
大多数程序员在日常开发中常常会碰到 GC 的问题:OOM 异常、GC 停顿等,这些异常直接导致糟糕的用户体验,如果不能得到及时处理,还会严重影响应用程序的性能。本系列从 GC 的基础入手,逐步帮助读者熟悉 GC 各种技术及问题根源。
GC 的由来
想当初,盘古开天辟地......
好吧,扯远了,这也不是仙侠小说...
GC 到底是怎么来的呢?这个问题要从 C 语言聊起, 大家都知道, C/C++语言在编写程序的时候, 需要码神们自己管理内存, 直观的说就是使用内存的时候要 malloc,之后这段内存会一直保留给程序进程,直到程序显式的调用 free 才会得以释放。
一个例子引发的问题
//第 0 步: char* aMem;//第 1 步:aMem = (char*) malloc(sizeof(char) * 1024);//第 2 步:strcpy(aMem, "I am a bunch of memory");//第 3 步:free(aMem);看到没有,就 3 步, 和把大象放进冰箱里一样:
打开冰箱门, 看看有没有空:用 malloc 申请空间。
把大象装进冰箱里:strcpy 把字符串拷贝到空间里。
关上冰箱门:不用的时候, free 还回内存 (严谨的说,这里应该是先把大象请出来, 腾出冰箱的空间,以备下一次能够再装大象)。
是不是很简单?需要的时候 malloc 申请内存,用完之后 free 释放内存。但实际上就这么简单的 3 行代码,可能会引发不少问题, 让我们 step by step 的看一下:
问题 1:如果上面第 0 步也变成 aMem = (char*) malloc(sizeof(char)), 这里直接执行 line 1, 有什么问题?
答: 内存泄漏,所有 malloc 申请的内存,必须要 free 释放之后才能再次被分配使用, 如果不 free,那么程序会一直占用这段内存,直到整个进程结束。虽然程序逻辑执行没有问题, 但是如果内存泄漏过多,很可能在后面的程序中出现内存不足的问题,产生各种未知错误。但是要注意的是,如果第 0 步用 malloc 分配了空间给 aMem,(假设地址是 aMem=0x1234),第 1 步这里的 malloc 同样分配了空间给 aMem,(假设这次 malloc 返回地址是 aMem=0x5678), 也就是说, 0x1234 指向的那段空间一直被占用,然后你的程序里却无法通过有效手段获得这个地址,也就没有办法再 free 它了。(因为 aMem 被修改成 0x5678 了)所以除非程序退出,不然我们再也没有机会释放这个 0x1234 指向的空间了。
问题 2:这里实际上申请了 1024 个 byte 的空间, 如果系统没有这么多空闲空间,有什么问题?
答:直接报错, 这个时候要调查一下是不是存在内存泄漏。问题 3:如果 copy 的字符串不是“I am a bunch of memory”, 而是“1,2,3,4 ... 1025" 会怎么样?答:由于 strcpy 不进行越界检查,这里第一步 malloc 出来的 1024 个字符, 却装载了 1026 个字符(包括'\0'), 也就是说内存被污染了, 这种情况轻的会导致内存溢出,如果被别有用心的人利用了, 可能就把你的程序所有信息 dump 出来...比如你的小秘密...问题 4:如果之前内存没有申请成功,第 3 步 free 会有什么问题?答:出错,如果 malloc 之前失败了,其实就是第二步出错了。假设没有第二步, malloc 失败之后,调用 free 程序会直接 crash。
问题 5:如果这里调用两次 free 会怎么样?
答: 同样会出错, 两次 free 会导致未知错误、或程序 crash。
问题 6:如果这里 free 之后, aMem 里面存的是什么值?
答:free 不会修改 aMem 的值,如果 malloc 之前返回 0x1234 给 aMem,那么这里 free 之后,aMEM 还是 0x1234。试想一下,如果后面还用 aMem 访问 0x1234 会有什么问题?
GC 的意义
有人可能会说:上面 6 个问题完全可以避免, 只要我能保证 malloc 和 free 用的对就行啦。如果现实真的这么美好,那就万事大吉了。可惜现实情况是更为复杂的程序, 比如 1000 行的代码里存在 if...else...、for /while 循环就会容易出现上面的问题。而且内存泄漏通常埋伏在你不知道的地方,慢慢积累,直到有一天产品的业务量达到一定程度后,服务进程就会突然崩溃。更可怕的是我们往往缺少有效的分析手段(或者高级的在线调试手段)来定位内存到底在哪里泄露了。
所以除了严格执行编程规范,还有别的办法可以减少 Memory leak 吗?一些大牛们想到了一个办法:程序员只负责分配和使用内存,由计算机负责识别需要 free 释放的内存,并且自动把这些不用的内存 free 掉。这样程序员只要 malloc/new,不需要 free/delete。 如果计算机能识别并且回收不用的内存(垃圾),那么一方面减少了代码量,另一方面也会避免内存泄漏的可能性,岂不美哉?这就是 Automatic Memory Management 概念的由来,也就是 GC 的由来。
现在大家应该明白 GC 的意义了吧,主要包括下面两方面:
一方面减少开发者的代码成本。开发者无需关心内存如何回收,可以减少思考程序内存使用逻辑的时间。
另一方面保证程序的正确性。没有了开发者的介入,减少了各种人为产生的内存泄漏和误 free 等问题,计算机更可以保证程序的正确性。程序就会更健壮, 也减少了运维人员半夜爬起来排障的机会。
GC 算法
下面我们来介绍 GC 里面各种牛闪闪的算法:Reference Counting,Mark Sweep,Concurrent Mark Sweep,Generational Concurrent Mark Sweep 等,这些算法其实可粗略的分为两大类:
一种是找到垃圾,回收之。
另一种是找到不是垃圾的对象,保留之。剩下的就作为垃圾对象,将它们回收掉。
由此而来,目前 GC 算法主要分为两类:Reference Counting(引用计数) 与 Object Tracing (对象追踪)。今天我们主要谈谈 Reference Counting。
Reference Counting
引用计数(Reference Counting)就是一种发现垃圾对象,并回收的算法。广义上讲,垃圾对象是指不再被程序访问的 Object,具体细分的话,“不再被程序访问的对象”实际上还要分成两类。来来来,让我们对 Object 进行一次灵魂拷问:你是什么样的垃圾?

不再被程序访问的 Object,具体可以细分为两大类:
1. 对象被还能被访问到, 但是程序以后不再用到它了。
举个例子:
public class A {private void method() { System.out.println("I am a method");}public static void main (String args[]) { A a1 = new A(); A a2 = new A(); a1.method(); // The following code has noting to do with a2 .... .... // a2.method();}}这个例子里面,a2 还能被访问到,但是程序后面也不会用到它了。从程序逻辑角度,这个 a2 指向的对象就是垃圾,但是从计算机的角度,这个垃圾“不够垃圾”。因为如果程序后面突然后悔了,想用 a2 这个对象了 (比如 code 里面最后一行注释), 程序还是可以正常访问到这个对象的。 所以从计算机的角度,a2 所指向的对象不是垃圾。看到这里,大家可能会疑问:编码时已经注释了 a2.method(),那么程序肯定不会运行这段代码, 这样的话,a2 引用的对象还是垃圾,为什么从计算机的角度来讲 a2 对象却不是垃圾?
实际上,我们有很多语言是支持动态代码修改的,比如 Java 的 Bytecode Instrument,完全可以在运行时插入 a2.method()的字节码,所以还是可以访问的。另外,这段代码的逻辑就是 a2 在函数栈上,a2 引用的对象在堆里,所以只要 a2 一直引用这个对象,这个对象对程序来说可见的,计算机不会认为它是垃圾,所以这种垃圾是不可回收物。
计算机: 我不要你觉得,我要我觉得!
2. 对象已经不能被访问了, 程序想用也没有办法找到它。
还是举个例子:
public class A {private void method() { System.out.println("I am a method");}public static void main (String args[]) { A a1 = new A(); A a2 = new A(); a1.method(); // The following code has noting to do with a2 .... .... a2 = a1;}}和前面例子几乎一致,只是最后我们把 a1 赋值给 a2。这里 a2 的值就变了,也就是说 a2 指向的对象变成了 a1 指向的对象,a2 原来的对象就没有别的东西引用它了,程序在此之后没有任何办法可以访问到它。所以它就变成了真正的垃圾。请看下图:
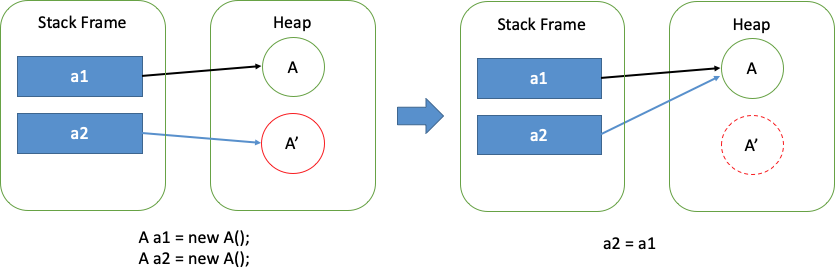
所以我们通常所讲的垃圾回收技术,也主要用来处理这种对象。那么问题来了, 如何找到这种对象呢? 按照刚才的思路,没有再被任何东西引用的对象,就是可回收垃圾,由此得出一个简单直观的回收算法:引用计数。
引用计数的概念, Wikipedia 的解释:
In computer science, reference counting is a programming technique of storing the number of references, pointers, or handles to a resource, such as an object, a block of memory, disk space, and others.
简单说来就是以下几点:
所有对象都存在一个记录引用计数的计数器,可能在对象里面,也可能单独的数据结构,总之是一种记录数据的地方。
所有对象在创建的时候(比如 new), 引用计数为 1。
当有别的变量或者对象对其进行引用,引用计数+1。
当有别的对象进行引用变更时,原先被引用的对象引用计数-1。
当引用计数为 0 的时候,回收对象
看不懂?没关系,上代码:
public class A {private void method() { System.out.println("I am a method");}public static void main (String args[]) { // 假设每个对象有一个引用计数变量rc A a1 = new A(); // 在堆上创建对象A, A.rc++; A a2 = new A(); // 在堆上创建对象A1,A1.rc++; a2 = a1; // A1.rc--,if ( A1.rc == 0 ) { 回收A1 }, A.rc++;} // 函数退出: // a1销毁, A.rc--; // a2销毁, A.rc--; // if ( A.rc == 0 ) { 回收A }}还没看懂?上图:
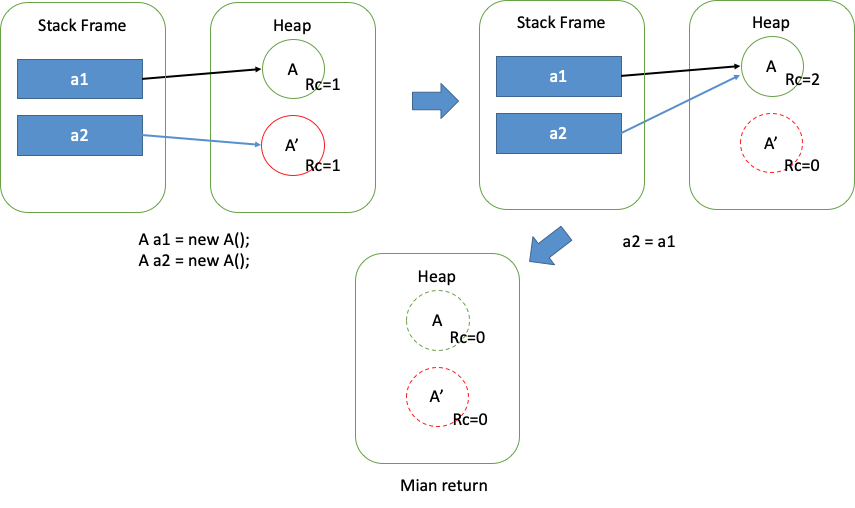
读到这里,你应该就明白 Reference Counting 的核心原理了。看起来很简单,只需要一个计数器和一些加减法就可以进行内存回收了。但是,Reference Counting 存在一个比较大的问题,也是我个人认为目前 Reference Counting 算法研究的核心问题:循环引用 。
循环引用
请看下面的伪代码:
class Parent { Child child;}class Child { Parent parent;}public class Main { public static void main (String[] args) { Parent p = new Parent(); Child c = new Child(); p.child = c; c.parent = p; }}图就是这样的:
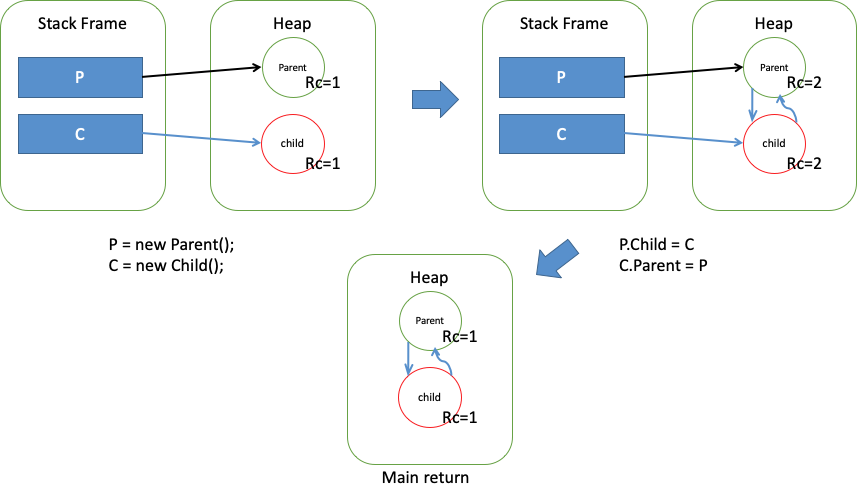
这个互相引用产生了环状引用, 引用计数器一致保持在 1, Object 无法被回收,造成了内存泄漏。可能你会问:不就是一个环,两个 Object 吗?这一点泄漏不是大问题,谁写代码不泄漏点内存。但是遇到下面这种情况呢?
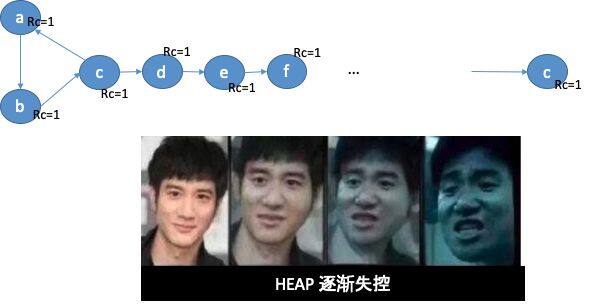
单单一个环,带了一个长长的小尾巴,导致整个链上的所有对象无法回收,Heap 内存逐渐失控,最终出现 OOM 异常,系统崩,代码卒。那么如何处理这个循环引用的问题呢?
破环之道
就如前面所说, Reference Counting 目前主要的研究课题都在破坏环形引用上。在我看来,目前主要是以下两种模式:
1. 左边跟我一起画条龙: 把问题抛给程序员
就是在程序设计语言层面提供一些办法,可以是 API、注解、新的关键字等等,然后把破环的能力交给程序员。比如 Swift 提供的 weak/unbound 关键字,包括 C++的 weak_ptr,相对于 strong 或者默认的引用,weak 在进行引用时不做引用计数的增减,而是判断所引用的对象是否已经被回收,这样所有构成环的引用都用 weak 来做引用,这样在计数器中,构成环的部分就不计数了。这样做的优缺点是:
优点:计算机不需要考虑环状问题,只要按照计数器进行对象回收就可以了。
缺点:程序员的意识直接决定了内存会不会溢出。如果程序员不使用 weak 关键字,那么有可能造成上述的内存泄漏。
2. 右边再划一道彩虹:把问题抛给计算机
这种办法就是让计算机自己找到方法去检测循环引用,一种常见的方法是配合 Tracing GC,找到没有被环以外的对象引用的环,把它们回收掉。关于 Tracing GC 咱们放到后续讨论。大家这里只要理解,为了帮助引用计数处理环形引用,计算机必须在适当的时候触发一个单独算法来找到环,然后再做处理。这样做的优缺点:
优点:程序员完全不需要介入,只需专注自己的业务实现。weak pointer、strong pointer 分不清楚也无所谓。
缺点:需要加入新的环形引用检测机制,算法复杂度,对于程序的影响都是问题。
说了这么多,咱们总结一下 Reference Counting 的优缺点:
优点:Reference Counting 算法设计简单,只需要在引用发生变化时进行计数就可以决定 Object 是否变成垃圾。并且可以随着对象的引用计数归零做到实时回收对象。所以 Reference Counting 是没有单独的 GC 阶段的,程序不会出现所谓的 GC stop the world 阶段。
缺点:程序在运行过程中会不断的生成对象,给对象成员变量赋值,改变对象变量等等。这所有的操作都需要引入一次++和--,程序性能必然受影响。(目前一种优化方法就是利用编译器优化技术,减少 Reference Counting 引入的计数问题,但也无法完全避免)。
处理环形引用问题,不论是交给程序员处理,还是交给计算机处理,都增加了程序的复杂度,还有可能会引入 GC stop the world phase,这些都会在一定程度上影响程序的性能和吞吐量。
好啦!今天就聊到这里吧,预知后事如何,且听下回分解!下次给大家分享另一类 GC 算法:Tracing GC,这也是目前应用比较广泛的一类算法。不论是 Javascript 的 V8、Android 的 ART、Java 的 Hotspot、OpenJ9,还是 Golang 的 GC,都采用了 Tracing GC 算法。
头图:Unsplash
作者:臧琳
原文:https://mp.weixin.qq.com/s/Qhu-Cpup4fobah6hsnGKpQ
原文: 趣谈 GC 技术,解密垃圾回收的玄学理论(一)
来源:腾讯云中间件 - 微信公众号 [ID:gh_6ea1bc2dd5fd]
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。




