
什么是链路追踪?微服务引发了怎样的问题?
在深入了解分布式链路追踪技术之前,我们需要先理解这项技术产生的背景,以及它能够帮我们解决哪些棘手的问题。
提到分布式链路追踪,我们要先提到微服务。相信很多人都接触过微服务,这里再回顾下基本概念:微服务是一种开发软件的架构和组织方法,它侧重将服务解耦,服务之间通过 API 通信。它使程序更与扩展性和小团队独立开发。从而加速新功能上线。
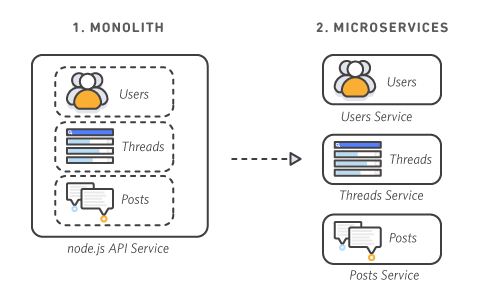
微服务演变-亚马逊云
加速研发快速迭代,让微服务在业务驱动的互联网领域全面普及,独领风骚。但是,随之而来也产生了新问题:当生产系统面对高并发,或者解耦成大量微服务时,以前很容易就能实现的监控、预警、定位故障就变困难了。
我拿研发的搜索系统的经历,结合场景给大家聊聊(曾经这套系统要去抗峰值到日均 10 亿 PV、5 千万 UV 的高并发)
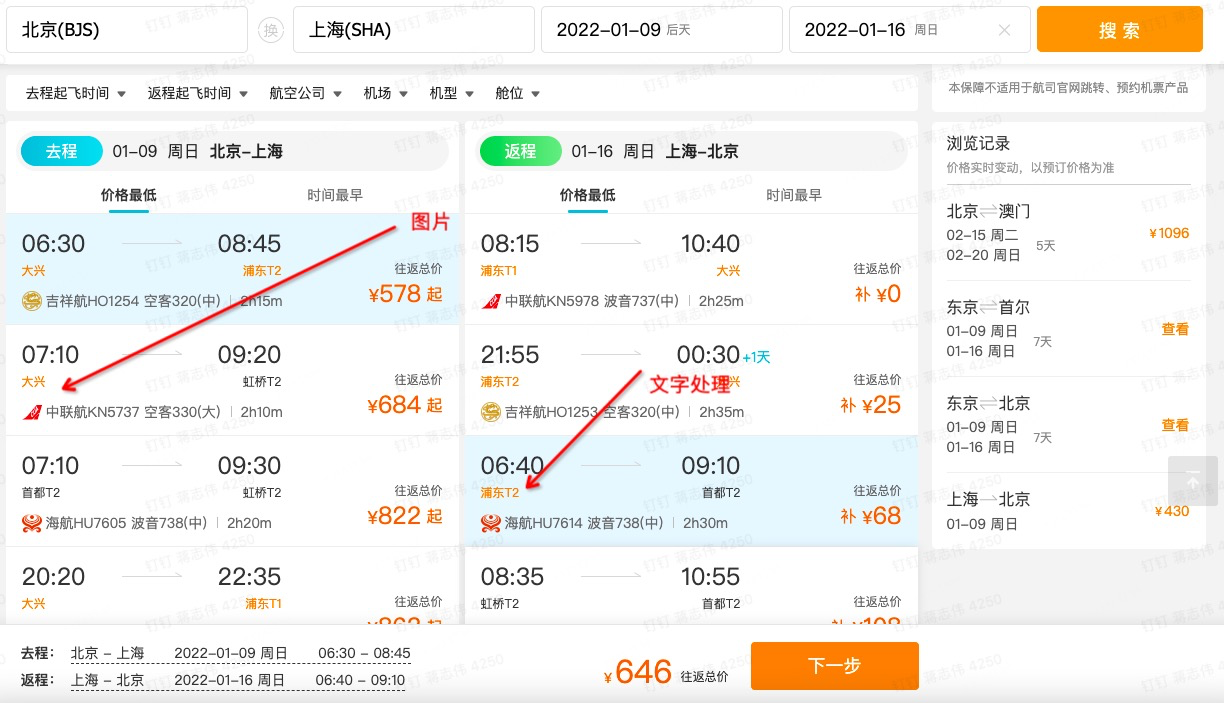
机票搜索演示图
比如搜索机票这样一个行为,其实是对上百个查询服务器发起了一个查询,这个查询会被发送到多个微服务系统,这些微服务系统分别用来处理航班信息、查询有无舱位、机票价格、机场关键字匹配,查找图片资源等等。每个子系统的查询最终聚合得到的结果,会汇总到搜索结果页上。
用户一次查询,做了这么一个“全局搜索”。任何一个子系统变慢,都会导致最终的搜索变得慢,那用户体验就会很差了。
看到这里,你可能会想,体验差我们做搜索优化不就好了么?确实如此,但一般情况,一个前端或者后端工程师虽然知道系统查询耗时,但是他无从知晓这个问题到底是由哪个服务调用造成的,或者为什么这个调用性能差强人意。
首先,这个工程师可能无法准确定位到这次全局搜索是调用了哪些服务,因为新的服务、乃至服务上的某个功能,都有可能在任何时间上过线或修改过。其次,你不能苛求这个工程师对所有参与这次全局搜索的服务都了如指掌,每一个服务都有可能是由不同的团队开发或维护的。再次,搜索服务还同时还被其他客户端使用,比如手机端,这次全局搜索的性能问题甚至有可能是由其他应用造成的。这是过去我的团队面临的问题,微服务让我们的工程师观察用户行为,定位服务故障很棘手。
为什么需要链路追踪
刚才说的情况,我们迫切需要一些新工具,帮我们理解微服务分布式系统的行为、精准分析性能问题。于是,分布式系统下链路追踪技术(Distributed Tracing)出现了。
它的核心思想是:在用户一次请求服务的调⽤过程中,无论请求被分发到多少个子系统中,子系统又调用了更多的子系统,我们把系统信息和系统间调用关系都追踪记录下来。最终把数据集中起来可视化展示。它会形成一个有向图的链路,看起来像下面这样
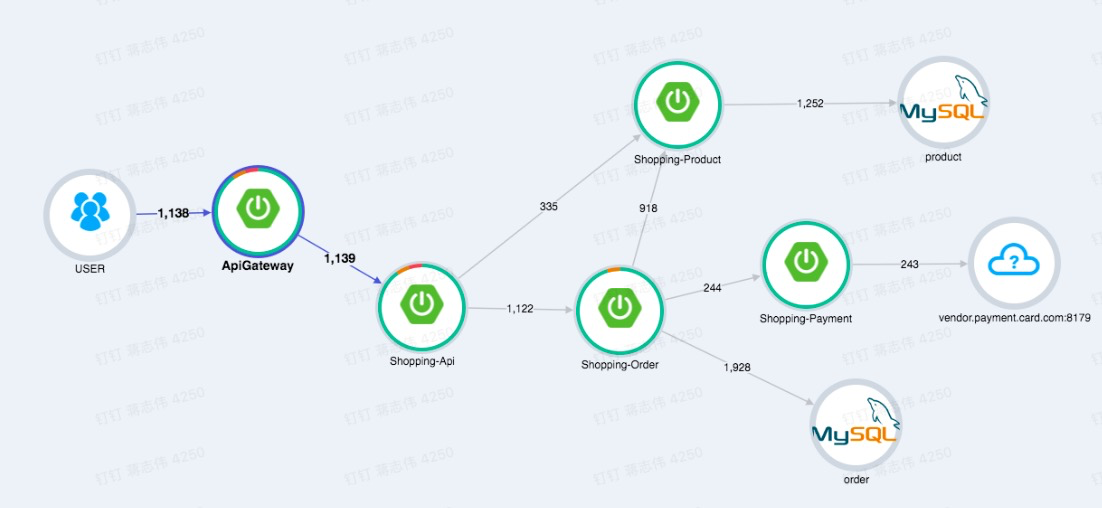
图一:电商系统的链路追踪图
什么是 Trace
后来,链路追踪技术相关系统慢慢成熟,涌现了像 Dapper、Zipkin、HTrace、OpenTelemetry 等优秀开源系统。他们也被业界,特别是互联网普遍采用。
目前 Dapper(诞生于 Google 团队)应用影响最大,OpenTelemetry 已经成为最新业界标准,我们重点基于它们讲解 Trace 原理。
快速入门
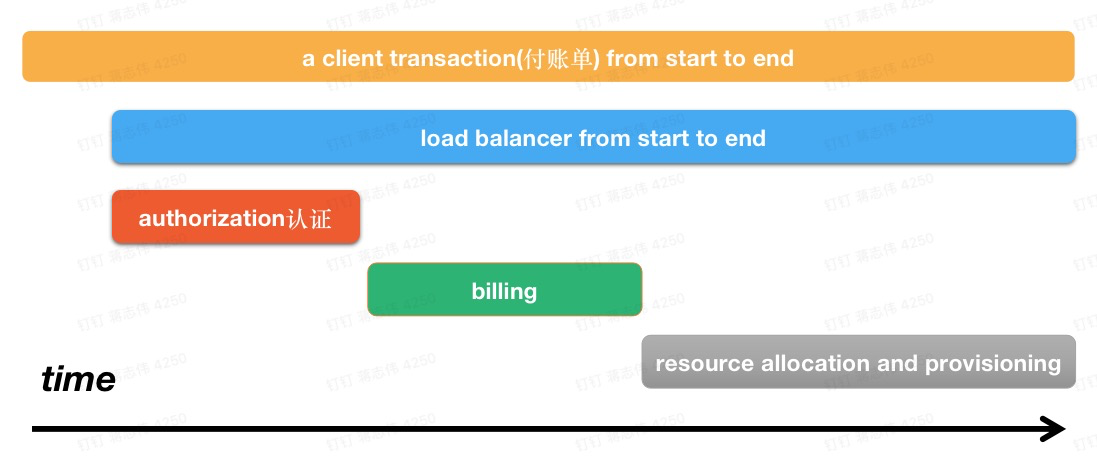
我们看看一个例子,某商家给(顾客)开账单(要求付款),在系统中大体的流程:
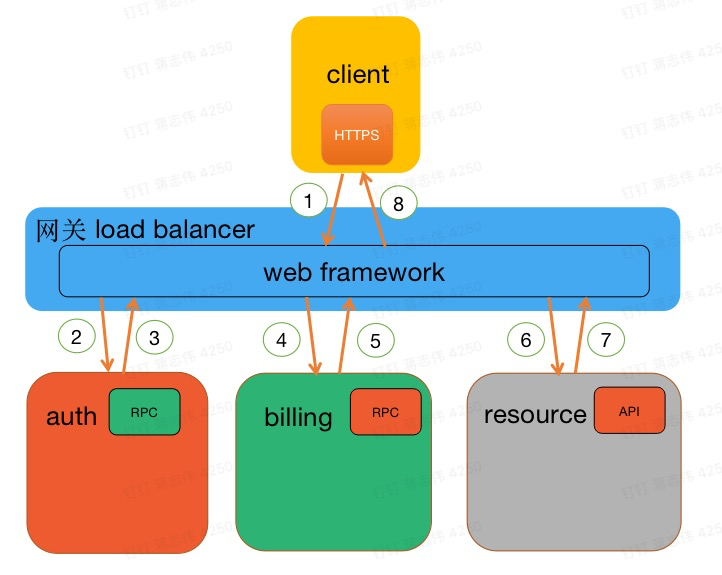
图二:一个开账单的例子
当商家从 client 发起开账单服务,请求从 client 程序先后进行了一系列操作:
网关 load balancer:client 的 https 请求先经过网关,网关调用下面的子系统;
身份认证 auth:网关 RPC 请求到服务 auth,auth 发起身份认证,完成后通知网关程序;
生成账单 billing:身份认证成功后,网关再发送 RPC 请求到服务 billing,billing 是生成账单的操作,billing 处理完通知网关下一步;
资源加载 resource:billing 成功,网关发送一个 HTTP 请求到服务 resource,加载和账单相关资源,比如静态图片,相关顾客资料,resource 完成通知网关;
最后网关程序处理完开账单服务,返回结果给 client;
例子中,我们把开账单服务一个流程或者叫一个事务称为 Trace。这里面有几个操作,分别是请求网关、身份认证、生成账单、加载资源,我们把每个操作(Operation)称为一个 Span。
Trace 数据模型
我们看看 Trace 广义的定义:Trace 是多个 Span 组成的一个有向无环图(DAG),每一个 Span 代表 Trace 中被命名并计时的连续性的执行片段。我们一般用这样数据模型描述 Trace 和 Span 关系:
[Span user click] ←←←(the root Span) | [Span gateway] | +------+----------+-----------------------+ | | |[Span auth] [Span billing] [Span loading resource]图三:开账单 Trace 数据模型
数据模型包含了 Span 之间关系。Span 定义了父级 Span,子 Span 的概念。一个父级的 Span 会并行或者串行启动多个子 Span。图三,gateway 就是 auth、billing 的父级 Span。
上面这种图对于看清各组件的组合关系是很有用的,但是,它不能很好显示组件的调用时间,是串行调用还是并行调用。另外,这种图也无法显示服务调用的时间和先后顺序。因此,在链路追踪系统会用另一种图展现一个典型的 Trace 过程,如下面所示:
这种展现方式增加显示了执行时间的上下文,相关服务间的层次关系,任务的串行或并行调用关系。这样的视图有助于发现系统调用的关键路径。通过关注关键路径的执行过程,项目团队可能专注于优化路径中的关键位置,最大幅度的提升系统性能。例如:可以通过追踪一个用户请求访问链路,观察底层的子系统调用情况,发现哪些操作有耗时重要关注优化。Span 基本结构前面提到 Span 通俗概念:一个操作,它代表系统中一个逻辑运行单元。Span 之间通过嵌套或者顺序排列建立因果关系。Span 包含以下对象:
操作名称 Name : 这个名称简单,并具有可读性高。例如:一个 RPC 方法的名称,一个函数名,或者一个大型计算过程中的子任务或阶段;
起始时间和结束时间:操作的生命周期;
属性 Attributes: 一组
事件 Event;
上下文 SpanContext: Span 上下文内容;
链接 Links:描述 Span 节点关系的连线,它的描述信息保存在 SpanContext 中;
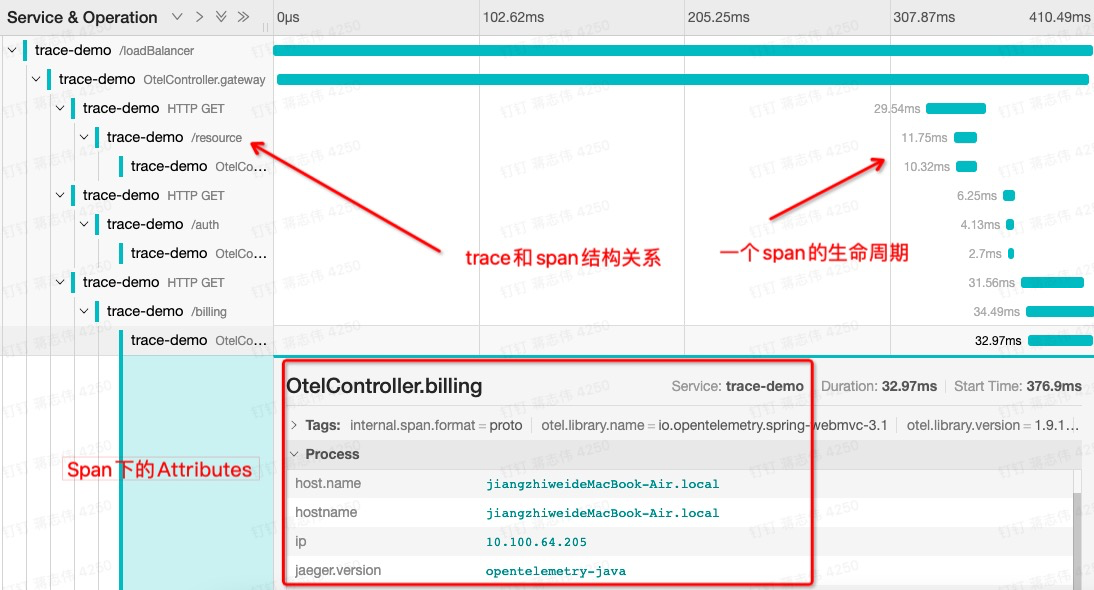
图四:可观测平台下的 Span
属性 Attributes
我们分析一个 Trace,通过 Span 里键值对
网络连接 Attributes:这些 Attributes 用在网络操作相关;
线程 Attributes
这些 Attributes 记录了启动一个 Span 后相关线程信息。考虑到系统可以是不同开发语言,相应还会记录相关语言平台信息。下面是不同语言开发的平台获取线程 Id、Name 方法。
记录线程信息,对于我们排查问题时候非常必要的,当出现一个程序异常,我们至少要知道它什么语言开发,找到对于研发工程师。研发工程师往往需要线程相关信息快速定位错误栈。
Span 间关系描述 Links
我们看看之前 Span 数据模型:
[Span gateway] | +------+------+------------------+ | | |[Span auth] [Span billing] [Span loading resource]一个 Trace 有向无环图,Span 是图的节点,链接就是节点间的连线。可以看到一个 Span 节点可以有多个 Link,这代表它有多个子 Span。
Trace 定义了 Span 间两种基本关系:
ChildOf: Span A 是 Span B 的孩子,即"ChildOf"关系FollowsFrom: Span A 是 Span B 的父级 Span
SpanSpan 上下文信息 SpanContext
字面理解 Span 上下文对象。它作用就是在一个 Trace 中,把当前 Span 和 Trace 相关信息传递到下级 Span 。它的基本结构类似
TraceId:随机 16 字节数组。比如 4bf92f3577b34da6a3ce929d0e0e4736
SpanId:随机 8 字节数组。比如 00f067aa0ba902b7
Baggage Items 是存在于 Trace 一个键值对集合,也需要 Span 间传输。
Trace 链路传递初探
在一个链路追踪过程中,我们一般会有多个 Span 操作, 为了把调用链状态在 Span 中传递下去,期望最终保存下来,比如打入日志、保存到数据库。SpanContext 会封装一个键值对集合,然后将数据像行李一样打包,这个打包的行李 OpenTelemetry 称为 Baggage(背包) 。
Baggage 会在一条追踪链路上的所有 Span 内全局传输。在这种情况下,Baggage 会随着整个链路一同传播。我们可以通过 Baggage 实现强大的追踪功能。
首先,我们在 loadBalancer 请求中加一个 Baggage,loadBalancer 请求了 source 服务:
@GetMapping("/loadBalancer")@ResponseBodypublic String loadBalancer(String tag){ Span span = Span.current(); //保存 Baggage Baggage.current() .toBuilder() .put("app.username", "蒋志伟") .build() .makeCurrent();...... ##请求 resourcehttpTemplate.getForEntity(APIUrl+"/resource",String.class).getBody();
然后我们从 resource 服务中获取 Baggage 信息,并把它存储到 Span 的 Attributes 中:
@GetMapping("/resource")@ResponseBodypublic String resource(){ String baggage = Baggage.current().getEntryValue("app.username"); Span spanCur = Span.current(); ##获取当前的 Span,把 Baggage 写的 resource spanCur.setAttribute("app.username", "baggage 传递过来的 value: "+baggage);
最终,我们从跟踪系统的链路 UI 中点击 source 这个 Span,找到传递的 Baggage 信息:
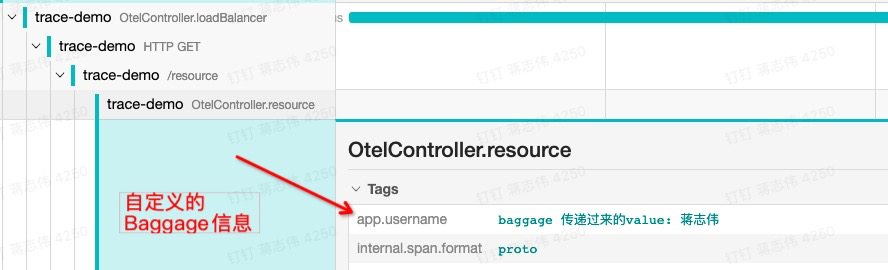
图五:展示 Baggage 的传递
当然,Baggage 拥有强大功能,也会有很大的消耗。由于 Baggage 的全局传输,每个键值都会被拷贝到每一个本地(local)及远程的子 Span,如果包含的数量量太大,或者元素太多,它将降低系统的吞吐量或增加 RPC 的延迟。
链路添加业务监控
我们进行系统链路追踪,除了 Trace 本身自带信息,如果我们还希望添加自己关注的监控。Trace 支持用打标签 Tags 方式来实现。Tags 本质还是 Span 的 Attributes(在 OpenTelemetry 定义中,统称 Attributes。在 Prometheus、Jaeger 里面沿袭 Tags 老的叫法)。
打 Tags 的过程,其实就是在 Span 添加我们自定义的 Attributes 信息,这些 Tags 大部分和我们业务息息相关,为了更方便做业务监控、分析业务。
我们看一个 Java 打 Tags 的例子:页面定义好了一个 Tag,名字叫"username"。我们输入 Tags 的值,然后把 Tags 通过一个 HTTP 请求发送给付账单的 API。
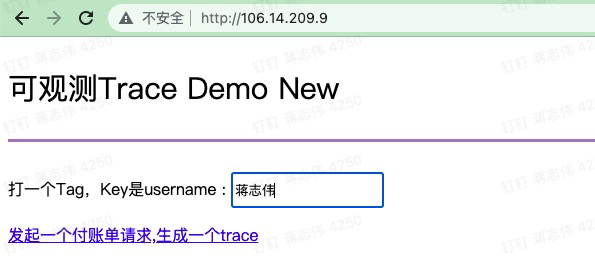
图六:打 Tags 的演示
API 获取 Tags 后,把它保存到当前 Span 的 Attribute 中。这个 Span 对应的是代码里面的一个 gateway 方法, 如果不重名 Span 名称,默认使用 gateway 作为 Span 名称:
@GetMapping("/loadBalancer")public String gateway(String tag){ Span Span = Span.current(); ##获取当前 Span,添加 username 的 tag Span.setAttribute("username", tag); ...... }
打了 Tags 后,我们可以在跟踪系统搜索 Tag 关键字。通过 Tag 可以快速找到对应的 Trace。
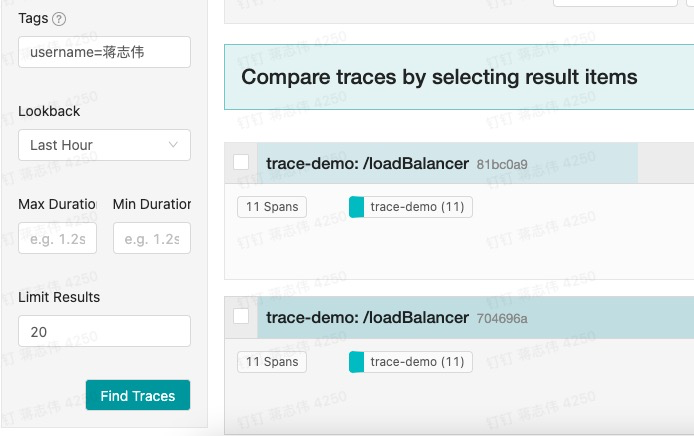
图七:基于 Tags 的搜索
可以看到,根据 Tags 的 key 我们可以很方便筛选想要的 Span 信息。实际场景里,我们面临是从成千上万链路中快速定位访问异常的请求。打 Tags 对我们诊断程序非常有帮助。
Baggage 和 Span Tags 的区别:
Baggage 在全局范围内,(伴随业务系统的调用)在所有 Span 间传输数据。Tags 不会进行传输,因为他们不会被子级的 Span 继承。
Span 的 Tags 可以用来记录业务相关的数据,并存储于追踪系统中。
全链路兼容性考虑
在不同的平台、不同的开发语言、不同的部署环境(容器非容器)下,为了保证底层追踪系统实现兼容性,将监控数据记录到一个可插拔的 Tracer 上。在绝大部分通用的应用场景下,追踪系统考虑使用某些高度共识的键值对,从而对诊断应用系统更有兼容,通用性。
这个共识称为语义约定 Semantic conventions。你会从下面一些语义约定看出 Trace 做了哪些兼容性:
General: 通用约定,之前提到网络连接 Attributes,线程 Attributes
HTTP: 针对 HTTP 请求的数据约定
Database: 数据库数据约定,包括 SQL 和 NOSQL 不同类型
RPC/RMI: 有关远程调用的约定
Messaging: 有关消息系统的 Span 约定,例如 MQ 的订阅、发布等
Exceptions: 针对异常,错误状态等
例如,我们访问 HTTP 的应用服务器。应用系统处理请求中的 URL、IP、HTTP 动作(get/post 等)、返回码,对于应用系统的诊断是非常有帮助的。监控者可以选择 HTTP 约定参数记录系统状态,像下面 Trace 展示的结果。
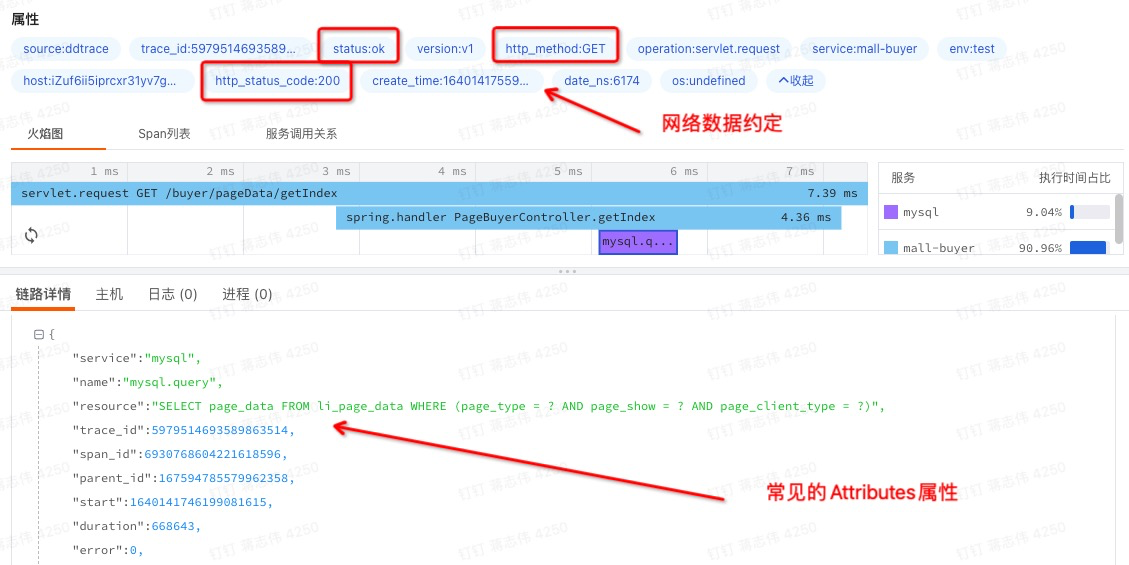
图九:Trace 默认的语义约定
最后,基于开账单例子,我们完整从监控平台上看看 Trace 的全貌:
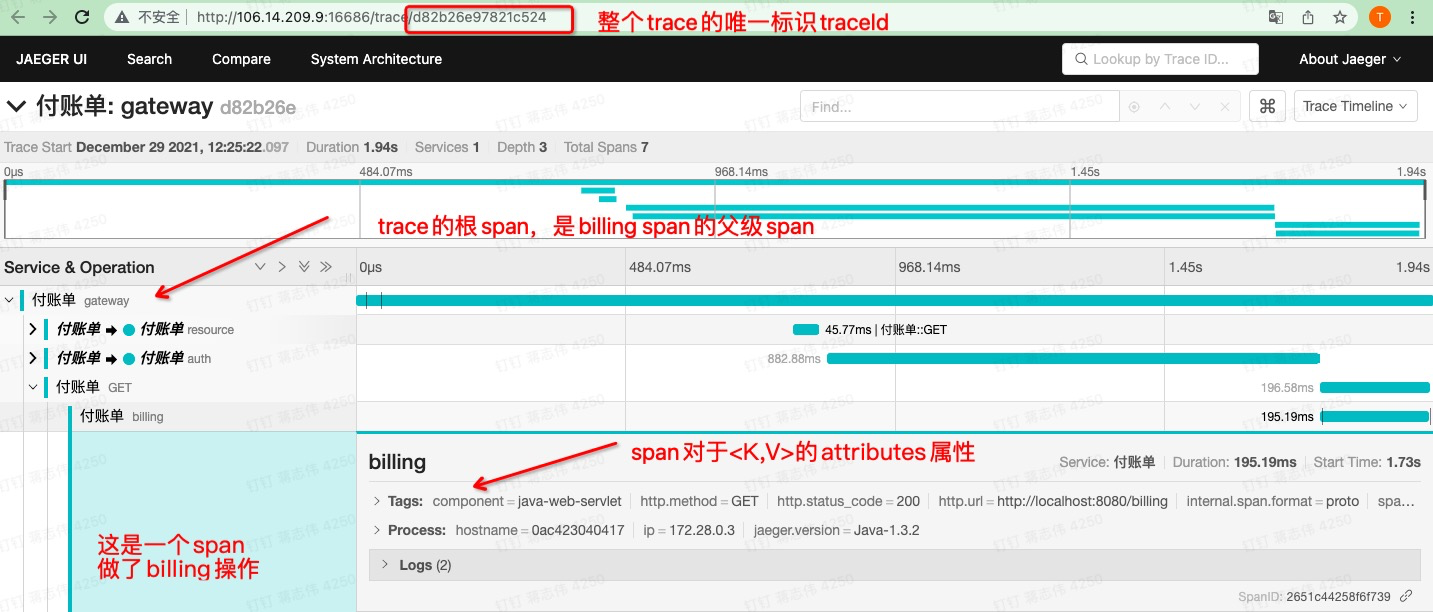
图十:付账单链路图
链路数据如何传播
在 Trace 传递中有一个核心的概念,叫 Carrier(搬运工具)。它表示"搬运" Span 中 SpanContext 的工具。比方说 Trace 为了把 Span 信息传递下去,在 HTTP 调用场景中,会有 HttpCarrier,在 RPC 的调用场景中会有 RpcCarrier 来搬运 SpanContext。Trace 通过 Carrier 可以把链路追踪状态从一个进程"搬运"到另一个进程里。
数据传播基本操作
为了更清晰看懂数据传播的过程,我们先了解 Span 在传播中有的基本操作
StartSpan:Trace 在具体操作中自动生成一个 Span
Inject 注入: 将 Span 的 SpanContext 写入到 Carrier 的过程
链路数据为了进行网络传输,需要数据进行序列化和反序列化。这个过程 Trace 通过一个负责数据序列化反序列化上下文的 Formatter 接口实现的。例如在 HttpCarrier 使用中通常就会有一个对应的 HttpFormatter。所以 Inject 注入是委托给 Formatter 将 SpanContext 进行序列化写入 Carrier。
Formatter 提供不同场景序列化的数据格式,叫做 Format 描述。比如:
Text Map: 基于字符串的 Map 记录 SpanContext 信息,适用 RPC 网络传输
HTTP Headers: 方便解析 HTTP Headers 信息,用于 HTTP 传输
一个 Python 程序实现 Inject 注入过程,Formatter 序列化 SpanContext 成 Text Map 格式。
##Trace 生成一个span tracer = Tracer() span = tracer.start_span(operation_name='test') tracer.inject( span_context=span.context, format=Format.TEXT_MAP, carrier=carrier)
Extract 提取: 将 SpanContext 从 Carrier 中 Extract(提取出来)
span_ctx = tracer.extract(format=Format.TEXT_MAP, carrier={})
同理,从 Carrier 提取的过程也需要委托 Formatter 将 SpanContext 反序列化。
运行原理
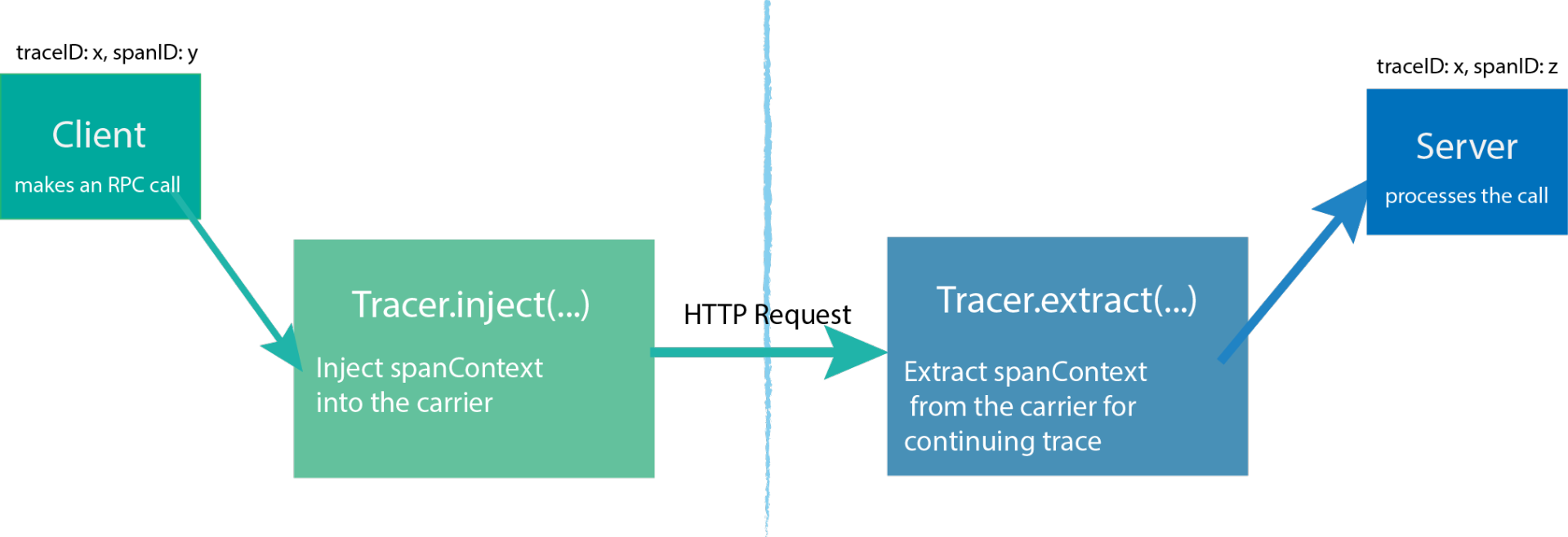
图一:链路数据在 HTTP 传递
我们基于 HTTP 通信解释传播原理。由图一,这个过程大致分为两步:
1、发送端将 SpanContext 注入到请求中,相应伪代码实现
/**** 将 SpanContext 中的 TraceId,SpanId,Baggage 等根据 format 参数注入到请求中(Carrier)** carrier := opentracing.HTTPHeadersCarrier(httpReq.Header)** err := Tracer.Inject(Span.Context(), opentracing.HTTPHeaders, carrier)**/Inject(sm SpanContext, format interface{}, carrier interface{}) error2、接收端从请求中解析出 SpanContext,相应伪代码实现
// Inject() takes the `sm` SpanContext instance and injects it for// propagation within `carrier`. The actual type of `carrier` depends on/** 根据 format 参数从请求(Carrier)中解析出 SpanContext(包括 TraceId、SpanId、baggage)。** 例如: ** carrier := opentracing.HTTPHeadersCarrier(httpReq.Header)** clientContext, err := Tracer.Extract(opentracing.HTTPHeaders, carrier)**/Extract(format interface{}, carrier interface{}) (SpanContext, error)
Carrier 负责将追踪状态从一个进程"Carry"(搬运)到另一个进程。对于一个 Carrier,如果已经被 Injected,那么它也可以被 Extracted(提取),从而得到一个 SpanContext 实例。这个 SpanContext 代表着被 Injected 到 Carrier 的信息。
说到这里,你可能想知道这个 Carrier 在 HTTP 中具体在哪。其实它就保存到 HTTP 的 Headers 中。而且,W3C 组织为 HTTP 支持链路追踪专门在 Headers 中定义了 Trace 标准:
https://www.w3.org/TR/trace-context/#trace-context-http-headers-format
W3C 组织是对网络标准制定的一个非盈利组织,W3C 是万维网联盟的缩写,像 HTML、XHTML、CSS、XML 的标准就是由 W3C 来定制
跨进程间传播数据
数据传播按照场景分为两类:进程内传播、跨进程间传播 Cross-Process-Tracing。
进程内传播是指 Trace 在一个服务内部传递,监控了服务内部相互调用情况,相当比较简单。追踪系统最困难的部分就是在分布式的应用环境下保持追踪的正常工作。任何一个追踪系统,都需要理解多个跨进程调用间的因果关系,无论他们是通过 RPC 框架、发布-订阅机制、通用消息队列、HTTP 请求调用、UDP 传输或者其他传输模式。所以业界谈起 Tracing 技术 往往说的是跨进程间的分布式链路追踪(Distrubute Tracing)。
我们用 OpenTelemetry 实践一个 HTTP 通信的 Trace 例子:
这是一个本地 Localhost 的 Java 程序,我们向下游服务 192.168.0.100 发起一个 HTTP 请求。程序中使用 OpenTelemetry 的 inject 注入,通过 HTTP Headers 把 Localhost 的 Trace 传递给 192.168.0.100 的下游服务。传播前,手动还创建两个想要一块传播的 Attributes。
@GetMapping("/contextR")@ResponseBodypublic String contextR() { TextMapSetter<HttpURLConnection> setter = new TextMapSetter<HttpURLConnection>() { @Override public void set(HttpURLConnection carrier, String key, String value) { // 我们把上下文放到 HTTP 的 Header carrier.setRequestProperty(key, value); } }; Span spanCur = Span.current(); Span outGoing = tracer.spanBuilder("/resource").setSpanKind(SpanKind.CLIENT).startSpan(); try { URL url = new URL("http://192.168.0.100:8080/resource"); HttpURLConnection transportLayer = (HttpURLConnection) url.openConnection(); outGoing.setAttribute("http.method", "GET"); outGoing.setAttribute("http.url", url.toString()); // 将当前 Span 的上下文注入到这个 HTTP 请求中 OpenTelemetry.getPropagators().getTextMapPropagator().inject(Context.current(), transportLayer, setter); // Make outgoing call...运行程序,从监控平台我们看到,Trace 从本地的程序成功传递到了 192.168.0.100 。
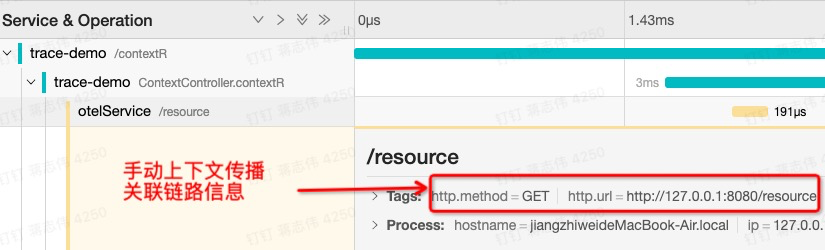
图二:跨进程传播数据
手动控制 Trace:自动构建
上面我们提到 Trace,都是链路追踪系统自动完成的。虽然这很通用,但在实际应用中,我们有些时候还想查看更多的跟踪细节和添加业务监控。链路追踪技术支持应用程序开发人员手工方式在跟踪的过程中添加额外的信息,甚至手动启动 Span,以期待监控更高级别的系统行为,或帮助调试问题。
OpenTelemetry 支持以 SDK 和 API 方式手动构建 Trace。API、SDK 都可以做一些基本 Trace 操作,可以理解 API 是 Min 实现,SDK 是 API 的超集。生产环境根据实际场景选择用哪一个。
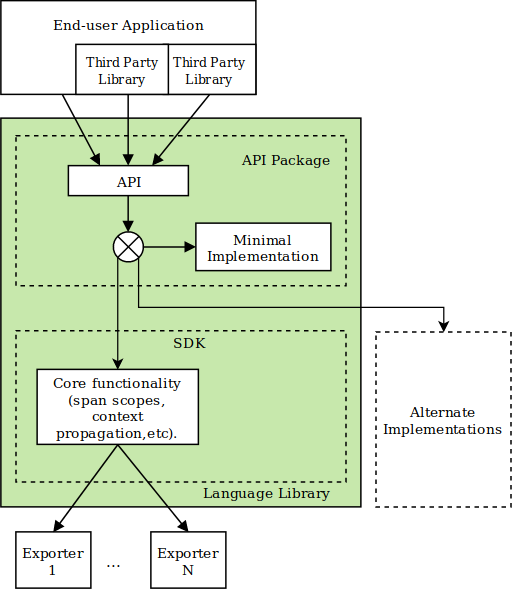
图三:手动构建 Trace 原理图
创建 Span
要创建 Span,只需指定 Span 的名称。手动创建 Span 需要显式结束操作,它的开始和结束时间由链路追踪系统自动计算。Java 代码实例:
Span Span = Tracer.SpanBuilder("手工创建 SpanOne").startSpan();try{......} finally { Span.end(); //手动创建 Span,我们需要手动结束 Span}应用程序运行时,我们可以这样获取一个 Span:
Span Span = Span.current()创建带链接 Span
一个 Span 可以连接一个或多个因果相关的其他 Span。实例中我们创建一个 Span,叫做"手工创建 SpanOne",然后分别创建了三个 Span,通过 link 把它们关联成 孩子 Span。最后又创建了一个 Span "childThree-Child",把它作为"childThree"的孩子 Span 关联:
@GetMapping("/createSpanAndLink")public String createSpanAndLink() { String SpanName = "手工创建 SpanOne"; //创建一个 Span,然后创建三个 child Span,最后关联 Span Span SpanOne = Tracer.SpanBuilder(SpanName) .startSpan(); Span childSpan = Tracer.SpanBuilder("childOne") .addLink(SpanOne.getSpanContext()).startSpan(); Span childSpan2 = Tracer.SpanBuilder("childTwo") .addLink(SpanOne.getSpanContext()).startSpan(); Span childSpan3 = Tracer.SpanBuilder("childThree") .addLink(SpanOne.getSpanContext()).startSpan(); //创建一个 Span,关联 childSpan3,作为它的 childSpan Span childSpan3Child = Tracer.SpanBuilder("childThree-Child") .addLink(childSpan3.getSpanContext()).startSpan();}我们看看运行程序后,收集的 Trace 的效果:Link 将各个 Span 连接起来
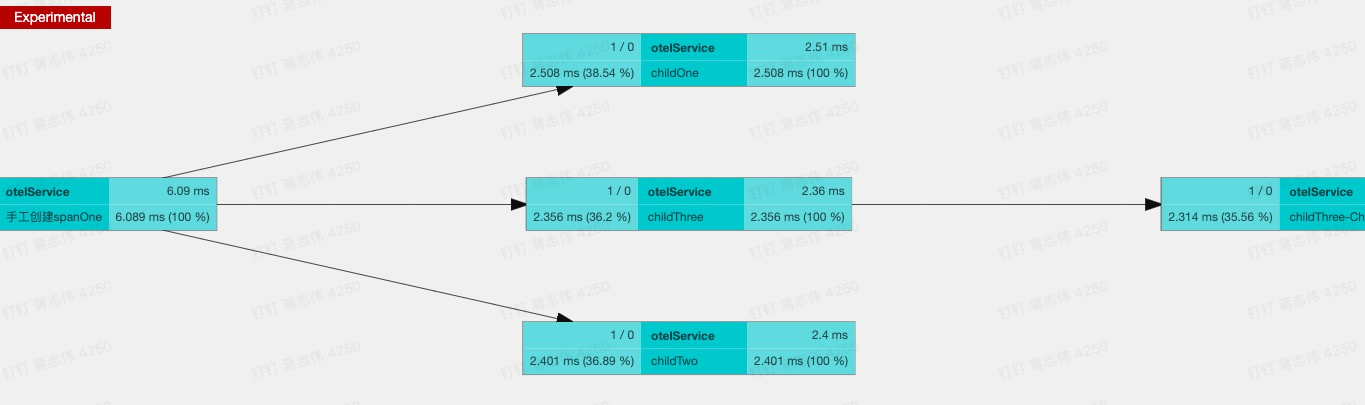
图四 链路 UI 展示 Trace 中 Span 关系
创建带事件的 SpanSpan
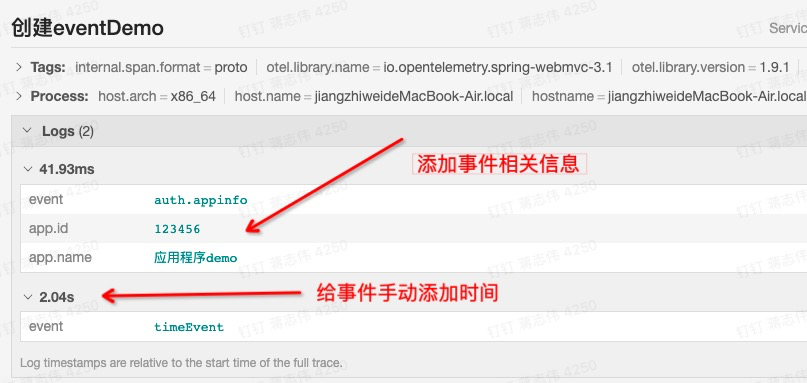
可以携带零个或多个 Span 属性的命名事件进行注释,每一个事件都是一个 key:value 键值对,并自动携带相应的时间戳。时间戳表示事件的持续时间。
@GetMapping("/event")public String event(){ Span span = Span.current(); span.updateName("创建 eventDemo"); //手动更新 Event 持续时间 span.addEvent("timeEvent",System.currentTimeMillis()+2000, TimeUnit.MILLISECONDS); //给 Event 添加相关信息 Attributes appInfo = Attributes.of(AttributeKey .stringKey("app.id"), "123456", AttributeKey.stringKey("app.name"), "应用程序 demo"); span.addEvent("auth.appinfo", appInfo); logger.info("this is a event"); }在上面程序可以看到,我们还可以给事件手动添加时间戳,这在复杂系统环境下还原真实持续事件很有意义的。看看运行程序后,追踪平台下 Span 生成的的效果:
数据如何上报
有了程序的 Trace 数据,包含 TraceId、Span、Spancontext 一系列数据。接下来需要上报到监控系统,通过视图方式展示出 Trace 整个全貌。我们习惯把 Trace 数据上报到监控过程称为数据收集(Data Collection)。看看数据收集基本原理:
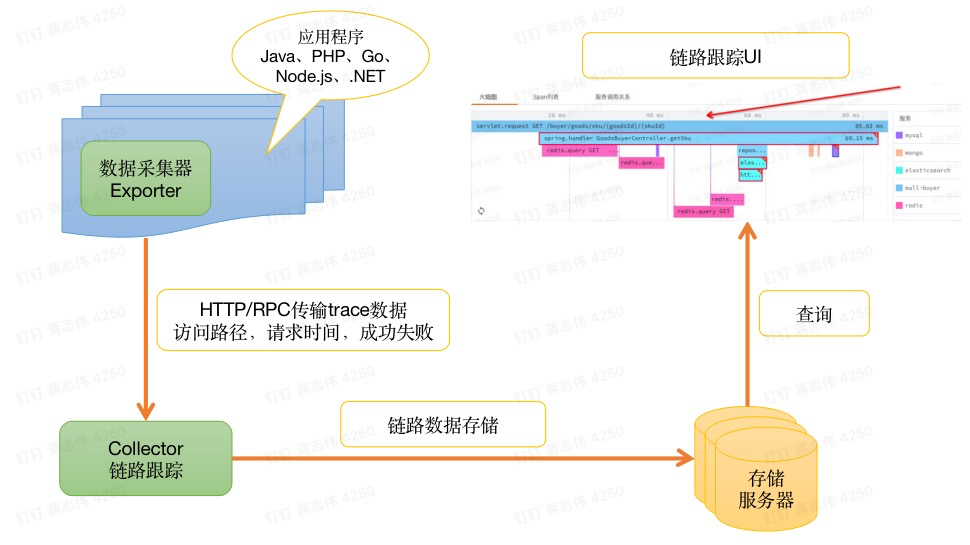
从图中,看到链路收集过程中,数据上报核心的几个组件:
Collector: 数据收集的处理器,它同时解析、加工监控数据,目的是给监控展示平台更直观的视图,便捷的查询。Exporters: 采集器,从哪个应用程序获得 Trace 数据,目前主流跟踪系统几乎可以支持任何语言平台下开发程序,并且兼容主流操作系统和容器。为了支持 Trace 标准化到这种程序,工程师可谓呕心沥血,中间过程极不容易。
Data Collection 在数据采集时候,Collector和 Exporters 有两种实现:Agent 和 Gateway。限于篇幅,我们在后面章节"解剖数据采集核心原理"详细给大家讲解。
总结
我们今天讲解了链路追踪的数据传播、数据上报的原理。通过一些实践案例,展示手动构建 Trace 的过程。我把文章中提到案例都做了线上的 Demo。如果你想动手实践内容中运行的代码,也放到了 Github 方便你进一步实践学习。
如果大家喜欢,后面的会介绍链路追踪理论发展起来应用性能监控系统 APM。
APM 为我们线上应用程序在故障定位、性能调优起到巨大作用。同时,我还会基于 APM 谈谈实际项目中,比如容器 K8s、服务网格 Istio 复杂环境下,Trace 数据采集具体实现和如何对它们做监控。
思考
一个常见的场景:用户访问一个每天上百万 UV 的电商系统,现在这个用户告诉我们下单不了,系统也没有错误提示。如果作为研发系统的工程师,你有哪些思路去排查故障呢?
如果用我们提到的链路追踪。能否知道该用户访问行为,快速定位到哪个服务出问题,或者你平时的经验,是怎样来快速解决这样类似的问题?
你可以在留言区与我交流。如果这节课对你有帮助的话,也推荐你分享给更多的同事、朋友。
作者介绍
蒋志伟,爱好技术的架构师,先后就职于阿里、Qunar、美团,前 pmcaff.com CTO,目前 OpenTelemetry 中国社区发起人,https://github.com/open-telemetry/docs-cn 核心维护者
欢迎大家关注“OpenTelemetry”公众号,这是中国区唯一官方技术公众号。




