
亚马逊云科技推进云原生数据战略全面服务化,开启数据与云的技术发展新篇章。
re:Invent 是亚马逊云科技年度最大的活动,也是云计算技术领域的风向标。每一年,re: Invent 都给全世界云用户带来超过上百种新的服务和功能。随着数据的持续增长、开源成果的不断进步和芯片 / 计算实例技术的升级,云计算的变化速度也超越了以往任何历史时期。更多的数据、更复杂的代码和更强的算力,帮助亚马逊在云计算新时代成为主导全球经济的力量。
亚马逊云科技于 2006 年率先进入云计算领域,重塑了 IT,那么在 16 年后的今天,亚马逊云科技酝酿了怎样的大新闻?在今年的 re: Invent 大会上,我们提取并分析了亚马逊云科技掌门人 Adam Selipsky、数据分析和机器学习副总裁 Swami Sivasubramanian 在 re: Invent 大会上发布的要点,从端到端的数据战略角度窥视云技术和数据服务的演进方向。
数字化转型中的企业需要什么?
今年的活动也正值全球经济阵痛之际,受到通货膨胀、供应链中断、芯片短缺等一系列挑战,一些企业也开始削减开支。但 Adam Selipsky 表示,正是因为如此企业才需要考虑利用云计算实现 IT 现代化改造,最糟糕的时期往往是业务上云最好的时期。这几年,上云潮保持上涨趋势,亚马逊云科技在 2020 年的总销售额为 453 亿美元,而 2021 年,亚马逊云科技的业务年收入高达 620 亿美元,比 2020 年增长 37%。
“我们看到很多客户在不确定的时期实际上倾向于他们的云之旅,很多企业因此节省了 30% 甚至更多”,Adam Selipsky 还举例说,一家财富 500 强农业制造商,通过在云上运行服务,将成本降低了 78%。而在 2019 年,Airbnb 已经是一个重要的云用户;2021 年,酒店业跌至谷底,Airbnb 迅速将云支出降低 27%。“也就是说,云自动伸缩特性所带来的好处在不确定时期放大,还能让企业随时准备在业务条件变好时加快发展速度。”“如果你要寻求成本优化,云计算就是最好的选择。”
这几年,不少企业希望借助上云或立足云端推动数字化转型,亚马逊在帮助他们进行业务转型的过程中,发现越来越多的组织将数据置于决策的最核心位置。
比如一家在线商店,想要提供激励来提高客户保留率,那么就需要去理解消费数据,获取业务洞察力。这需要将数据、数据分析、数据库、机器学习结合起来,从端到端的视角去认识数据,构建企业自身的数据战略。换句话说,企业需要考虑如何对数据从摄取到存储、数据融合、数据查询、基于 BI(商业智能)和 AI(人工智能)分析,这样才能真正实现数据的协同与共享。
亚马逊云科技通过与积累的 150 万客户交流,了解他们的诉求,总结了端到端的数据战略中最重要的三点:
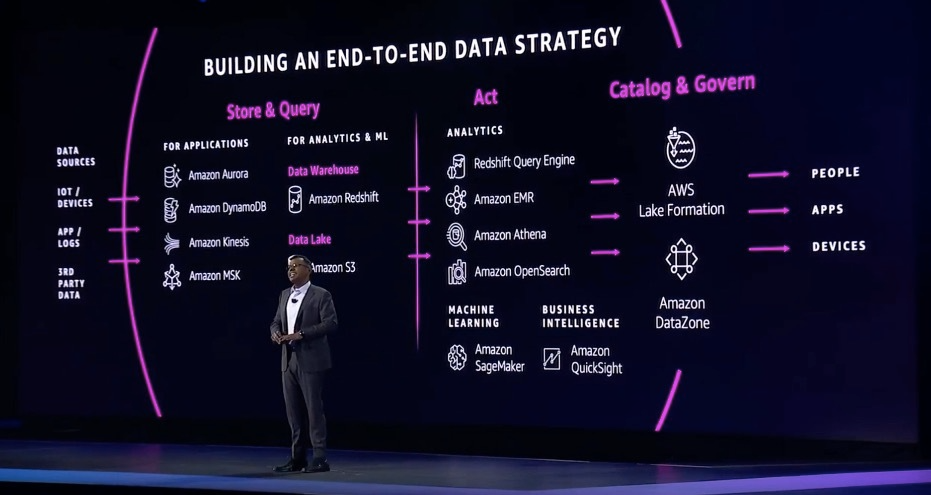
首先是需要有一套能够支撑未来的数据基础设施:需要有恰当的数据工具来应对不同类型的数据工作负载,同时,这些数据服务在大规模访问的时候也能保持高性能运行,并且不需要我们做太多的冗余的运维工作,且可以保持高可靠性和安全;其次企业需要有能力实现安全高效的跨组织数据融合,打破数据的孤岛;再次是需要有易用的工具和员工赋能、教育来实现数据普惠化。
端到端数据战略与云原生基础基础设施
这 16 年来,亚马逊一直致力于实现和整合云上从数据存储、到数据分析再到机器学习各个方面的云原生数据工具。15 年前,亚马逊云科技实现了最早的对象存储 S3;10 年前,实现了全球第一个云原生数据库 Amazon DynamoDB, 第一个云原生数据仓库 Amazon Redshift,而随后出现了第一个云原生流式数据处理工具 Amazon Kinesis、第一个云原生机器学习 IDE 工具 Amazon SageMaker。
在服务 150 万客户的过程中,亚马逊锤炼出了一套能满足极致性能的经典云原生数据库产品:Amazon Aurora 支持 128TB 的规模,其成本是其他传统企业数据库的 1/10。AmazonDynamoDB 在今年的 AmazonPrimeDay 上处理了每秒超过 1 亿个请求,涉及数万亿次 API 调用。Amazon Redshift 每天处理超过 EB 级别的数据,性价比比其他云数据库高出 5 倍。
通过 Amazon Glue 等数据集成工具,开发者可以将所有这些数据,流转到数据分析服务中,再借助亚马逊云科技构建的云原生数据分析工具,如 Amazon EMR、Amazon Redshift、Amazon OpenSearch 等,搭建适合自己的数据分析场景。
亚马逊云科技集合了这些最完整全链路云原生数据服务,形成了端到端的数据战略。
作为端到端的数据战略基础设施的补充,在 12 月 1 日 re: Invent 大会的主题演讲中,Swami 宣布推出了新品 Amazon DocumentDB Elastic Clusters,专为处理文档类型工作负载打造的全托管弹性集群。
Amazon DocumentDB 是一款兼容 MongoDB 的文档数据库,它可以自动向上拓展到每个数据集群达到 64 TB,已拥有数十万用户。而 Amazon DocumentDB Elastic Clusters,可以自动上行拓展存储,几分钟即可完成,用户不需要去担心运维或者迁移的复杂度。它的弹性数据集群可以灵活满足用户的数据管理的需求,并减少相关的维护成本。

运行 Apache Spark 的最优平台
数据是应用程序、流程和业务决策的核心,是每个组织数字化转型的基石,但分析和处理数据却很棘手。现在,由于数据和机器学习分而治之,如果要用现在流行的大数据框架 Spark 对云数据库中的数据进行分析,就需要先将数据提取到 S3,或为数据库引入一个第三方连接器,再使用 Spark 查询分析。为此,亚马逊云科技为 Apache Spark 添加了 Redshift 集成,无需移动数据即可运行查询,也不再需要构建或管理任何连接器,从存储数据的地方就能完成分析工作。
Adam Selipsky 表示,针对 Apache Spark 的 Amazon Redshift 集成最大限度地减少了设置开源连接器的繁琐且通常是手动的过程,同时保持高水平的性能,使开发者能够将应用程序性能提高 10 倍,超过使用现有的连接器。

而在第三天的主题演讲中,Swami 也宣布了 Amazon Athena for Spark。添加 Apache Spark 可以帮助开发人员使用自己喜欢的语言编写应用程序,例如 Java、Scala、Python 和 R,而无需在每次运行查询时设置、管理和扩展 Apache Spark 实例。
“有了这些新功能,亚马逊云科技就是运行 Apache Spark 的最佳场所”,Swami 表示,而且亚马逊将 Apache Spark 进行了优化,在亚马逊云上的 Spark 比开源版本速度快 3 倍。
减少重复劳动,Zero ETL 直击开发人员的痛点
数据流通才有价值,不能移动和共享的数据只能成为数据沼泽,而移动数据势必需要各种 ETL 操作。但重复无聊的 ETL 劳动可能已经成了大家心中的梦魇。就像 Adam Selipsky 解释的那样,企业可能在许多不同的地方拥有数据,如果要连接各种数据库、数据湖进行数据分析,这对很多企业来说是一项重大挑战。
“这几年,我们已经为此做了很多工作,希望能够在服务之间构建集成,以便更轻松地进行数据分析和机器学习,而无需处理 ETL,”Selipsky 告诉 re:Invent 观众。
“但如果我们能做得更多呢?如果我们可以完全消除 ETL 呢?数据集成就不再是一项手动工作,那肯定是大家所期待的,所以,我们的愿景是构建一个 Zero ETL 的未来。”他说。“因此今天我很高兴地宣布 Amazon Aurora 与 Amazon Redshift 实现 Zero ETL 集成。”这意味着亚马逊打通了 Aurora 数据库和 Redshift 数据仓库,让用户不用执行 ETL 就能进行同步,且不会相互影响各自的正常运行。

过去,大家需要跑一个 ETL 将数据库里的数据导到数据仓库里,在晚上进行每天的汇总分析。有了这个集成功能后,就不再需要 ETL 操作了,直接在数据仓库里分析就行,而且也不用在中间去构建很多复杂的基础设施,它就自动保证任务成功了。
另外,亚马逊云科技还新发布一个特性更新 Amazon Redshift auto-copy from S3,利用它可以将 S3 里的数据给拷贝上来,然后自动同步到数据仓库里去。
Zero ETL 还需要可以无缝链接所有数据源,不管在亚马逊云科技还是在第三方的任何应用上面。在一些场景下,我们也需要从很多地方 import 数据,接入不同类型的 SaaS 服务或者第三方数据源,这种情况下新发布的 Amazon AppFlow 支持 50 多种不同的 connectors,无需编写代码即可在数分钟内轻松设置数据流。我们可以看到亚马逊云科技所有的数据服务,可以将上百个数据源都连接联系在一起。

将数据库、数据服务底层打通,把各种各样的数据都连接到执行分析所需要的地方去,实现数据平滑“无感”的流动,这也是 Zero ETL 的未来。
亚马逊认为,Zero ETL 不是一个服务,而是一个由多个服务组成的解决方案集合,其中涉及到了 Amazon Glue、Amazon Redshift、Amazon MSK、Amazon Appflow、Amazon Athena、Amazon DataExchange。客户可以基于自身需求选取合适的 Zero ETL 服务进行自己的端到端数据之旅,实现近乎 0 投入的数据一体化融合。
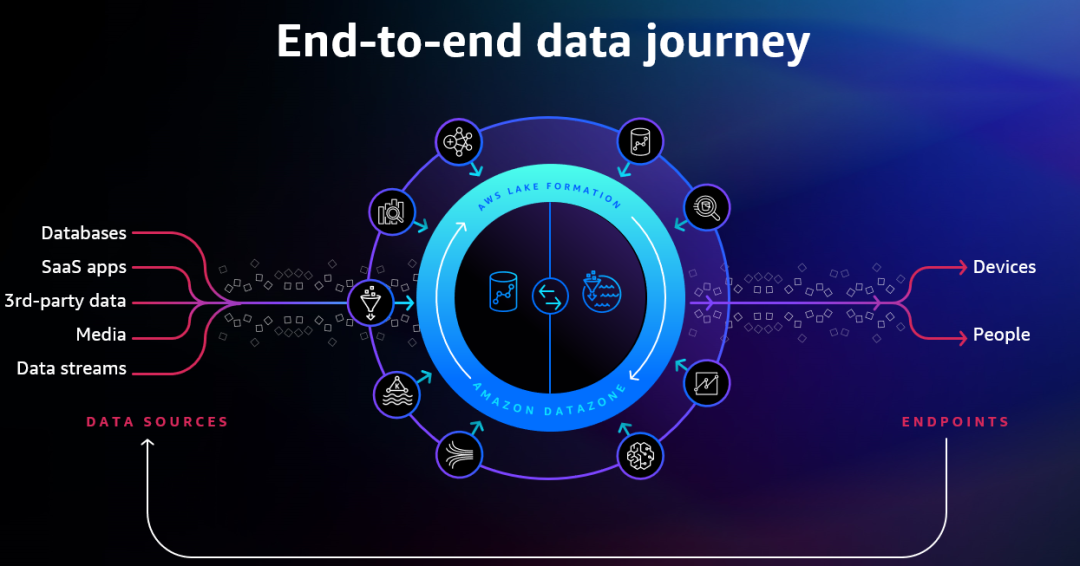
数据治理是个非常重要的命题
数据加速仍在继续,世界上新数据的涌现速度从未像现在这样快。每年我们都会听到关于数据爆炸式增长的消息,而且毫无止歇的迹象。我们希望把企业中所有的这些数据融合一起,以了解它们的内涵并获取价值。但要让数据产生价值,我们必须基于高质量的数据,并以一种一体化的方式实现数据的共享与安全访问,以解锁不同企业用户和不同目的的数据价值。
然而这同样也存在一大挑战:客户真正需要的是在数据访问和控制之间,为组织找到最合适的平衡点。如果提供的访问权限过多,就会担心自己的数据暴露在不该暴露的位置、被不该看到的人们看到。这意味着数据的安全性得不到保障。但如果反应过度、保护失当,就相当于把数据锁定了起来,形成数据孤岛,导致没有合适的人能看到数据内容。
Adam Selipsky 表示,亚马逊云科技正在努力研究端到端的数据之旅,并在数据之旅的每一站都建立强大的功能和服务,然后将这些功能和服务利用数据治理这样强大的概念结合在一起。明确谁有权访问哪些数据,哪些数据需要设置保护。通过良好的数据治理,人们就可以自由发挥创造力,探索可用的所有数据。

在 re: Invent 大会上,Adam Selipsky 宣布推出 Amazon DataZone,一项全新的数据治理服务。使用 Amazon DataZone 跨组织边界大规模共享、搜索和发现数据。通过统一的数据分析门户协作处理数据项目,该门户为大家提供所有数据的个性化视图,同时执行治理和合规性策略。Amazon DataZone 使组织中的每个人都可以访问数据。
“为了释放数据的全部力量和全部价值,我们需要让合适的人和应用程序在需要时轻松查找、访问和共享正确的数据——并确保数据安全可靠,”Adam Selipsky 在主题演讲中说道。
它的典型使用场景包括:
在业务数据目录中查找数据。使用业务术语搜索、共享和访问存储在云上、本地或与第三方提供商一起存储的数据目录。
简化工作流程。通过跨团队无缝协作并以自助服务方式访问数据和分析工具来提高效率。
简化分析访问。使用基于 Web 的应用程序获取个性化视图以发现、准备、转换、分析和可视化数据。
一站式管理数据访问。根据组织的安全法规,一站式管理和管理数据访问。
除此之外,Swami 还宣布推出了 Amazon Glue Data Quality (Preview) ,可以进一步提升数据质量,萃取数据价值,保证数据治理。数据治理需要有非常高的数据质量规范,然而越高的规范代表了越高的管理成本,非常费时费力,有时要花几天,甚至几周的时间。Amazon Glue Data Quality 能识别丢失、陈旧或不良数据,将这些手动的数据质量工作从几天缩短到几小时。
写在最后:一种影响深远的变革
今年,re: Invent 大会的一大主题就是保持经典亚马逊云计划的发展势头:更快、性能更高的基础设施,以及强大的合作伙伴生态系统。亚马逊云科技的服务,其核心就是为企业客户、软件即服务解决方案市场乃至合作伙伴生态系统提供运行良好的基础设施构建块,用以支持各类工作负载。
而在构建块之上,亚马逊云科技也开始了更高级的开发与探索。在这次发布会上,Adam Selipsky 宣布了亚马逊自己行业云解决方案:Amazon Supply Chain(预览版)和 Amazon Omics。Amazon Supply Chain 针对供应链行业,“帮助供应链领导者降低风险和降低成本,以提高供应链弹性。”这可以让缺乏工程人才或技能的组织,也能利用亚马逊云科技高级解决方案来快速部署现代 SaaS 应用程序,全面了解其供应链运营情况。Amazon Omics 针对生命科学和医疗行业,存储、查询和分析基因数据,生成有助于改善健康和推进科学发现的见解。这种新的解决方案代表一种前所未有的体验——与云服务更加深入集成、进一步提升软件与应用的开发敏捷性,最终让数据发挥出更大的作用。
由此,我们可以总结出几个趋势:
数据的扩张速度进一步提升,远超以往的现实乃至想象;
更强调基于数据治理、数据安全、数据质量的一体化融合;
更强调数据服务的端到端集成,充分利用云原生数据服务的优势,简化和加速客户的云应用;
作为组织运营的基础元素,云和数据分析深入渗透至业务的各个层面。
亚马逊云科技的最大优势,其实来自 150 万个客户——以及他们处理数据的需求,共同构成了亚马逊云科技生态系统。这样的生态系统再结合前文中我们提到的各项功能,足以让现在的数据共享和综合治理快速找到发展方向,立足庞大的生态规模实现成功。
这背后代表着一种影响深远的变革。因为几十年来,行业一直在努力解决数据应用程序的开发复杂度和成本难题。与数据规模相关的复杂性问题始终存在,开发数据驱动型应用时的直接数据查询和数据移动需求也亟待解决。如果亚马逊云科技能够找到合理的答案,那么新的纪元就由此开启:一套云原生全数据堆栈,能够切实降低大规模数据管理中的复杂性。
在亚马逊云科技开发者社区官网,我们发布了关于本次 re:Invent 更全面的信息资讯。




