
昆仑万维是全球领先、业内前沿的综合性互联网集团,业务涵盖昆仑游戏(GameArk)、信息资讯(Opera)等多个业务板块。其中,昆仑游戏(GameArk)凭借研发及运营的核心优势,面向全球进行游戏的研发、发行与运营,形成多样性的产品矩阵。截止 2020 年底,月活用户达到上亿规模。
面临挑战
游戏业务在运营过程中会产生大量数据,比如道具产生消耗、货币产生消耗、玩家等级分布、任务完成情况、各地图玩家分布、玩家战斗数据等等。随着业务深入发展和精细化运营的不断加深,市场投放和运营所需的数据维度越来越多,越来越细,开始呈现爆发式的增长态势,如何存放及分析这些数据成为迫切需要解决的问题。在复杂的场景下,昆仑游戏开始使用多种数据库支撑业务,从传统关系型数据库到 NoSQL、NewSQL,以及各类分析数据的系统和工具,这为运维与管理层面带来了严峻挑战。
从 MySQL Cluster 到 TiDB 的升级
昆仑游戏从 2008 年拓展业务开始,技术的传承既带来了经验的积累,也导致了技术债的产生。昆仑游戏的数据分析系统,为业务提供实时的游戏汇总数据,例如金币消耗、道具购买分布等。游戏业务实时将产生的信息按照指定格式发送到指定接口,MySQL 数据库接到汇报过来的数据进行存储。初期在数据量不大的情况下,数据库运行比较稳定。随着业务的快速发展,MySQL 单表的数据突破 5000 万条之后, 数据的入库与实时查询都开始变慢,从而无法适应业务需求。
昆仑游戏在综合考量后决定:在尽量不重构现有业务端代码的基础上,对现有 MySQL 方案进行平滑过渡和升级改造。最开始是优化 SQL 查询语句,查找慢查询的原因。随着单表数据量的增多,昆仑游戏发现 SQL 执行效率的提升并不明显。如果按时间对 MySQL 进行分库分表,随之而来的是跨节点查询 Join 、跨节点分页、排序、函数等一系列问题,方案过于复杂,并且需要改写业务端代码。从本质上来讲,这是以“打补丁”的方式来实现横向扩展。
为了更好地解决单点故障问题,昆仑游戏的数据库形态从最初的 MySQL 单库,MySQL 主从、一主多从,升级到了 MySQL Cluster。MySQL Cluster 是 Oracle 官方提供的企业级数据库方案,采用了 Shared Nothing 的架构设计,该方案的优点是解决了以前的 MySQL 单点故障,提供自动失效切换,相较来说有更好的可扩展性与更高的处理性能。
但 MySQL Cluster 方案也存在明显缺点:首先是成本高昂,原有版本的 MySQL Cluster 的数据节点把数据都存放在内存里,单一节点的内存通常需要配置到 512GB ,甚至更高。可以预料的结果是,当随着海量数据的增长,所需节点也会越来越多,硬件成本的提升也将很迅速;其次,MySQL Cluster 存在诸多限制,例如不支持外键,数据行不能超过 8K 等;第三,该方案的备份和恢复并不方便,恢复数据需要 IT 人员到每个数据节点上以敲指令的形式执行,且无法备份到如 S3 等云端存储;此外,整套系统的部署、管理、配置相对比较复杂,无法与现有基于云的 IT 架构完美匹配。
昆仑游戏希望采用云原生 NewSQL 数据库来匹配性能、扩展性以及云端部署与运维等方面的需求。经过对市场上主流的 NewSQL 数据库进行调研与真实业务场景测试对比之后,昆仑游戏决定选用 TiDB 扩展数据架构体系的能力版图。
TiDB 解决之道
昆仑游戏基于公有云构建起一套支持高并发、高可用、可横向扩展的 TiDB 分布式数据库集群,实现游戏类业务数据的集中管理,同时为报表、监控、运营、用户画像与大数据计算等业务提供数据服务。
通过使用 TiDB Data Migration (DM) 工具,昆仑游戏将多个 MySQL 库的数据同步到 TiDB 集群,并借助 TiDB 的水平扩展能力提供理论上容量无上限的存储能力。目前,昆仑游戏的 TiDB 集群数据规模已达到几十 TB 。未来,昆仑游戏还将会结合自身的业务需求以及 TiDB 的新特性,探索更多业务场景。
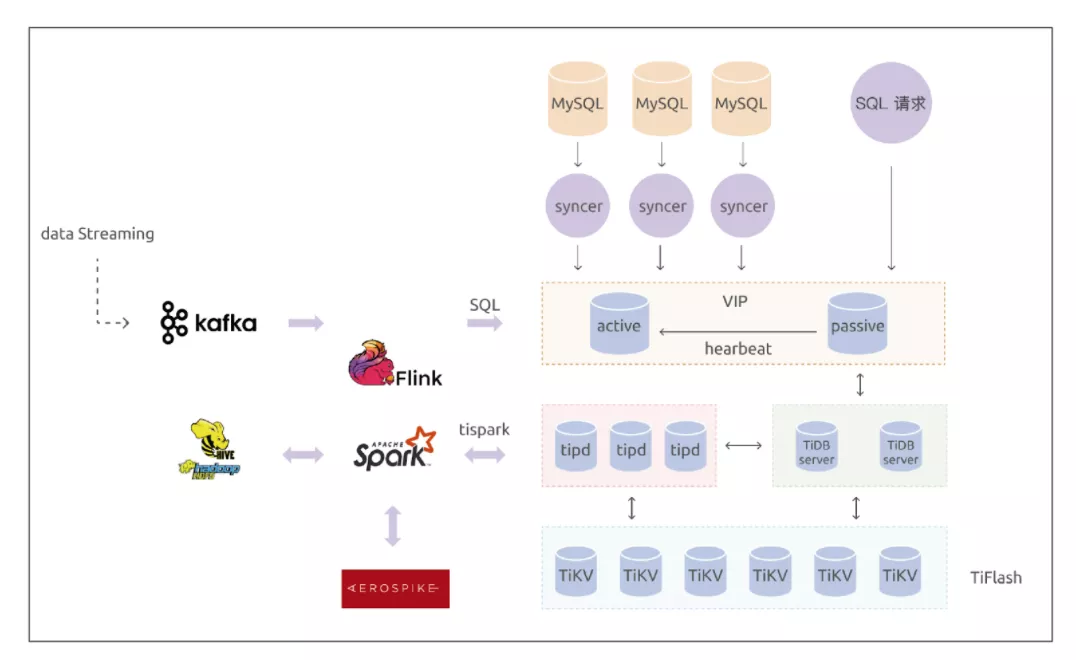
逻辑架构图
为什么选择 TiDB?
昆仑游戏通过构建 TiDB 数据服务平台,解决了原有数据库系统在性能、扩展性以及云端部署与运维等方面的问题,提升了面向业务的数据服务能力。其主要优势集中体现在以下几方面:
TiDB 与 MySQL 高度兼容,原有业务代码基本不用改动,实现了业务的平滑切换;
在架构与性能方面,TiDB 存储计算分离的架构设计,打破了单机数据库的容量和性能瓶颈,可以实现性能与容量的弹性伸缩,读写 QPS 与平均延时完全满足业务要求;
在生态方面,TiDB 具备强大的生态体系,支持连接 Spark、Flink、Kafka 等数据应用生态,为业务打造全场景的数字化服务平台;
在成本方面,TiDB 支持云端部署与运维,并且可与 S3 无缝对接。将整套数据分析系统搬到云端部署以后,硬件成本下降 50% 以上。
“ 我们的目标是把数据服务变得更加敏捷:一是通过分布式架构提升数据库的服务效率,让数据库更好地满足业务的需求;二是让数据库应用层与底层 IT 技术进行解耦, 减少上层应用对底层技术的依赖,降低整体的 IT 建设与运维成本。”
——昆仑游戏 IT 运维总监 刘晗




