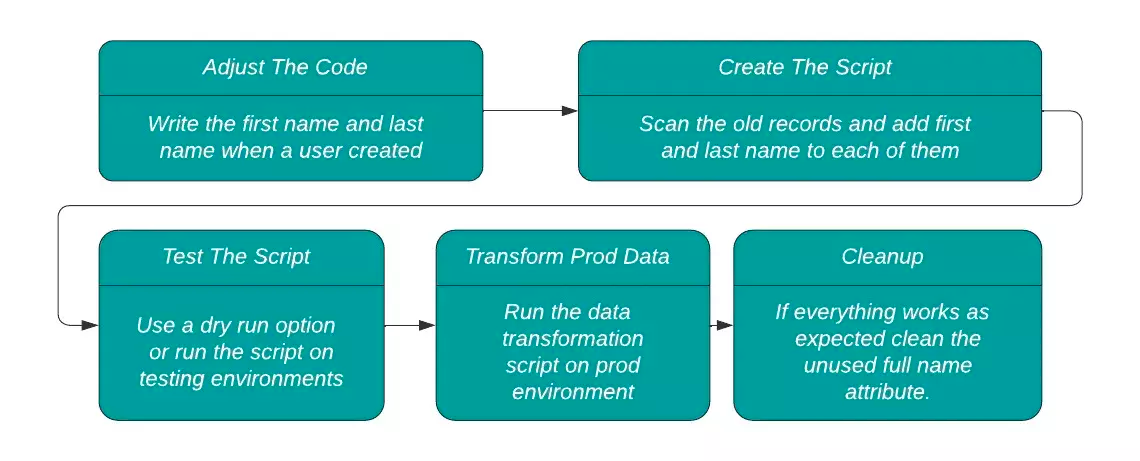
图 1 重写流程图
首先,我们调整后端代码,在保留旧格式的同时将新格式的数据写入数据库。先写入 FullName、FirstName 和 LastName 三个字段,确保向后兼容。如果出现了严重错误,我们可以恢复到以前的格式。
async function createUser(item) { // FullName = 'Guy Br' // 'Guy Br'.split(' ') === ['Guy', 'Br'] // 对于这个示例,假设FullName在名和姓之间有一个空格 const [FirstName, LastName] = item.FullName.split(' '); const newItemFormat = { ...item, FirstName, LastName }; return dynamodbClient.put({ TableName: 'Users', Item: newItemFormat, }).promise();};GitHub链接:https://gist.github.com/Guy7B/070701d73964987733a12cee422fc4da.js
接下来,我们写了一个数据转换脚本,扫描数据库中的旧记录,并将 FirstName 和 LastName 属性附加到每条记录上,参见下面的示例。
async function appendFirstAndLastNameTransformation() { let lastEvalKey; let scannedAllItems = false; while (!scannedAllItems) { const { Items, LastEvaluatedKey } = await dynamodbClient.scan({ TableName: 'Users' }).promise(); lastEvalKey = LastEvaluatedKey; const updatedItems = Items.map((item) => { const [FirstName, LastName] = splitFullNameIntoFirstAndLast(item.FullName); const newItemFormat = { ...item, FirstName, LastName }; return newItemFormat; }); await Promise.all(updatedItems.map(async (item) => { return dynamodbClient.put({ TableName: 'Users', Item: item, }).promise(); })); scannedAllItems = !lastEvalKey; };}GitHub链接:https://gist.github.com/Guy7B/fe2154630dfce753ac28c0ddb8c185c1.js
在写完脚本(这是比较容易的部分)之后,我们现在需要验证它是否执行了它应该执行的任务。为此,下一步是在测试环境中运行这个脚本,并确保它的行为符合预期。只有在确认了脚本的可用性之后,才能让它在应用程序环境中运行。
最后一步是清理,包括冒险将 FullName 列从数据库中完全删除。这样做是为了清除不再使用的旧数据格式,并减少混乱和未来对数据格式的滥用。
async function cleanup() { let lastEvalKey; let scannedAllItems = false; while (!scannedAllItems) { const { Items, LastEvaluatedKey } = await dynamodbClient.scan({ TableName: 'Users' }).promise(); lastEvalKey = LastEvaluatedKey; const updatedItems = Items.map((item) => { delete item.FullName; return item; }); await Promise.all(updatedItems.map(async (item) => { return dynamodbClient.put({ TableName: 'Users', Item: item, }).promise(); })); scannedAllItems = !lastEvalKey; }; };GitHub链接:https://gist.github.com/Guy7B/e56e170bba337f02e3dc91c3241c8430.js
我们来快速回顾一下我们在这个过程中所做的事情:
调整后端代码,写入新的数据格式;
创建一个更新所有记录的数据转换脚本;
在测试环境中验证脚本;
在应用程序环境中运行脚本;
清理旧数据。
这个定义良好的流程帮助我们在数据转换过程中构建了安全性和护栏。正如我们前面提到的,在这个过程中,我们能够通过保留记录的旧格式来避免停机,直到我们不再需要它们。这为更复杂的数据转换提供了良好的基础和框架。
使用外部资源转换现有全局二级索引(GSI)
现在我们有了一个流程——老实说,真实世界中的数据转换几乎没有这么简单的。我们假设一个更可能的场景,即数据是从外部资源(如 GitHub API)中摄取的,而更高级的数据转换场景可能要求我们从多个数据源摄取数据。
我们来看看下面的这个例子,看看它是如何工作的。
在下面的表中,GSI 分区键为 GithubUserId。
对于这个数据转换示例,我们希望向现有表中添加一个“GithubUsername”列。
转换前

转换后

这个数据转换看起来和上一个示例一样简单,但有一点小变化。
如果我们没有这个信息,该怎么获得 Github 用户名?我们必须使用外部资源,在这里就是 Github API。
GitHub 提供了一个简单的 API 来获取这些数据(你可以参考 文档)。我们通过 GithubUserId 获取用户信息,其中就包含我们想要的 Username 字段。
https://api.github.com/user/:id
基本流程与上面的示例类似:
调整代码,使用新格式写入数据;
假设我们在创建用户时有 Github 用户名;
扫描用户记录(使用‘GithubUserId’调用 Github API 获取每条记录的‘GithubUsername’),并更新记录;
在测试环境中运行脚本;
在应用程序环境中运行脚本。
不过,与之前的例子相比,这个例子有一个问题,就是它不够安全。如果在进行数据转换时调用外部资源出了问题该怎么办?也许外部资源发生崩溃或 IP 阻塞,或者因为其他原因不可用?在这种情况下,你可能会遇到错误或只执行了部分转换,或者出现其他数据问题。
我们能够做些什么来让这个过程更安全呢?
虽然你可以在发生错误时恢复脚本,或者尝试修复脚本中的错误,但如果能在生产环境中运行脚本之前先使用外部资源数据进行演练是最好不过了。提前准备数据是一种更安全的措施。
下面是更安全的流程设计:
调整代码,使用新格式写入数据(创建 GithubUsername 字段创建一个用户);
为执行转换准备数据。
然后,我们扫描用户记录,使用 Github API 获取每个用户的 GithubUsername,将其附加到 JSON 对象“{ [GithubUserId]: GithubUsername }”,然后将该 JSON 写入文件。
这个流程是这样子的:
async function prepareGithubUsernamesData() { let lastEvalKey; let scannedAllItems = false; while (!scannedAllItems) { const { Items, LastEvaluatedKey } = await dynamodbClient.scan({ TableName: 'Users' }).promise(); lastEvalKey = LastEvaluatedKey; const currentIdNameMappings = await Promise.all(Items.map(async (item) => { const githubUserId = item.GithubUserId; const response = await fetch(`https://api.github.com/user/${githubUserId}`, { method: 'GET' }); const githubUserResponseBody = await response.json(); const GithubUsername = githubUserResponseBody.login; return { [item.GithubUserId]: GithubUsername }; })); currentIdNameMappings.forEach((mapping) => { // append the current mapping to the preparationData object preparationData = { ...preparationData, ...mapping }; }); scannedAllItems = !lastEvalKey; }; await fs.writeFile('preparation-data.json', JSON.stringify(preparationData));};GitHub链接:https://gist.github.com/Guy7B/48306ad4acfb1e7136b039635013d25b.js
接下来,我们扫描用户记录(使用准备好的数据,通过 GithubUserId 获取每条记录的 GithubUsername),然后继续更新记录。
async function appendGithubUsername() { let lastEvalKey; let scannedAllItems = false; while (!scannedAllItems) { const { Items, LastEvaluatedKey } = await dynamodbClient.scan({ TableName: 'Users' }).promise(); lastEvalKey = LastEvaluatedKey; const updatedItems = Items.map((item) => { const GithubUsername = preparationData[item.GithubUserId]; const updatedItem = currentGithubLoginItem ? { ...item, GithubUsername } : item; return updatedItem; }); await Promise.all(updatedItems.map(async (item) => { return dynamodbClient.put({ TableName: 'Users', Item: item, }).promise(); })); scannedAllItems = !lastEvalKey; };};GitHub链接:https://gist.github.com/Guy7B/15149835c7f4b18d368c69a1960ef6b1.js
最后,与前面的流程一样,我们在测试环境中运行脚本,然后在应用程序环境中运行脚本。
Dynamo 数据转换
在构建了一个可靠的数据转换流程之后,我们就会明白,要想消除手动错误,最好的办法就是将其自动化。
我们意识到,手动流程可能适用于小规模的场景,但不具备可伸缩性。这不是一个可行的长期解决方案,它最终会随着组织规模的扩大而发生崩溃。因此,我们决定构建一个工具来帮助我们自动化和简化这个过程,这样一来,数据转换在我们产品的增长和演进中就不再是一个可怕和痛苦的过程了。
使用开源工具进行自动化
数据转换就是一段段的代码,帮助我们执行特定的数据库变更,但这些脚本最终必须出现在代码库中。
我们因此能够做一些重要的操作:
跟踪数据库的变化,每时每刻都可以了解数据的历史。这有助于排查错误和问题。
不需要重新发明轮子——重用已经编写好的数据转换脚本可以简化流程。
对数据转换过程进行自动化基本上可以让每个开发人员都能够执行数据转换。虽然你可能不应该将生产环境的访问权限授予组织中的每一个开发人员,但应用数据变更总是发生在整个流程的最后一英里。当只有少数人能够访问生产环境,他们不需要承担编写脚本的繁重工作,但需要验证脚本并在生产环境中运行它们。我们知道这样做会消耗更多的时间,而且不安全。
当代码库中的脚本及其执行过程通过 CI/CD 管道进行自动化后,其他开发人员就可以检查它们。基本上,任何人都可以在所有环境中执行数据转换,从而缓解了瓶颈。
现在,我们了解了在代码库中管理脚本的重要性,我们还希望为每个数据转换开发人员创造最佳的开发体验。
让每个开发人员都能进行数据转换
每个开发人员都喜欢专注于他们的业务逻辑——很少有上下文中断和变化。这个工具可以帮助他们专注于业务逻辑,而不必在每次需要执行数据转换时都从头开始。
例如,dynamo-data-transform 提供了以下这些好处:
对大多数数据转换都有用的导出功能;
数据转换脚本的版本控制;
支持演练,可以轻松地测试数据转换脚本;
在转换出错时回滚——很难轻松恢复到之前的状态;
交互式 CLI——为了提升开发体验并与开发工作流保持一致。你可以使用命令 dynamodt up 来运行脚本,用 dynamodt down 进行回滚,用 dynamodt history 来显示执行了哪些命令。
DynamoDT 示例
无服务器安装:
dynamo-data-transform 可以作为一个独立的 npm 包使用。
要使用 DynamoDT,首先通过 NPM(也可以通过其他方式)来安装这个包:
npm install dynamo-data-transform --save-dev接下来,将这个工具添加到无服务器中:
npx sls plugin install -n dynamo-data-transform你也可以选择手动将它添加到 serverless.yml 中:
plugins: - dynamo-data-transform你还可以通过执行这个命令
sls dynamodt --help来查看 DynamoDT 支持的所有特性。
我们现在使用 DynamoDT 运行一个示例。我们从代码库的代码示例中选择了一个示例 v3_insert_users.js,你也可以使用在这里找到的其他示例进行测试(https://github.com/jitsecurity/dynamo-data-transform/tree/main/examples/serverless-localstack/data-transformations/UsersExample)。
我们通过运行命令
npx sls dynamodt init --stage local对包含了相关表的数据转换目录进行初始化。
对于无服务器,serverless.yml 中将会出现:
resources: Resources: UsersExampleTable: Type: AWS::DynamoDB::Table Properties: TableName: UsersExample生成的目录 data-transformations 中有一个模板脚本(https://github.com/jitsecurity/dynamo-data-transform#data-transformation-script-format)。
使用模板脚本生成的数据转换文件夹可以在这里找到。
我们将模板文件 v1_script-name.js 中的代码替换为:
const { utils } = require('dynamo-data-transform');const TABLE_NAME = 'UsersExample';/** * The tool supply following parameters: * @param {DynamoDBDocumentClient} ddb - dynamo db document client https://docs.aws.amazon.com/AWSJavaScriptSDK/v3/latest/clients/client-dynamodb * @param {boolean} isDryRun - true if this is a dry run */const transformUp = async ({ ddb, isDryRun }) => { const addFirstAndLastName = (item) => { // Just for the example: // Assume the FullName has one space between first and last name const [firstName, ...lastName] = item.name.split(' '); return { ...item, firstName, lastName: lastName.join(' '), }; }; return utils.transformItems(ddb, TABLE_NAME, addFirstAndLastName, isDryRun);};module.exports = { transformUp, transformationNumber: 1,};GitHub链接:https://gist.github.com/Guy7B/495732ecc3c9915bf160de97940e2a28
对于大多数常规的数据转换,你可以使用 dynamo-data-transform 包提供的辅助功能,不需要自己管理数据转换脚本的版本,这个包将为你完成这项工作。在自定义了你想要转换的数据之后,就可以通过运行下面的命令来测试脚本:
npx sls dynamodt up --stage local --dry脚本将在控制台打印出记录,这样你就可以立即看到脚本的结果,并确保没有发生数据中断或其他问题。
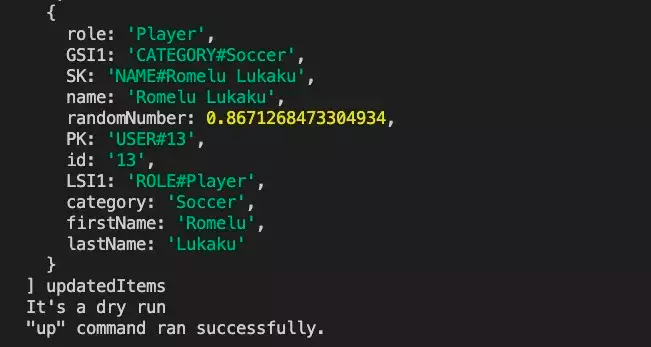
如果你对测试结果感到满意,就可以删除 --dry 选项,并再次运行它。这一次,它将在生产环境的数据上运行脚本,因此请确保对结果进行验证。
在创建了数据转换文件之后,接下来你可能想要将其添加到 CI/CD 管道中。你可以将这个命令添加到生产环境的工作流 /CI 文件中。
这个命令将在 sls deploy 命令之后立即运行,这对于无服务器应用程序来说非常有用。
最后,所有这些都会被保存起来。如上所述,如果你想查看数据转换的历史,可以运行:
npx sls dynamodt history --table UserExample --stage local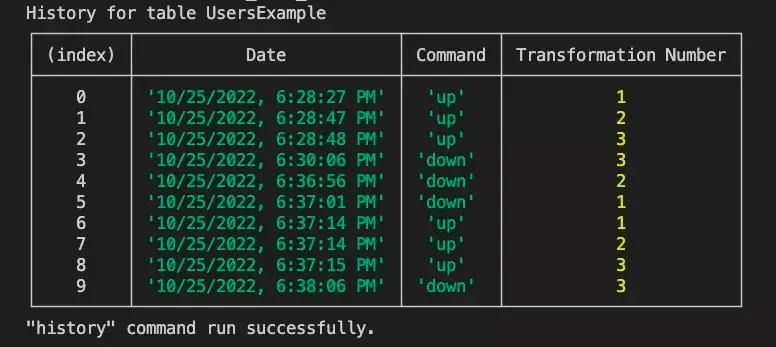
这个工具还提供了一个交互式 CLI。
以上所有的命令都可以通过 CLI 来实现。
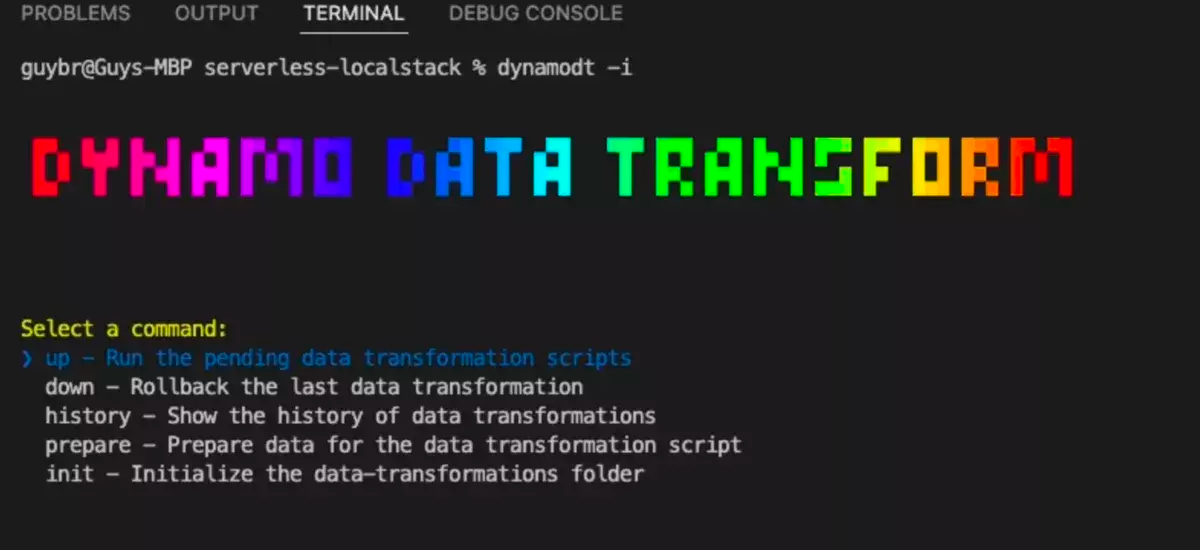
有了 Dynamo Data Transform,你可以获得额外的好处,可以对数据转换操作进行排序和版本化,并在一个地方管理它们。如果回滚了某个操作,你还可以查看数据转换操作的历史记录。最后,你还可以重用和查看以前的数据转换。
我们已经开源了 Dynamo Data Transform,在内部,我们用它在 DynamoDB 和基于无服务器的环境上执行数据转换,并安全地管理以前只能通过手动的方式来执行的过程。
这个工具可以作为无服务器插件使用,也可以作为独立的 NPM 包使用。
NPM
GitHub
如果你觉得有用,请随时提供反馈并参与项目的贡献。
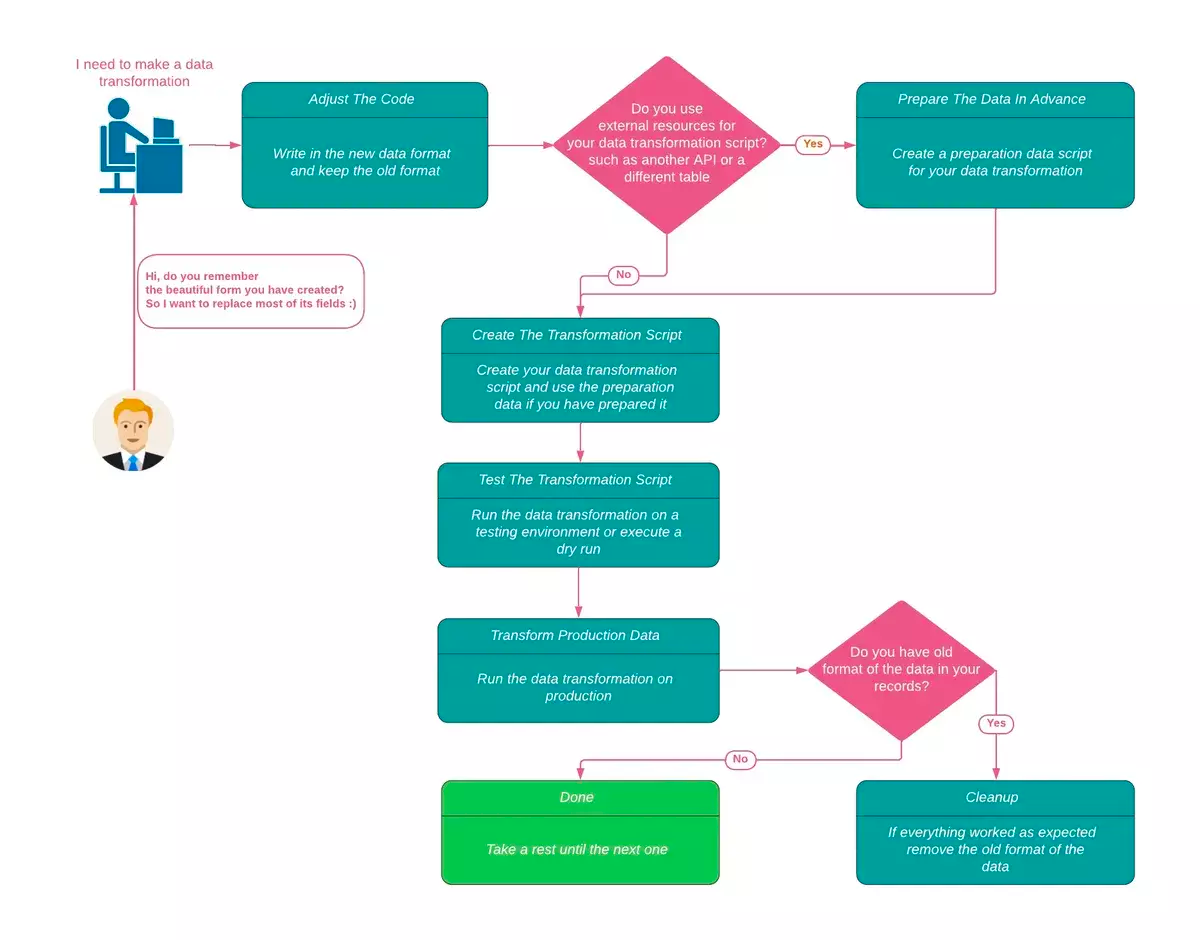
图 2 数据转换流程图
原文链接:
https://www.infoq.com/articles/dynamoDB-data-transformation-safety/




