
背景介绍
1. 现状

众所周知,业界各种大中型软件系统在生产运行时,总会有一些手段来进行保驾护航。如上图所示,Metric 机制作为一个非常重要的监控手段,与日志系统,告警系统,APM 等,共同守护业务系统运行安全。没有“运行时监控机制”的软件系统都是不合格的系统,是根本没有资格上到生产环境上去的,因为掌握不了软件系统的运行状况,就像一个瞎子开着汽车上路了,是极其危险的。Metric 机制承担着收集软件系统各种监控指标的职责,提供的各个监控指标能够帮助运维人员进行系统运行状态的研判,配合告警系统及时进行预警,在出现异常情况的时候,给日志分析团队指明“问题查找”的方向。总之,Metric 的重要程度非常高,可以认为是不可或缺的非功能性需求。
2. 痛点
在日常的软件项目开发测试过程中,由于监控设施不完备所带来的问题非常的明显,特别是在对组件进行“性能测试”的时候尤为突出,导致在性能测试过程中,需要查看的性能指标如 TPS,Latency,并发,吞吐等一些关键指标根本无从读取,特别是遇到“性能瓶颈”的时候,根本不知道去进行问题定位和性能优化的方向是什么,慌乱之下迫于压力就开始病急乱投医,时常舍本逐末,采用一些野路子(如手工日志打点,借助其他的性能分析工具,人肉统计等)来临时救场,最后的结果就是事倍功半,解决问题不在点上,吃力不讨好。
另外一个问题就是有些组件有配置一些对应的监控指标,但是风格格式,展示方式都不尽相同,无法针对组件特点进行合理的统一化 GUI 展示;不统一的结果就是“各自为政”,五花八门,抓不住关注的重点。如果我们的 Metrics 机制是完备的,开发和测试过程中很多的问题都可以轻松应对,各种推诿扯皮都可以迎刃而解,工作起来就自然轻松。
3. 原因分析
细节是魔鬼。以上问题的根源,在于很多的软件研发团队在“最后一公里”没有准备好,尽管我们在系统架构层面都一些 Solution,但是落实的情况不理想,没有构建起来一个完善可控的监控系统。但是又是什么原因导致了我们做不好这件事情呢?不外乎下面的几个原因
涉及的技术栈比较长,有一定的学习成本
以目前采用的 Micrometer + Prometheus + Grafana 的监控方案为例,一套完整的监控系统涉及到规划,埋点,采集,传输,存储,展示等各个环节,需要对整个方案有全局性的理解,特别是对 Prometheus 的一些基本的“时序运算函数”需要有正确的理解,才能够实现对展示指标的灵活定制和自主可控。同时需要能够正确对各个开源软件进行操作和配置,确实存在一定的学习成本。
相关依赖太重
目前 DevOps 的体制下,想去构建一套能够 RUN 起来的监控系统,是一件复杂的事情,需要找很多的相关 team 的同事去申请资源,开通各种账号和访问权限,在各种系统上提交不同的 ticket,各种各样的协调和沟通在所难免,总之需要依赖很多的其他资源,通常的情况下就是事情还没走完一半,热情已经被浇灭了一半,除非被 KPI 考核,否则很难有继续推动下去的动力。
人的惰性
人都是有惰性的,当能够从别的地方 Copy & Paste 过来一个 Metrics 面板,能够临时应付,基本就不会去深入研究其中的一些细节了。比方面板中用到了哪些 PromSql 表达式,各种函数的意义是什么,如何基于该面板进行客制化。久而久之,就停留在这个浅尝则止的初级层面了,丧失了去深入学习的能力了。
目的和范围
1. 目的
本文的目的是“系统性”阐述构建一个可用的 metrics 监控系统所需要掌握的完整的理论知识,方法,基础工具软件的配置和使用,一起搞懂一些常用的 PromSql 函数的含义和正确打开的方式。在掌握了这些基本的知识技能之后,按照文末的实操步骤,任何人都可以在自己的工作电脑上花费不超过 15 分钟的时间将一个完整可以用,并且满足主流微服务组件核心指标监控的 Dashboard 给运行起来,并且进行 GUI 展示和测试。
本文的终极目标是希望能够和大家一起对 metrics 方案的构建进行一次比较系统性的梳理和回顾,从理论到实践,帮助大家扫清一些技术和流程方面的障碍,希望能够起到抛砖引玉的作用。希望读完此文后,大家能够在构建 metrics 系统的时候不再嫌麻烦,怕困难,能够做到了然于胸,理解原理,懂得实操,心情舒畅。本文没有介绍任何的高深知识,所有的资料来源都可以在互联网上找到,基于这些基础的材料,本文叙述尽力做到通俗易懂,目的明确,条理清晰,逻辑严谨,铺陈有序,干货满满。
2. 范围和限制
本文聚焦于微服务的 Metrics 方案,重点关注的是基于 HTTP 的请求和回应建立的指标监控系统,我们把这些核心监控指标统称为“通用的 Metrics”。以下的资源对象的监控不是本文描述的重点,因为这些监控基本都可以通过三方的 exporter 来构建。
Database
缓存(Redis)
MQ (Kafka)
Filesystem
VM
Kubernetes runtime
理论和方法
1. 微服务的特点
本文前面部分非常地小心进行铺垫,就是想尽量圈小想涉及的知识范围,控制冲动,因为一旦有了想将所有细节囊括其中的想法,注定了难逃烂尾的结局,最终会变成一堆裹脚布。
所以,我们只以“微服务组件”为切入点,看看如何基于微服务的特点去构建合理的 Metrics 监控系统。从监控的角度来看,微服务有以下的几个显著的特点:
大部分基于 HTTP 协议:采集指标基于 HTTP 协议特点进行埋点
实例是可以扩展的:采集的监控指标数据可以基于多实例进行聚合运算
每个采集指标都可以设置对应的 label 信息:采集指标可以基于 Label 进行过滤
2. 监控原则
一般来讲,作为监控软件厂商,如 Prometheus,它是会鼓励你监控所有东西的,指标越多越好。生态链位决定立场,可以理解。但是我们作为商业软件开发团队,监控系统是“基础设施”,是“非功能性”需求,目的是为了解决问题,不要只朝着大而全去做,尤其是不必要的指标采集,浪费人力和存储资源(除非有商业上的合理性)。
对于监控系统的建设,可以遵循如下的几个原则:
只关注重要的 Metrics 指标(大板展示)
需要处理的告警才发出来,发出来的告警必须得到处理
尽量做得简单和高可用,业务系统都挂了,监控也不能挂
本文重点对第一个原则进行论述,其他的不展开。那么,一个基于微服务的系统,需要监控哪些指标是合理的呢?目前业务普遍采用的方法是遵循 Google 的“黄金四信号”(Four Golden Signals)方法来定制业务系统的监控面板。
3. Four Golden Signals
Four Golden Signals 是 Google 在“SRE Handbook”中提出的一个理论,建议业务团队在构建监控系统的时候有限关注“四个黄金信号”:延迟、流量、错误数、饱和度。Four Golden Signals 是 Google 针对大量分布式监控的经验总结,4 个黄金指标可以在服务级别帮助衡量终端用户体验、服务中断、业务影响等层面的问题。
延迟:服务请求所需时间。
记录用户所有请求所需的时间,重点是要区分成功请求的延迟时间和失败请求的延迟时间。 例如在数据库或者其他关键端服务异常触发 HTTP 500 的情况下,用户也可能会很快得到请求失败的响应内容,如果不加区分计算这些请求的延迟,可能导致计算结果与实际结果产生巨大的差异。除此以外,在微服务中通常提倡“快速失败”,开发人员需要特别注意这些延迟较大的错误,因为这些缓慢的错误会明显影响系统的性能,因此追踪这些错误的延迟也是非常重要的。
流量:监控当前系统的通信流量,用于衡量服务的容量需求。
流量对于不同类型的系统而言可能代表不同的含义。例如,在 HTTP REST API 中,流量通常是每秒 HTTP 请求数;
错误:监控当前系统所有发生的错误请求,衡量当前系统错误发生的速率。
对于失败而言有些是显式的(比如,HTTP 500 错误),而有些是隐式(比如,HTTP 响应 200,但实际业务流程依然是失败的)。
对于一些显式的错误如 HTTP 500 可以通过在负载均衡器(如 Nginx)上进行捕获,而对于一些系统内部的异常,则可能需要直接从服务中添加钩子统计并进行获取。
饱和度:衡量当前服务的饱和度。
主要强调最能影响服务状态的受限制的资源。 例如,如果系统主要受内存影响,那就主要关注系统的内存状态,如果系统主要受限与磁盘 I/O,那就主要观测磁盘 I/O 的状态。因为通常情况下,当这些资源达到饱和后,服务的性能会明显下降。同时还可以利用饱和度对系统做出预测,比如,“磁盘是否可能在 4 个小时候就满了”。
4. Metrics 监控方案
1) 实现原理
一个完整的监控系统,一般需要涵盖如下几个环节的建设:指标规划,埋点采集,爬取和传输,存储,计算,展示等。监控系统稳定运行之后,同时可以基于监控数据构建告警系统,也可在系统出现问题的时候第一时间为问题排查团队提供解决问题的方向。
我们采用业界主流的 Prometheus + Grafana 为基础框架来构建自己的监控系统。核心架构如下图所示:
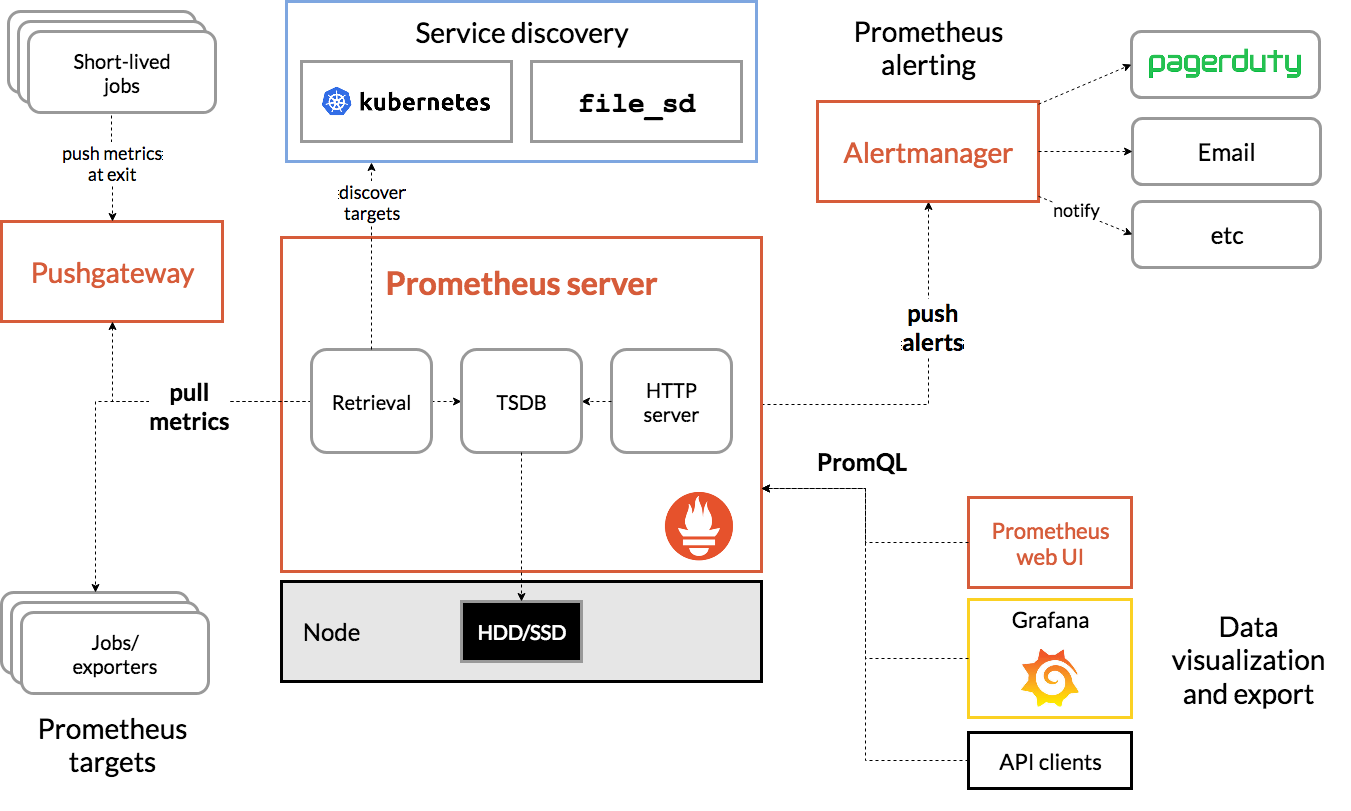
因为我们的微服务一般是采用的 Springboot2.0 以上的版本进行开发的,这个版本以上的 Springboot 已经将 Prometheus 的监控指标的“埋点和采集”等功能都无缝集成到了 starter 中了,所以开发人员几乎可以做到“不写一行代码(零编码)”就将一套满足业务需求的监控系统给构建起来,非常方便,这个在后面的实操部分也有介绍的。所以如果你了解到了这些,就会发现其实我们搭建 Metrics 系统也不是很复杂的事情。如下图所示:
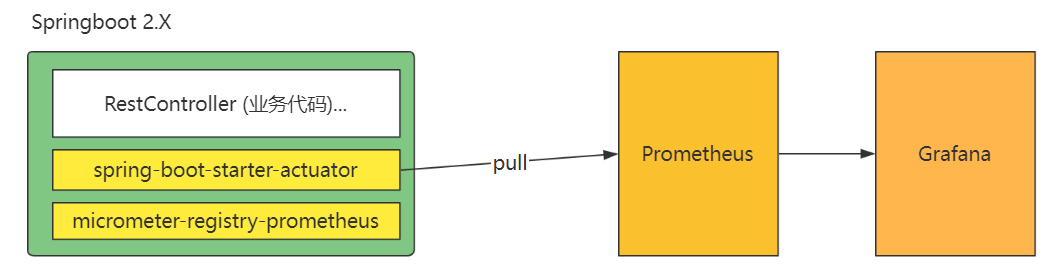
Springboot 项目中只需要将下面的两个 maven 依赖包引入到项目中,不需要写一行代码,就可以轻松实现和 Prometheus 的无缝集成。
micrometer-registry-prometheus
负责自动产生符合 Prometheus metrics 格式的所有指标样本。这些指标样本的设计都很巧妙,基本可以满足大部分的 HTTP 协议业务请求的监控功能。默认方式下会缓存在本地。
spring-boot-starter-actuator
负责暴露一个 endpoint 给到 Prometheus,Prometheus 会启动一个 Job 线程,定期到这个 endpoint 将 metrics 数据爬取回来进行处理。
可以看到,micrometer-registry-prometheus 其实已经帮我们把采集指标规划,埋点的工作做完了,spring-boot-starter-actuator 通过和 Prometheus 爬取 Job 的配合,将数据的传输,和存储,计算工作也完成了,最后,Grafana 完成了数据的展示工作。其实整个过程,代码开发量约等于 0。只需要进行几行简单的配置即可。
这里需要重点关注的是 micrometer-registry-prometheus 为我们自动生成的 HTTP 的 metrics 指标数据,整个设计非常巧妙,这块在后面的章节会单独介绍。这些设计精巧的监控指标将作为数据样本被 Prometheus 采集到,然后进行一些内部函数的运算及一些聚合操作处理,最终就产出了满足我们需求的各种监控面板。
具体的实现原理,我们继续往下看。
2) 样本格式
Prometheus Server 运行起来之后,自动拉起配置好的 Job 任务,去到指定的 endpoint 去 pull 数据,这些被爬取到的数据统称为“样本”。样本由以下三部分组成:
指标(metric):metric name 和描述当前样本特征的 labelsets;
时间戳(timestamp):一个精确到毫秒的时间戳;
值(value):表示该时间的样本的值。
<--------------- metric ---------------------><-timestamp -><-value->http_request_total{status="200", method="GET"}@1434417560938 => 94355http_request_total{status="200", method="GET"}@1434417561287 => 94334http_request_total{status="404", method="GET"}@1434417560938 => 38473http_request_total{status="404", method="GET"}@1434417561287 => 38544http_request_total{status="200", method="POST"}@1434417560938 => 4748http_request_total{status="200", method="POST"}@1434417561287 => 47853) 指标类型
Prometheus 根据目标功能和内容的不同,把指标分了 4 种类型(metric type):Counter(计数器)、Gauge(仪表盘)、Histogram(累积直方图)、Summary(摘要);但是本质上都是指标,都是时间序列,只是进行了简单的分类,更方便理解和沟通。可以通过“聚合操作”和“内置函数”对采集到的指标数据进行操作。
Counter:只增不减的计数器
Counter 类型的指标其工作方式和计数器一样,只增不减(除非系统发生重置)。常见的监控指标,如 http_requests_total,node_cpu 都是 Counter 类型的监控指标。Counter 是一个简单但有强大的工具,例如我们可以在应用程序中记录某些事件发生的次数,通过以时序的形式存储这些数据,我们可以轻松的了解该事件产生速率的变化。PromSql 内置的聚合函数可以用户对这些数据进行进一步的分析。

例如:
通过 rate()函数获取 HTTP 请求量的增长率:
rate(http_requests_total[5m])查询当前系统中,访问量前 10 的 HTTP 地址:
topk(10, http_requests_total)一般而言,counter 数值本身所产生的意义不是很大,实际使用中多是通过 counter 数据来进行 rate 计算变化率,增长率。(问题,如果 counter 采集到的数据,突然变小了会怎么样?)
Gauge:可增可减的仪表盘,用于采集瞬时数据
与 Counter 不同,Gauge 类型的指标侧重于反应系统的当前状态。因此这类指标的样本数据可增可减。常见指标如:node_memory_MemFree(主机当前空闲的内容大小)、node_memory_MemAvailable(可用内存大小)都是 Gauge 类型的监控指标。

还可以直接使用 predict_linear() 对数据的变化趋势进行预测。例如,预测系统磁盘空间在 4 个小时之后的剩余情况:这个函数是用来做预测的,predict_linear()这个函数对于磁盘空间来说的话是非常有用的,因为磁盘在实际使用的过程当中一下子就增长起来了,这是一个缓慢的过程,所以可以根据这个函数来判断 4 个小时之后磁盘剩余的情况,根据这个情况就可以提前去将磁盘空间清理或者扩容。
predict_linear(node_filesystem_free_bytes[1h], 4 * 3600)Histogram 和 Summary:主用用于统计和分析样本的分布情况。
在大多数情况下人们都倾向于使用某些量化指标的平均值,例如 CPU 的平均使用率、页面的平均响应时间,这种方式也有很明显的问题,以系统 API 调用的平均响应时间为例:如果大多数 API 请求都维持在 100ms 的响应时间范围内,而个别请求的响应时间需要 5s,那么就会导致某些 WEB 页面的响应时间落到中位数上,而这种现象被称为长尾问题。
为了区分是平均的慢还是长尾的慢,最简单的方式就是按照请求延迟的范围进行分组。例如,统计延迟在 0~10ms 之间的请求数有多少而 10~20ms 之间的请求数又有多少。通过这种方式可以快速分析系统慢的原因。
Histogram 和 Summary 都是为了能够解决这样的问题存在的,通过 Histogram 和 Summary 类型的监控指标,我们可以快速了解监控样本的分布情况。
Summary
摘要用于记录某些东西的平均大小,可能是计算所需的时间或处理的文件大小,摘要显示两个相关的信息:count(事件发生的次数)和 sum(所有事件的总大小),如下图计算摘要指标可以返回次数为 3 和总和 15,也就意味着 3 次计算总共需要 15s 来处理,平均每次计算需要花费 5s。下一个样本的次数为 10,总和为 113,那么平均值为 11.3,因为两组指标都记录有时间戳,所以我们可以使用摘要来构建一个图表,显示平均值的变化率,比如图上的语句表示的是 5 分钟时间段内的平均速率

Histogram
摘要非常有用,但是平均值会隐藏一些细节,上图中 10 与 113 的总和包含非常广的范围,如果我们想查看时间花在什么地方了,那么我们就需要直方图了。
直方图以 bucket 桶的形式记录数据,所以我们可能有一个桶用于需要 1s 或更少的计算,另一个桶用于 5 秒或更少、10 秒或更少、20 秒或更少、60 秒或更少。该指标返回每个存储桶的计数,其中 3 个在 5 秒或更短的时间内完成,6 个在 10 秒或更短的时间内完成。
Prometheus 中的直方图是累积的,因此所有 10 次计算都属于 60 秒或更少的时间段,而在这 10 次中,有 9 次的处理时间为 20 秒或更少,这显示了数据的分布。所以可以看到我们的大部分计算都在 10 秒以下,只有一个超过 20 秒,这对于计算百分位数很有用。
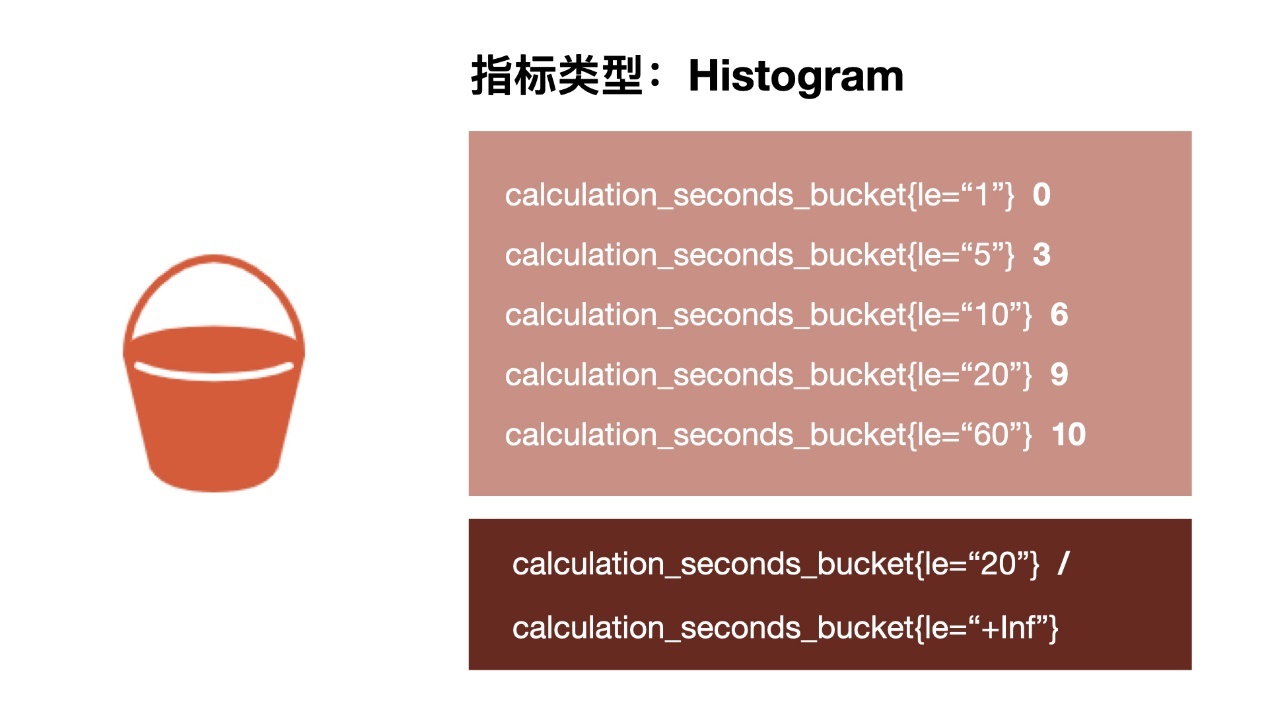
Histogram 和 Summary 的区别
Summary 的分位数是直接在客户端计算完成的,histogram 则在服务端完成
histogram 存储的是区间的样本数统计值,不能得到精确的分为数,而 Summary 可以**。**
如果需要聚合(aggregate),选择 histograms。
如果比较清楚要观测的指标的范围和分布情况,选择 histograms。如果需要精确的分位数选择 summary。
4) 内置函数与聚合操作
这里列一下 Prometheus 中常用的一些内置函数,但是其实我们真正需要彻底搞懂原理,懂得运用的只有一个,那就是 rate()。后面会有重点介绍。
absent() #取布尔值abs() #绝对值sqrt() #平方根ceil() #向上取整floor() #向下取整changes() #显示变更次数round() #四舍五入取整clamp_max() #当大于最大值时,则为最大值clamp_min() #当小于最小值时,则为最小值lable_join() #新增标签lable_replace() #替换标签predict_linear() #基于一段时间内的增长值来预测多久后会溢出rate() #计算区间向量里的平均增长率irate() #计算区间向量内最新和最后的瞬时向量的增长率sort() #升序排序sort_desc() #降序排序delta() #计算区间向量里最大最小的差值increase() #计算区间向量里最后一个值和第一个值的差值常用的一些聚合操作函数也列一下,同样需要理解和掌握的只有** sum, avg**,后面会重点介绍,其他的基本可以触类旁通,忽略就行。
sum: #求和。min: #最小值。max: #最大值avg: #平均值stddev: #标准差stdvar: #方差count: #元素个数count_values: #等于某值的元素个数bottomk: #最小的k个元素topk: #最大的k个元素quantile: #分位数如果在实际开发中,想深入了解一些高级用法,建议直接去阅读官方文档,一手资料最为权威和详实。
5) 重点公式
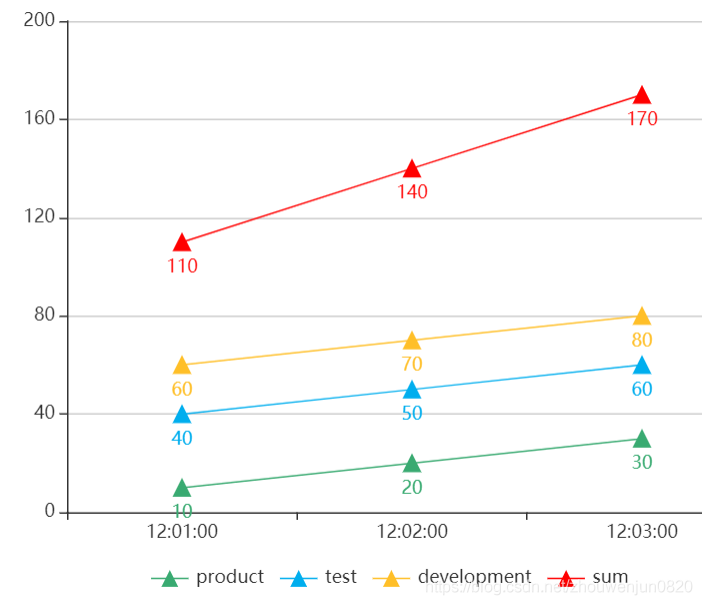
SUM() 操作的理解误区:
不要误认为 sum 是求指标在某个时间段的和。
查询可能会返回多条满足指定标签的时间序列,可是有时候我们并不希望分开查看,恰恰大多数情况其实是想查询一条时间序列的结果,例如查询请求总数时想要的结果是:
http_requests_total{} 170而并不是想要:
http_requests_total{environment="product"} 30 http_requests_total{environment="test"} 60 http_requests_total{environment="developement"} 80为了实现这个需求,PromSql 提供的聚合操作可以用来对这些时间序列进行处理,通过处理形成一条新的时间序列,上述需求的表达式应该是:sum(http_requests_total),例如下图会自动将所有时间序列的值相加后形成一条新的时间序列作为结果。
RATE() 函数的理解
官方文档的介绍是:计算范围向量中时间序列每秒的平均增长速率,通俗的讲,就是“一段时间内平均每秒的增量”。描述它的算法实现就是:范围向量的差值/持续时长。采用官方提供的一个用来辅助说明的表达式如下:
rate(http_requests_total{status="200", method="GET"}[5m])假定其在最近 5M 之内采样数据如下:
<--------------- metric ---------------------><-timestamp -><-value-> http_request_total{status="200", method="GET"}@1434417560938 => 10 http_request_total{status="200", method="GET"}@1434417561287 => 200 ……… http_request_total{status="200", method="POST"}@1434417560938 => 389 http_request_total{status="200", method="POST"}@1434417561287 => 510那么这个 rate()表达式的计算结果 = (510 – 10) / (5 * 60) = 1.667
但是需要注意的是一般来讲,rate 值很少是绝对精确的。由于针对不同目标的抓取发生在不同的时间,因此随着时间的流逝会发生抖动,计算时很少会与抓取时间完美匹配,并且抓取有可能失败。rate 计算出来的数据,都会比我们按照它的算法公式直接结算出来的稍微大那么一丢丢,因为 Prometheus 会默认在分母那里乘一个 1.X 的系数。
rate 函数的用途非常广泛,可以说是在 Grafana 配置的时候使用最多的一个函数,包括我们接下来需要使用到的 Latency 和 TPS 之类的核心监控指标,都是需要通过 rate 函数的计算之后,才能够展现在监控面板上的。那么,究竟是如何实现的呢?这里先卖一个关子,等到下一个章节的知识点介绍完了,你就会茅塞顿开,恍然大悟!
PXX() 分位图函数的反直觉
分位数统计是 Prometheus 常用的一个功能,比如经常把某个服务的 P95 响应时间来衡量服务质量。它到底是什么意思呢?和平均数(中位数)又有何关系呢?
比方说,我们算出来的 P95 平均响应延迟是 100ms,实际上是指对于收集到的所有响应延迟,有 5%的请求大于 100ms,95%的请求小于 100ms。Prometheus 里面的 histogram_quantile 函数接收的是 0-1 之间的小数,将这个小数乘以 100 就能很容易得到对应的百分位数,比如 0.95 就对应着 P95,而且还可以高于百分位数的精度,比如 0.9999。
当我们用分位图数据绘制响应时间的趋势图时,可能经常会被问:为什么 P95 大于或小于我的平均值(或者中位数)?
正如中位数可能比平均数大也可能比平均数小,P99 比平均值小也是完全有可能的。通常情况下 P99 几乎总是比平均值要大的,但是如果数据分布比较极端,最大的 1%可能大得离谱从而拉高了平均值。一种可能的例子:
1, 1, ... 1, 901 // 共 100 条数据,平均值=10,P99=1类似的疑问很多。其实,对于分位数统计结果,记住一个结论就可以了:分位数统计结果和平均数,中位数都无必然的关联关系,也没有比较的意义。分位数的统计学意义在于描述数值的分布区间情况。所以,分位数无论大于或者小于平均数(中位数)都是合理的!
自此,如果你理解了这三个函数的原理,那么恭喜你,你已经可以处理大部分我们常用到的 Metrics 指标了。同样,本文的后面章节也只需要用到这点知识就可以了。是不是挺简单的呢?
6) 默认指标
前面章节已经介绍过了,通过引入 micrometer 和 actuator 两个依赖库,就已经会默认自动生成一些 metrics 数据了,并且这些 metrics 数据针对 HTTP 业务而言,是足够的了,大部分的监控数据可以基于这些默认的 metrics 通过各种运算生产出来。
通过访问微服务通过 actuator 暴露出的一个专门为 Prometheus 爬取数据所用到的 endpoint:localhost:8080/actuator/prometheus 可以看到默认产生的 metrics 数据长下面的样子:
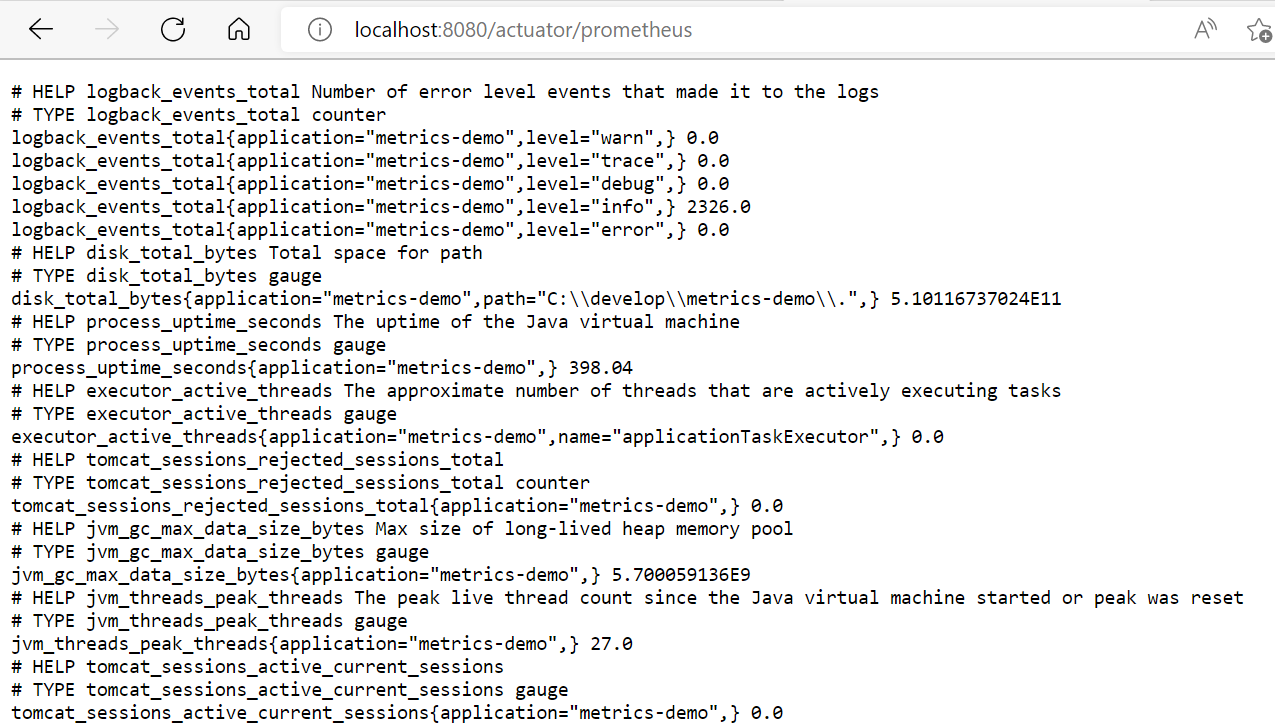
之前在样本格式这个章节已经介绍过了,每个样本数据都是一条包含了“[metrics-timestamp-value]”三部分关键信息的记录,所以上面的数据就可以理解了,全部都是符合这个格式规范的。在所有的默认采集样本中,我们只需要彻底理解两条就够了,因为基于这两条样本数据,结合前面介绍过的**rate()和 count()**算法,就可以把几乎所有的 HTTP 微服务相关的监控面板给配置出来。同时,理解了这两条数据后,其他的数据也可以做到触类旁通。
两个重要的重要的监控指标:
http_server_requests_seconds_count:从上次服务重启到现在所有的 HTTP 的请求数量
http_server_requests_seconds_sum:从上次服务重启到现在所有的 HTTP 的请求的耗时时长,单位是秒
基于这两个非常基础但是非常重要的监控指标,我们利用 Prometheus 提供的函数就可以非常方便地得到我们需要的监控信息了。
a) 比方,TPS/RPS/OPS 数据(AVG 数据),可以采用下面的方式计算得到:
rate(http_server_requests_seconds_count [5m])b) 过去一段时间内的平均处理时间可以使用如下的方式计算得到:
increase(http_server_requests_seconds_sum [5m])/increase(http_server_requests_seconds_count [5m])c) 我们用平时用的最多的 HTTP 平均响应时间(RT):
rate(http_server_requests_seconds_count [$__rate_interval])/rate(http_server_requests_seconds_count [$__rate_interval])*10007) 客制化指标
需要注意的是,另外一个常用的监控指标“平均响应时间分位图“,即俗称的 PXX 分布图,micrometer 默认是不提供的,需要开发者自行添加几行代码才能够显示出来。可以参考后面提供的 Demo 代码
如果不想通过默认的 tomcat 的线程并发数来监控线程并发指标,可以可以拦截器的方式来实现客制化,参考后面的 HTTP BUSY SESSION 面板
关于对“系统级别资源”的监控大板展示,建议选用 4701 号公共模板资源
关于客制化 metrics 的开发方面,基本所有的问题都可以在网络在很方便地找到对应的答案,没啥高深的东西
到此,我们对理论,方法及知识点的系统性梳理已经结束了。基于我们掌握的知识,按照下文的实操步骤,任何人,不管会不会写代码,都可以在不超过 15 分钟的时间内在自己的机器上搭建一套基本完整的监控系统对微服务业务组件进行监控。
Let's try it! 😊
落地实操
1. 实操方案
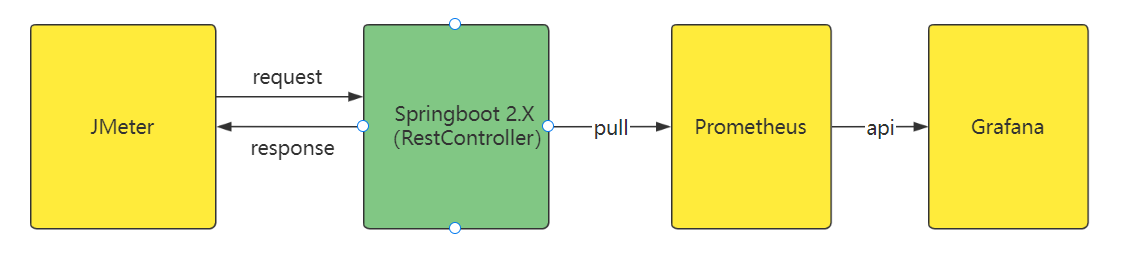
本文设计的实操例子如上图所示,操作步骤如下:
本地运行 Springboot 服务程序代码,代码集成 micrometer 和 actuator.模拟业务组件。
本地机器下载和安装好单机版的 Prometheus 程序
本地机器下载和安装好单机版的 Grafana 程序
本地机器下载和安装好单机版的 Apache JMeter 程序,用于模拟产生 HTTP 并发请求
监控面板上要展示什么呢?按照前面提及的“黄金四信号”,我们本地的测试例子准备将如下的信息通过监控面板展示出来,这些指标对于我们日常微服务组件的运维监控,性能测试,问题排查等都非常重要。
流量指标:OSP/RPS:
响应延迟指:Average Response Time Latency, PXX RT Latency
错误指标:Error Rate/Count
饱和度指标:这块主要是关注系统的硬件资源的利用率,采用 4701 通用模板
好了,实操方案的设计和构思基本结束,下面开始进行实操。
2. Springboot Code
测试代码主要是模拟运行一个微服务组件,接受请求,然后进行处理(随机休眠)。
整个测试过程这个 Springboot 程序需要一直运行着。
3. Promethues
下载
点击以下链接通过官网下载 prometheus-2.35.0.windows-amd64
配置
解压 zip 包,然后打开 prometheus.yml,在里面配置一个 Metrics 数据的爬取 Job,指定到本地去进行 pull.配置也非常简单,只需要在增加阴影部分行的配置数据就可以了,其他的全部保持不变。如下图所示:
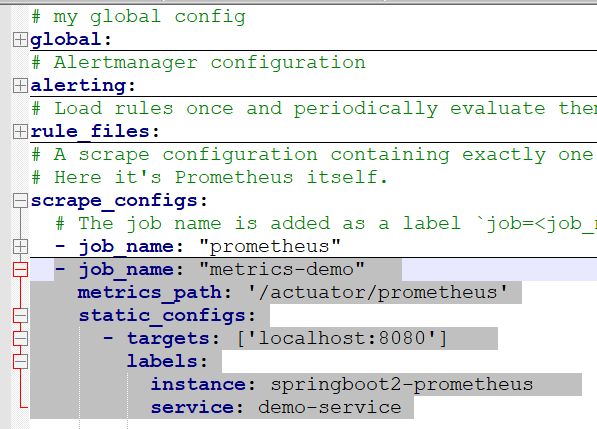
- job_name: "metrics-demo" metrics_path: '/actuator/prometheus' static_configs: - targets: ['localhost:8080'] labels: instance: springboot2-prometheus service: demo-service运行
最后,双击 prometheus.exe 运行起来即可。
访问 http://localhost:9090/有 GUI 出来即说明安装 OK
4. Grafana
下载
点击以下链接通过官网下载grafana-enterprise-8.5.3.windows-amd64.zip
配置
和 Prometheus 都跑到同一台机器上了,没啥要配置的,开箱即用
运行
到 bin 目录找到 grafana-server.exe,双击运行就可以了。
访问 http://localhost:3000/;admin/admin.有 GUI 出来即说明安装 OK
5. JMeter
下载
https://dlcdn.apache.org//jmeter/binaries/apache-jmeter-5.4.3.zip
配置
和 Springboot 程序都跑到同一台机器上了,没啥要配置的,开箱即用
启动
找到 apache-jmeter-5.4.3\bin\jmeter.bat 双击启动即可。启动成功后可见如下的 GUI
添加 case
添加一个并发测试的 case 用来模拟用户向微服务发送 HTTP 请求:
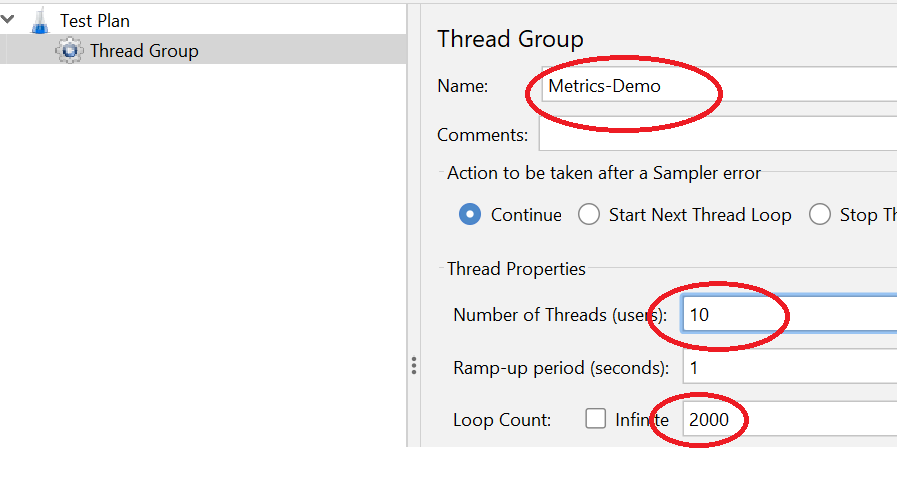
1:添加一个 Thread Group:
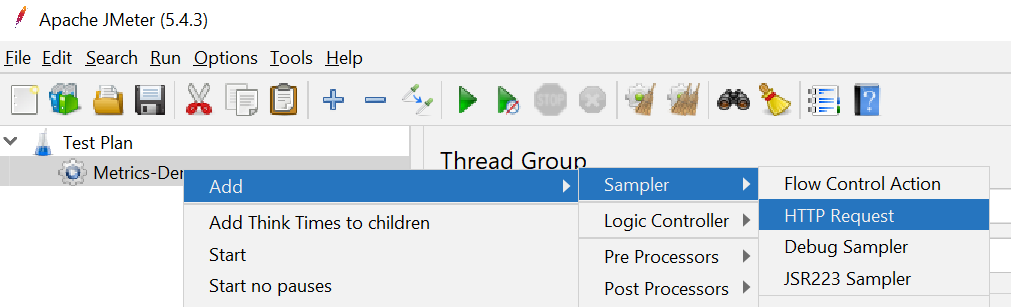
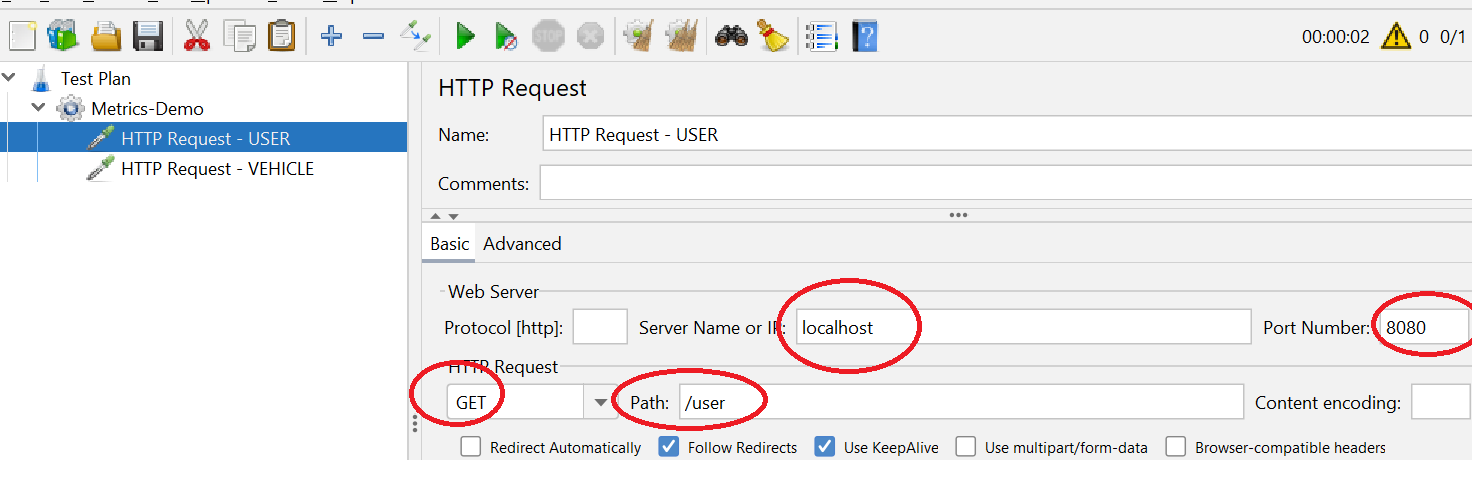
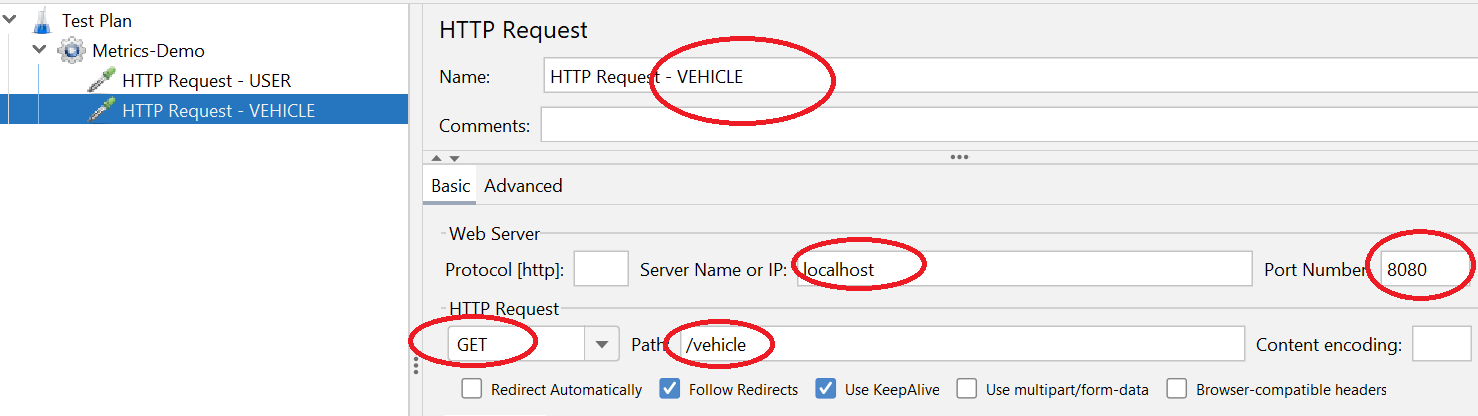
2:添加两个类型为 HTTP Requester 的采样器:
执行
配置完 case 之后,回到 Thread Group 界面,点击绿色箭头即可启动测试;
测试启动之后,相应的一些 metrics 数据就已经开始被采集到 Prometheus 中了。这个时候我们就可以去到 Grafana 上面去配置我们的监控面板了。需要注意的是,配置的前提是先要有时序样本数据。这就是为什么要先开启 JMeter 进行数据生产的原因。
6. 配置 Dashboard
前面的步骤做完了,接下来就可以开始实现我们的实操的终极目的:配置出一个可以用于对微服务进行监控的监控大板了. 以下的所有的操作都在 Grafana 上进行。
登陆 Grafana
访问 http://localhost:3000/登陆到 Grafana,如果需要账号密码,就是 admin/admin。可以见到如下的 Welcome 首页。
配置数据源
首先,需要告诉 Grafana 去哪个数据源获取数据。在 Welcome 界面上,点击 “Add your first data source”,进入到添加数据源的界面,然后选择第“Prometheus”,进行配置,将 Prometheus 作为其数据源。
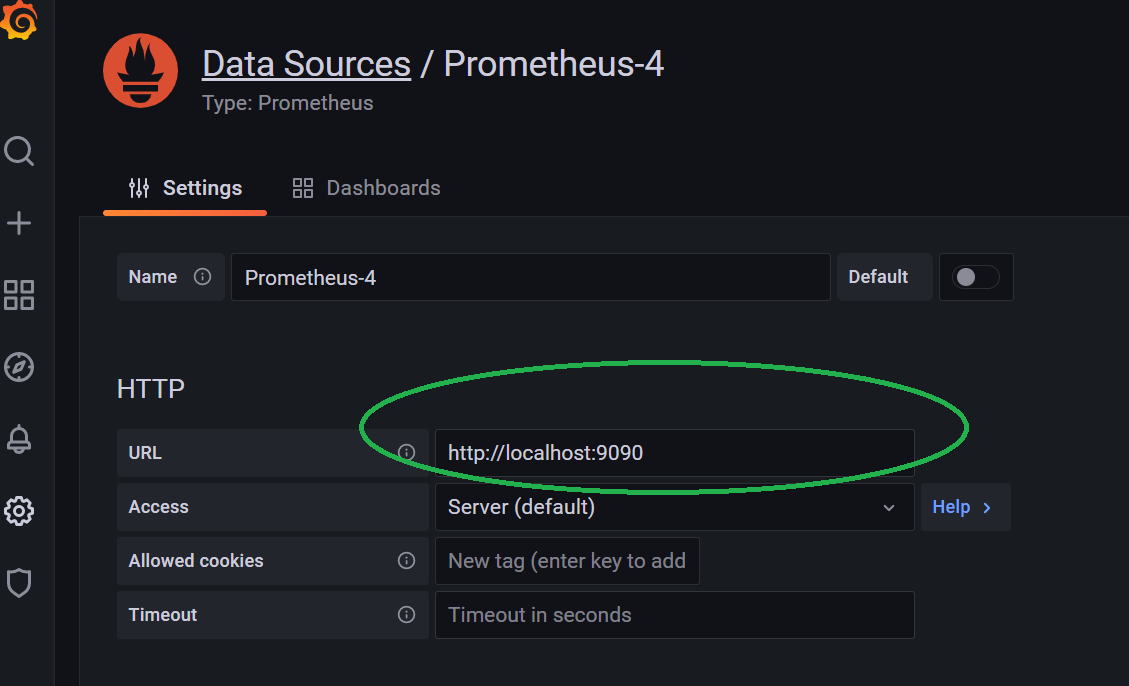
这里 URL 是需要手工添加进去的。只设置这个 URL 就可以了,其他的所有配置保持默认即可。最后拖到底部,保存并测试。如一切正常,可以看到绿色的测试成功信息提示。
配置面板
接下来,我们就需要利用我们前面掌握的相关知识,将我们设计好的监控面板给配置出来。在 Welcome 界面上点击“Create your first dashboard”,然后点击“Add a new panel”开始创建监控面板。
RPS/OPS 面板
在创建面板的时候,将 Panel 的名字设置为 HTTP RPS/OPS。同时注意要将 visualization 里面的图形样式改为**Graph (old),**否则会出现很多的时序图形无法展示的问题。另外在“Metrics browser”这里的输入栏,相关的指标会智能提示的,不需要去一个个记的。
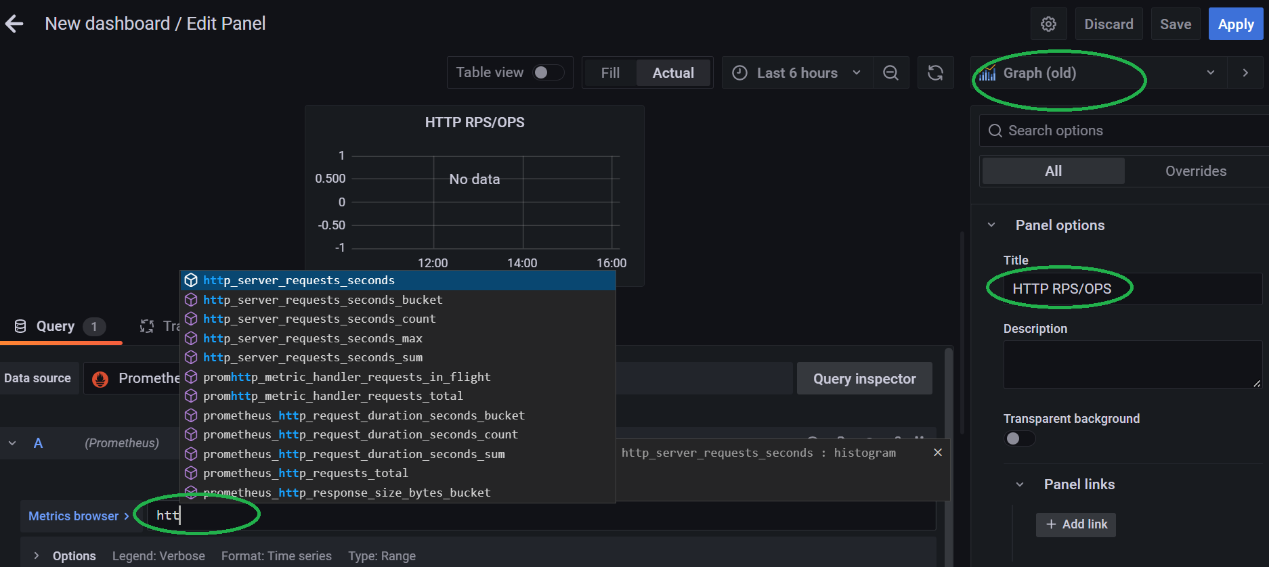
这里,我们使用如下的 PromSql 表达式:
rate(http_server_requests_seconds_count{uri=~"/user|/vehicle"}[$__rate_interval])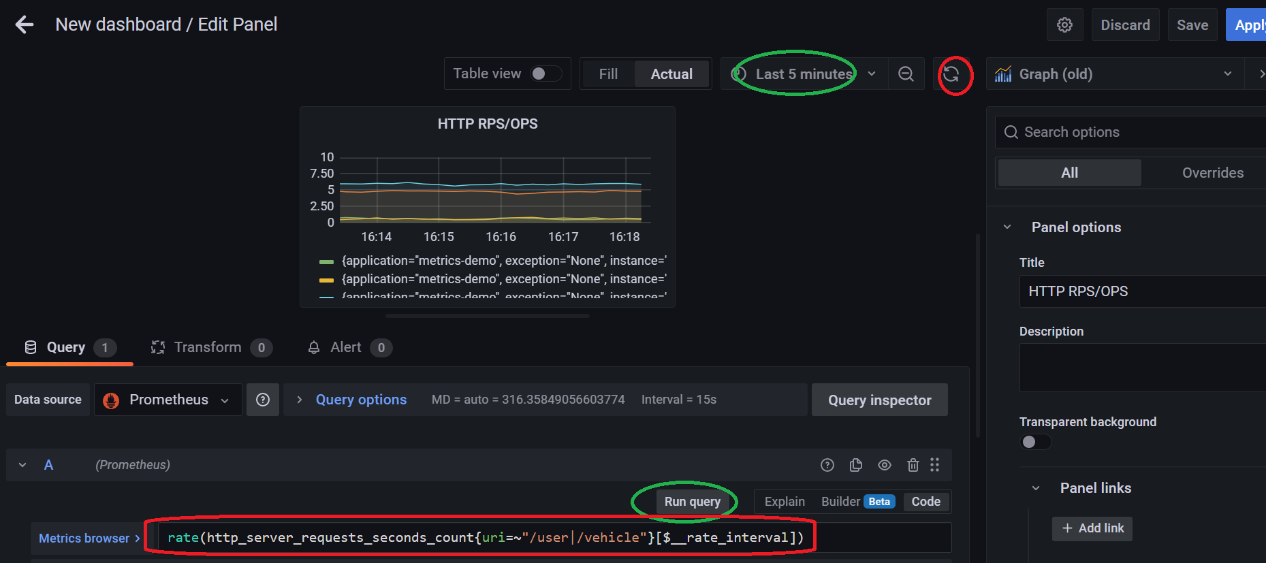
可以看到,OPS 数据的监控面板已经产生了。 Apply 保存即可。
AVG RT 面板
接下来,同样的操作用来构建我们用的最多的 Latency 监控面板,
使用到的 PromSql 表达式如下:
rate(http_server_requests_seconds_sum{exception="None",method="GET",service="demo-service",status="200",uri=~"/user|/vehicle"}[$__rate_interval])/rate(http_server_requests_seconds_count{exception="None",method="GET",service="demo-service",status="200",uri=~"/user|/vehicle"}[$__rate_interval]) * 1000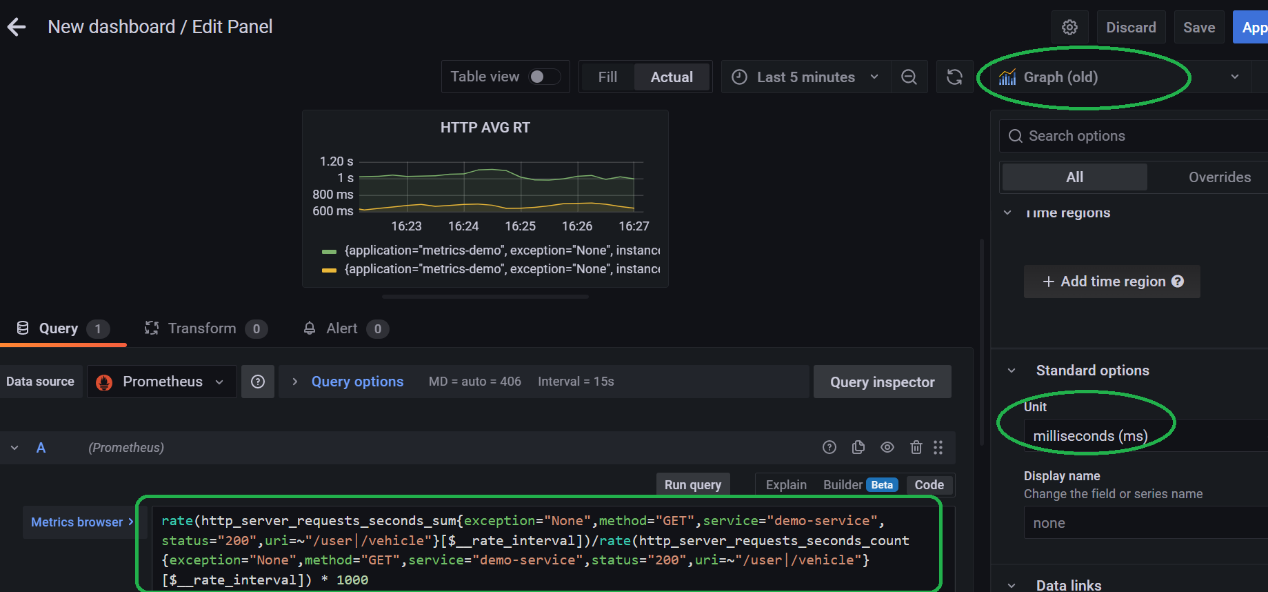
这里要注意的是需要将单位显示这里设置为 ms,因为我们计算的时候扩大了 1000 倍。同样 apply 保存即可
ERROR 面板
Error 面板主要用来监控 HTTP 的非 2XX 的返回数据,相对简单,它是不需要啥计算的,直接过滤一下 counter 数据就可以了。注意:ERROR 的图表适用用 Stat 格式来进行展示。
使用下面的 PromSql 表达式来实现:
http_server_requests_seconds_count{status="404",uri="/vehicle"}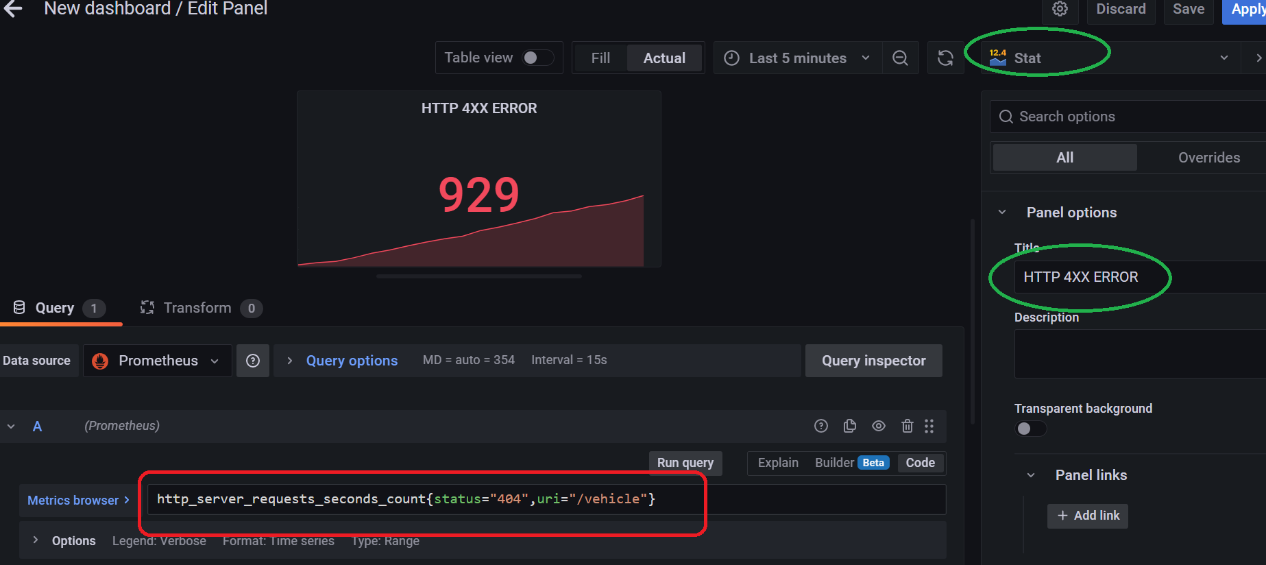
同样,5XX 之类的监控指标也可以采用同样的操作实现.
接下来再配置一个监控系统 HTTP 请求 ERROR 速率的面板
使用如下的 PromSql 表达式:
sum(rate(http_server_requests_seconds_count{application="metrics-demo", instance="springboot2-prometheus", status=~"5..|4.."}[1m]))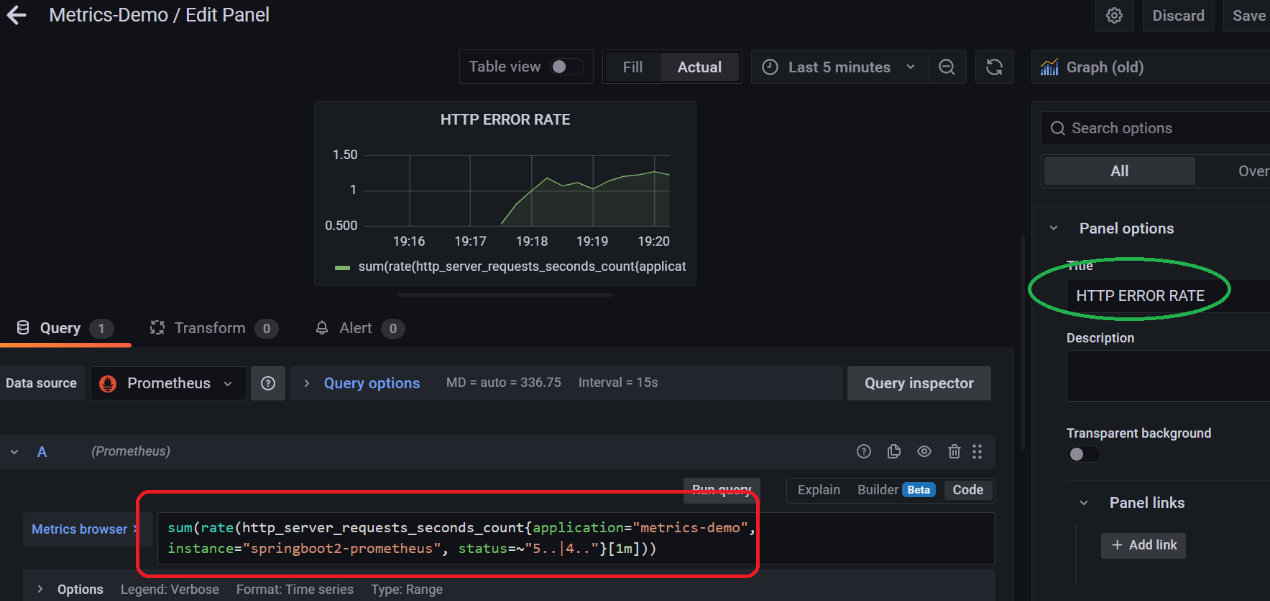
保存即可。
PXX 分位图 &并发数
前面的章节已经提过了,micrometer 默认产生的监控指标中是不包含 PXX 数据 HTTP 并发数指标的,这两个指标是需要在代码中写几行代码进行定制,其实很很简单,模式都是固定的,固定写法而已。有兴趣可以参考代码。
采用如下的 PromSql 来计算 HTTP 的平均响应时间的分位图:
avg(http_server_requests_seconds{service="demo-service",quantile =~ "0.5|0.9|0.95|0.99",uri="/user"} * 1000) by (uri,quantile)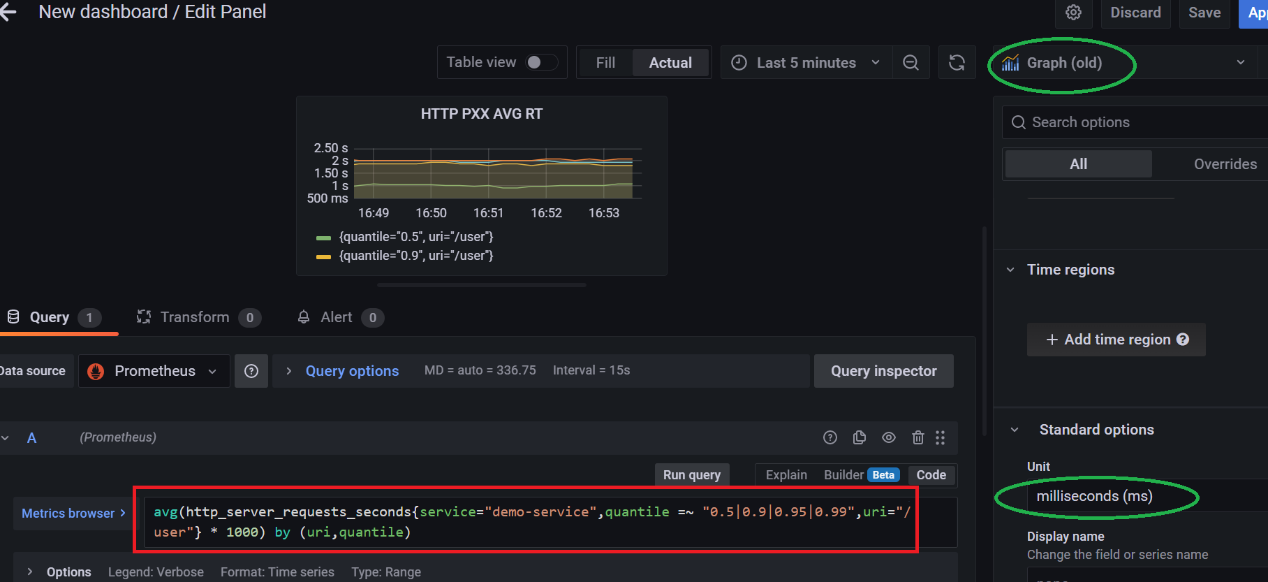
保存即可。
使用如下的表达式来监控 HTTP 当前真正在处理请求的 Session 数量。
demo_rest_inprogress_req{}该指标同样是一个客制化的 Metrics.
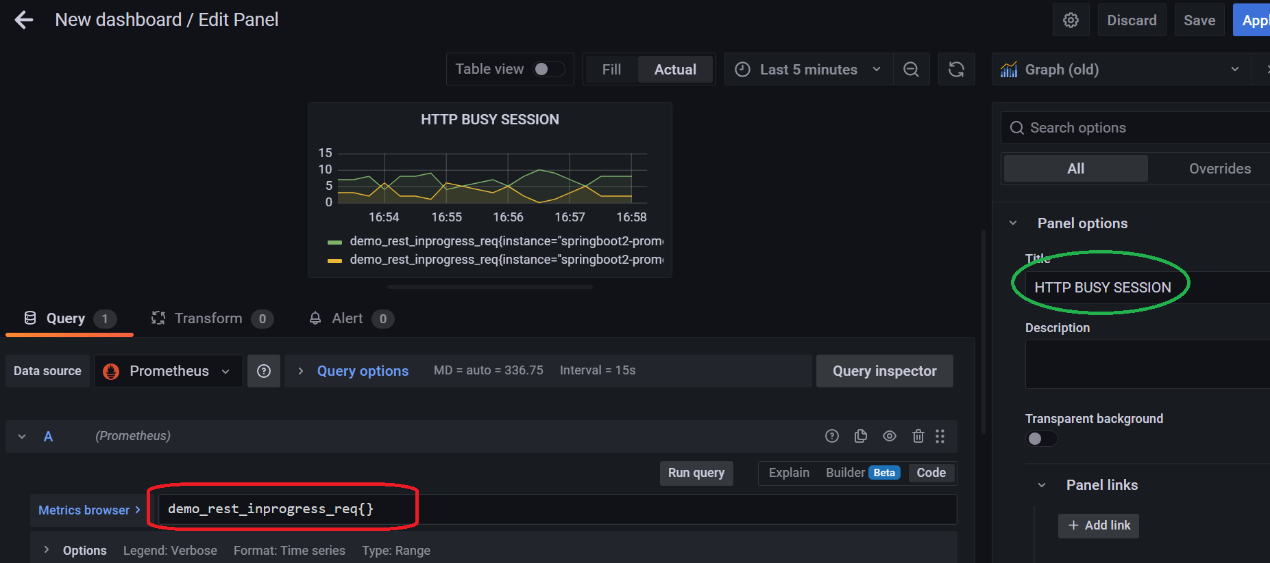
保存即可。
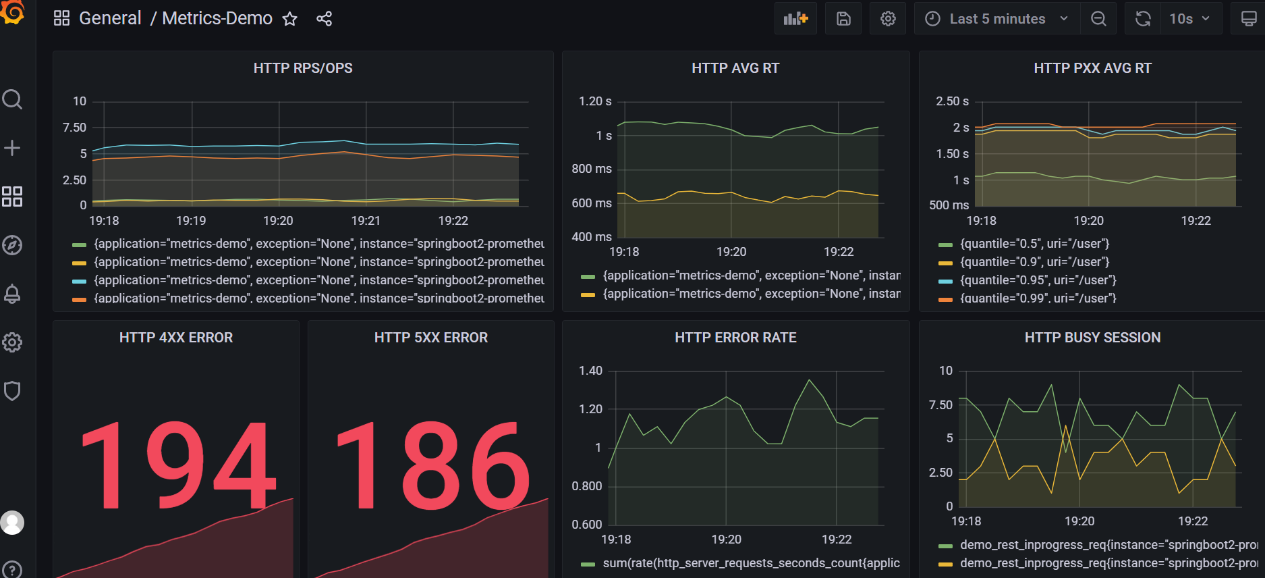
自此,一个完整的针对 HTTP 微服务组件的监控面板就创建起来了,最终的效果如下:
饱和度指标面板
细心的读者可以发现了,我们还缺少一个可以用来监控系统资源饱和度的面板。这里我们就直接使用在业界应用非常广泛,大名鼎鼎的 4701 模板了。这个模板依然是直接导入,开箱即用。
在 Welcome 界面左侧点击那个小+,进入到 import 界面:
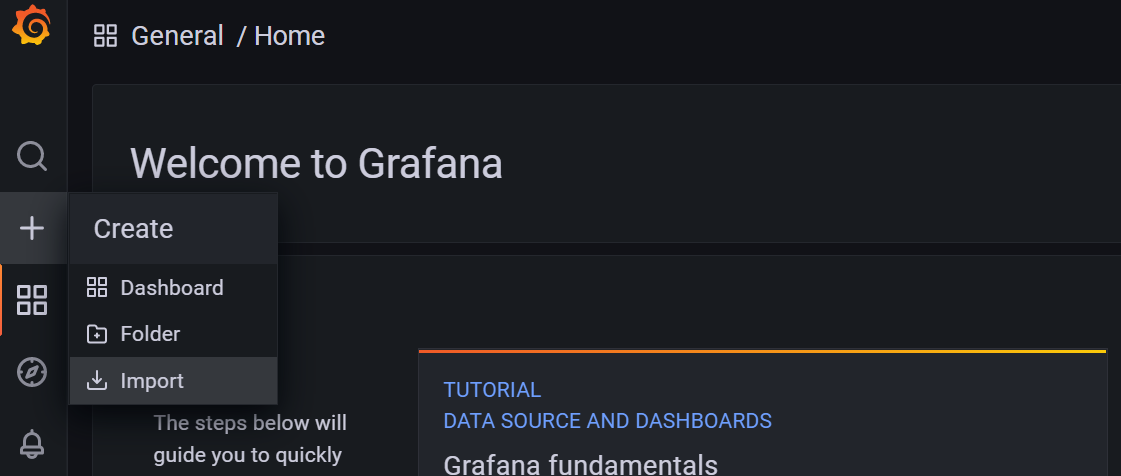
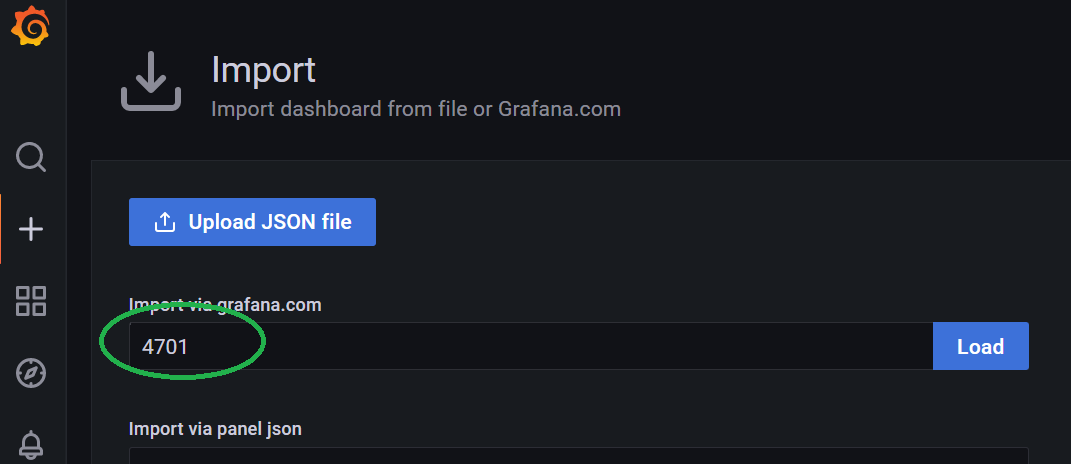
输入 4701 然后 load 一下。
配置好面板名称,选择数据源,就可以了。然后 import 进来就完事了。
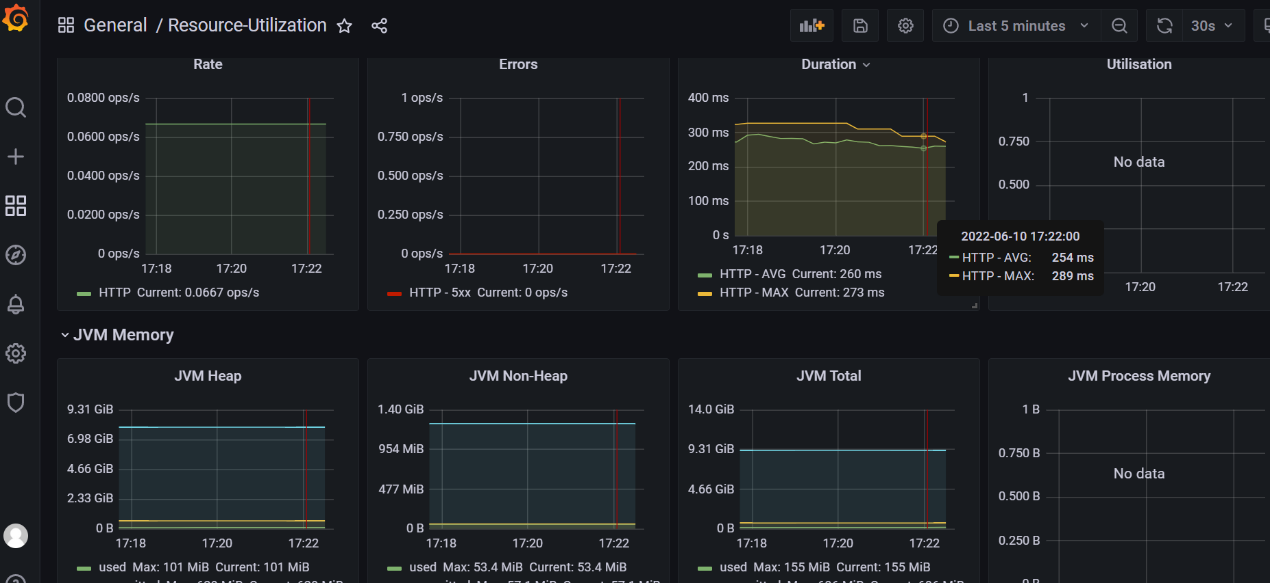
导入后的 4701 面板效果如下:
总结
最终,针对微服务组件的监控,我们得到了如下的两个监控面板,能够很好地完成针对微服务组件(HTTP)进行监控的目标了。
自此,本文开头提出的想法已经被我们一一实现了。从发现问题,分析问题,然后系统性地进行知识梳理,学习,再进行落地实操,如果你完整地走过了一遍,相信你此刻面对监控系统,应该会多了一份自信,少了一份彷徨了,以后类似的问题基本都可以举一反三,从容应对了。
希望这个文档能够给你带来一些小小的帮助!谢谢!




