
我知道大家和我一样,都是以一种特别积极的心态沉浸在这个 DeepSeek 的学习世界中。实际上,DeepSeek 在我们春节期间送给我们的这份“大礼包”,对我个人来说,就像是一下子把我抛回到了两年前的那个夜晚——2022 年 11 月 30 号,ChatGPT 诞生的那个夜晚。那时候,我充满了兴奋,感觉到了这个世界的不同,也感受到了大家对知识的渴望。所以,我非常急迫地想和大家分享我在这段时间里的心路历程和总结,一起探索这一切。
大家有没有注意到一个重要的现象,就是在大模型时代,新的技术和创新出现的速度越来越快,而我们学习新东西的速度也在加快。为什么会这样呢?我们不妨想一想,为什么和大模型接触久了之后,我们自己变得越来越聪明了?实际上,我们有一句古话,“近朱者赤,近墨者黑”。如果我们总是和更聪明的模型在一起探讨、用更聪明的方法去学习,那么我们的认知就能不断升级,越来越快。这是我第一个想告诉大家的道理。所以,大家也可以把我看作是一个知识的“蒸馏者”,而这个“蒸馏”在今天是一个特别流行的词汇。通过我对 DeepSeek 的学习、论文的阅读和听其他老师的分享,我形成了一些自己的想法,希望在这里和大家分享。在大模型时代,我们思考得越多,得到的也就越多。
让我们一起思考几个问题。第一个问题是:为什么 DeepSeek 每一步都做对了?这也是我一直在思考的一个问题。大家也许会奇怪,为什么 DeepSeek 团队能一次次做对,仿佛他们开了天眼。其实,每一次尝试都有可能失败,尤其是在资源有限的情况下。卡片数量就那么多,要用这些资源去做方向探索。如果这个探索失败了,会怎样?你还能不能在这么短的时间里做出 V3 和 r1?DeepSeek 团队就像是特斯拉,相对于爱迪生那种“一直试下去”,用蛮力排除万难,试一万种,一万种不行再试一亿种。而特斯拉一出手就准确。为什么能做到这一点?第二个问题是:DeepSeek 给我们带来了什么?我们每个人可能并不是大模型的训练者,可能在工作中会用到大模型,也有可能并不涉及。那么,作为普通人,了解 DeepSeek 对我们到底有什么用呢?这个问题我也不好直接回答。我能说的是,我自己的一系列的思考,也许这些思考能给我们这些不是大模型训练者或者微调者带来一些启示。
另外,我还想和大家分享一个观点:AI 时代为每个人带来了新的机会。当 DeepSeek 出现时,除了 DeepSeek 团队的几百个博士外,每个人都是在同一时间开始学习这个技术。我鼓励大家多学习、多探索新事物,也许你会成为未来的专家和导师。这正是 AI 时代为我们每个人带来的新机会。今天的分享目录大致如下:
为什么要学习 DeepSeek?
DeepSeek 有哪些核心创新?
DeepSeek 为普通人(我们)带来什么?
为什么要学习 RAG?
RAG 的前沿进展
DeepSeek 为 RAG 带来了什么?
为什么要学习 DeekSeek
李继刚老师在一次分享中提出了关于人与 AI 认知的“乔哈里窗”模型,将人和 AI 的认知分为四个象限。这个模型非常有启发性,它将人脑中的“认知宇宙”与 AI 中的“认知宇宙”进行对比,指出两者逻辑可能相同也可能不同,关键在于找到连接这两个宇宙的“钥匙”。具体来说:
人知道且 AI 知道:在这个象限中,人和 AI 都对某个问题有清晰的认知,交流时无需过多提示,直接沟通即可。
人知道但 AI 不知道:此时需要通过详细的提示和框架指导 AI,这通常是大模型应用开发中开发者需要做的工作,涉及提示工程和 RAG。
AI 知道但人不知道:需要通过提问 AI 来获取知识。
人和 AI 都不知道:这种情况下需要共同探索。
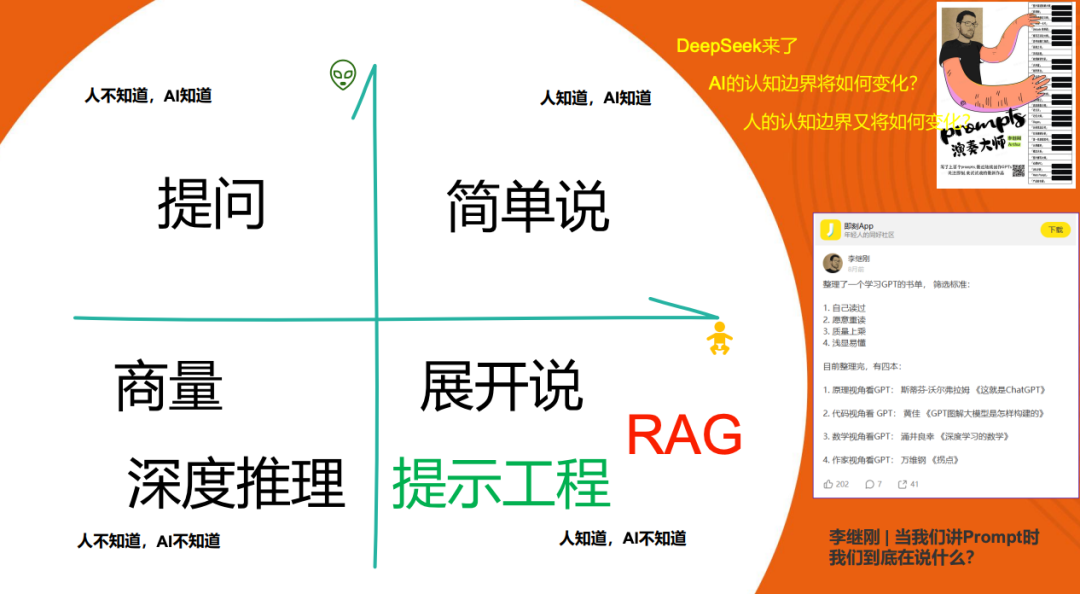
随着像 DeepSeek 和 OpenAI 的 O3 这样强大的推理模型出现,AI 的认知边界发生了变化。AI 知道的内容更多,使得与 AI 交流时,人们无需过多展开问题,交流变得更加简单。这降低了提示工程和 RAG 的门槛,是大模型发展带来的直接好处。然而,这种技术进步也引发了关于人类认知边界变化的思考。如果大模型变得越来越强大,人类的认知边界可能会有两种走向:一种是依赖 AI,导致认知范围缩小;另一种是与 AI 共同进化,使认知边界得到拓展。这种分化可能使未来只有 20% 的人选择进化,而 80% 的人可能会退化。
DeepSeek 的出现为人们提供了强大的工具。从使用者角度看,DeepSeek 的部署和调用相对简单。其开源生态使得开发者可以快速构建 RAG 框架。例如,通过工具如 Cursor,开发者可以一边编码一边调试,大大缩短了开发时间。DeepSeek 的文档也非常详尽,从 DeepSeek LLM 到 DeepSeek Math,再到 V3 R1,用户可以通过研究其开源论文来深入了解。关于 DeepSeek R1 和 V3 的区别,R1 版本通过将人类偏好融入训练过程,进化为更安全、更有效、更可靠的人工智能助手。而 V3 版本对 MoE 框架进行了创新,包含细粒度多数量的专业专家和更通用的共享专家。
DeekSeek 有哪些核心创新
DeepSeek 的核心创新可以从其研究历程和关键成果中得到清晰的体现。从 2024 年 1 月发布第一版论文开始,DeepSeek 就展现出强烈的长期主义倾向,其目标是通过持续的研究和开发逐步攻克一系列技术难题。这种长期规划和逐步推进的策略使得 DeepSeek 在短短一年内取得了显著的进展,并最终在 2025 年 1 月完成其 r1 版本,实现了最初设定的目标。DeepSeek 的创新主要体现在以下几个方面。
1. 长期主义与开源理念
DeepSeek 从一开始就强调长期主义和开源。其第一篇论文《DeepSeek LLM:通过长期主义扩展开源语言模型》明确了这一理念。与 OpenAI 的封闭开发模式不同,DeepSeek 选择开源其研究成果,让其他研究者和开发者能够直接利用其成果,避免重复劳动。这种开源策略不仅加速了技术的传播,也为 DeepSeek 赢得了广泛的社区支持和合作机会。
2. 混合专家语言模型(MoE)
DeepSeek 在 2024 年 5 月发布了基于混合专家系统(MoE)的语言模型 V2,这是其技术创新的重要一步。MoE 架构通过将多个领域专家模型组合在一起,并通过门控网络动态分配查询请求,使得模型能够更高效地处理多样化的任务。这种架构不仅提升了模型的性能,还降低了资源消耗,使得 DeepSeek 在硬件资源有限的情况下也能实现高性能表现。

3. 推理能力的强化
DeepSeek 的推理能力是其核心竞争力之一。从 2024 年 2 月开始,DeepSeek 就专注于提升模型的推理能力,尤其是通过代码和数学问题的训练。代码和数学问题的解决需要复杂的逻辑推理和逐步思考,这使得模型能够学习到更深层次的思维模式。相比之下,普通的问答任务往往缺乏推理细节。DeepSeek 通过这种方式训练模型,使其在处理复杂问题时表现出色,其 r1 版本的推理能力甚至超过了 V3 版本。
4. 高性价比的软硬件协同设计
在资源有限的情况下,DeepSeek 探索了高性价比的软硬件协同设计。这意味着 DeepSeek 不仅在算法上进行了优化,还在硬件适配和资源管理上进行了创新。这种策略使得 DeepSeek 能够在没有像 OpenAI 那样庞大硬件资源的情况下,依然能够实现高效运行和快速迭代。
5. 持续的技术演进与生态建设
从 2024 年 1 月到 2025 年 1 月,DeepSeek 通过一系列论文和版本迭代,逐步完善了其技术体系。每一步的研究成果都为后续的开发奠定了基础,最终形成了一个强大的技术生态。例如,DeepSeek Coder 在 2024 年初就已经展现出强大的代码生成能力,比其他同类工具提前了约 9 个月。这种前瞻性使得 DeepSeek 在技术竞争中占据了优势。
DeepSeek 的技术成果并非一蹴而就,而是通过持续的研究和优化逐步积累而成。其 r1 版本的推出标志着 DeepSeek 在技术上的成熟,其背后是深厚的技术积淀和长期的规划。这种长期主义和技术积累使得 DeepSeek 在 AI 领域脱颖而出,成为值得关注的研究方向。
DeepSeek 的开发始于对“规模法则”(Scaling Law)的研究。规模法则描述了模型大小、数据量和计算资源之间的关系,以及这些因素如何影响模型性能。DeepSeek 团队通过大量实验,分析了不同参数配置下的模型能力,试图回答“多大的模型能在特定数据集上达到何种性能水平”这一问题。这一研究为 DeepSeek 模型的训练提供了理论基础,并指导其在代码、数学和推理领域的优化。例如,DeepSeek 在 67B 模型大小时,性能超过了 LLAMA2 的 70B 模型,尤其是在代码和数学推理方面表现出色。
代码智能的崛起
在数据组织和训练方法方面,DeepSeek Coder 引入了创新。它采用代码仓库的层级结构来组织训练数据,帮助模型更好地理解文件之间的关联关系。这种组织方式与传统的基于简单问答对的训练方法不同,能够为模型提供更丰富的上下文信息,从而增强其推理能力。此外,DeepSeek Coder 还借鉴了 BERT 的填空式训练方法,通过在代码片段中“抠掉”部分内容,让模型预测缺失的部分,从而提升代码生成的完整性和准确性。这种方法不仅基于前人的思路,还在此基础上进行了创新。
DeepSeekMath 则专注于突破数学推理的极限,进一步强调了推理能力的重要性。它通过代码预训练来增强数学推理能力,体现了 DeepSeek 团队对推理能力的重视。这一过程是逐步推进的:从代码生成能力出发,进而增强数学推理能力,最终实现推理能力的提升。这一逻辑链条表明,代码和数学推理之间存在紧密联系,且这一方向是正确的。
DeepSeekMath 的最大贡献在于其提出的 GRPO(Generalized Reinforcement Policy Optimization)方法。GRPO 是一种强化学习方法,与 OpenAI 使用的 PPO(Proximal Policy Optimization)不同。在 GRPO 中,没有传统的“value model”,但需要一个“reward model”来为模型提供奖励信号,从而引导模型更新参数。这种方法与监督学习不同:监督学习通过标准答案直接进行反向传播更新模型参数,而强化学习则通过奖励信号引导模型在环境中获得长期回报。GRPO 的提出为模型训练提供了新的思路,尽管其细节与 PPO 有所不同,但它的核心在于通过奖励机制而非固定的“标准答案”来调整模型行为。
ChatGPT 是从 Transformer 架构逐步发展而来的,从基础模型到最终的 ChatGPT 模型之间的关键步骤如下所述。
首先,我们需要一个基于 Transformer 架构训练的基础模型。这个模型虽然功能强大,但还需要进一步优化以适应特定任务。因此,第一步是进行监督微调(Supervised Fine-Tuning,SFT)。SFT 是通过人类标注的高质量数据对基础模型进行微调,使其能够更好地理解和生成符合人类期望的文本。这是从普通模型向高级对话模型转变的第一步。
接下来,为了进一步优化模型,OpenAI 引入了奖励模型(Reward Model,RM)。RM 的作用是评估模型生成的答案质量,并为模型提供反馈。具体来说,OpenAI 利用 SFT 模型生成一系列答案,并让人类标注者对这些答案进行排序,从而训练出一个能够判断答案优劣的 RM。这个过程避免了直接生成标准答案的复杂性,而是通过相对简单的排序任务来构建 RM。
RM 在强化学习阶段至关重要,无论是 PPO 还是 GRPO,都需要一个能够打分的奖励模型来指导模型的训练。RM 不需要像基础模型那样庞大,它只需要能够判断生成内容的好坏即可。这种设计大大降低了训练成本,并提高了模型的可扩展性。
在强化学习阶段,模型通过 RM 的打分来调整自身行为,逐渐优化生成内容的质量。PPO 是一种常用的强化学习算法,它结合了 RM 和一个价值模型(Value Model)。价值模型的作用是估计在给定状态下采取某种行动的预期回报,它与 RM 一起帮助模型在强化学习环境中实现最大化回报。然而,价值模型的引入也带来了问题。它需要与基础模型类似的规模,这不仅耗费大量训练资源,还可能导致策略更新过程的不稳定,从而影响训练的稳定性。
相比之下,GRPO 放弃了价值模型,仅依赖 RM 进行打分和反馈。这种设计简化了训练过程,减少了资源消耗,并提高了训练的稳定性。GRPO 的核心在于通过 RM 的打分直接引导模型优化,而不是依赖复杂的价值模型来估计回报。
OpenAI 展示了从 SFT、到 RM、再到强化学习的三步训练过程。这一过程为构建高性能的对话模型奠定了基础。然而,GRPO 的出现进一步优化了这一过程,通过去除价值模型,GRPO 在保持高效训练的同时,避免了价值模型带来的复杂性和不稳定性。
为何是强化学习?
为什么需要强化学习来训练大模型?在实验室中,我们经常搭建基于 Transformer 架构的模型,但这些模型的能力往往非常有限,无法像人类一样进行推理和聊天。那么,从基础模型到具备高级推理能力的模型,最关键的跃迁发生在哪个环节呢?答案是强化学习。
强化学习提供了一种基于反馈驱动的方法,通过反馈让大模型能够自主地、自驱地进行目标驱动的优化。这就是为什么很多人说 r1 模型的训练过程像是“左脚踩右脚”一样不断提升的原因。强化学习的核心在于:
自我检查与改进推理质量:强化学习帮助模型更擅长自我检查,并改进推理质量。人类思维中最重要的推理过程,很大程度上是在强化学习的最后一步中诞生的。
优化长远推理过程:强化学习鼓励模型学会从长远角度优化推理过程。例如,人类在面对复杂问题时,往往需要逐步推理,而不是简单地快速回答。大模型也需要学会这种“慢思考”,通过逐步推理来提高准确性和可靠性。
思维链与推理的重要性
思维链(Chain of Thought)的论文提出了一个重要观点:大模型需要一些机制来引导其进行更全面的思考。具体来说,需要更多的 token 和更多的推理时间。例如,当我们要求模型“一步一步思考”(think step by step)时,模型的回答会变得更加准确。这是因为我们为模型提供了更多的“内存激活空间”,使其能够更深入地处理问题。
这与人类的思考方式类似。人类有两种思考系统:快思考(自动化、直觉性)和慢思考(逻辑性、分析性)。对于复杂问题,如投资、战略规划或编写代码,我们需要慢思考来深度分析和推理。大模型也类似,思考时间越长,生成的答案往往越好。
RAG 与检索质量的重要性
在 RAG(Retrieval-Augmented Generation)框架中,检索的质量决定了大模型生成内容的质量。通过 RAG,我们为大模型提供了更多的思考空间,从而提升其推理和生成能力。因此,检索过程和上下文的质量至关重要。
DeepSeek 的创新与混合专家模型(MoE)
DeepSeek 在 2024 年 2 月就意识到推理能力的重要性,并将其作为研究的核心方向。其成功的关键在于早期发现了推理的重要性,并在模型架构上进行了创新。
在 2024 年 1 月,DeepSeek 发表了一篇论文,提出了混合专家语言模型(MoE)的两个重要思想:更细粒度的专家分割和共享专家的隔离。MoE 架构的核心是将模型划分为多个“专家”,每个专家负责处理特定的任务。这种架构早在 1991 年就已提出,但在深度学习时代得到了新的发展。
DeepSeek MOE 架构的核心是将输入的 token 通过一个路由器(Router)分配给多个专家网络。这些专家网络并不是单层结构,而是由多层组成,每一层都包含多个专家。例如,早期的 Misture 模型可能每层有 7 个专家,而 DeepSeek MOE 已经扩展到每层有 200 多个专家。这种架构通过稀疏激活机制,使得每个 token 只激活一小部分专家,而不是整个网络,从而显著降低了计算负担。
DeepSeek MOE 的训练机制与 Transformer 架构类似,通过不断的训练优化,模型能够自动学习如何将不同的 token 分配给合适的专家。这种动态分配能力是通过门控网络(Gating Network)实现的,它可以根据输入 token 的特征,决定哪些专家参与计算。这种设计不仅提高了计算效率,还增强了模型对不同输入的适应性。
DeepSeek MOE 的两个关键微创新包括:
更细粒度的专家分割:通过更细致地划分专家,模型能够更精准地处理不同类型的输入。
共享专家的隔离:除了专业的专家网络外,还设置了一批共享专家,类似于医院中的全科医生,用于处理通用知识。
这种设计使得模型在处理多样化任务时更加灵活。这些创新都建立在对 Transformer 架构深刻理解的基础上。只有深刻理解了 Transformer 的基本结构,我们才能在此基础上进行优化和创新。
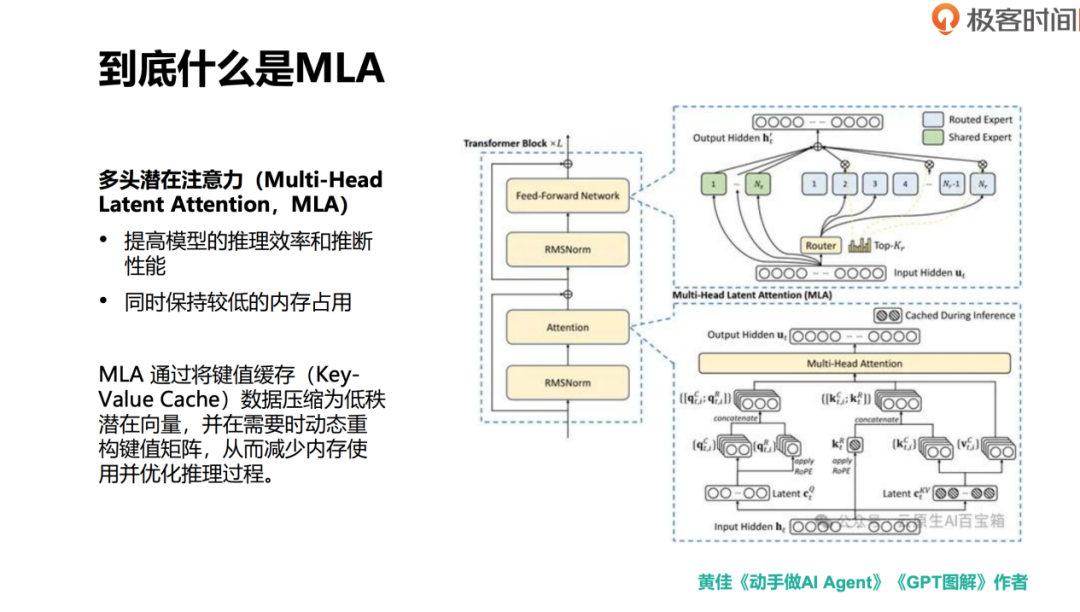
DeepSeek MOE 结合了多种优化技术,包括监督微调 SFT 和奖励模型 RM。这些技术最初由 OpenAI 提出,DeepSeek 在此基础上进行了整合和优化。例如,DeepSeek V2 在 2024 年 5 月引入了对齐优化(Alignment Optimization),进一步提升了模型的性能。此外,DeepSeek 还引入了多头潜在注意力(MLA,Multi-head Latent Attention)机制,这是一种新的优化技术,旨在优化 Transformer 模型中的多头注意力(MHA)结构,特别是在推理阶段的效率和资源消耗方面。
MLA(Multi-Head Latent Attention,多头潜在注意力)
MLA 是一种技术,旨在通过优化模型的推理效率和性能,同时保持较低的内存占用。具体来说,MLA 利用 KV Cache(键值缓存)来优化推理过程。它将 KV Cache 中的数据压缩成低维的潜在向量,这些向量占用的资源较少。在需要时,系统会动态重构键值矩阵,从而减少内存占用,优化推理过程。这种技术特别适用于资源有限的场景,例如没有大量 GPU 资源的公司或研究机构。MLA 的核心价值在于,它能够在资源受限的情况下,帮助完成与资源充足条件下相同水平的任务。相比之下,像 OpenAI 这样的公司由于拥有大量计算资源,可能不需要这种优化技术。
DeepSeek-V3 技术报告(2024 年 12 月)
DeepSeek-V3 是一个大规模语言模型,其技术报告在 2024 年 12 月发布。该模型具有以下特点和创新。
模型规模
DeepSeek-V3 的模型规模为 671 亿参数,虽然不算最大的模型,但已经相当庞大。每个 token 激活时会涉及 370 亿参数,支持如此大规模的上下文,这表明模型在处理复杂任务时具有强大的能力。
技术集成
DeepSeek-V3 集成了多种先进技术,包括:
MoE:通过多个专家网络协同工作,提高模型的多样性和效率。
MLA:通过优化 KV cache 的使用,减少内存占用,提高推理效率。
MTP(Multi-Token Prediction,多 token 预测):这是 DeepSeek-V3 提出的一个新概念。传统的 Transformer 架构通常一次生成一个 token(即 next token prediction)。然而,DeepSeek-V3 尝试一次预测多个 token,以提高推理效率。尽管业界主流尚未广泛采用这种方法,但 DeepSeek-V3 在这一方向上进行了探索,并取得了一定的成果。
高效的 FP8 训练:为了在资源有限的情况下训练大规模模型,DeepSeek-V3 采用了高效的 FP8 训练技术。传统的训练标准使用 FP32(32 位浮点数),每个参数占用 32 位。然而,FP32 的训练成本较高,尤其是在资源受限的情况下。DeepSeek-V3 通过混合精度训练框架,将部分参数压缩到 FP8(8 位浮点数),甚至更低精度的 FP16(16 位浮点数)或 int4(4 位整数)。这种技术不仅降低了训练成本,还提高了训练效率,使得在资源有限的情况下也能训练出高质量的模型。
DeepSeek-R1:通过强化学习激励大语言模型的推理能力
在 2025 年 1 月 20 日,DeepSeek 团队推出了极具影响力的 DeepSeek-R1 模型。这一版本不仅在技术上取得了显著突破,还引入了一系列新的关键词,这些关键词将在业界成为经典。其中最重要的一个概念是纯强化学习,即完全通过强化学习训练出的推理能力。
纯强化学习的重要性
在传统的模型训练流程中,通常会经历三个阶段 SFT-RM-PPO。DeepSeek-R1 的初始版本 DeepSeek-R1 Zero 采用了不同的方法。从 DeepSeek-V3 到 R1 Zero,团队放弃了 SFT 阶段,直接使用纯强化学习来训练模型。这一决策的关键在于,DeepSeek-V3 已经通过之前的训练达到了较高的水平,类似于一个“博士级”的模型。因此,团队认为可以直接在这一基础上,通过纯强化学习进一步提升模型的推理能力,而无需再进行昂贵且耗时的监督微调。
放弃 SFT 阶段带来的最大优势是成本和资源的显著降低。SFT 需要大量人工标注的数据,这不仅耗时,还需要大量的人力和计算资源。而强化学习(尤其是纯强化学习)则依赖于模型自身的探索和奖励信号,资源需求相对较小。通过这种方式,DeepSeek-R1 Zero 不仅节省了成本,还证明了在资源有限的情况下,依然可以训练出高性能的推理模型。
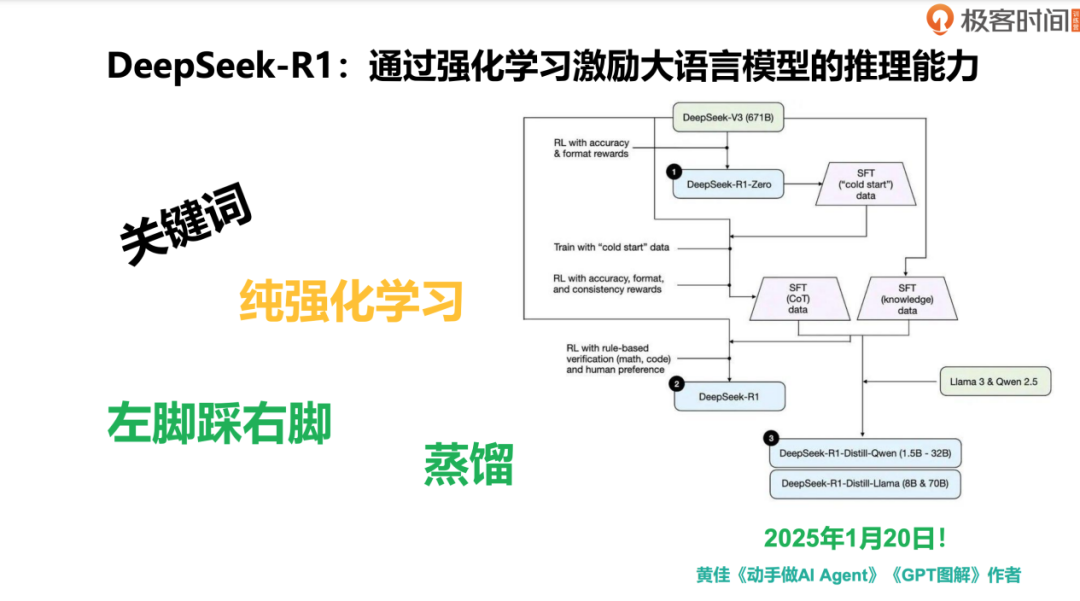
R1 的诞生过程 – 左脚踩右脚
DeepSeek R1 的开发过程中,一个关键的技术策略被称为“左脚踩右脚”,即通过 V3 和 R1 Zero 之间的相互训练和优化,逐步提升模型的性能。这一过程体现了迭代优化的思想,具体步骤如下。
1.V3 模型的起点
DeepSeek 团队从一个已经训练得非常好的基础模型 DeepSeek V3 出发。V3 模型本身已经具备了较高的性能,但由于其并非专门针对推理任务优化,因此需要进一步提升其推理能力。
2. 强化学习训练 R1 Zero
基于 V3 模型,团队尝试了一种全新的训练方式——纯强化学习,直接训练出一个推理能力更强的模型 R1 Zero。R1 Zero 的训练过程中没有使用传统的 SFT,而是完全依赖强化学习来优化模型的推理能力。这种方法的优势在于节省了大量的人力标注成本,同时能够快速提升模型的推理性能。
3. 生成推理数据
通过 R1 Zero 模型,团队生成了一系列高质量的推理数据,这些数据带有特殊的标签,用于记录模型的推理过程。这些数据不仅包含了推理的结果,还展示了模型在推理过程中的思考步骤,为后续的训练提供了宝贵的资源。
4. 反馈优化 V3 模型
利用 R1 Zero 生成的推理数据,返回来对 DeepSeek V3 进行进一步训练。这一过程使得 V3 模型能够吸收 R1 Zero 的推理能力,从而变得更强大。这种“你训我,我训你”的迭代优化方式,使得两个模型在训练过程中相互促进,逐步提升性能。
5. 解决 R1 Zero 的不足
尽管 R1 Zero 在推理能力上表现出色,但它也存在一些问题,例如中英文混杂、推理格式不完美等。为了解决这些问题,团队采用了 SFT 对齐的方式,将 R1 Zero 生成的数据与人类的语言和思维方式对齐。这一过程包括以下几个步骤:
Consistent Format and Accuracy:确保生成的数据格式一致且准确。
COT(Chain of Thought)数据:利用带有推理步骤的数据进一步优化模型。
Knowledge 数据:补充一些不需要推理的基础知识,例如简单的数学问题或常识性问题,确保模型在这些方面也能给出准确答案。
经过上述步骤,团队最终形成了 DeepSeek R1。这一版本的模型不仅具备强大的推理能力,还能生成符合人类语言习惯和思维模式的输出。通过这种“左脚踩右脚”的迭代优化方式,DeepSeek R1 在性能上超越了之前的版本,成为了一个具有里程碑意义的模型。

蒸馏
DeepSeek R1 模型的规模达到了 631 亿参数,这使得它难以在普通硬件上部署和使用。为了解决这一问题,DeepSeek 团队引入了模型蒸馏(Knowledge Distillation)技术。模型蒸馏是一种将大型复杂模型的知识迁移到小型模型中的方法,使得小型模型能够在有限的资源下表现出接近大型模型的性能。
DeepSeek 团队利用 R1 模型生成的高质量推理数据集,对其他开源模型(如 LLaMA 和千问)进行蒸馏训练。这些数据集包括:
COT(Chain of Thought)数据:记录模型推理过程的数据。
人类知识数据:包含常识和基础问题的答案。
通过这些数据,团队对较小的模型(如 32B、1.5B、8B 和 70B 的 LLaMA 和千问模型)进行训练,显著提升了它们的性能。例如,经过蒸馏训练后,千问 32B 模型的推理能力从 50% 提升到了 70% 以上,某些指标甚至达到了 83 分。这一提升证明了推理数据在模型蒸馏中的重要性。
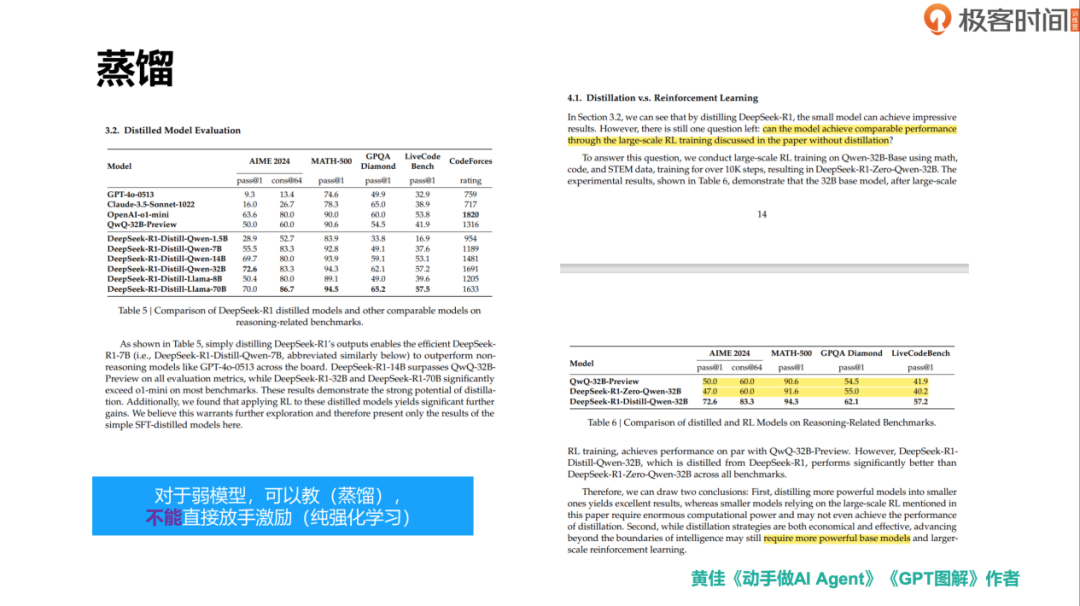
DeepSeek 团队进一步探索了纯强化学习在模型蒸馏中的应用。他们发现,对于较小的模型(如 32B 的千问),直接应用纯强化学习效果不佳。原因在于这些模型本身不具备足够的推理能力,无法通过强化学习实现自我提升。
这一过程为模型训练和优化提供了重要启示。
模型能力的门槛:纯强化学习需要模型具备一定的基础能力。对于能力较弱的模型,直接应用强化学习可能效果不佳,甚至可能导致模型性能退化。
蒸馏的有效性:高质量的推理数据对于提升模型性能至关重要。通过蒸馏,可以将大型模型的知识迁移到小型模型中,使得小型模型在资源受限的情况下也能表现出色。
模型训练的策略:对于能力较弱的模型,应先通过监督学习(如 SFT)进行基础能力的训练,然后再逐步引入强化学习进行优化。
An aha Moment:模型的“灵光一闪”
DeepSeek R1 一个引人注目的现象是 Aha Moment。这是一个在模型推理过程中出现的瞬间,模型突然“明白”了某些东西,并通过类似“Wait, wait Wait that’s an aha moment I can flag here”的语句表达出来。这种现象让人联想到人类在解题过程中,经过多次尝试后突然灵光一闪的时刻。尽管我们无法确定模型是否真的经历了类似人类的“意识觉醒”,但这种现象无疑是推理能力的体现,也是大模型在复杂任务中表现出色的一个标志。

DeepSeek R1 的技术成就
DeepSeek R1 的开发是中国 AI 领域的一个重要里程碑。它由 100 多个博士组成的团队合作完成,这些研究人员在资源有限的情况下,通过一系列创新方法,开发出了与 OpenAI 的 O1 模型相媲美的推理能力。DeepSeek R1 不仅达到了与 O1 相近的性能,还在某些方面超越了它。这一成就展示了中国在 AI 领域的强大实力,也证明了即使在资源有限的情况下,通过正确的技术路径和创新方法,也能取得突破性进展。
技术路径与关键词
DeepSeek R1 的开发过程可以总结为以下三个关键点。
纯强化学习
DeepSeek R1 从 V3 模型出发,通过纯强化学习训练出 R1 Zero,这一过程中没有使用传统的监督微调(SFT)。这种方法不仅节省了大量的人力标注成本,还显著提升了模型的推理能力。
左脚踩右脚
DeepSeek 团队通过 V3 和 R1 Zero 之间的相互训练和优化,逐步提升模型性能。具体来说,R1 Zero 生成的高质量推理数据被用来进一步训练 V3 模型,使其变得更强大。这种迭代优化的方式使得模型在推理能力上不断提升。
模型蒸馏
DeepSeek R1 不仅自身强大,还通过蒸馏技术将知识迁移到其他开源模型(如 LLaMA 和千问)中。通过高质量的推理数据和 COT 数据,这些小型模型的性能得到了显著提升。
DeepSeek R1 的成功离不开 OpenAI 等先驱团队的思想启发。尽管 OpenAI 没有开源其成果,但他们的技术理念:“不要教,而是激励”(Don’t teach, incentivize)为 DeepSeek 团队提供了重要的指导。这一理念的核心在于,当模型达到一定水平后,不应再通过大量的标注数据和监督学习去“教”模型如何思考,而是通过强化学习去“激励”模型自主探索和发现解决问题的方法。
OpenAI 的研究员指出,AI 研究者的工作是教机器如何思考,但一种不幸且常见的方法是,我们在用自己认为的思考方式去教机器,而忽略了机器在底层架构(如 Transformer)中的真实思考方式。实际上,我们用有限的数学语言去教授那些我们自己都不完全理解的内容。这种思考方式不仅限制了模型的潜力,也忽略了模型自主学习的能力。
DeepSeek R1 的开发过程中,团队深受 OpenAI 这一理念的影响。在论文中,DeepSeek 团队明确提到了“激励推理能力”(Incentivizing Reasoning Capability in LLMs),并采用了强化学习的方法来提升模型的推理能力。这种方法不仅节省了大量的人力标注成本,还显著提升了模型的性能。
尽管 OpenAI 的理念为模型训练提供了重要的指导,但 DeepSeek 团队也意识到,并非所有模型都适合直接应用强化学习。对于能力较弱的模型,仍然需要通过监督学习进行基础能力的训练。只有当模型达到一定强度后,才能通过强化学习进一步提升其性能。
DeepSeek 给我们带来了哪些机遇
DeepSeek 的出现为我们带来了诸多机遇和启示,这些不仅局限于技术层面,更触及到我们每个人的生活和学习。尽管我们可能并非 DeepSeek 的研究人员、人工智能博士或顶尖专家,但作为普通人,我们依然能从 DeepSeek 的发展中获益良多。
首先,DeepSeek 为我们带来了一场知识的盛宴。它激发了公众对人工智能的兴趣和讨论,使得从大爷大妈到专业人士都在探讨这一领域。它让我们意识到,AI 时代的学习至关重要。只有不断学习新知识,我们才能紧跟时代的步伐,不被落下。因为在这个快速发展的时代,每年都有新的技术涌现,只有持续学习,我们才能有机会站在行业的前沿。
DeepSeek 还带来了一系列关键技术的突破和创新,如纯强化学习、混合专家模型(MOE)、多头潜在注意力(MLA)、多 token 预测(MTP)等。这些技术不仅推动了人工智能领域的发展,也为其他行业带来了新的思路和方法。
对于 AI 系统应用人员来说,DeepSeek 提供了一个强大的工具,可以帮助他们进行更精细的系统设计。对于研究者而言,DeepSeek 的开源性和详细的训练过程为他们提供了复现和进一步研究的基础。他们可以尝试自己训练类似模型,探索新的技术和方法。对于企业来说,DeepSeek 的出现意味着他们可以将这一先进的技术集成到自己的产品和服务中,提升产品的竞争力。例如,微信小程序等应用已经开始接入 DeepSeek,为企业带来了新的发展机遇。同时,DeepSeek 的轻量级部署和算力成本优化,使得企业能够以更低的成本使用这一技术,从而降低了开发和运营成本。
对于开发者而言,DeepSeek 的出现为他们提供了新的学习和创新方向。他们可以通过学习和应用 DeepSeek 的技术,提升自己的技能水平,探索新的应用场景。此外,DeepSeek 的学习成本相对较低,使得更多的人能够参与到这一领域的发展中来。
DeepSeek 不仅对专业人士和企业有重要意义,它也与我们每个人的生活息息相关。它的出现甚至影响了股市的估值,提升了中国科技公司的国际形象。这让我们看到了中国在人工智能领域的强大实力和潜力。DeepSeek 的成功也激励了我们,让我们对自己的能力充满信心。它告诉我们,只要我们有正确的方向、坚持和勇气,就能够在这个领域取得成功。
DeepSeek 的出现也让我们意识到,AI 的发展是一个不断探索和创新的过程。虽然 r1 等模型已经取得了显著的成果,但它们并非 AI 的终点。未来,我们还有更多的工作要做,更多的未知领域等待我们去探索。在我们最新的论文中,两位杰出的创始人杨植麟和梁文锋参与了研究工作,这些研究主要集中在注意力机制的探索上,目标是开发出更节省资源的注意力机制。

为什么要学习 RAG
随着大语言模型的迅速发展,RAG 成为了这一领域的自然产物。大语言模型的强大能力引发了我们对其应用场景的思考,而 RAG 正是基于这种思考的产物。RAG 的核心价值在于,它能够使大语言模型的应用更加精准、更加贴近实际需求。在当今的工作环境中,RAG 的应用几乎无处不在,无论是企业内部知识库、学术研究、法律领域、客户支持,还是零售和电商政策等,RAG 都能发挥重要作用,提高工作效率。
目前,大语言模型的应用开发主要分为两个范式:RAG 和 Agent。对于开发者来说,学习大语言模型的应用开发,要么专注于 Agent,要么专注于 RAG,或者两者都学。这两个范式代表了大语言模型应用开发的两个主要方向。
Agent 范式侧重于利用大语言模型的逻辑推理能力,让模型去思考、判断,并优化工作流程。Agent 的想象空间很大,但落地实现相对较为抽象,需要开发者发挥创造力来实现。RAG 范式则侧重于通过检索增强的方式,弥补大语言模型在知识检索和生成方面的短板,使其能够回答原本不知道的问题。RAG 从提示工程出发,逐渐发展出标准 RAG、高级 RAG 和模块化 RAG,甚至可以进行协作式微调,以增强大语言模型的知识内化能力。
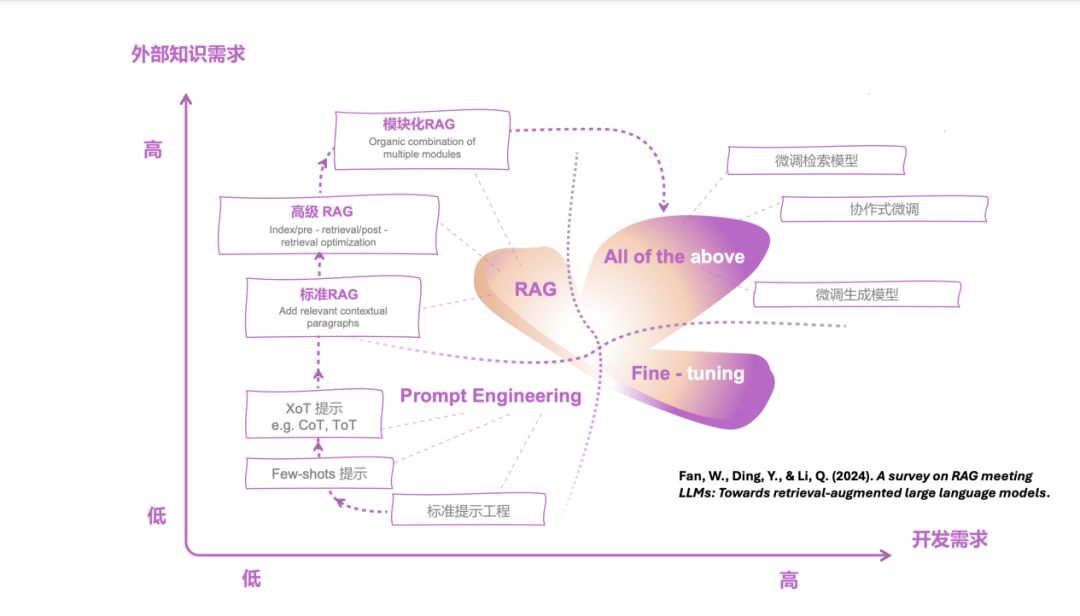
RAG 技术框架本身并不复杂,但流程其实相对直观。简单来说,RAG 的流程从文档导入开始,经过嵌入(embedding)和检索(retrieval)两个关键步骤,最终完成生成任务。然而,尽管流程本身并不复杂,但在实际操作中,RAG 涉及的细节和技术内核却相当丰富,这也是为什么 RAG 上手容易,但优化却很难。
RAG 的核心在于向量相似性,即通过将文本转换为向量形式,利用向量之间的相似性来进行检索。这一过程看似简单,但其中包含了诸多技术细节。例如,如何实现混合检索,即将传统的 BM25 算法与向量检索相结合;如何将图数据库嵌入到检索流程中;以及如何对检索结果进行预处理和后处理等。这些细节不仅影响检索的效率,还决定了生成内容的质量。
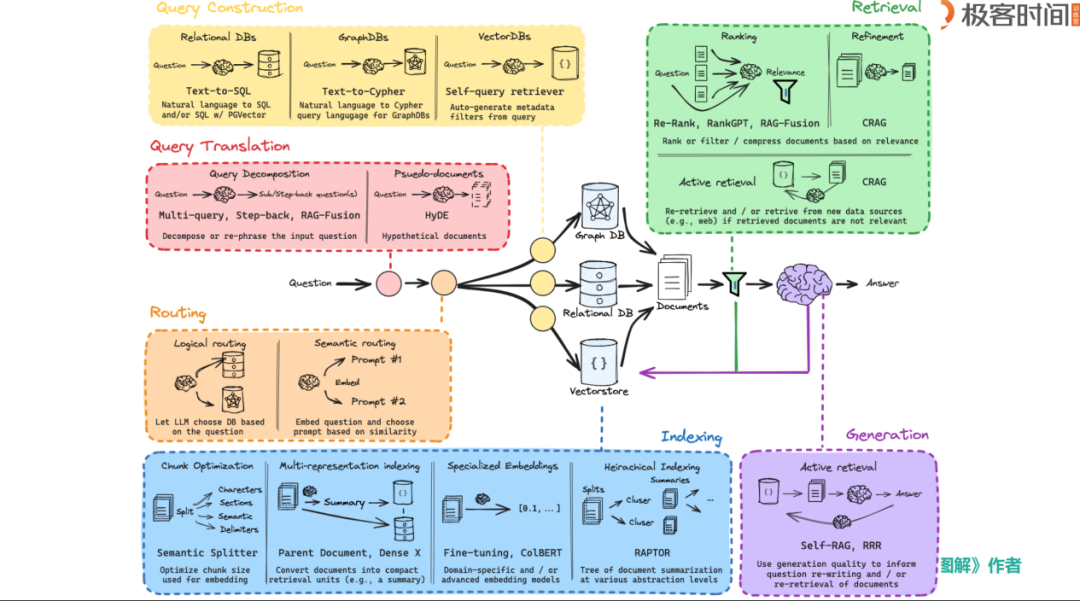
为了更好地理解和应用 RAG,我们的课程可以将其流程拆解为几个关键环节:
数据导入与文本分块(Chunking):将原始文档分割成适合处理的小块。
嵌入(Embedding):将文本块转换为向量形式,以便进行相似性检索。
检索(Retrieval):通过向量相似性检索相关文本块。
预处理(Pre-retrieval)与后处理(Post-retrieval):对检索结果进行优化,以提高生成内容的相关性和准确性。
生成(Generation):基于检索到的信息生成最终的输出。
评估(Evaluation):对生成结果进行评估,以确保其质量和相关性。
每个环节都有其独特的技术和技巧。例如,在嵌入环节,选择合适的嵌入方法和模型至关重要;在检索环节,优化检索算法和参数可以显著提高效率;而在生成环节,如何利用检索到的信息生成连贯、准确的内容则需要精心设计。
RAG 的前沿进展
RAG 的前沿进展体现在多个方面。首先,Graph RAG 的出现为 RAG 带来了新的思路。通过结合知识图谱,Graph RAG 能够更有效地进行 embedding 和社区构建。在这个框架中,节点通过知识图谱被聚类成不同的簇,例如蓝色、绿色和黄色的簇,这些簇代表了相关的知识。通过这种方式,Graph RAG 能够更精准地识别和整合相关资料,提升检索和生成的效果。
此外,RAG 还在不断拓展其功能模块,包括 Agenda RAG、Adaptive RAG 和 Corrective RAG。这些模块旨在让 RAG 系统具备自我修正和自我优化的能力,从而实现更高效的检索和更准确的生成。同时,Modular RAG 的出现使得多模态 RAG 成为可能,进一步拓展了 RAG 的应用范围和灵活性。
DeepSeek 为 RAG 带来了什么?
DeepSeek 对 RAG 的贡献是多方面的。首先,DeepSeek 显著降低了 RAG 的开发门槛,使得 RAG 流程中的每一个子任务都能更精细地执行。例如,在处理 PDF 文件时,DeepSeek 优化了布局分析、文本分块(chunking)和表格解析等环节,提升了 RAG 在处理复杂文档时的效率和准确性。
DeepSeek 还通过提供一系列蒸馏模型,进一步简化了 RAG 的本地开发和部署过程。这些蒸馏模型不仅降低了资源需求,还提升了模型的推理能力,使得 RAG 的应用更加广泛和高效。此外,DeepSeek 在模型优化方面的进展也为 RAG 带来了更好的上下文理解和推理能力,进一步提升了生成内容的质量。
未来展望
随着技术的不断进步,RAG 和 DeepSeek 的未来充满无限可能。从感知智能到认知智能,从语言智能到具身智能,AI 的发展正在不断拓展其应用边界。未来,我们可能会看到更多机器人和智能系统的出现,这些系统将具备更强的自主学习和决策能力。
DeepSeek 在资源有限的情况下,通过非凡的创造力和准确的判断力,创造了令人瞩目的成就。这不仅展示了中国在 AI 领域的强大实力,也为全球 AI 的发展提供了宝贵的经验和启示。未来,我们有理由相信,DeepSeek 和 RAG 将继续引领 AI 技术的发展,为人类带来更多的可能性。




