
本文最初发表于 ZDNet,经原作者 George Anadiotis 授权,InfoQ 中文站翻译并分享。
怎样才能更好地利用人工智能的硬件,这一问题的答案可能不仅仅在于硬件,而且主要在于硬件。
假如我们要给这个问题贴上一个价格标签,它将会是数十亿美元的市场。这些都是它对不同市场的综合估价。支持这些应用的专业硬件随着人工智能应用的爆炸式增长而爆发。
对我们来说,对所谓的人工智能芯片的兴趣是来自于我们对人工智能的兴趣的一个分支,我们一直试图跟上这个领域的发展。对于 Determined AI 首席执行官兼创始人 Even Sparks 来说,这是个更深层次的问题。本文就硬件和模型在人工智能中的相互作用进行了一次访谈。
不同硬件堆栈的互操作性层
在创立 Determined AI 之前,Sparks 是加州大学伯克利分校 AmpLab的一名研究员。他致力于大规模机器学习的分布式系统,正是在这一点上,他获得了与计算机科学先驱,RISC-V 基金会现任董事会副主席[Dave Patterson](https://en.wikipedia.org/wiki/David_Patterson_(computer_scientist)和其他人合作的机会。
正如 Sparks 所说,Patterson 在早期就在鼓吹摩尔定律已死,而定制硅则是这个领域持续发展的唯一希望。Sparks 受到了影响,他和 Determined AI 所做的工作就是开发帮助数据科学家和机器学习工程师的软件。
这个软件的目的是帮助数据科学家和机器学习工程师加速工作负载和工作流,更快地构建人工智能应用。为了达到这个目的,Determined AI 提供了一个软件基础设施层,该层位于 TensorFlow 或PyTorch等框架之下,并在各种芯片和加速器之上。
处在这样的位置上,Sparks 的兴趣并不在于剖析供应商的策略,而是要站在开发和部署机器学习模型的角度考虑问题。所以,ONNX是一个天然的起点。
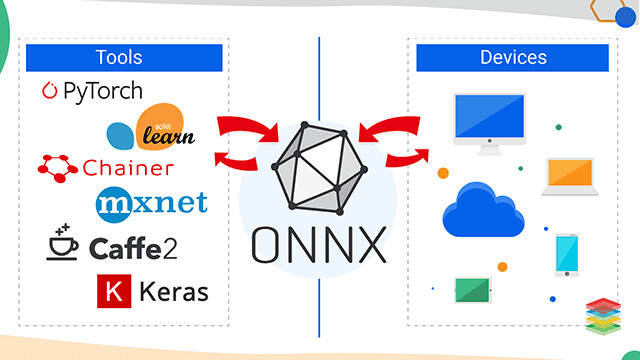
ONNX 是一个互操作性层,允许使用不同框架训练的机器学习模型能够部署到一系列人工智能芯片上。
ONNX 是一个互操作性层,允许在一系列支持 ONNX 的人工智能芯片上使用不同框架训练的机器学习模型进行部署。我们已经看到,像GreenWaves或Blaize这样的供应商已经开始支持 ONNX 了。
ONNX 最初出自 Facebook,Sparks 指出,之所以开发 ONNX,是因为 Facebook 有一套完全不同的训练和推理系统来处理机器学习应用。
Facebook 内部使用 PyTorch 进行开发,而生产环境中运行的深度学习模大多是 Caffe 支持的计算机视觉模型。Facebook 的任务是,可以使用任何语言进行研究,但生产部署必须在 Caffe 中进行。
这就需要一个中间层,用于在 PyTorch 中输出的模型架构和输入 Caffe 的模型架构之间进行转换。很快,人们就意识到,这是一个应用范围更广的好主意。事实上,它与我们以前在编程语言编译器中所看到的并没有什么不同。
ONNX 和 TVM: 解决类似问题的两种方法
这个想法是利用多种高级语言之间的中间表示,并将多种语言插入源语言和目标框架。这个主意听起来很像编译器,也是个好主意。但是,ONNX 并非人工智能芯片互操作的最终目的。
TVM是一个“新手”。TVM 最初是华盛顿大学的一个研究项目,最近它成为 Apache 的顶级开源项目,而且它在OctoML中也有商业上的努力。
TVM 的目标与 ONNX 类似:能够将深度学习模型编译成它们所谓的最小可部署模块,然后对这些模型自动地针对不同的目标硬件进行优化。
Sparks 指出,TVM 是一个相对较新的项目,但是它背后有一个相当强大的开源社区。他接着补充说,很多人希望 TVM 成为一个标准:“在 Nvidia 中没有提及的硬件供应商可能想要更开放、更容易进入市场。而且他们想找一个狭窄的接口来实现。”
在 ONNX 和 TVM 之间的精确定位上存在着细微的差别,在这方面,我们还得听听 Sparks 说的。简而言之,Sparks 说,TVM 比 ONNX 的级别要低一些,而且还存在一些与之相关的折衷方案。他认为 TVM 有可能更具通用性。
然而, Sparks 指出, ONNX 和 TVM 都处于早期阶段,它们会随着时间的推移相互学习。对 Sparks 而言,他们并非直接的竞争者,而是两种解决类似问题的方法。
人工智能的限制、成本和能源效率
但是,不管是 ONNX 还是 TVM,处理这一互操作性层,数据科学家和机器学习工程师都不应该有这样的任务。Sparks 提倡在模型开发的不同阶段分离关注点,这非常符合MLOps 的主题:
为了准备数据训练,有许多系统可以实现高性能和紧凑的数据结构,等等。它是流程的不同阶段,不同于模型训练与开发的实验工作流程。
当你在开发模型时,只要你获取的数据格式正确,你就可以对上游数据系统进行操作。同样的,只要你使用这些高级语言开发,你所使用的训练硬件,是 GPU 还是 CPU,还是外置加速器,都无关紧要。
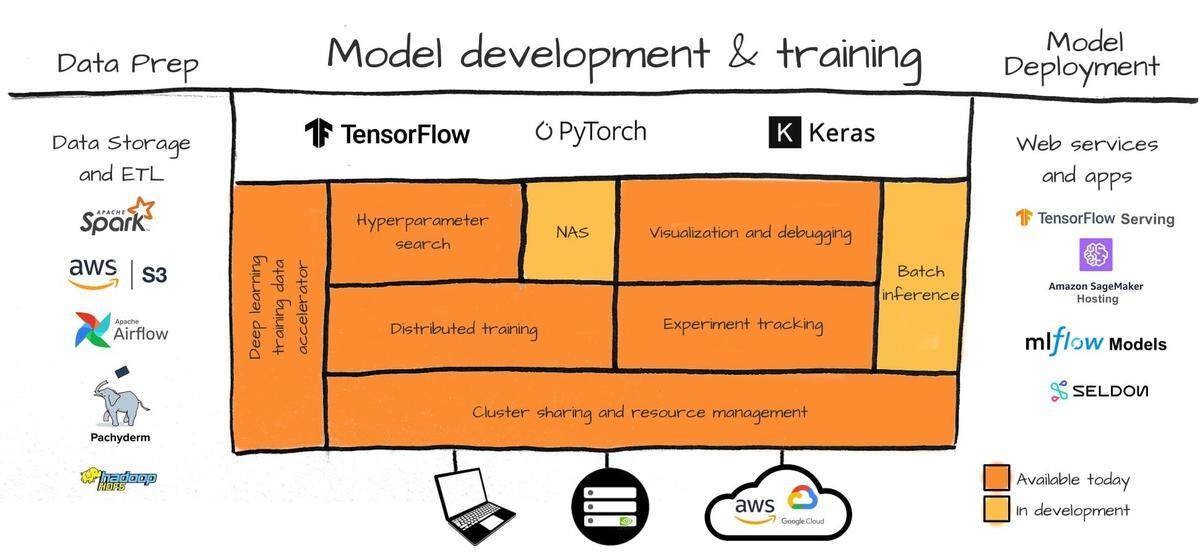
Determined AI 的堆栈旨在抽象不同的底层硬件架构
正如 Sparks 所说,关键在于硬件如何满足应用的约束。想像一家拥有传统硬件的医疗设备公司在现场。它们不会升级只是为了运行稍微精确一些的模型。
然而,问题却完全相反:如何获得能在特定硬件上运行的最精确模型。所以它们可能会从一个庞大的模型开始,使用诸如量化和蒸馏等技术来适应硬件。
这指的是部署 / 推理,但是同样的逻辑也适用于训练。包括经济成本和环境成本在内的训练人工智能模型的成本很难忽略。Sparks提到了 OpenAI 的工作,在过去的几年里,训练成本上升了 30 万倍。
不过,那是两年前的事了。正如最近来自谷歌伦理人工智能团队前联合负责人所做的工作表明,这一趋势丝毫没有放缓。使用最新的 OpenAI 语言模型 GPT3 的训练费用估计在 700 万到 1200 万美元之间。
Sparks 指出了显而易见的一点:这是一个疯狂的计算量、能量和金钱,而大多数凡人都没有这些条件。Sparks 正忙着开发工具,我们需要能够帮助计算成本并分配配额的工具。
在模型中输入知识
Determined AI 的技术提供了一种方法,可以指定预算、需要进行收敛训练的模型数量,以及探索模型的空间。在收敛之前停止训练,用户无需额外费用就可以研究模型。这是一种基于主动学习的方法,但是还有其他诸如蒸馏、微调或迁移学习的方法:
这些世界巨头,Facebook 和 Google 都在使用数十亿个参数对海量数据进行大规模训练,并在一个问题上花费数百年的 GPU 时间。那么,你不需要从头开始,而是拿来这些模型,或者用它们来形成(你要用于下游任务的嵌入)。
Sparks 提到了自然语言处理和图像识别,BERT和ResNet-50就是很好的例子。尽管如此,他还是发出了警告:这并不总是有效的。这一问题变得棘手的地方在于,当人们所训练的数据模式与现有数据完全不同时。
但是,也许还有别的办法。不管我们称它为健壮人工智能、混合人工智能、神经符号人工智能,还是其他什么名字,将知识注入到机器学习模型中是否有用?Sparks 的回答是肯定的:
“商品”用例,如自然语言处理或视觉,在这些用例中有人们一致认可的基准和标准数据集。人人都知道问题所在,图像分类,目标检测,语言翻译。但是,随着专业水平的提高,我们看到的一些最大的进步就是,你找到了一位领域专家,将他们的知识注入其中。
Sparks 以物理现象为例。比方说,你建立了一个包含 100 个参数的前馈神经网络,让它预测一个飞行物在一秒钟内的位置。如果给予足够多的例子,系统就会收敛到对所关注的函数的合理、良好的近似值,并能以较高的正确度进行预测:
但如果你将更多的物理世界知识注入到应用程序中,那么数据量就会大大减少,而且正确度也会大大提高,我们将看到一些引力常数开始出现,可能是网络特征,也可能是某些特征的组合。
神经网络非常好。他们的函数逼近能力非常强。但是如果我把这个函数的一些信息告诉计算机,希望能给大家省下几百万的计算费用,得到一个更精确的模型来显示这个世界。放弃这种想法是不负责任的。
作者介绍:
George Anadiotis,特约撰稿人。熟悉技术、数据和媒体。现为 Gigaome 分析师,为财富 500 强、初创公司和非政府组织提供咨询服务、建立和管理各种规模的项目、产品和团队。
原文链接:




