
本文最初发表于 Towards Data Science 博客,经原作者 Eric Hofesmann 授权,InfoQ 中文站翻译并分享。
最近几年,开源工具在满足端到端平台的许多需求方面取得了很大进步。从模型架构开发到数据集管护(Dataset curation),再到模型训练和部署,它们都可以扮演一个不可思议的角色。有了充分的挖掘,你就能发现一个开源的工具,可以支持大量的数据和模型生命周期。工具间的紧密集成是实现近乎无缝工作流的最好方法。本文将对PyTorch Lightning Flash与数据集可视化和模型分析工具FiftyOne之间的集成进行了深入研究。
Lightning Flash 是一个在 PyTorch Lighting 基础上构建的新框架,它提供了快速原型、基线、微调和深度学习解决业务和科学问题的任务集合。尽管 Flash 很容易上手,但是不管你有多少深度学习经验,你都可以通过 Lightning 和 PyTorch 修改已有的任务来寻找适合你的抽象层次。为更快地推进,Flash 的代码是可扩展的,内建支持任何硬件的分布式训练和推理。
Flash 可以让你的第一个模型变得非常简单,但是要继续改进,你需要知道你的模型的性能和改进方法。FiftyOne 是一个开源工具,由 Voxel51 开发,用来建立高质量数据集和计算机视觉模型。它提供了优化数据集分析管道的构件,允许你亲自操作数据,包括可视化复杂的标签、评估模型、探索感兴趣的场景、确定失败模式、查找注释错误、管护训练数据集等。
有了 Flash+ FiftyOne,你就可以加载资料集,训练模型,然后分析下列所有计算机视觉任务的结果:
概述
Flash 和 FiftyOne 之间的紧密集成允许你执行端到端的工作流,加载数据集,训练它的模型,以及可视化 / 分析它的预测,所有这些都只需要几个简单的代码块。
将 FiftyOne 数据集加载到 Flash
尽管使用 FiftyOne 开发数据集一直都很容易,但是与 PyTorch Lightning Flash 集成后,你就可以将这些数据加载到 Flash 中,直接完成训练任务。
from flash.image import ImageClassificationDataimport fiftyone as fotrain_dataset = fo.Dataset.from_dir("/path/to/train",fo.types.ImageClassificationDirectoryTree,label_field="ground_truth",)val_dataset = fo.Dataset.from_dir("/path/to/val",fo.types.ImageClassificationDirectoryTree,label_field="ground_truth",)datamodule = ImageClassificationData.from_fiftyone(train_dataset=train_dataset,val_dataset=val_dataset,label_field="ground_truth",)训练 Flash 任务
Flash 提供了你需要的工具,你可以用尽可能少的代码抓取任务的模型,然后从数据上进行微调,最重要的是,不需要成为该领域的专家。
import flashfrom flash.core.data.utils import download_datafrom flash.image import ImageClassificationData, ImageClassifier# 1. Download the datadownload_data("https://pl-flash-data.s3.amazonaws.com/hymenoptera_data.zip", 'data/')# 2. Load the datadatamodule = ImageClassificationData.from_folders(train_folder="data/hymenoptera_data/train/",val_folder="data/hymenoptera_data/val/",test_folder="data/hymenoptera_data/test/",)# 3. Build the modelmodel = ImageClassifier(num_classes=datamodule.num_classes, backbone="resnet18")# 4. Create the trainer. Run once on datatrainer = flash.Trainer(max_epochs=1)# 5. Finetune the modeltrainer.finetune(model, datamodule=datamodule, strategy="freeze")# 6. Save it!trainer.save_checkpoint("image_classification_model.pt")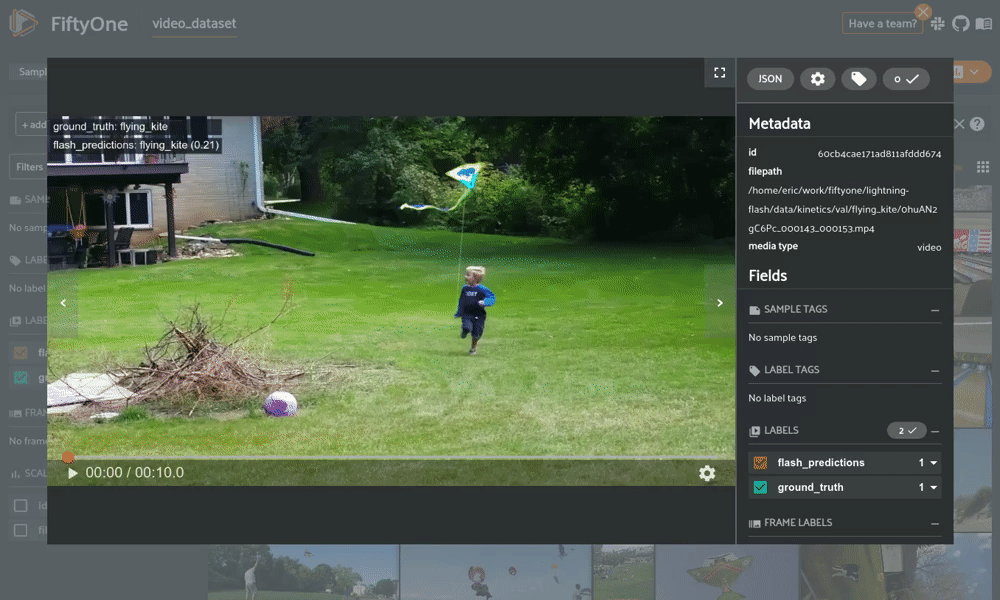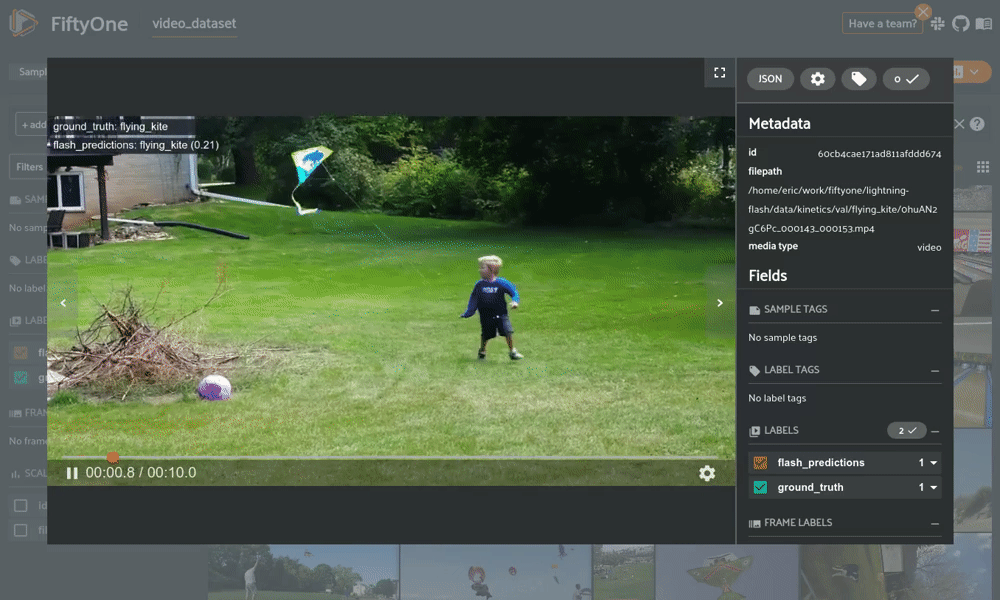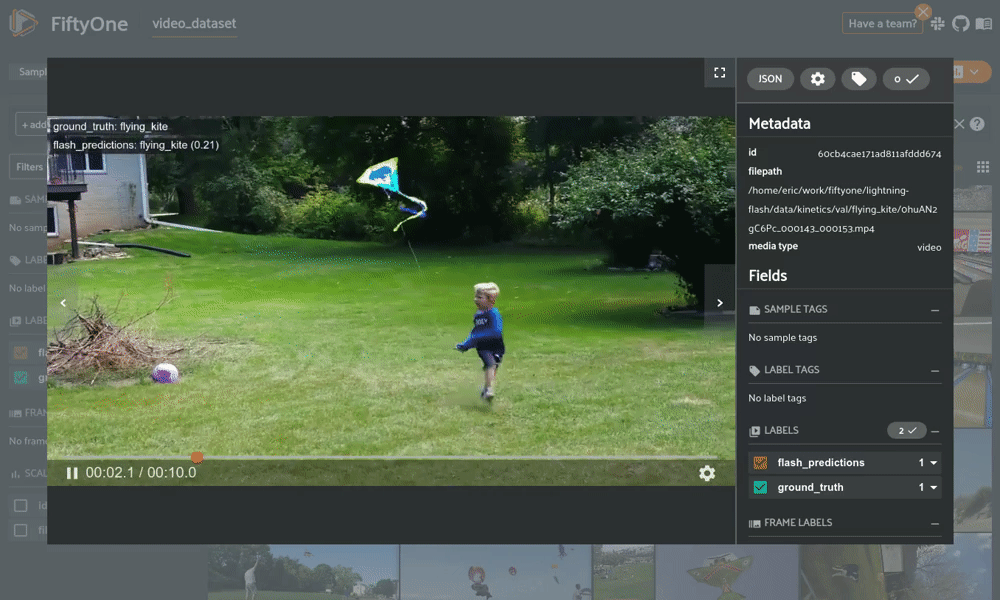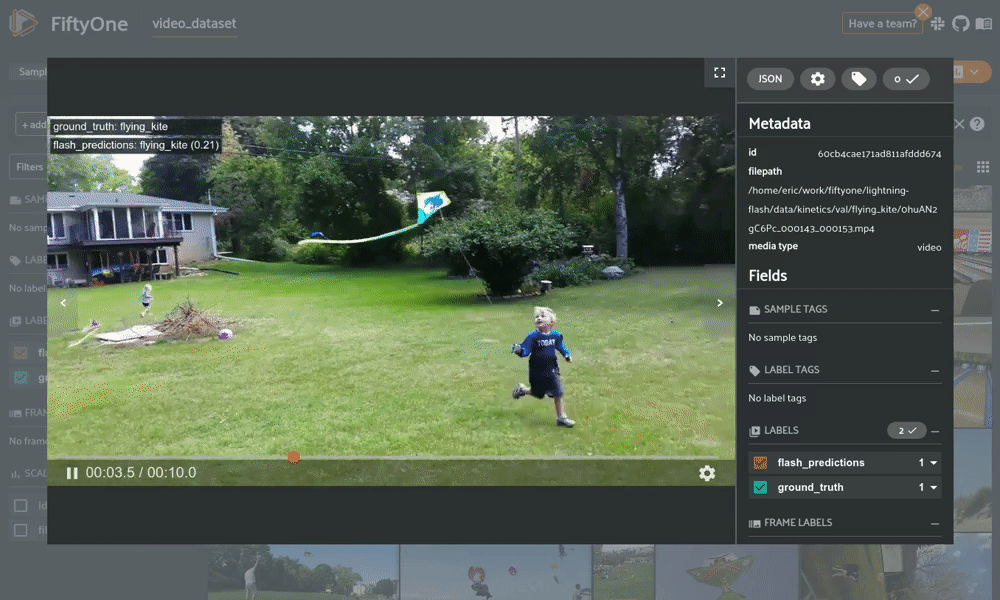
使用 FiftyOne 可视化 Flash 预测
随着现代数据集的复杂性和规模的增加,图像和视频数据的可视化一直是一个挑战。FiftyOne 的设计目的是提供对数据集和标签的用户友好的视图 (包括注释和模型预测),现在 Flash 模型可以通过一行额外的代码访问这些数据集和标签。
from flash import Trainerfrom flash.core.classification import FiftyOneLabelsfrom flash.core.integrations.fiftyone import visualizefrom flash.video import VideoClassificationData, VideoClassifierclassifier = VideoClassifier.load_from_checkpoint(...)# Option 1: Generate predictions using a Trainer and datamoduledatamodule = VideoClassificationData.from_folders(predict_folder="/path/to/folder",...)trainer = Trainer()classifier.serializer = FiftyOneLabels(return_filepath=True)predictions = trainer.predict(classifier, datamodule=datamodule)session = visualize(predictions) # Launch FiftyOne# Option 2: Generate predictions from model using filepathsfilepaths = ["list", "of", "filepaths"]predictions = classifier.predict(filepaths)classifier.serializer = FiftyOneLabels()session = visualize(predictions, filepaths=filepaths) # Launch FiftyOne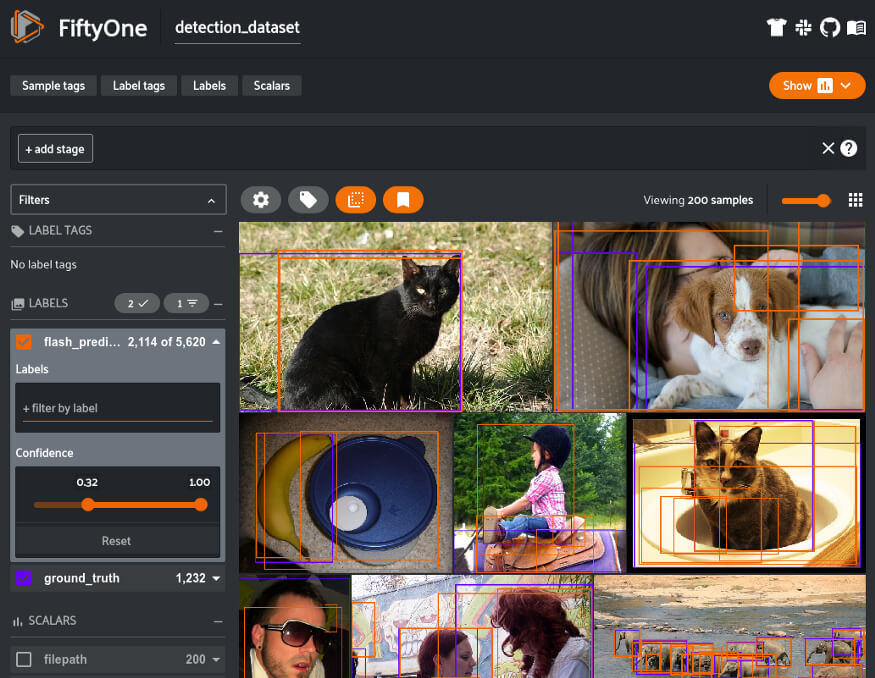
用 FiftyOne 进行可视化 Flash 视频分类预测。
示例工作流
安装
要跟上本文的示例,你需要安装相关的软件包。首先,你需要安装 PyTorch Lightning Flash 和 FiftyOne:
pip install fiftyone lightning-flash对于嵌入可视化工作流,你还需要安装降维软件包 umap-learn:
pip install umap-learn通用工作流
使用这些工具的大多数模型开发工作流遵循相同的通用结构:
图像目标检测
本节展示了使用 PyTorch Lightning Flash 和 FiftyOne 之间的这种集成,以训练和评估一个图像目标检测模型的具体示例。
from itertools import chainimport fiftyone as foimport fiftyone.zoo as fozfrom flash import Trainerfrom flash.image import ObjectDetectionData, ObjectDetectorfrom flash.image.detection.serialization import FiftyOneDetectionLabels# 1. Load your FiftyOne dataset# Here we use views into one dataset, but you can also create a# different dataset for each splitdataset = foz.load_zoo_dataset("quickstart", max_samples=40)train_dataset = dataset.shuffle(seed=51)[:20]test_dataset = dataset.shuffle(seed=51)[20:25]val_dataset = dataset.shuffle(seed=51)[25:30]predict_dataset = dataset.shuffle(seed=51)[30:40]# 2. Load the Datamoduledatamodule = ObjectDetectionData.from_fiftyone(train_dataset = train_dataset,test_dataset = test_dataset,val_dataset = val_dataset,predict_dataset = predict_dataset,label_field = "ground_truth",batch_size=4,num_workers=4,)# 3. Build the modelmodel = ObjectDetector(model="retinanet",num_classes=datamodule.num_classes,serializer=FiftyOneDetectionLabels(),)# 4. Create the trainertrainer = Trainer(max_epochs=1, limit_train_batches=1, limit_val_batches=1)# 5. Finetune the modeltrainer.finetune(model, datamodule=datamodule)# 6. Save it!trainer.save_checkpoint("object_detection_model.pt")# 7. Generate predictionsmodel = ObjectDetector.load_from_checkpoint("https://flash-weights.s3.amazonaws.com/object_detection_model.pt")model.serializer = FiftyOneDetectionLabels()predictions = trainer.predict(model, datamodule=datamodule)predictions = list(chain.from_iterable(predictions)) # flatten batches# 8. Add predictions to dataset and analyzepredict_dataset.set_values("flash_predictions", predictions)session = fo.launch_app(view=predict_dataset)在 FiftyOne 中可视化的 Flash 目标检测预测
在此之后,你可以将预测返回到数据集中,并且可以运行评估来生成混淆矩阵、PR 曲线,以及准确率和 mAP 等指标。尤其是,你可以识别并查看个别的真 / 假正类 / 负类结果,让你了解你的模型在哪些方面表现良好,哪些方面表现不佳。基于常见失败模式改进模型是开发更好模型的更加可靠的方法。
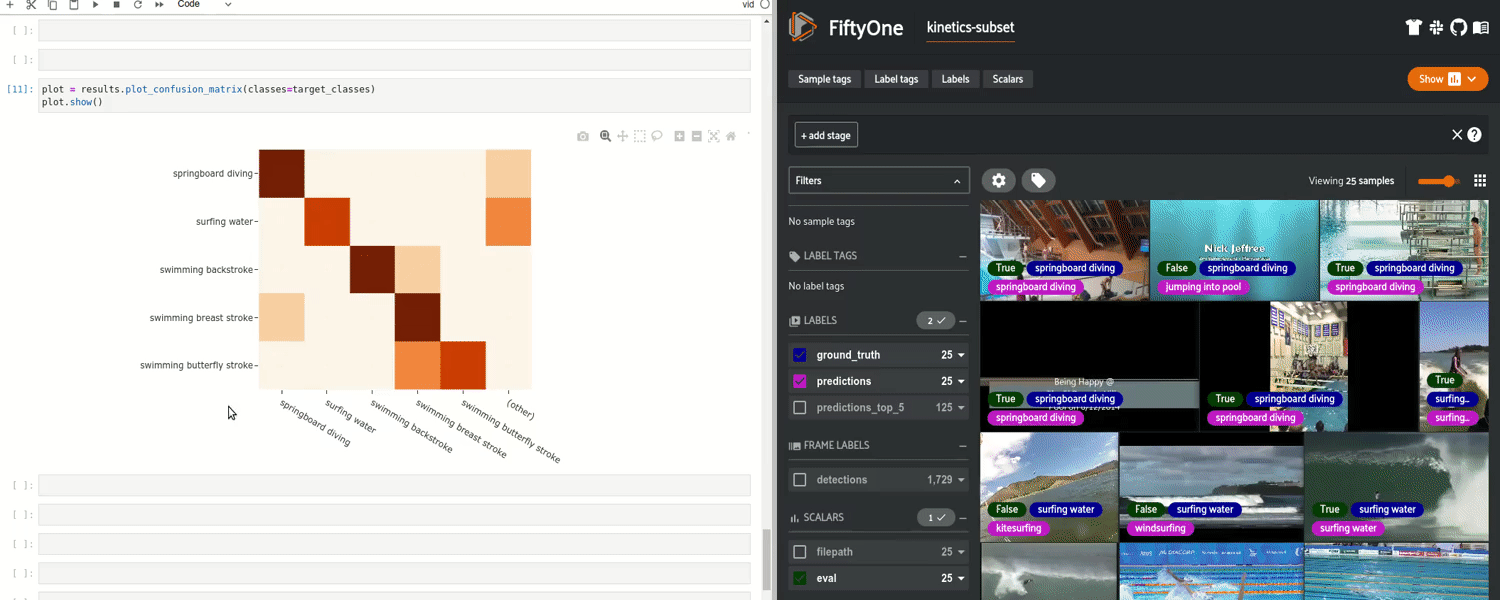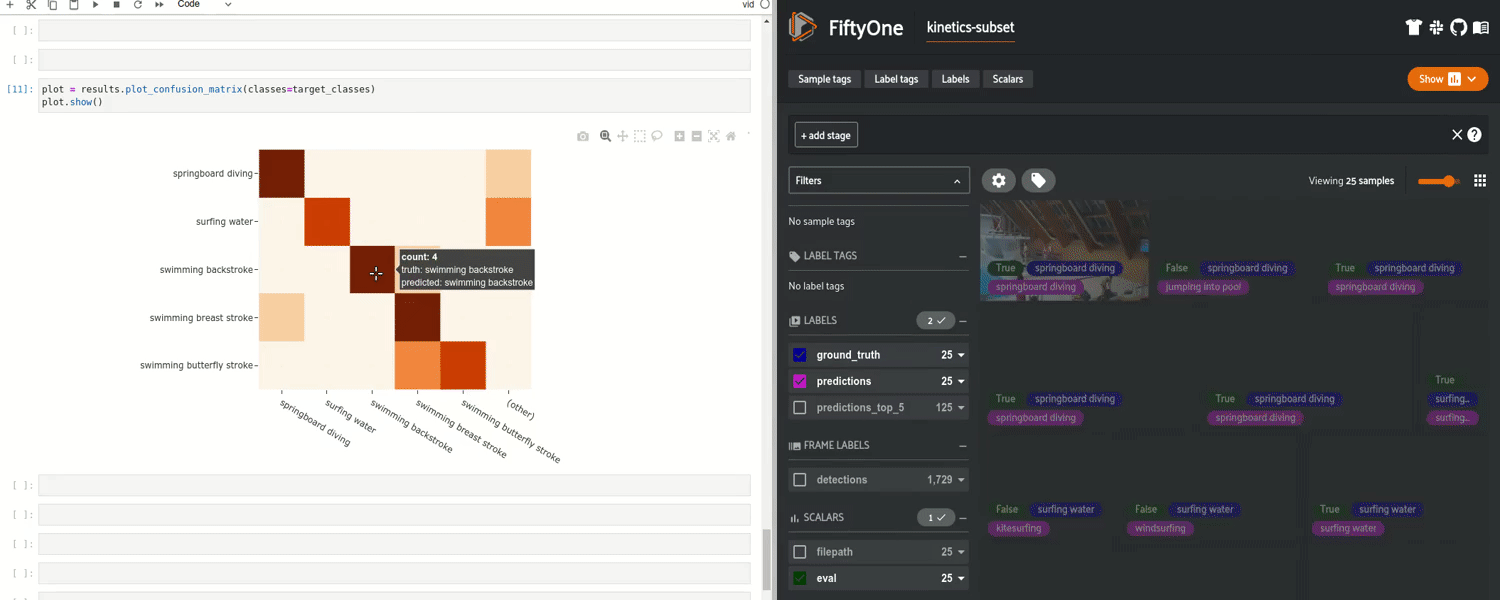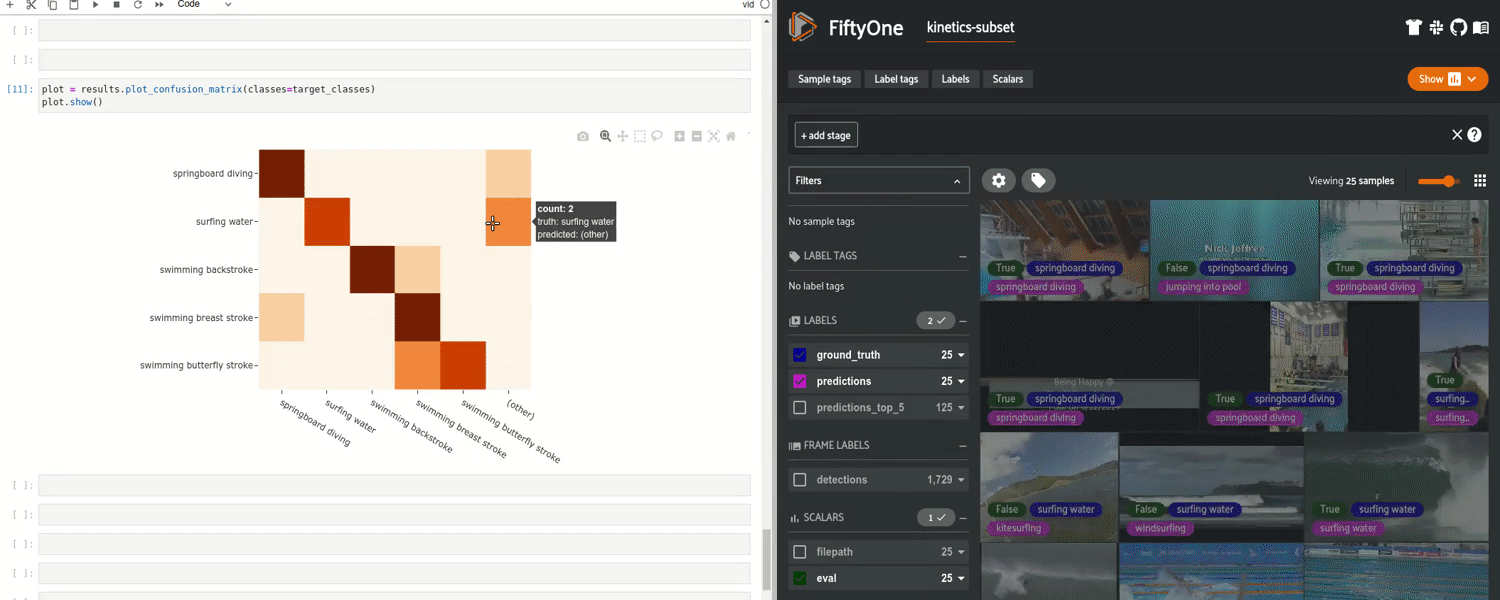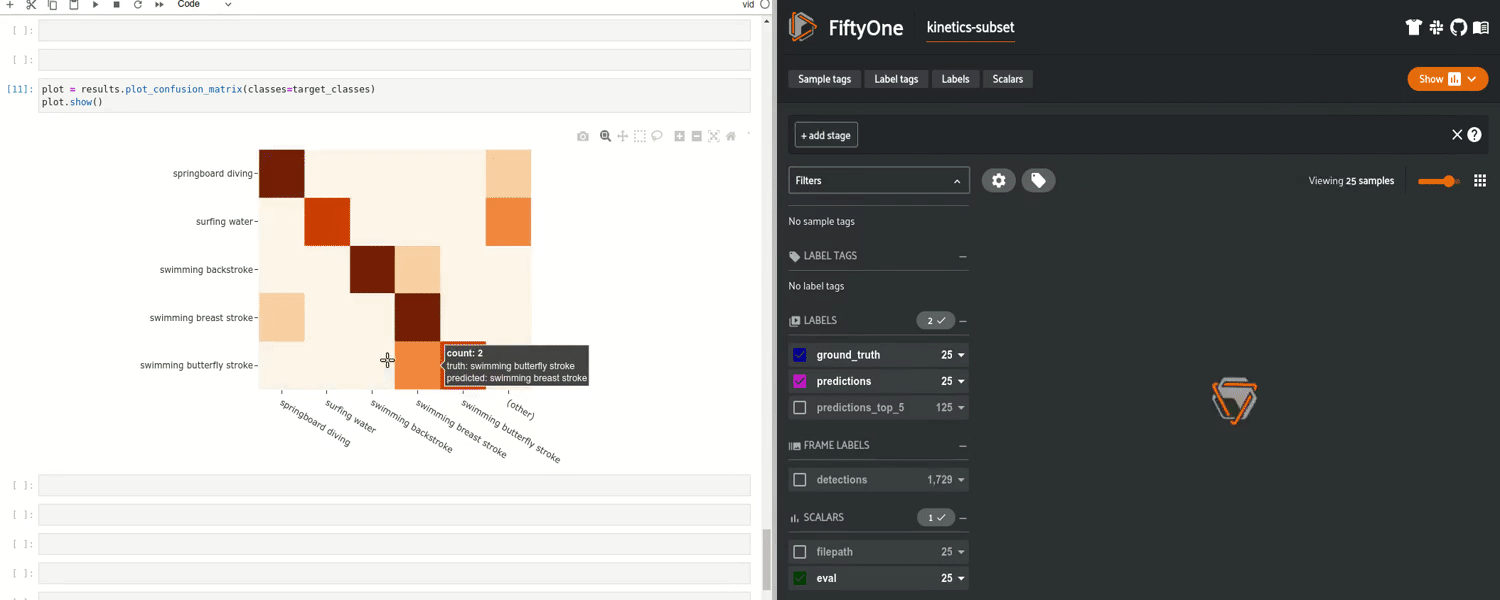
FiftyOne 中的交互式混淆矩阵
嵌入式可视化
这个工作流的独特之处在于,它采用预训练模型,并使用它们来生成数据集中的每一张图片的嵌入向量。然后,你就可以在低维空间中计算这些嵌入的可视化,以查找数据集群。这一功能可以为硬样本挖掘、数据注释、注释样本推荐等提供有价值的发现。
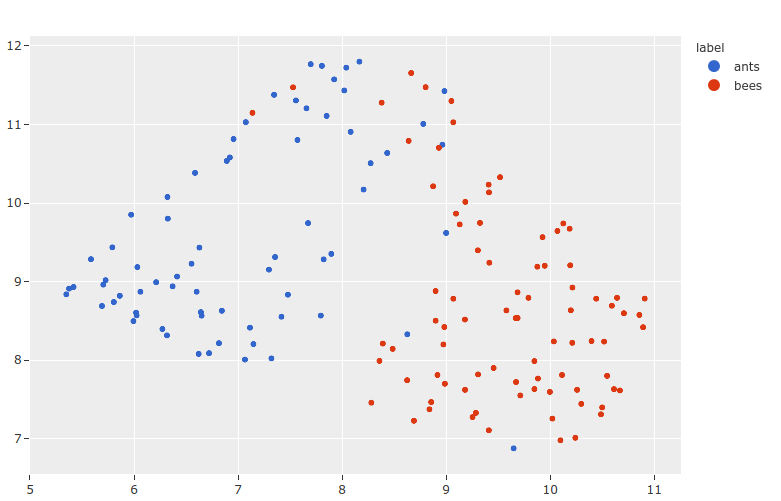
有了交互图的概念,你可以点击或圈出这些嵌入的区域,并自动更新你的会话,查看和标记相应的示例。
其他任务
你可以在这里查看其他任务的类似工作流,例如分类和分割。
总结
开源社区多年来的发展令人瞩目,特别是在机器学习领域。尽管单独的工具可以很好地解决一个特定的问题,但是它们之间的紧密结合形成了一个强大的工作流。PyTorch Lightning Flash 与 FiftyOne 之间的新集成为开发数据集、训练模型和分析结果提供了一种新的简便方法。
作者介绍:
Eric Hofesmann,Voxel51 机器学习工程师,密歇根大学(University of Michigan)计算机科学硕士。
原文链接:




