
本文基于 Apahce Spark 3.1.1 版本,讲述 AQE 自适应查询优化的原理,以及网易数帆在 AQE 实践中遇到的痛点和做出的思考。
前言
自适应查询优化(Adaptive Query Execution, AQE) 是 Spark 3.0 版本引入的重大特性之一,可以在运行时动态的优化用户的 SQL 执行计划,很大程度上提高了 Spark 作业的性能和稳定性。AQE 包含动态分区合并、Join 数据倾斜自动优化、动态 Join 策略选择等多个子特性,这些特性可以让用户省去很多需要根据作业负载逐个手动调优,甚至修改业务逻辑的痛苦过程,极大的提升了 Spark 自身的易用性和灵活性。
作为网易大数据基础软件的缔造者,网易数帆旗下网易有数团队自 AQE 诞生起就关注其应用。第一个应用 AQE 的系统是 Kyuubi。 Kyuubi 是网易开源的一款企业级数据湖探索平台,它基于 Spark SQL 实现了多租户 SQL on Hadoop 查询引擎。在网易内部,基于 Kyuubi 的 C/S 架构,在保证 SQL 兼容性的前提下,服务端可以平滑地实现 Spark 版本升级,将社区和内部的最新优化和增强快速赋能用户。从 Spark 3.0.2 开始,网易有数就在生产环境中逐步试用和推广 AQE 的特性。而在 Spark 3.1.1 发布后,AQE 在 Kyuubi 生产环境中已经是用户默认的执行方式。在这个过程中,我们还端到端地帮助某个业务迁移了 1500+ Hive 历史任务到 Spark 3.1.1 上,不仅实现了资源量减半,更将总执行时间缩短了 70%以上,综合来看执行性能提升 7 倍多。
当然,AQE 作为一个“新”特性,在实践过程中我们也发现它在很多方面不尽如人意,还有很大的优化空间。秉着坚持开源策略,网易有数努力将团队遇到的问题和 Spark 社区分享,将我们的优化努力合进社区。以下章节,我们将展开介绍这半年多来 AQE 特性在网易的实践经验和优化改进。
AQE 的设计思路
首先明确一个核心概念,AQE 的设计和优化完全围绕着 shuffle,也就是说如果执行计划里不包含 shuffle,那么 AQE 是无效的。常见的可能产生 shuffle 的算子比如 Aggregate(group by), Join, Repartition。
不同于传统以整个执行计划为粒度进行调度的方式,AQE 会把执行计划基于 shuffle 划分成若干个子计划,每个子计划用一个新的叶子节点包裹起来,从而使得执行计划的调度粒度细化到 stage 级别 (stage 也是基于 shuffle 划分)。这样拆解后,AQE 就可以在某个子执行计划完成后获取到其 shuffle 的统计数据,并基于这些统计数据再对下一个子计划动态优化。
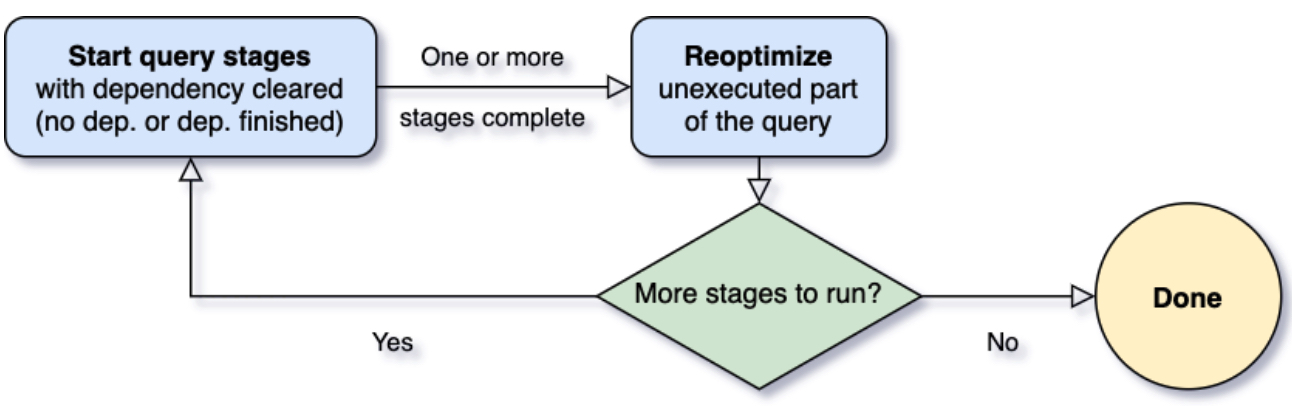
图片来自 databricks博客
有了这个调度流程之后,AQE 才可能有接下来的优化策略,从宏观上来看 AQE 优化执行计划的策略有两种:一是动态修改执行计划;二是动态生成 shuffle reader。
动态修改执行计划
动态修改执行计划包括两个部分:对其逻辑计划重新优化,以及生成新的物理执行计划。我们知道一般的 SQL 执行流程是,逻辑执行计划 -> 物理执行计划,而 AQE 的执行逻辑是,子物理执行计划 -> 父逻辑执行计划 -> 父物理执行计划,这样的执行流程提供了更多优化的空间。比如在对 Join 算子选择执行方式的时候可能有原来的 Sort Merge Join 优化为 Broadcast Hash Join。执行计划层面看起来是这样:
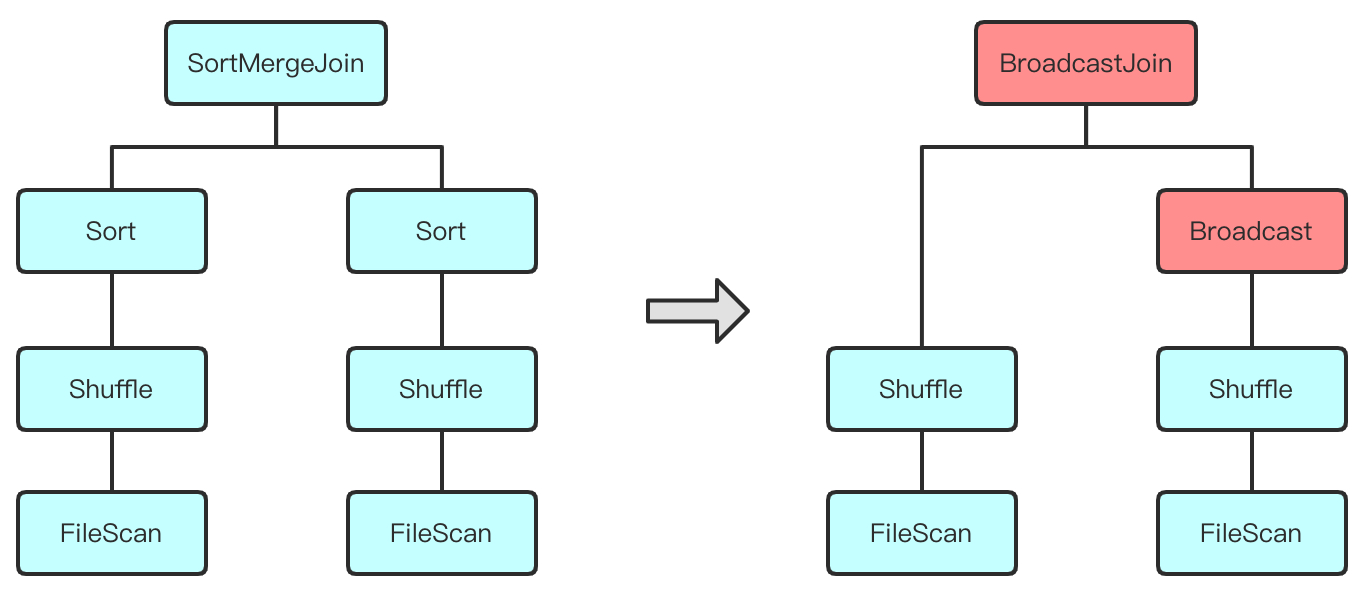
动态生成 Shuffle Reader
先明确一个简单的概念 map 负责写 shuffle 数据,reduce 负责读取 shuffle 数据。而 shuffle reader 可以理解为在 reduce 里负责拉 shuffle 数据的工具。标准的 shuffle reader 会根据预设定的分区数量 (也就是我们经常改的 spark.sql.shuffle.partitions),在每个 reduce 内拉取分配给它的 shuffle 数据。而动态生成的 shuffle reader 会根据运行时的 shuffle 统计数据来决定 reduce 的数量。下面举两个例子,分区合并和 Join 动态优化。
分区合并是一个通用的优化,其思路是将多个读取 shuffle 数据量少的 reduce 合并到 1 个 reduce。假如有一个极端情况,shuffle 的数据量只有几十 KB,但是分区数声明了几千,那么这个任务就会极大的浪费调度资源。在这个背景下,AQE 在跑完 map 后,会感知到这个情况,然后动态的合并 reduce 的数量,而在这个 case 下 reduce 的数量就会合并为 1。这样优化后可以极大的节省 reduce 数量,并提高 reduce 吞吐量。
Join 倾斜优化相对于分区合并,Join 倾斜优化则只专注于 Join 的场景。如果我们 Join 的某个 key 存在倾斜,那么对应到 Spark 中就会出现某个 reduce 的分区出现倾斜。在这个背景下,AQE 在跑完 map 后,会预统计每个 reduce 读取到的 shuffle 数据量,然后把数据量大的 reduce 分区做切割,也就是把原本由 1 个 reduce 读取的 shuffle 数据改为 n 个 reduce 读取。这样处理后就保证了每个 reduce 处理的数据量是一致的,从而解决数据倾斜问题。
AQE 优化规则实现都是非常巧妙的,其他更多优化细节就不展开了,推荐阅读 Kyuubi与AQE。
社区原生 AQE 的问题
看起来 AQE 已经是万能的,我们经常遇到的问题点都被覆盖到了,那么实际用起来的时候真的有这么丝滑吗?这里列举一些网易在使用 AQE 过程中遇到的痛点。
覆盖场景不足
就拿 Join 倾斜优化来说,这真的是一个非常棒的 idea,什么都很好但是有一个缺陷:覆盖的场景有限。在网易的深度实践过程中,经常会遇到一些 Join 明明就是肉眼可见的倾斜,但却没有被优化成想象中的样子。这种情况对用户来说会带来极大的困扰,在成百上千行的 SQL 里,哪些 Join 能被优化,哪些不能被优化?要花费很大一部分时间来去校验确认。
广播 Join 不可逆
广播配置 spark.sql.autoBroadcastJoinThreshold 是我们最常修改的配置之一,其优势是可以把 Join 用广播的形式实现,避免了数据 shuffle。但是广播有个很严重的问题:判定一张表是否可以被广播是基于静态的统计数据,特别是在经过一系列的过滤操作后,再完美的代价估计都是不精确的。由这个问题引发的任务失败报错就很常见了,Driver 端的 OOM,广播超时等。而 AQE 中的广播是不可逆的,也就是说如果一个 Join 在进入 AQE 优化前已经被选定为广播 Join,那么 AQE 无法再将其转换为其他 Join (比如 Sort Merge Join)。这对于一些由于错误估计大小而导致被广播的表是致命的。也是我们遇到影响任务稳定性的一大因素。
配置不够灵活
虽然 AQE 真的很好用,但是配置还是不够灵活。比如 stage 级别的配置隔离,我们知道 AQE 是基于 stage 的调度,那么更进一步的,SQL 的配置也可以是 stage 级别的,这样可以最细粒度的优化每一次 shuffle。听起来可能有点过犹不及的感觉,但是最容易遇到的一个需求就是单独设置最后一个 stage 的配置。最后一个 stage 是与众不同的,它代表着写操作,也就是说它决定了最终产生文件的数量。所以矛盾和痛点就这样出现了,最后一个 stage 考虑的是存储,是文件数,而过程中的 stage 考虑的是计算性能,是并发。
网易数帆在 AQE 上的改进
网易是 AQE 这个特性的重度使用者,当然不应该放着这些痛点不管,基于社区版本的分支下我们做了一系列的优化和增强,并且已经把其中的一部分内容 push 到了社区。在开源这个话题上,网易秉持着开放的理念。
回合社区补丁
Spark 的发布周期没有那么频繁,就算小版本迭代一般也要小半年,那么我们不可能只眼睁睁看着一系列的 bug 存在于旧分支。因此网易在 Spark 分支管理上的策略是:自己维护小版本,及时跟进大版本 (小版本可能是从 3.0.1 到 3.0.2,大版本则是从 3.0 到 3.1)。在这个策略下,我们可以及时回合社区新发现的问题。比如 AQE 相关的补丁 SPARK-33933,这个补丁的作用是在执行子物理计划的时候优先执行广播其次 shuffle,从而减小在调度资源不足情况下广播超时的可能性。社区的这个补丁需要到 3.2.0 分支才能发布,但是出于稳定性的考虑,网易内部把它回合到了 3.1.1 分支。
回馈社区
提高广播 Join 的稳定性
为了解决静态估计执行计划的统计数据不准确以及广播在 AQE 中不可逆的问题,我们支持了在 AQE 自己的广播配置 SPARK-35264。这个方案的思路是增加一个新的广播配置 spark.sql.adaptive.autoBroadcastJoinThreshold 和已有的广播配置隔离,再基于 AQE 运行时的统计数据来判断是否可以用广播来完成 Join,保证被广播表的数据量是可信的。在这个条件下,我们可以禁用基于静态估计的广播 Join,只开启 AQE 的广播,这样我们就可以在享受广播 Join 性能的同时兼顾稳定性。
增加 Join 倾斜优化覆盖维度
我们对 Join 倾斜优化做了很多增强,这个 case 是其中之一。在描述内容之前,我们先简单介绍一个 SHJ 和 SMJ (Shuffled Hash Join 简称为 SHJ,Sort Merge Join 简称 SMJ)。SMJ 的实现原理是通过先把相同 key shuffle 到同一 reduce,然后做分区内部排序,最后完成 Join。而 SHJ 相对于 SMJ 有着优秀的时间复杂度,通过构建一个 hash map 做数据配对,节省了排序的时间,但缺点也同样明显,容易 OOM。
一直以来 SHJ 是一个很容易被遗忘的 Join 实现,这是因为默认配置 spark.sql.preferSortMerge 的存在,而且社区版本里触发 SHJ 的条件真的很苛刻。但自从 Spark 3.0 全面地支持了所有类型的 Join Hint SPARK-27225,SHJ 又逐渐进入了我们的视野。回到正题,社区版本的 AQE 目前只对 SMJ 做了倾斜优化,这对于显式声明了 Join Hint 为 SHJ 的任务来说很不友好。在这个背景下,我们增加了 AQE 对 SHJ 倾斜优化的支持 SPARK-35214,使得 Join 倾斜优化在覆盖维度上得到了提升。
一些琐碎的订正
由于 Spark 在网易内部的使用场景是非常多的,包括但不限于数仓,ETL,Add hoc,因此我们需要最大程度减少负面的和误导用户的 case。
SPARK-35239,这个 issue 可以描述为当输入的 RDD 分区是空的时候无法对其 shuffle 的分区合并。看起来影响并不大,如果是空表的话那么就算空跑一些任务也是非常快的。但是在 Add hoc 场景下,默认的 spark.sql.shuffle.partitions 配置调整很大,这就会造成严重的 task 资源浪费,并且加重 Driver 的负担
SPARK-34899,当我们发现某些 shuffle 分区在被 AQE 的分区合并规则成功优化后,分区数居然没有下降,一度怀疑是没有找到正确使用 AQE 的姿势
SPARK-35168,一些 Hive 转过来的同学可能会遇到的 issue,理论上 MapReduce 中 reduce 的数量等价于 Spark 的 shuffle 分区数,所以 Spark 做了一些配置映射。但是在映射中出现了 bug 这肯定是不能容忍的。
内部优化(已开源)
除了和社区保持交流之外,网易数帆也做了许多基于 AQE 的优化,这些优化都在我们的开源项目 Kyuubi 里。
支持复杂场景下 Join 倾斜优化
社区版本对 AQE 的优化比较谨慎,只对标准的 Sort Merge Join 做了倾斜优化,也就是每个 Join 下的子算子必须包含 Sort 和 Shuffle,这个策略极大的限制了 Join 倾斜优化的覆盖率。举例来说,有一个执行计划先 Aggregate 再 Join,并且这两个算子之间没有出现 shuffle。我们可以猜到,在没有 AQE 的介入下,Aggregate 和 Join 之间的 shuffle 被剪枝了,这是一种常见的优化策略,一般是由于 Aggregate 的 key 和 Join 的 key 存在重复引起的。但是由于没有击中规则,AQE 无法优化这个场景的 Join。有一些可以绕过去的方法,比如手动在 Aggregate 和 Join 之间插入一个 shuffle,得到的执行计划长这样子:
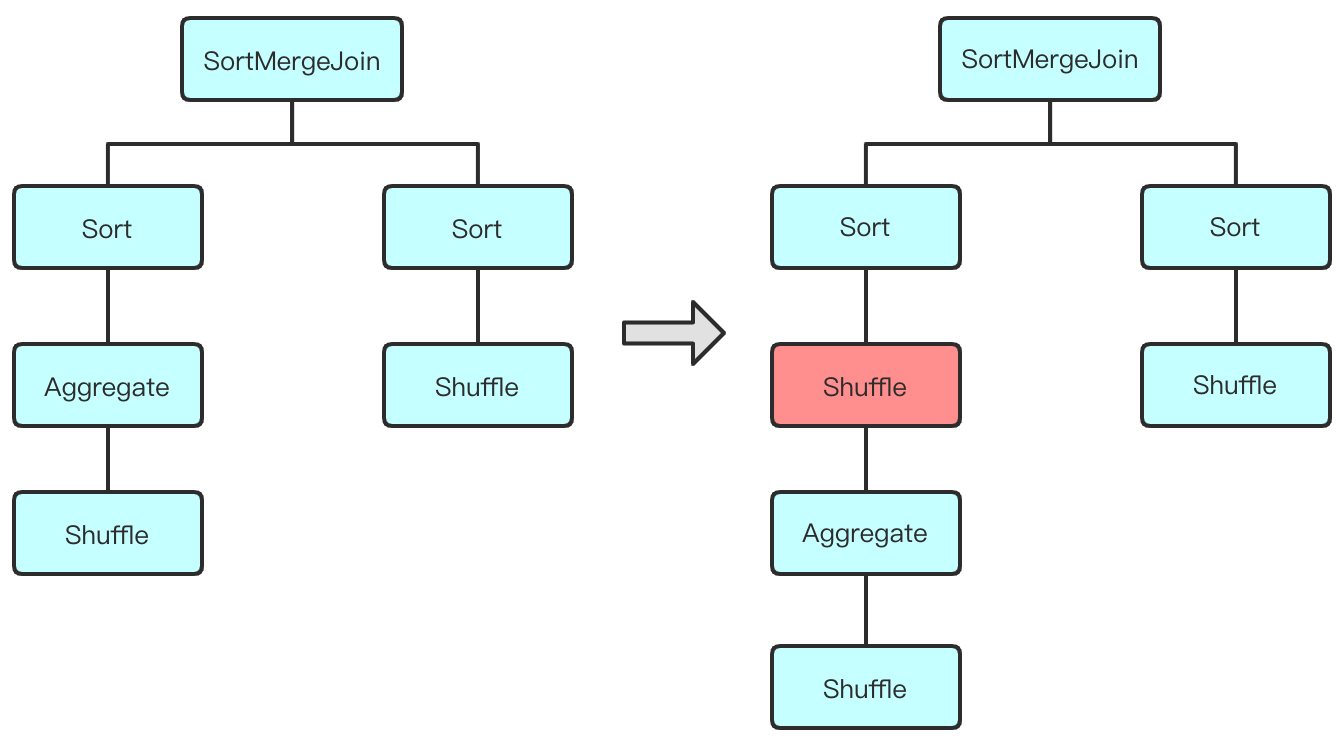
我们在这种思路下,以增加规则的方式可以在不入侵 AQE 代码的前提下,自动增加 shuffle 来满足 Join 倾斜优化的触发条件。选择这样处理的理由有 3 个
增加 shuffle 可以带来另一个优秀的副作用,就是支持多表 Join 场景下的优化,可以说是一举两得
不用魔改 AQE 的代码,可以独立于我们内部的 Spark 分支快速迭代
当然这不是最终的解决方案,和社区的交流还在继续
小文件合并以及 stage 级别的配置隔离
Spark 的小文件问题已经存在很多年了,解决方案也有很多。而 AQE 的出现看起来可以天然的解决小文件问题,因此网易内部基于 AQE 的分区合并优化规则,对每个涉及写操作的 SQL,在其执行计划的顶端动态插入一个 shuffle 节点,从执行计划的角度看起来是这样的:
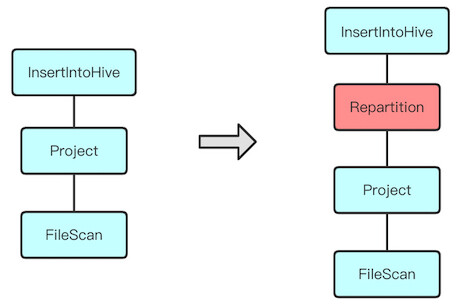
再结合可以控制每个分区大小的相关配置,看起来一切都是这么美好。但问题还是来了,其中有两个最明显的问题:
简单添加一个 shuffle 节点无法满足动态分区写的场景
假设我们最终产生 1k 个分区,动态插入的分区值的数量也是 1k,那么最终会产生的文件数是 1k x 1k = 1m。这肯定是不能被接受的,因此我们需要对动态分区字段做重分区,让包含相同分区值的数据落在同一个分区内,这样 1k 个分区生成的文件数最多也是 1k。但是这样处理后还有有一个潜在的风险点,不同分区值的分布是不均匀的,也就是说可能出现数据倾斜问题。对于这样情况,我们又额外增加了与业务无关的重分区字段,并通过配置的方式帮助用户快速应对不同的业务场景。
单分区处理的数据量过大导致性能瓶颈
成也萧何,败也萧何。把 spark.sql.adaptive.advisoryPartitionSizeInBytes 调大后小文件的问题是解决了,但是过程中每个分区处理的数据量也随之增加,这导致过程中的并发度无法达到预期的要求。因此 stage 级别的配置隔离出现了。我们直接把整个 SQL 配置划分为两部分,最后一个 stage 以及之前的 stage,然后把这两个部分之间的配置做了隔离。拿上面这个配置来说,在最后一个 stage 的样子是 spark.sql.finalStage.adaptive.advisoryPartitionSizeInBytes。在配置隔离的帮助下,我们可以完美解决小文件和计算性能不能兼得的问题,用户可以更加优雅地使用 AQE。
案例分享
多表 Join 倾斜
下面这两张图为 3 表 Join 的执行计划,由于长度的限制我们只截取到 Join 相关的片段,并且没有被优化的任务由于数据倾斜问题没有执行成功。可以明显看到社区版本无法对这类多表 Join 做倾斜优化,而我们在动态插入 shuffle 之后,两次 Join 都成功的被优化。在这个特性的帮助下,Join 倾斜优化的覆盖场景相对于社区有明显提升。
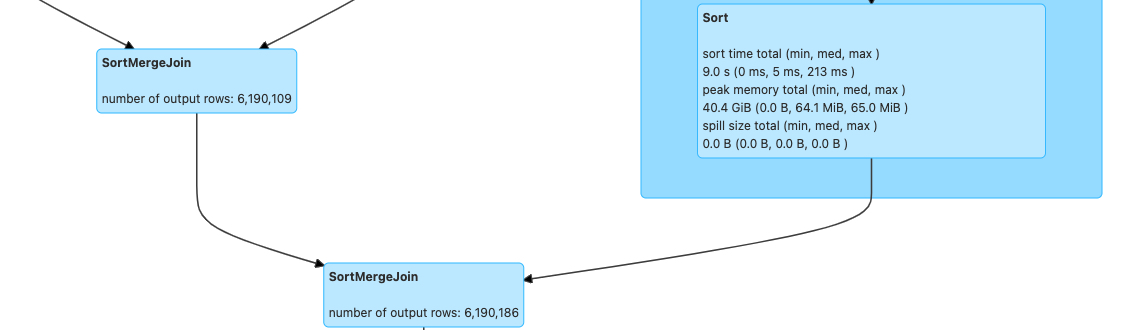
社区版本
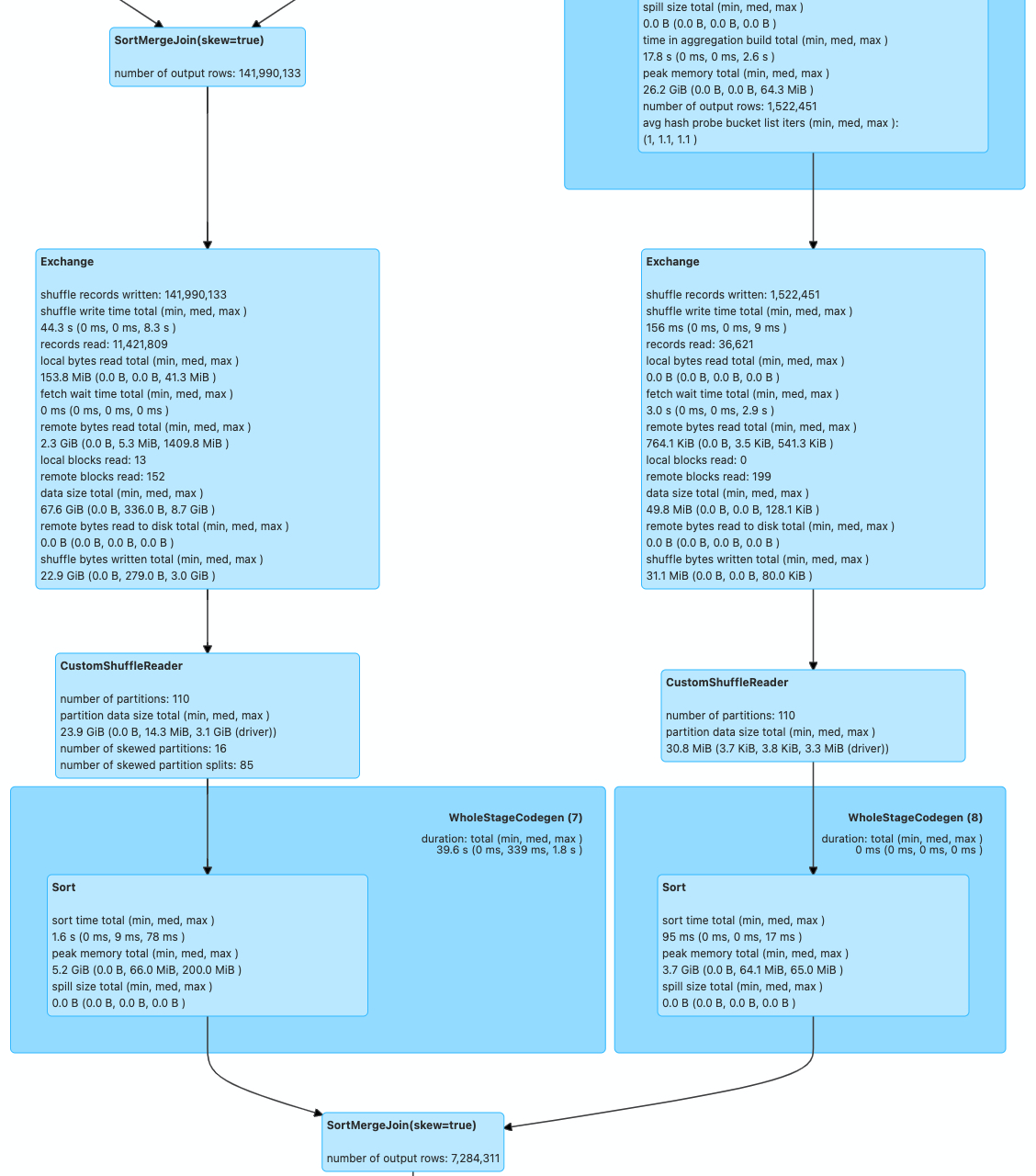
内部版本
Stage 配置隔离
在支持了 stage 级别的配置隔离后,我们单独设置了最后一个 stage 的参数,下面两张图是某个线上任务前后两天的执行情况,可以明显看到在配置隔离后,在保证最终产出的文件数一致的情况下,过程中 stage 的并发度得到了提升,从而使任务性能得到提升。
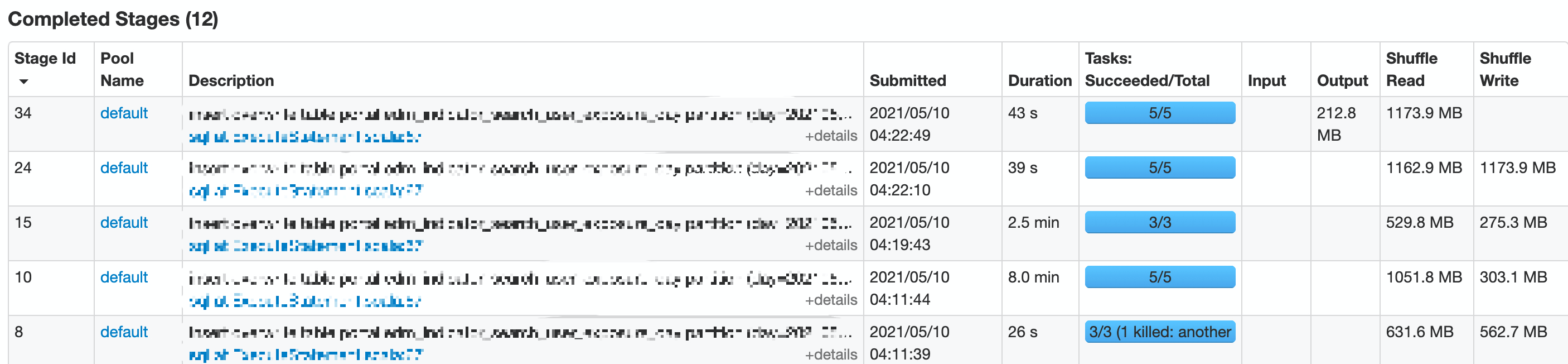
配置隔离前
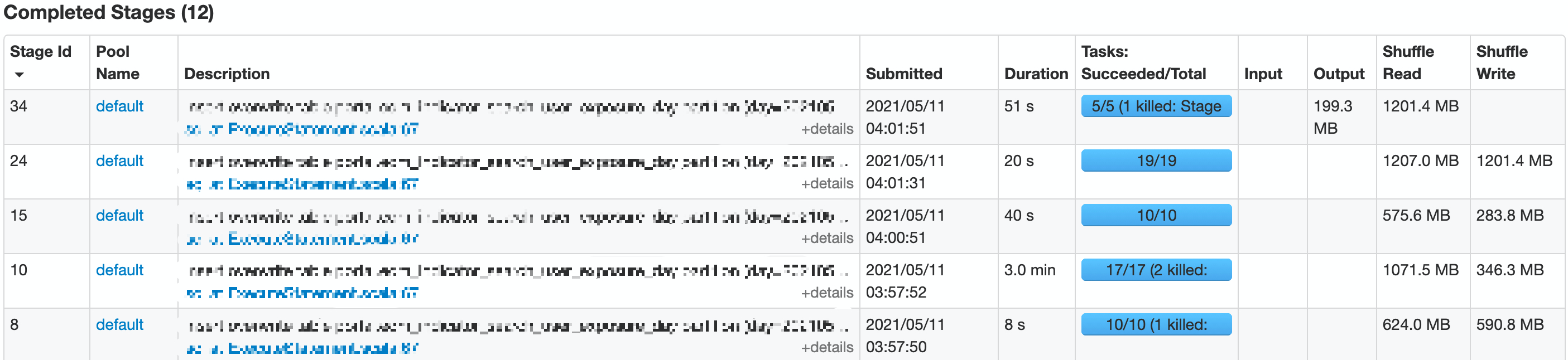
配置隔离后
任务性能对比
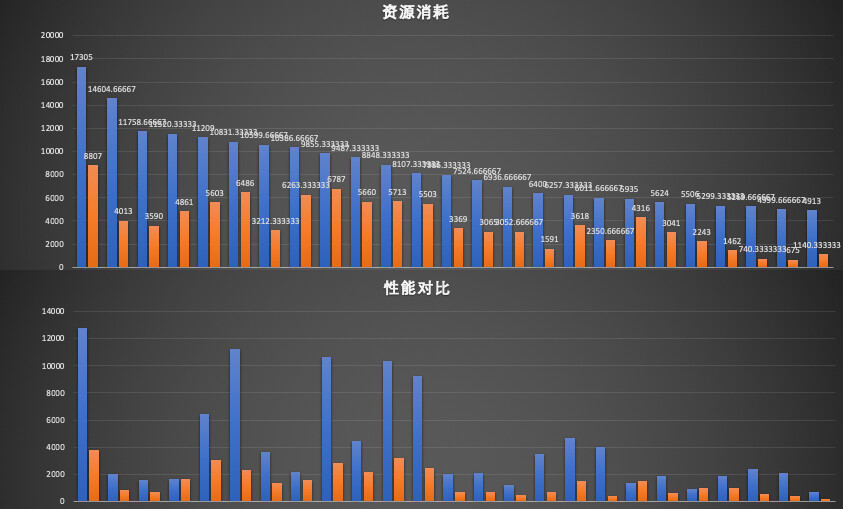
这张图展示了我们部分迁移任务的资源成本以及性能对比,其中蓝线是迁移前的数据,红线是迁移后的数据。可以非常明显看到,在资源成本大幅下降的同时任务性能有不同程度的提升。
总结与展望
首先得感谢一下 Apache Spark 社区,在引入了 AQE 之后,我们的线上任务得到了不同程度的性能提升,也使得我们在遇到问题的时候可以有更多解决问题的思路。在深度实践的过程中,我们也发现了一些可以优化的点:
在优化细节上的角度,可以增加命中 AQE 优化的 case,比如 Join 倾斜优化增强,让用户不用逐个检查不能被优化的执行计划
在业务使用上的角度,可以同时支持 ETL,Add hoc 等侧重点不一样的场景,比如 stage 配置隔离这个特性,让关注写和读的业务都有良好的体验
在完成这个阶段性的优化后,接下来我们会继续深耕在 AQE 的覆盖场景上,比如支持 Union 算子的细粒度优化,增强 AQE 的代价估计算法等。除此之外,还有一些潜在的性能回归问题也是值得我们注意的,比如在做分区合并优化后会放大某些高时间复杂度算子的性能瓶颈。
作为可能是最快在线上使用 Apache Spark 3.1.1 的用户,网易在享受社区技术福利的同时也在反哺社区。这也是网易对技术的思考和理念:
因为开放,我们拥抱开源,深入社区
因为热爱,我们快速接收新的理论,实践新的技术
作者简介:尤夕多,目前就职于网易数帆-有数事业部,专注于开源大数据领域。网易数帆开源项目 Kyuubi Committer / Apache Spark Contributor。




