
这家成立 4 周时就能凭借 7 页 PPT 融到超 1 亿美元的 AI 初创公司,究竟是什么来头?
AI 初创公司 Mistral 正寻求 3 亿美元新融资
据外媒报道,生成式 AI 初创公司 Mistral AI(常自称为“欧洲 OpenAI”)目前正寻求 3 亿美元新融资。如果一切顺利,那么新融资将帮助这家年轻企业估值突破 10 亿美元大关。
据了解,Mistral AI 总部位于法国巴黎,由来自 Meta Platforms 和 Alphabet 的几位前研究人员 Arthur Mensch(现任 CEO)、Guillaume Lample 和 Timothee Lacroix 共同创立,公司成立于 2023 年 5 月,专门开发大语言模型及各类 AI 技术。Mistral 这个名号来自北方寒冷的季风,也体现了他们想要在 AI 领域占据一席之地的愿望。

6 月,Mistral 在拿下 1.13 亿美元巨额种子融资后引发业界轰动,公司估值也瞬间来到 2.6 亿美元。彼时,该公司刚刚成立,员工仅 6 人,还未做出任何产品,仅仅凭借着 7 页 PPT 就斩获了巨额融资。
该轮融资由 Lightspeed Venture Partners 牵头,Redpoint、Index Ventures、Xavier Niel、德高控股以及意大利、德国、比利时和英国的其他知名风险投资公司参与。但该公司很快发现这“区区”1 亿美元根本不够,要推动后续增长和扩张计划还需要更多资金的支持。
据 The Information 近日报道,熟悉谈判内情的消息人士称,Mistral 正计划从投资者处额外筹集 3 亿美元,而此时距离由 Lightspeed Venture Partners 领投的种子轮融资才刚刚过去四个月。
目前还不清楚 Mistral 已经与哪些风险投资商进行过通气,但根据另一位知情人士透露,生成式 AI 投资领域的重要参与者 Andreessen Horowitz 正在积极寻求向开源大语言模型(LLM)开发者注资的机会。如果能够顺利合作,自然不失为一件美事。

Mistral 公司 CEO、前 DeepMind 研究科学家 Mensch 表示,这家企业的使命是“打造出能够解决现实世界问题的下一代 AI 系统”。他同时补充称,新一轮融资将用于扩大团队、加快研发工作,以及在欧洲和美国建立新的办事处。
Mistral 敢于开出如此夸张的融资数额,也体现出投资者对于 AI 初创企业不断增长的关注和信心。近年来,AI 初创公司已经筹得海量资金,其中不少企业正在开发前沿 AI 技术,有望彻底颠覆众多传统行业。
但目前 Mistral 仍在起步阶段,能否成为 AI 领域的主要参与者仍然有待观察。尽管如此,该公司强大的初始团队和雄心勃勃的发展目标,已经使其成为当前乃至未来几年中最值得关注的 AI 初创力量之一。
“最强 7B 开源模型”Mistral 7B
9 月 27 日,Mistral AI 团队发布了自家首个大模型 Mistral 7B,该模型号称是“最强 7B 开源模型”。
据介绍,Mistral 7B 是一套拥有 73 亿参数的大语言模型,采用 Apache 2.0 许可证,以不加限制的方式对外开放以供使用。在所有基准测试中,Mistral 7B 均优于 Llama 2 13B;在多种基准测试中,优于 Llama 1 34B;拥有比肩 CodeLlama 7B 的编码性能,并同时保持着良好的英语能力;使用分组查询注意力(GQA)来加快推理速度;使用滑动窗口注意力(SWA)以较低成本处理更长序列。
GitHub 链接:https://github.com/mistralai/mistral-src
HuggingFace 链接:https://huggingface.co/mistralai
Mistral 7B 基础设施集群由 CoreWeave 提供 24/7 全天候支持,CINECA/EuroHPC 团队及 Leonardo 运营团队提供资源与帮助,FlashAttention、vLLM、xFormers、Skypilot 维护团队提供新功能以及方案集成指导。HuggingFace、AWS、GCP、Azure ML 团队协助实现了 Mistral 7B 的全平台兼容。
Mistral 7B 还能针对任意任务进行轻松微调。Mistral AI 团队将 Mistral 7B 与 Llama 2 系列模型进行了比较,并重新运行了这些模型以验证评估结论是否准确。
Mistral 7B 及各 Llama 模型在不同基准测试中的性能。这里列出的所有指标,均从 Mistral AI 团队评估管道中的实际运行中采集而来,从而保证比较的真实性。Mistral 7B 在所有指标上均显著优于 Llama 2 13B,而且与 Llama 34B 基本相当(由于 Llama 2 34B 模型尚未发布,因此这里暂时与 Llama 34B 比较)。Mistral 7B 在编码与推理方面同样性能出众。
本轮基准测试按主题可分为以下几类:
常识推理: Hellaswag、Winogrande、PIQA、SIQA、OpenbookQA、ARC-Easy、ARCChallenge 和 CommonsenseQA 的 0-shot 平均值;
世界知识: NaturalQuestions 和 TriviaQA 的 5-shot 平均值;
阅读理解: BoolQ 和 QuAC 的 0-shot 平均值;
数学: mai@8 的 8-shot GSM8K 和 ma@4 的 4-shot MATH 的平均值;
编码: 0-shot Humaneval 和 3-shot MBPP 的平均值;
热门聚合结果: 5-shot MMLU、3-shot BBH 和 3-5-shot AGI Eval (仅限英文多项选择题)。

在对模型的成本/性能进行比较中,Mistral AI 团队提出了一个有趣的指标,即计算“等效模型大小”。在推理、理解与 STEM 推理(MMLU)方面,Mistral 7B 的性能与体量达到其 3 倍以上的 Llama 2 模型相当,意味着它能显著节约内存容量和数据吞吐量。
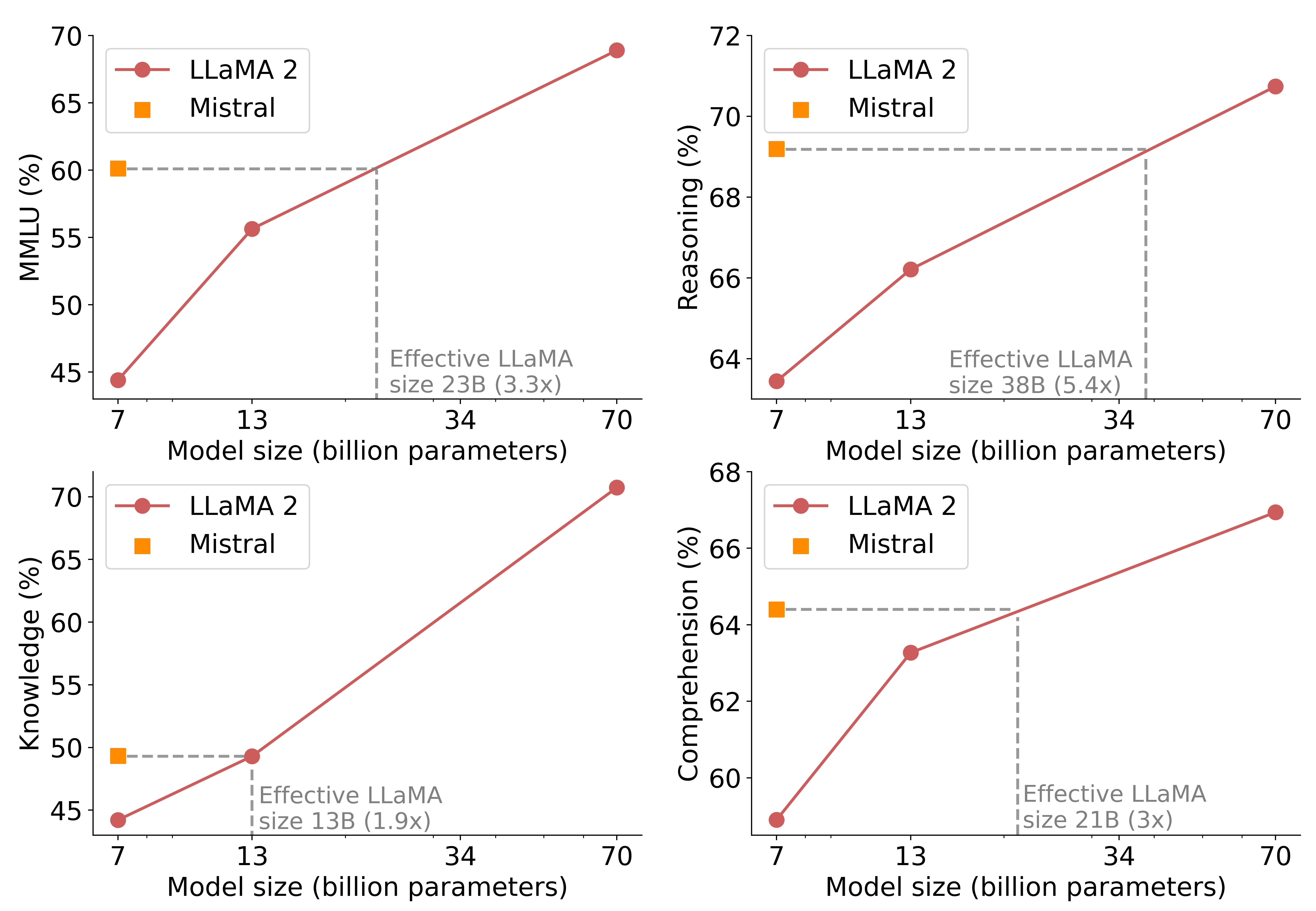
Mistral 7B 和 Llama 2(7B/13B/70B)的 MMLU 常识推理、世界知识与阅读理解比较结果。Mistral 7B 在绝大多数评估中均显著优于 Llama 2 13B,仅在知识基准测试中与后者处于同一水平(这可能是由于参数规模有限,因此掌握的知识量不足)。
注意:此次评估与 Llama 2 论文之间存在以下区别:
在 MBPP 测试中,这里使用了手工验证的子集。
在 TriviaQA 测试中,这里未提供维基百科上下文。
此外,Mistral 7B 使用滑动窗口注意力(SWA)机制,即每个层都关注之前的 4096 个隐藏状态。这里做出的主要改进以及尝试改进的原因,来自 O(sliding_window.seq_len) 的线性计算成本。具体来讲,在对 FlashAttention 和 xFormers 做出改进之后,成功在 16k 序列长度和 4k 上下文窗口下实现了速度倍增。Tri Dao 和 Daniel Haziza 为相关调整做出了贡献。
滑动窗口注意力的原理,是利用 Transformer 的堆叠层来关注此前超出窗口大小的情形:第 k 层的 token i 关注第 k-1 层的 token [i-sliding_window, i],后者又关注 [i-2*sliding_window, i]。如此一来,较高层就能访问到距离更“久远”的过往信息。
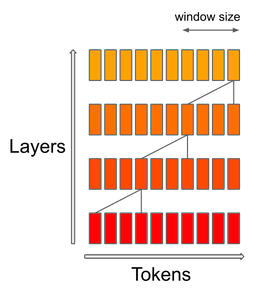
总之,采取固定注意力范围的最大意义,就是使用轮换缓冲区将缓存限制为 sliding_window token 的大小(更多细节请查看参考实现https://github.com/mistralai/mistral-src)。如此一来,同样在执行 8192 序列长度的推理时,可以节约下 50% 的高速缓存容量且不会影响模型质量。
为了展示 Mistral 7B 模型的泛化能力,研究团队使用 HuggingFace 上的公开指令数据集对其进行了微调。不用问题集“作弊”、也不涉及专有数据,由此产生的 Mistral 7B Instruct 模型在 MT-Bench 测试中获得了优于一切同体量 7B 模型的性能,表现可与 13B 聊天模型相比肩。

快速演示的 Mistral 7B Instruct 模型能够轻松微调,进而带来引人注目的卓越性能。其中不涉及任何协调机制。
参考链接:
https://www.theinformation.com/articles/mistral-a-wannabe-openai-of-europe-seeks-300-million




