
几个月前,Uber开始将其批处理数据分析和机器学习平台迁移到了谷歌云平台(GCP)上。最近,Uber 在其工程博客上发布了一篇文章,提供了更多将批处理数据平台迁移上云的信息,其中包含至关重要的数据网格原则。
Uber 的批处理数据平台是其数据基础设施的重要组成部分,有 1 万多名内部用户,其中包括数据科学家、工程师、城市运营人员和业务分析师。该系统管理着约 1.5 艾字节的数据(存储在Apache Hadoop分布式文件系统HDFS中),跨两个本地区域,每天处理超过 50 万次Presto查询和 37 万Apache Spark应用。为了提高可扩展性并简化运营,Uber 将其批处理数据平台迁移到了谷歌云 GCP。在本次迁移中,他们将谷歌云存储(GCS)作为 Uber 的数据湖,同时将其他基础设施迁移到基于云的基础设施即服务(IaaS)上。
在迁移上云的过程中,他们遇到了一些挑战,这主要是因为云提供商对于存储和身份与访问管理(IAM)有一些限制。Uber 主要考虑的问题之一是如何将 HDFS 文件有效地映射到 GCS 存储桶,同时又避免过度使用或未充分利用可用的资源。此外,Uber 必须在多级存储结构中适当应用访问控制,以确保系统安全,同时又避免不必要地提升用户权限。这次迁移也提供了一个机会,让他们可以通过合并安全组和分散数据所有权来增强系统。在新模式下,属于特定组织的数据将存储在特定组织的存储桶中,数据所有权和访问控制变得更清晰。
在整个迁移过程中,安全和治理一直都是核心问题。他们的目标是根据数据的预期用途和生命周期来映射数据,并对其进行分类,以保证可以应用恰当的访问控制。组织内部广泛使用的关键数据集存储在开放访问的专用数据桶中,而不太重要的数据则单独存储,并施加访问限制和生命周期管理策略。此外,迁移还实现了基础设施的自动设置,可以加快测试、准生产和生产环境的准备。这种自动化有助于加快新数据分析用例的应用,并利用多个区域为灾难恢复场景做好了准备。
为了推动这一巨大转变,Uber 开发了一项名为 DataMesh 的服务,旨在抽象和管理云基础设施。DataMesh 遵循数据网格原则来组织数据资源,重点关注数据所有权去中心化和领域控制。该服务可以利用云资源自动校正(reconciliation)数据。它从 Uber 的内部存储库中提取信息,并保证数据被恰当地标记、保护和监控。DataMesh 平台还能管理 HDFS 路径到对应云路径的映射,尽可能地使用户实现无缝迁移,并防止中断现有工作流程。
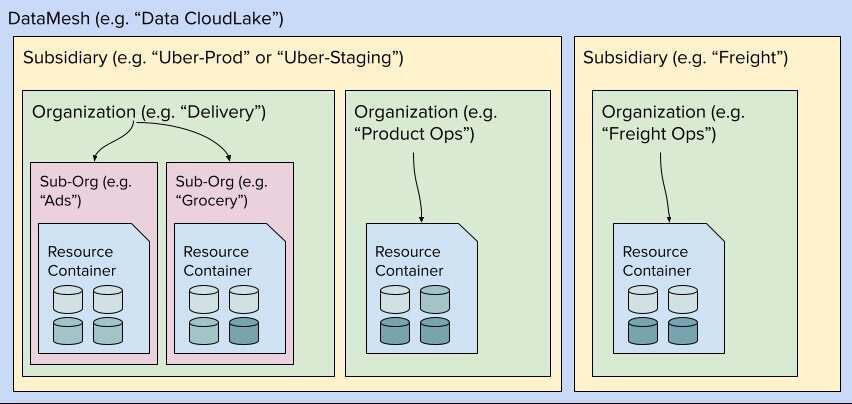
DataMesh 组件和层次结构的逻辑视图
在迁移过程中,Uber 面临的一个重大挑战是:需要适应数据所有权的变化和 GCS 设置的限制。由于团队重组或用户资产重新分配,所以数据所有权可能会发生变化。为了解决这个问题,Uber 实现了一个自动化流程,用于监控并在必要时重新分配所有权,确保数据的安全存储和管理。此外,为了避免达到 GCS 存储限制,Uber 还优化了数据分布,将大量使用的表分离到各自的数据桶中,从而提高性能并简化监控。
以下是现实世界中其他实现数据网格的例子:
Gilead Sciences:这是一家生物制药公司。他们开发了数据网格架构,目的是创建一个以数据为支撑的组织与运营新模式,使他们公司能够参与到云转型中。数据网格方法使得该公司能够将数据作为产品进行管理,并采用云优先的架构。
Saxo Bank:这是一家金融服务公司。他们在一个项目中实现了数据网格,旨在分散数据所有权和管理权,使领域团队能够管理他们自己的数据产品并为业务提供实时洞察。
展望未来,Uber 的目标是通过构建一个提供自治数据域的平台,进一步扩大数据网格原则的使用范围。这将简化基础设施管理并强化数据治理,最终将可以创建一个更加灵活、安全和经济高效的数据生态系统。Uber 批处理数据平台迁移上云是一项非常重大的工程,但通过精心策划并开发 DataMesh 等创新工具,Uber 正在云中获得更高的可扩展性、安全性和运营效率。
原文链接:




