本文要点
- 由于对象 - 关系阻抗失配,传统的 N 层设计会引发问题;
- 修复 ORM 和数据库问题的最佳方式是移除那些层;
- 访问数据库对象可以和访问普通的.NET 类一样简单;
- 没有传统限制的数据库可以提供设计自由;
- 类似 Starcounter 这样的混合数据库让这一点成为可能。
本文将重点介绍当前供软件开发人员和独立软件供应商使用的 MVC 框架所存在的一些问题,然后利用内存内应用程序引擎 Starcounter 提供了解决方案。为了尽可能地真实,几个源于实际项目的例子使用了 ASP.NET+Entity Framework(数据库优先和代码优先),并以 MS-SQL Server 或 MySQL 作为数据库引擎。本文末尾有一个简单的入门项目,不要读过就完了,还要亲自测试一下。
在开发业务应用程序时,你会发现,几乎每个应用程序都需要一致性管理及在多个并发用户之间共享数据。通常,该功能是由数据库管理系统(DBMS)提供的。早在 70 年代初,大部分 DBMS 就实现了标准数据操作语言 SQL。于是,软件开发人员需要根据每个系统的优缺点选择一种数据存储方法。然而,所有的应用程序差不多都采用了同样的设计:应用程序逻辑在这里,数据库在那里。
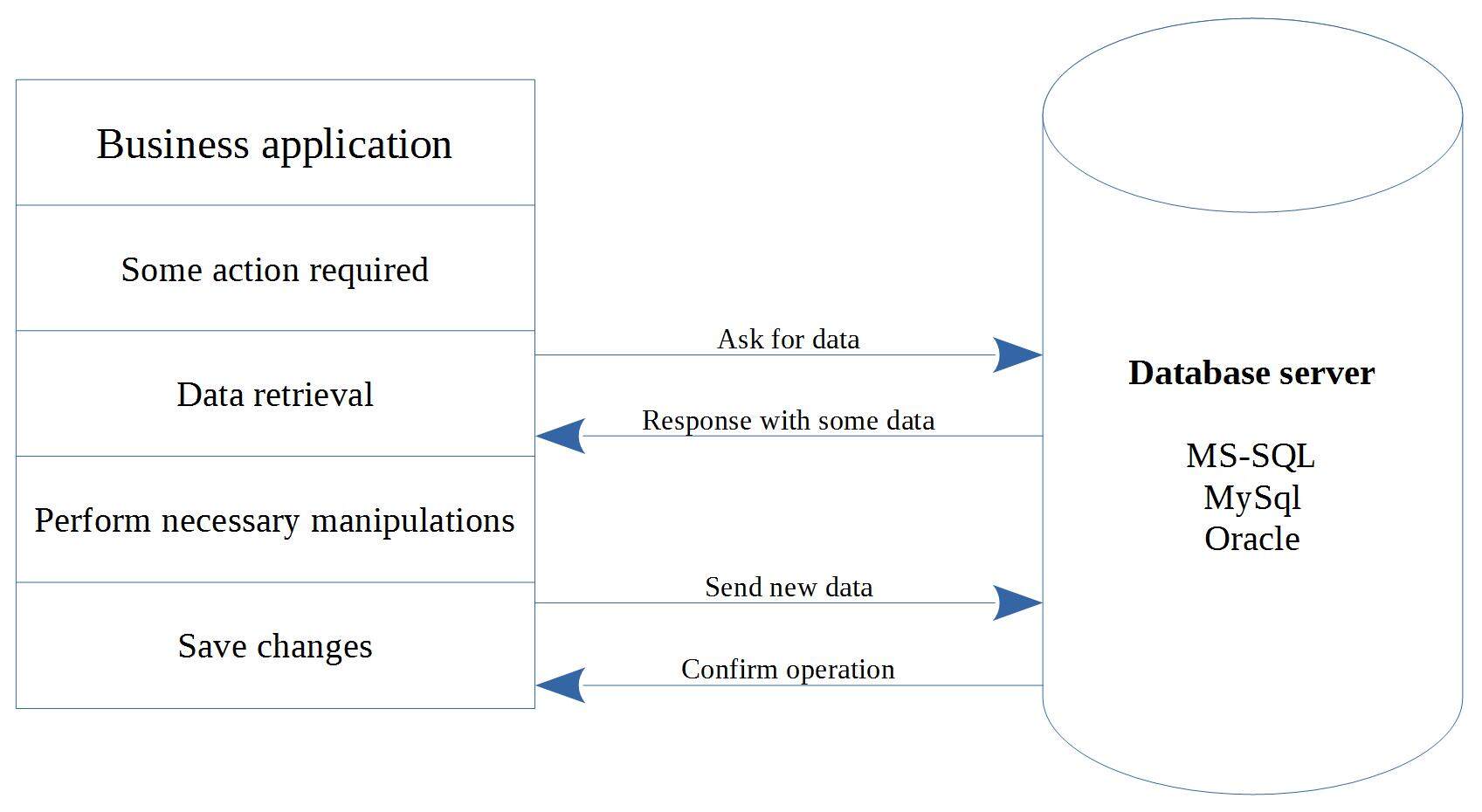
1.ORM
SQL 数据库引擎按照表、列和行来操作数据。使用任意 OOP 语言编写的应用程序则按照类、属性和实例来操作数据。
这种失配会导致应用程序和数据库之间的通信层产生大量的冗余代码。为了减少冗余代码、Bug 和开发时间,ORM 库(对象关系映射)被发明出来。
ORM 在应用程序和数据库之间又加了一层。ORM 充当了表、列、行和类、属性、实例概念之间的翻译。
ORMs 旨在:
1.1. 移除应用程序中的所有 SQL 代码;
1.2. 为访问数据库表提供和访问普通的应用程序类一样的方式;
1.3. 为不修改应用程序代码切换数据库引擎提供可能。
这可能听上去很好,但遗憾的是,没有这样的好事。下面是当前使用 ORM 的实际情况:
1.1. 减少应用程序中的 SQL 代码;
1.2. 为访问数据库表提供和访问普通的应用程序类类似的方式;
1.3. 为少修改应用程序代码切换数据库引擎提供可能。
出现这种情况不是因为 ORM 不好,而是因为数据库引擎的架构。让我们看下究竟是什么限制了 ORM。
1.1. 移除应用程序中的所有 SQL 代码
在任何 SQL 数据库引擎中,SQL 查询都是唯一的数据操作方式。ORM 应该将表类实例上的每个动作转换成 SQL 查询,并在数据库里运行。
ORM 尚不够智能,无法选择最好的 SQL 语法。大型复杂查询还是应该由开发人员利用自己的 SQL 知识来编写。
有些动作,如触发器,只能在数据库引擎内执行,而该引擎只支持 SQL。
1.2. 为访问数据库表提供和访问普通的应用程序类一样的方式
类实例的属性值和实例本身都保存在内存中。表类的属性值保存在数据库引擎中,可能是 HDD 或内存的另一部分。为了访问表类实例,我们必须将所有的属性值一起加载,或者按需加载每个属性(延迟加载)。这两种方法都可能会导致性能问题。
在访问表类的实例时,开发人员应该牢记数据库的限制。
我们都知道“计算属性(calculated properties)”有多重要,但遗憾的是,ORM 不支持。例如,考虑下下面的类和查询:
public class OrderItem {
public int Quantity;
public decimal Price;
public decimal Amount {
return this.Price * this.Quantity;
}
}
var items = db.OrderItems.Where(x => x.Amount > 1000);
Where 查询会被转换成 SQL,然后失败,因为数据库没有提供 Amount 属性。
1.3. 为不修改应用程序代码切换数据库引擎提供可能
有许许多多不同的数据库引擎,每一种都有自己独一无二的特性、优点和不足。如果不检查并重写应用程序某些部分的代码,就不可能切换数据库引擎。上一个引擎的独特特性必须删除。
尝试将一个项目从 MS-SQL 迁移到 MySQL,从 MS-SQL 迁移到 MS-SQL CE,或者反过来,你就了解所面临的挑战了:不同的数据类型,不同的“跳过 N 行”和“取前 N 行”实现、不同的子查询、视图、存储过程实现和限制。
2. 领域驱动设计(DDD)
将业务应用程序分成两部分(应用和数据库)会导致一些重大问题。为了解决那些问题,领域驱动设计被发明出来。
下面列出了 DDD 旨在解决的部分问题:
2.1. 项目中相同的功能,其实现方式相同或者在不同的地方不同;
2.2. 同一个项有不止一个对象;
2.3. 有的对象的属性实际上不是那个对象的基本属性;
2.4. 相关项之间有一个糟糕的关系;
2.5. 无法通过查看对象了解整个应用。
这里有一篇介绍 DDD 的文章:领域驱动设计——开始之前先明确思想。
现在,我们将详细介绍上面列出的每一条内容,理解下都是什么情况。
2.1. 项目中相同的功能,其实现方式相同或者在不同的地方不同
这个问题的原因无疑是应用被分成了不同的部分。下面是一个简单的例子:
有个购物车,里面有一些物品。下面是两个场景。
a)用户向购物车添加或从购物车删除一个物品。总价会在用户保存修改之前自动计算。这个计算是由应用程序完成。
b)管理员按照总价顺序列出了所有购物车。总价是由数据库计算的。
大多数开发人员会倾向于在购物车中添加一个 TotalAmount 属性。一旦购物车里的物品发生了变化,TotalAmount 属性就会更新。这解决了第一个问题,但导致了上面列出的第三个问题。
2.2. 同一个项有不止一个对象
应用程序和数据库之间的通信速度是最大的性能缺陷之一。为了减少传输的数据量,有些大表可能会有两个或两个以上的 ORM 类。
一个简单的例子,下表:
CREATE TABLE Cars (
ID int,
Driver varchar,
PlateNumber varchar,
Brand varchar,
Model varchar,
Kit varchar,
Color varchar,
Engine decimal,
Travelled int,
Year int,
Cost decimal,
FuelConsumption decimal
)
可能会产生两个场景:
a)显示所有汽车的列表——需要所有字段;
b)在一个自动完成字段中显示汽车列表——只需要 ID、Driver 和 PlateNumber 值。
如果这两种情况使用相同的 ORM 类,那么,即使汽车类的所有字段值不会都用到,也会全部从数据库加载到应用程序。这意味着传输了更多的数据、消耗了更多的时间,最终就要承担客户不满意的风险。
如果这两种情况使用不同的 ORM 类,就会违反 DDD 模式。当应用程序被分成不同的部分,就会导致问题。如果表 Cars 位于应用程序之内,这个问题就不存在了。
2.3. 有的对象的属性实际上不是那个对象的基本属性
通常,深度嵌套需要冗余属性来提升性能。
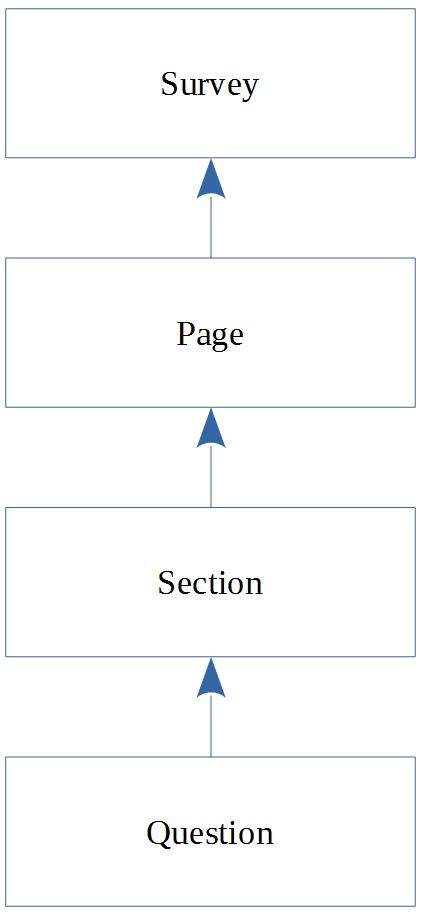
这是一个简单且常见的模型。现在假设,我们有一项调查,并且需要查询调查的所有问题。
SQL 的写法如下:
SELECT Question.*
FROM Question INNER JOIN Section ON Question.SectionID = Section.ID
INNER JOIN Page ON Section.PageID = Page.ID
INNER JOIN Survey ON Page.SurveyID = Survey.ID
WHERE Survey.ID = ?
LINQ 查询的写法如下:
Context.Questions.Where(q => q.Section.Page.SurveyID = ?);
那么,这个查询有什么问题呢?有性能问题。
看下下面这张图。这张图看上去要复杂一些,因为有四个冗余关系。
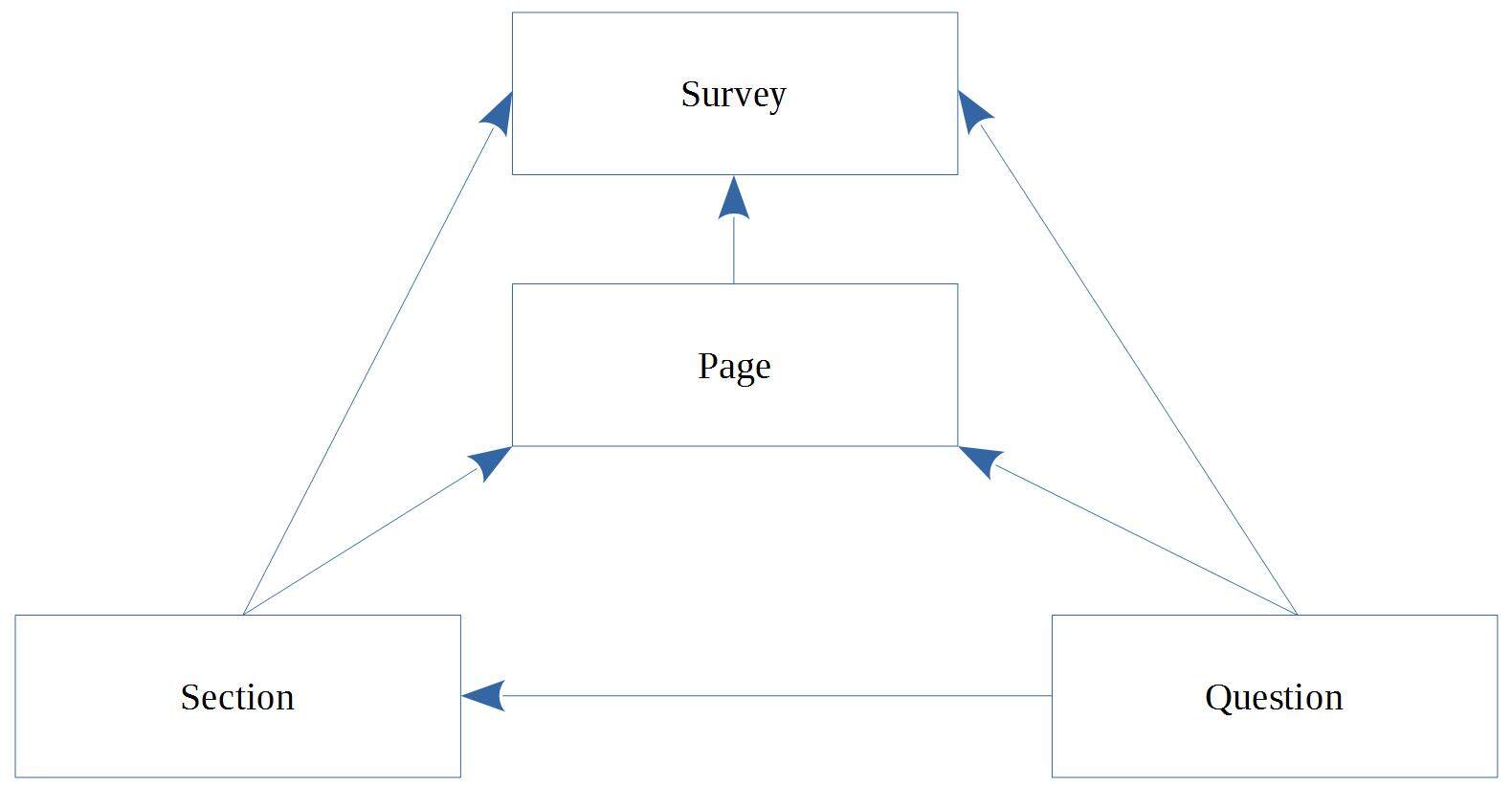
由于添加了其他的关系,SQL 查询变成了下面的样子:
SELECT *
FROM Question
WHERE Question.SurveyID = ?
我们为什么需要那些冗余属性和关系呢?答案很简单:为了提升性能。如果第一种方法运行得足够快,我们还会添加那些关系吗?当然不会。
2.4. 相关项无法很好地协调
相互关联的两个表可以作为这个问题的一个例子。
TABLE A (ID, Name, BID);
TABLE B (ID, Name, AID);
插入两行相互关联的记录需要三个操作:
Insert row A.
Insert row B with AID.
Update BID of row A.
这段代码在 ORM 表类里是行不通的:
var a = new A();
var b = new B();
a.Name = “Instance of A with B”;
a.B = b;
b.Name = “Instance of B with A”;
b.A = a;
Context.SaveChanges();
这还是因为类和表之间的转换。SQL 数据库引擎不支持同时插入两行或多行数据。
另一个例子是“多重选择(multi-select)”值。
TABLE Motherboard (
ID int,
Brand varchar,
Socket varchar,
Ram varchar,
Name varchar
);
TABLE CPU (
ID int,
Brand varchar,
Socket varchar,
Name varchar
);
-- 主板支持的 CPU
TABLE MotherboardCpu (
ID int,
MotherboardID int,
CpuID int
);
当一定会选择多行时,例如,当需要查询所有主板及其支持的 CPU 时,当通过 CPU 名称过滤时,从 MotherboardCpu 表查询并处理数据会显著地降低性能。
开发人员通常会使用下面的数据模型替换上述模型:
TABLE Motherboard (
ID int,
Brand varchar,
Socket varchar,
Ram varchar,
Name varchar,
-- 以 CSV/JSON 格式列出支持的 CPU 名称
Cpu text
);
TABLE Cpu (
ID int,
Brand varchar,
Socket varchar,
Name varchar
);
从领域设计的角度看,Motherboard 和 CPU 是两个相关的实体,但它们在数据库里没有任何关系。
2.5. 无法通过查看对象了解整个应用
下面的例子是一个项目中的实体图。
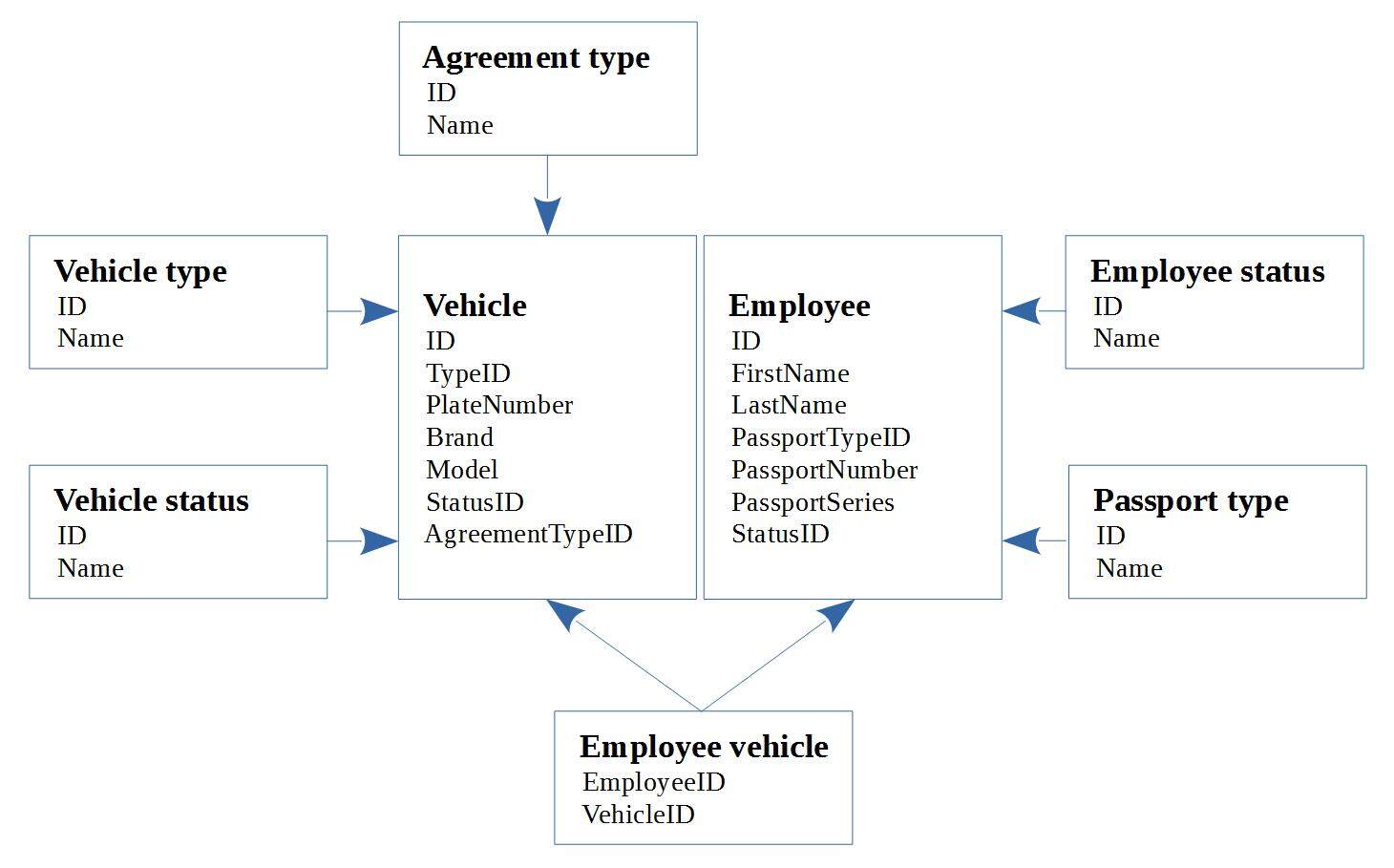
项目中的每张表都需要一个 ORM 类、一个 JSON 表示类和一个 JavaScript 类。每个表三个类,而且表也难以维护。开发人员决定将将所有的状态和类型存到一张表里,从而减少表的数量。最后,数据表图如下:
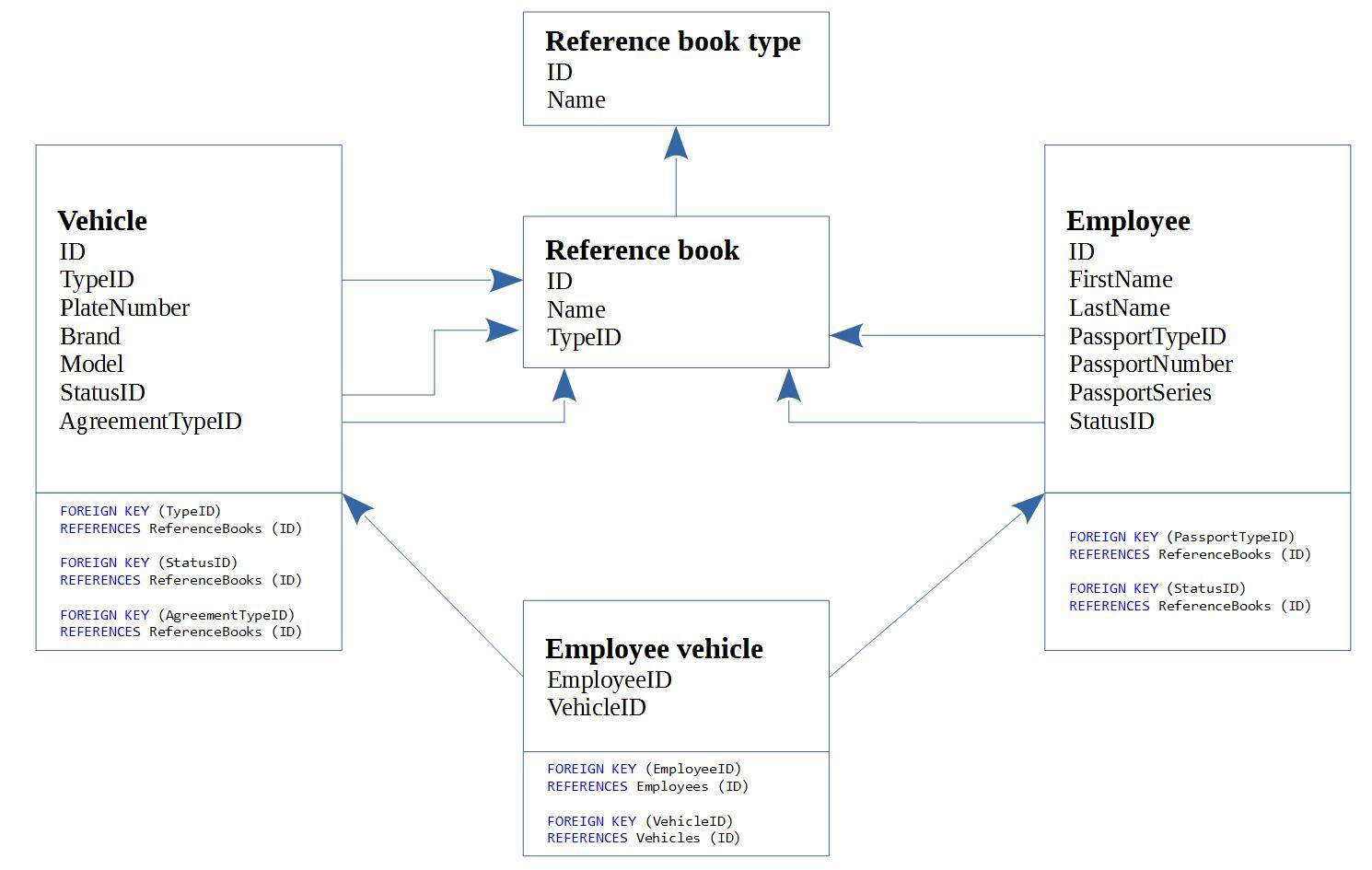
实体图很清晰,一目了然,而数据表图则相当难理解。框架的限制导致开发人员需要在数据库纯净度和代码纯净度之间进行取舍。
Starcounter
下图展示了 Starcounter 的架构。
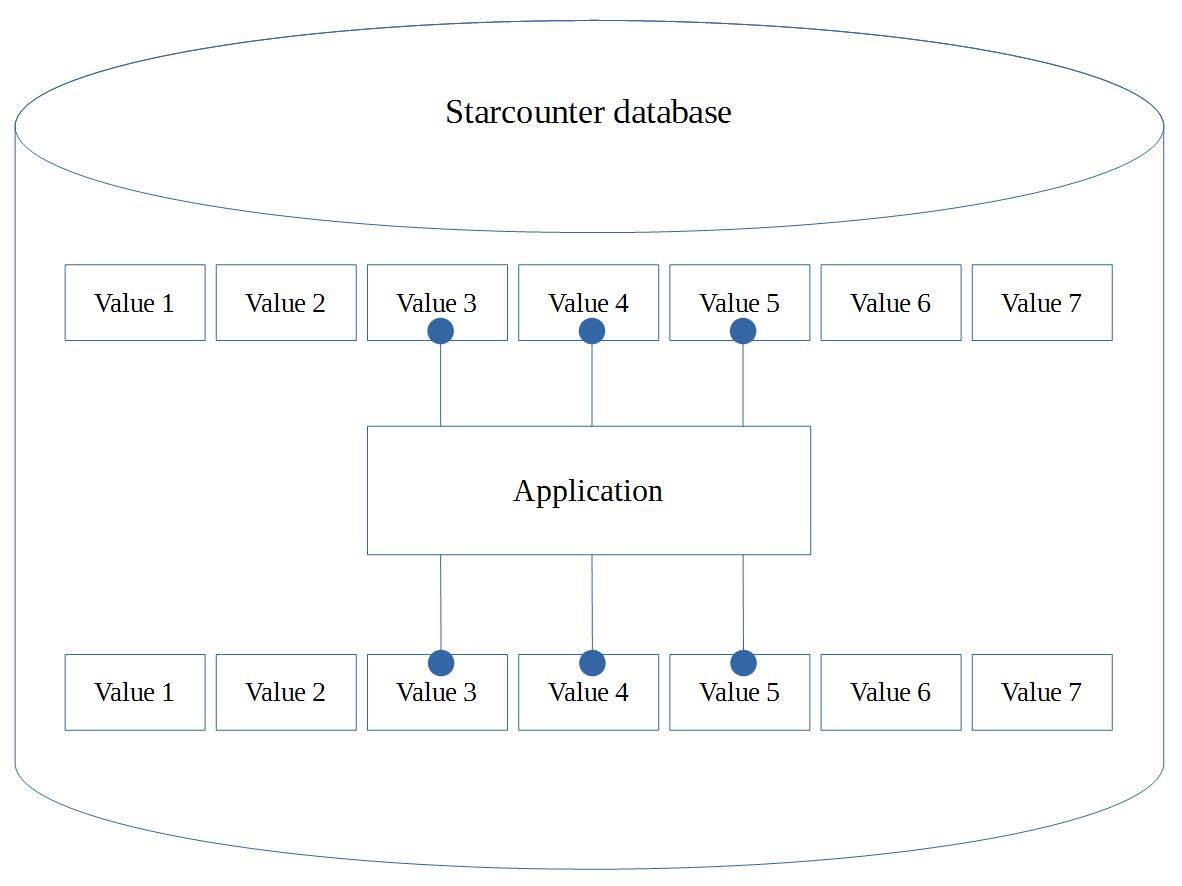
该图展示了运行在数据库里的 Starcounter 应用程序,它可以直接访问保存在 RAM 中的数据库对象。
数据不需要在数据库和应用程序之间往返。应用程序类即数据库对象。有了 Starcounter,就不需要 ORM 或其他映射器了。
下面是一个数据库类定义。
[Database]
public class Vehicle {
public string PlateNumber;
public string Brand;
public string Model;
}
没有上下文声明,没有表名或者属性名映射器,有的只是带有属性的 C#类。下面是另外一个带有外键的例子。
[Database]
public class VehicleStatus {
public string Name;
}
[Database]
public class Vehicle {
public string PlateNumber;
public string Brand;
public string Model;
public VehicleStatus Status;
}
情况还是一样。没有外键声明,没有映射,有的只是 C#属性。现在让我们看下,Starcounter 解决了上述哪些问题?
1.1. 移除应用程序中的所有 SQL 代码
目前,Starcounter 仍然需要使用一些 SQL 从数据库中查询对象。不过,你需要编写的 SQL 数量大幅减少,因为你可以追踪属性,从一个对象到下一个对象,而不必使用联合或多重查询。
1.2. 为访问数据库表提供和访问普通的应用程序类一样的方式
是的,绝对的。
数据库对逻辑复杂的只读属性提供了完全支持。由于 C#对象即数据库对象,所以不存在任何数据类型问题。
1.3. 为不修改应用程序代码切换数据库引擎提供可能
不,代码修改和调整是必需的。Starcounter 使用一种与传统数据库引擎完全不同的方法。
2.1. 项目中相同的功能,其实现方式相同或者在不同的地方不同;
Starcounter 没有数据库端和应用程序端。数据库对象即应用程序对象,反之亦然。而且,大多数 Starcounter 应用程序在服务器和客户端之间共用相同的模型。JavaScript 库 PuppetJs 负责同步服务器和客户端之间的变化。
最后,只有一个模型类,一个地方编写逻辑,降低了在不同地方编写相同逻辑的可能性。
2.2. 同一个项有不止一个对象
不需要为数据库对象创建任何额外的类或映射器;整个项可以直接从内存访问。
2.3. 有的对象的属性实际上不是那个对象的基本属性
如果每个对象的每个属性都可以直接访问,而且很简单,就不需要创建额外的属性。CPU 类应该有一个 Motherboard 的引用,Motherboard 类应该有一个 PC Case 的引用,但 CPU 类不应该包含任何 PC Case 的引用。
2.4. 相关项无法很好地协调
与传统 SQL 数据库不同,Starcounter 允许你同时存储两个相关对象。下面的代码可以正常运行:
Db.Transact(() => {
var a = new A();
var b = new B();
a.Name = "Instance of A with B";
a.B = b;
b.Name = "Instance of B with A";
b.A = a;
});
多重查询属性的问题更容易解决:
[Database]
public class Motherboard {
public string Brand;
public string Socket;
public string Ram;
public string Name;
public IEnumarable<MotherboardCpu> MotherboardCpus {
get {
return Db.SQL<MotherboardCpu>("
SELECT o FROM MotherboardCpu o WHERE o.Motherboard = ?", this);
}
}
public string MotherboardCpuNames {
get {
return string.Join(", ", this.MotherboardCpus.Select(x => x.Name));
}
}
}
[Database]
public class Cpu {
public string Brand;
public string Socket;
public string Name;
}
[Database]
public class MotherboardCpu {
public Motherboard Motherboard;
public Cpu Cpu;
}
只读属性 MotherboardCpuNames 完全可以在数据库层面访问。下面的 SQL 查询是有效的!
var motherboards = Db.SQL<Motherboard>(
"SELECT o FROM Motherboard o WHERE o.MotherboardCpuNames LIKE ?",
"%i7-5___%");
注意:字符串连接是一项性能代价很高的任务。使用务必要恰当。
下面这个查询是上述查询的另一个版本,速度比上述查询快 25 倍:
var motherboards = Db.SQL<Motherboard>(
"SELECT c.Motherboard FROM MotherboardCpu c WHERE c.Cpu.Name LIKE ?",
"%i7-5%").Distinct();
2.5. 无法通过查看对象了解整个应用
Starcounter 提供了一种简洁的方式,让开发人员可以根据需要创建任意多的数据库类。使用什么样的设计模式,应用什么样的架构,完全由开发人员决定。
小结
对于那些经历过上述任何问题的开发人员、小型创业公司或者大型企业来说,现在有解决方案了。从我个人的经验来看,我用过 ASP.NET MVC,倾向于不使用 PHP,尊重 Ruby on Rails。现在,我无法想象切回其中任何一项技术并编写大量的胶水代码。
作为入门,这里有一个简单的项目,对ASP.NET MVC 和Starcounter 这两项技术做了很好地比较,你可以试一下。
关于作者
 Kostiantyn Cherniavskyi是一名资深应用程序开发人员。他在 C#、ASP.NET、MVC、PHP、数据库建模、MS-SQL、MySQL 等方面有 6 年多的经验。
Kostiantyn Cherniavskyi是一名资深应用程序开发人员。他在 C#、ASP.NET、MVC、PHP、数据库建模、MS-SQL、MySQL 等方面有 6 年多的经验。
查看英文原文: Starcounter vs. ORM and DDD




