
背景
随着用户数的快速增长,闲鱼的 IM 也迎来了前所未有的挑战。多年的业务迭代,端侧 IM 的代码已经因为多年的迭代层次结构不足够清晰,之前消息一些隐藏起来的数据同步问题,也随着用户数的增大而被放大。
这里面的具体流程在于,后台需要同步到用户端侧的数据包,后台会根据数据包的业务类型划分成不同的数据域,数据包在对应域里面存在唯一且连续的编号,每一个数据包发送到端侧并且被成功消费后,端侧会记录当前每一个数据域已经同步过的版本编号,下一次数据同步就以本地数据域的编号开始,不断的同步到客户端。
当然用户不会一直在线等待消息,所以之前这里端侧采用了推拉结合的方式保证数据的同步。
在线时使用 ACCS 实时的将最新的数据内容推送到客户端。ACCS 是淘宝无线向开发者提供全双工、低延时、高安全的通道服务。
离线启动后,根据本地的数据域编号,拉取不在线时候的数据差。
当数据获取出现黑洞(数据包 Version 不连续的状态)时,触发数据同步拉取。
分析
现存的一个同步策略是可以基本保障 IM 的数据同步的,但是也伴随着一些隐含的问题:
短时间密集数据推送时,会快速的触发多次数据域同步。域同步回来的数据如果存在问题,又会触发新一轮的同步,造成网络资源的浪费。冗余数据包/无效的数据内容会占用有效内容的处理资源,又对 CPU 和内存资源造成浪费。
数据域中的数据包客户端是否正常消费,服务端侧无感知,只能被动地根据当前数据域信息返回数据。
数据收取/消息数据体解析/存储落库逻辑拆分不够清晰,无法针对性的对某一层的代码拆分替换进行 ABTest。
针对遇见的这些问题,对闲鱼 IM 进行分层改造,抽离数据同步层。除了希望以后这个数据的同步内容可以用在 IM 之外,也希望随着稳定性的增加,赋能其他的业务场景。
本文重点来看下端侧闲鱼 IM 数据同步的一些解决思路。
数据同步优化
拆分 &分层
对于服务端来说,业务侧产出数据包后,会拼接上当前的数据域信息,然后通过数据同步层将数据推送到端侧。
对于客户端来说,接收到数据包后,会根据当前的数据域信息,来确定需要消费数据包的业务方,确保数据包在数据域内完整连续后,将数据体脱壳后交于业务侧消费,并且应答消费的状况。
数据同步层的抽取,把数据同步中的加壳、脱壳、校验,重试流程封装到一起,可以让上层业务只需要关心自己需要监听的数据域信息,然后当这些数据域更新数据的时候,可以获取到这些数据进行消费,而不再需要关心数据包是否完整。
业务侧只需要关心业务侧对接的协议,数据侧只需要关心数据侧包装的协议,网络层负责真实的数据传输。
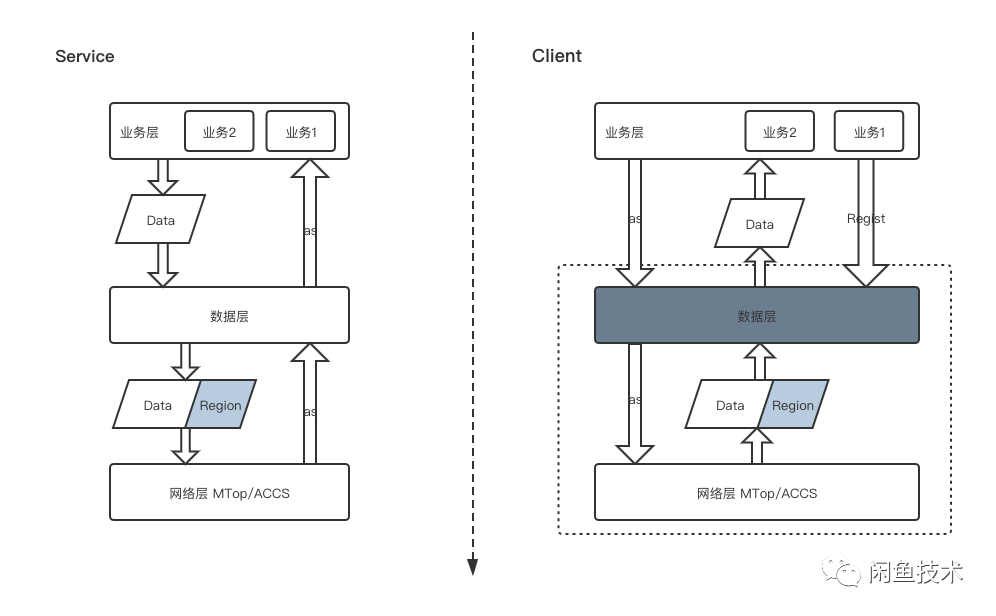
对齐数据层数据传输协议、描述当前数据包体数据域信息
将消息的处理/合并/落库抽离成数据消费者
上下楼依赖抽象化,去除对于具体实现的依赖
数据层结构模型
基于对于数据模型剥离和对当下遇见的问题的解决方案规整,将数据同步层拆分为这样的架构:
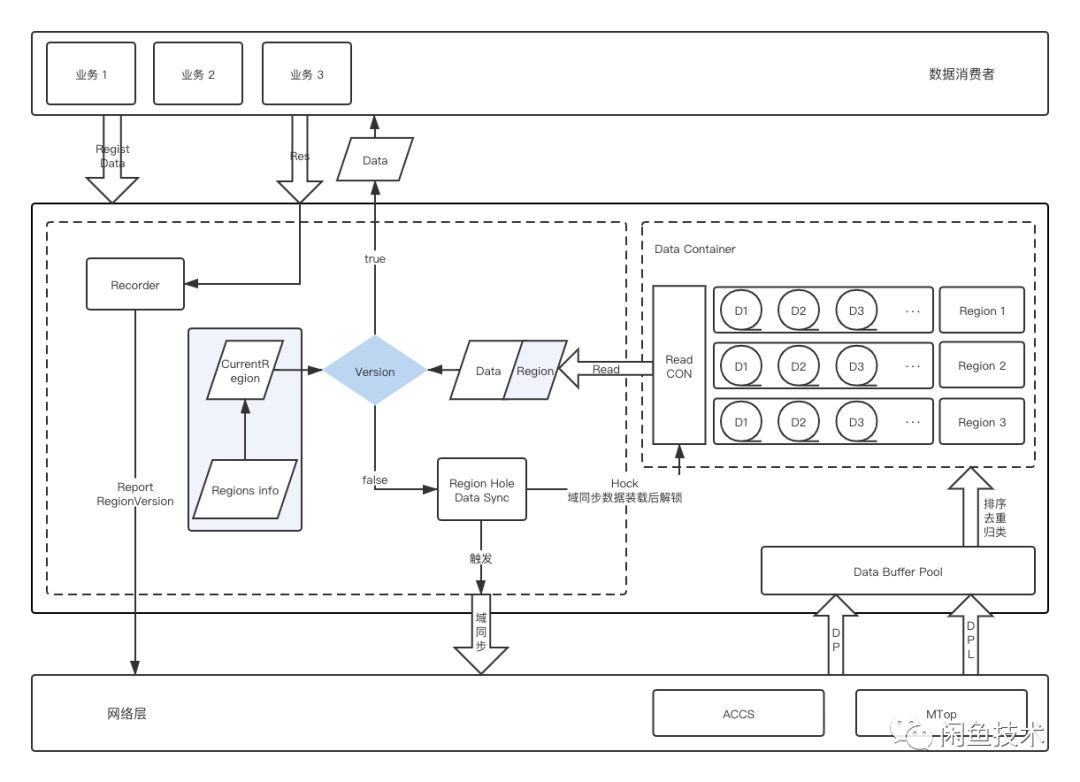
step1:App 启动时建立 ACCS 长链接服务,保证推推送信道链接,并且根据当前本地数据域信息触发一次数据拉取。
step2:数据消费者注册消费者信息和需要监听的数据域信息,这里是一对多的关系。
step3:新的数据抵达端侧后,将数据包放到指定的数据域的缓冲池,批量数据归纳结束后,重新出发数据的读取。
step4:根据当前数据域优先级弹出最高优的数据包,判断数据域版本是否符合消费者要求,符合则将数据包脱壳后丢给消费者消费,不符合则根据上一次正确的数据包的域信息触发增量的数据域同步拉取。
step5:触发数据域同步拉取时,block 数据读取,此时通过 ACCS 触达的数据依旧会在继续归纳到指定的数据域队列中,等待数据域同步拉取结果,将数据包进行排序、去重,合并到对应的数据域队列中。然后重新激活数据读取。
step6:数据包体被消费者正确消费后,更新域信息并且通过上行信道告知服务端已经正确处理的数据域信息。
数据域同步协议
Region 中携带的数据不必过多,但是又需要将数据包的内容描述清楚
目标用户的 ID,用以确定目标数据包是否正确
数据域 ID 和优先级信息
当前数据包的域优先级版本
排序策略
针对于域数据归纳,无论是在写入数据的时候进行排序还是在读取的时候进行查找都需要进行一次排序的操作,时间复杂度最优也是 O(logn)级别的,在实际 coding 中发现由于在一个数据域里面,数据包的 Version 信息是连续唯一并且不存在断层的,上一个稳定消费的数据体的 Version 信息自增就是下一个数据包的 Version,所以这里采用了以 Versio 为主键的 Map 存储,既降低了时间复杂度,也使得唯一标识的数据包后抵达端侧的包内容可以覆盖之前的包内容。
一些问题 &解决策略
多数据来源和唯一数据消费的平衡
每当产生一条针对于当前用户的数据包,如果当前 ACCS 长链接存在,就会通过 ACCS 将数据包推送到客户端,如果 App 切换到后台一段时间,或者直接被杀死,ACCS 链接断开,那么只能通过离线推送到用户的通知面板。所以每当 App 切换到活跃状态,都需要根据当前本地存储的数据域信息从后台触发一次数据同步
数据包触达到端侧的来源主要是 ACCS 长链接的推送和域同步时的拉取,但是数据包的消费是根据数据域的监听划分的唯一消费者,也就是同一时间内只能消费一个数据包。
在压力测试中,当后台短时间内密集的将数据包通过 ACCS 推送到端侧时,端侧接收到的数据包并不有序,不连续的数据包域版本又会触发新的数据域同步,导致同样的一份数据包会通过两个不同的渠道多次的触达到端侧,浪费了不必要的流量。
当数据域同步时,这个时间节点产生的新数据包也会推送到端侧,数据体有效,并且需要被正确的消费。
针对这些问题的解决策略:
在数据消费和数据获取中间装载一个数据中间层,当触发数据域同步的时候 block 数据的读取并且 ACCS 推送下来的数据包会被存放在一个数据的中转站里面,当数据域同步拉取的数据回来后,对数据进行合并后再重启数据读取流程。
数据域优先级
需要推送到端侧的数据包,根据业务的不同优先级也有不同的划分,用户和用户的聊天产生的数据包会比运营类的消息的数据包优先级要高一些,所以要当多优先级的数据包快速的抵达端侧时,高优先级数据域的数据包需要被优先消费,而数据域的优先级也是需要动态调整,不断变换的优先级策略。
针对这个问题的解决策略:
不同的数据域,产生不同的数据队列,高优队列里面的数据包会被优先读取消费。
每一个数据包体中带回的数据域信息,都可以标注当前的数据域优先级,当数据域优先级发生变化的时候,调整数据包消费优先级策略。
优化效果
除去结构上分层梳理,使得数据同步层和依赖的服务内容可便捷解耦/每一个环节可插拔之外,数据同步中对于消息消费时长/流量节省,压力测试场景下优化效果更加明显。
压力测试场景:500ms 内 100 条全乱序数据包推送
消息处理时长(接收-上屏)缩短 31%
流量损耗(最终拉取到端侧数据包累积大小)降低 35%
后续计划
数据同步层能力提升
数据同步侧的目标,既要保证数据包完整的到达端侧,又要在保证稳定性的前提下尽可能的减少数据的拉取,使得每一次数据的获取都有效。后续数据同步层会着手于有效数据率和到达率进行更进一步的优化。
针对不同的场景,动态智能调整数据同步的优先级策略。
阻塞式长链接推送,保证同一时间只存在推模式或者拉模式,进一步减少冗余数据包的推送。
闲鱼 IM 端侧整体架构升级
升级数据同步层策略主要还是要提升闲鱼 IM 的能力,将数据同步分层后,接下来就是将消息的处理流程化,对每一个流程都可监控可回溯,提升 IM 数据包的正确解析存储和落库率。
在数据来源侧剥离开后,后续对 IM 的整改也会逐步的将消息的处理分层剥离
消息处理关键节点的流程式上报、建立完整的监控体系,让问题发现先于用户舆情
消息完整性的动态自检,最小化数据补偿补全。
注: 该改造升级将于十一月中旬的版本和大家见面,敬请期待
本文转载自公众号闲鱼技术(ID:XYtech_Alibaba)。
原文链接:




