
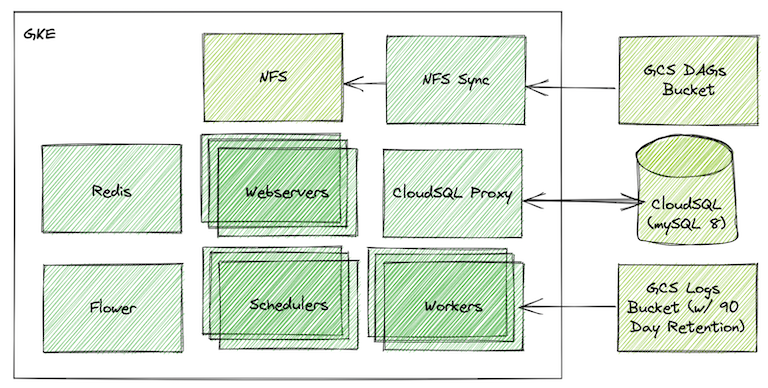
Apache Airflow 是一个能够开发、调度和监控工作流的编排平台。在 Shopify,我们已经在生产中运行了两年多的 Airflow,用于各种工作流,包括数据提取、机器学习模型训练、Apache Iceberg 表维护和 DBT 驱动的数据建模。在撰写本文时,我们正通过 Celery 执行器和 MySQL 8 在 Kubernetes 上来运行 Airflow 2.2。
Shopify 在 Airflow 上的应用规模在过去两年中急剧扩大。在我们最大的应用场景中,我们使用了 10000 多个 DAG,代表了大量不同的工作负载。在这个场景中,平均有 400 多项任务正在进行,并且每天的运行次数超过 14 万次。由于 Shopify 的内部采用率越来越高,我们的 Airflow 部署将会产生更多的负载。因为这样的迅速增长,我们所面临的困难包括:文件存取速度太慢、对 DAG(Directed acyclic graph,有向无环图)能力的控制不足、流量水平的不规则、工作负载之间的资源争用等等。
接下来,我们将与大家分享我们所获得的经验以及我们为实现大规模运行 Airflow 而构建的解决方案。
使用云端存储时,文件存取速度可能会变慢
对于 Airflow 环境的性能和完整性,快速的文件存取速度至关重要。一个清晰的文件存取策略可以保证调度器能够迅速地对 DAG 文件进行处理,并且让你的作业保持更新。
通过重复扫描和重新解析配置的 DAG 目录中的所有文件,可以保持其工作流的内部表示最新。这些文件必须经常扫描,以保持每个工作负载的磁盘数据源和其数据库内部表示之间的一致性。这就意味着 DAG 目录的内容必须在单一环境中的所有调度器和工作器之间保持一致(Airflow 提供了几种方法来实现这一目标)。
在 Shopify 中,我们利用谷歌云存储(Google Cloud Storage,GCS)来存储 DAG。我们最初部署 Airflow 时,利用 GCSFuse 在单一的 Airflow 环境中的所有工作器和调度器来维护一致的文件集。然而,在规模上,这被证明是一个性能瓶颈,因为每个文件的存取都会引起对 GCS 的请求。由于在环境中的每一个 pod 都需要单独挂在桶,所以存取量特别大。
经过几次试验,我们发现,在 Kubernetes 集群上运行一个 NFS(Network file system,网络文件系统)服务器,可以大大改善 Airflow 环境的性能。然后,我们把 NFS 服务器当作一个多读多写的卷转进工作器和调度器的 pod 中。我们编写了一个自定义脚本,使该卷的状态与 GCS 同步,因此,当 DAG 被上传或者管理时,用户可以与 GCS 进行交互。这个脚本在同一个集群内的单独 pod 中运行。这使得我们可以有条件地在给定的桶中仅同步 DAG 的子集,或者根据环境的配置,将多个桶中的 DAG 同步到一个文件系统中(稍后会详细阐述)。
总而言之,这为我们提供了快速的文件存取作为一个稳定的外部数据源,同时保持了我们快速添加或修改 Airflow 中 DAG 文件的能力。另外,我们还可以利用谷歌云平台的 IAM(识别和存取管理)功能来控制哪些用户能够上传文件到特定的环境。例如,我们可以让用户直接将 DAG 直接上传到 staging 环境,但将生产环境的上传限制在我们的持续部署过程中。
在大规模运行 Airflow 时,确保快速文件存取的另一个考虑因素是你的文件处理性能。Airflow 具有高度的可配置性,可以通过多种方法调整后台文件处理(例如排序模式、并行性和超时)。这使得你可以根据需求优化环境,以实现交互式 DAG 开发或调度器性能。
元数据数量的增加,可能会降低 Airflow 运行效率
在一个正常规模的 Airflow 部署中,由于元数据的数量而造成的性能降低并不是问题,至少在最初的几年里是这样。
但是,从规模上看,元数据正在迅速地累积。一段时间之后,就可能开始对数据库产生额外的负载。这一点在 Web 用户界面的加载时间上就可以看得出来,尤其是 Airflow 的更新,在这段时间里,迁移可能要花费数小时。
经过反复试验,我们确定了 28 天的元数据保存策略,并实施了一个简单的 DAG,在 PythonOperator 中利用 ORM(对象关系映射)查询,从任何包含历史数据(DagRuns、TaskInstances、Logs、TaskRetries 等)的表中删除行。我们之所以选择 28 天,是因为它可以让我们有充足的历史记录来管理事件和跟踪历史工作绩效,同时将数据库中的数据量保持在合理的水平。
import loggingfrom datetime import datetime, timezone, timedeltafrom sqlalchemy import deletefrom airflow.models import DAG, Log, DagRun, TaskInstance, TaskReschedule, Variablefrom airflow.jobs.base_job import BaseJobfrom airflow.utils.dates import days_agofrom airflow.operators.python import PythonOperatorfrom airflow.utils.state import Statefrom airflow.utils.session import provide_sessionEXPIRATION_WEEKS = 4@provide_sessiondef delete_old_database_entries_by_model(table, date_col, session=None): expiration_date = datetime.now(timezone.utc) - timedelta(weeks=EXPIRATION_WEEKS) query = delete(table).where(date_col < expiration_date) if "state" in dir(table): query = query.where(State.RUNNING != "state") result = session.execute(query) logging.info( "Deleted %s rows from the database for the %s table that are older than %s.", result.rowcount, table, expiration_date, )def delete_old_database_entries(): if Variable.get("ENABLE_DB_TRUNCATION", "") != "True": logging.warning("This DAG will delete all data older than %s weeks.", EXPIRATION_WEEKS) logging.warning("To enable this, create an Airflow Variable called ENABLE_DB_TRUNCATION set to 'True'") logging.warning("Skipping truncation until explicitly enabled.") return delete_old_database_entries_by_model(TaskInstance, TaskInstance.end_date) delete_old_database_entries_by_model(DagRun, DagRun.end_date) delete_old_database_entries_by_model(BaseJob, BaseJob.end_date) delete_old_database_entries_by_model(Log, Log.dttm) delete_old_database_entries_by_model(TaskReschedule, TaskReschedule.end_date)dag = DAG( "airflow-utils.truncate-database", start_date=days_ago(1), max_active_runs=1, dagrun_timeout=timedelta(minutes=20), schedule_interval="@daily", catchup=False,)PythonOperator( task_id="cleanup-old-database-entries", dag=dag, python_callable=delete_old_database_entries,)遗憾的是,这就意味着,在我们的环境中,Airflow 中的那些依赖于持久作业历史的特性(例如,长时间的回填)并不被支持。这对我们来说并不是一个问题,但是它有可能会导致问题,这要取决于你的保存期和 Airflow 的使用情况。
作为自定义 DAG 的另一种方法,Airflow 最近增加了对 db clean 命令的支持,可以用来删除旧的元数据。这个命令在 Airflow 2.3 版本中可用。
DAG 可能很难与用户和团队关联
在多租户环境中运行 Airflow 时(尤其是在大型组织中),能够将 DAG 追溯到个人或团队是很重要的。为什么?因为如果一个作业失败了,抛出错误或干扰其他工作负载,我们的管理员可以迅速联系到合适的用户。
如果所有的 DAG 都直接从一个仓库部署,我们可以简单地使用 git blame 来追踪工作的所有者。然而,由于我们允许用户从自己的项目中部署工作负载(甚至在部署时动态生成作业),这就变得更加困难。
为了方便追踪 DAG 的来源,我们引入了一个 Airflow 命名空间的注册表,并将其称为 Airflow 环境的清单文件。
projects: defaults: &defaults source_repository: 'https://github.com/my_organization/dag_repo' dag_source_bucket: 'my_organization_dags' constraints: &constraints airflow_celery_queues: - 'default' pools: - 'default' data_extracts: << : *defaults owner_email: 'etl-team@my-organization.com' source_repository: 'https://github.com/my_organization/airflow_extracts' constraints: << : *constraints namespaces: - 'etl-jobs' pools: - 'extracts' batch_processing: <<: *defaults owner_email: 'spark-team@my-organization.com' source_repository: 'https://github.com/Shopify/airflow_batch_jobs' constraints: <<: *constraints清单文件是一个 YAML 文件,用户必须为他们的 DAG 注册一个命名空间。在这个文件中,他们将包括作业的所有者和源 github 仓库(甚至是源 GCS 桶)的信息,以及为其 DAG 定义一些基本限制。我们为每个环境维护一个单独的清单,并将其与 DAG 一起上传到 GCS。
DAG 作者有很大的权力
通过允许用户直接编写和上传 DAG 到共享环境,我们赋予了他们很大的权力。由于 Airflow 是我们数据平台的核心组成部分,它与许多不同的系统相联系,因此作业有广泛的访问权。虽然我们信任我们的用户,但我们仍然希望对他们在特定的 Airflow 环境中能做什么和不能做什么保持一定程度的控制。这一点在规模上尤为重要,因为要让 Airflow 管理员在所有作业进入生产之前对其进行审查是不现实的。
为了创建一些基本的“护栏”,我们采用了一个 DAG 策略,它从之前提到的 Airflow 清单中读取配置,并通过引发 AirflowClusterPolicyViolation 来拒绝那些不符合其命名空间约束的 DAG。
根据清单文件的内容,该策略将对 DAG 文件应用一些基本限制,例如:
DAG ID 必须以现有名称空间的名称为前缀,以获得所有权。
DAG 中的任务必须只向指定的 celery 队列发出任务,这个将在后面讨论。
DAG 中的任务只能在指定的池中运行,以防止一个工作负载占用另一个的容量。
该 DAG 中的任何
KubernetesPodOperators必须只在指定的命名空间中启动 pod,以防止存取其他命名空间的秘密。DAG 中的任务只能向指定的外部 kubernetes 集群集发射 pod。这个策略还可以延伸到执行其他规则(例如,只允许一组有限的操作者),甚至可以将任务进行突变,以满足某种规范(例如,为 DAG 中的所有任务添加一个特定命名空间的执行超时)。
下面是一个简化的例子,演示如何创建一个 DAG 策略,该策略读取先前共享的清单文件,并实现上述前三项控制:
import osfrom typing import Listimport yamlfrom airflow.exceptions import AirflowClusterPolicyViolationfrom airflow.models import DAGdef validate_pools(dag: DAG, pools: List[str]) -> None: for task in dag.tasks: if task.pool not in pools: raise AirflowClusterPolicyViolation( f"DAG {dag.dag_id} cannot submit tasks to the pool: {task.pool}" )def validate_queues(dag: DAG, queues: List[str]) -> None: for task in dag.tasks: if task.queue not in queues: raise AirflowClusterPolicyViolation( f"DAG {dag.dag_id} cannot submit tasks to the queue: {task.queue}" )def dag_policy(dag: DAG) -> None: airflow_home = os.environ.get('AIRFLOW_HOME', '~/airflow') manifest_path = f"{airflow_home}/airflow_manifest.yaml" with open(manifest_path, "r", encoding="UTF-8") as manifest_file: manifest = yaml.safe_load(manifest_file) dag_namespace = dag.dag_id.split(".")[0] if dag_namespace not in manifest["projects"]: raise AirflowClusterPolicyViolation( f"Namespace {dag_namespace} is not registered in the Airflow Manifest." ) constraints = manifest["projects"][dag_namespace]["constraints"] validate_pools(dag, constraints["pools"]) validate_queues(dag, constraints["queues"])这些验证为我们提供了足够的可追溯性,同时也创造了一些基本的控制,从而减少了 DAG 之间的相互干扰能力。
很难确保负载的一致分布
对你的 DAG 的计划间隔中使用一个绝对的间隔是很有吸引力的:简单地设置 DAG 每运行一次 timedelta(hours=1),你就可以放心地离开,因为你知道 DAG 将大约每小时运行一次。然而,这可能会导致规模上的问题。
当用户合并大量自动生成的 DAG,或者编写一个 Python 文件,在解析时生成许多 DAG,所有的 DAGRuns 将在同一时间被创建。这会导致大量的流量,使 Airflow 调度器以及作业所使用的任何外部服务或基础设施超载,比如 Trino 集群。
在一个 schedule_interval 通过之后,所有这些作业将在同一时间再次运行,从而导致另一个流量激增。最终,这可能导致资源利用率不理想,执行时间增加。
虽然基于 crontab 的时间表不会导致这种激增,但它们也存在自己的问题。人类偏向于人类可读的时间表,因此倾向于创建在整点、每小时、每晚的午夜运行的作业,等等。有时候,它可以为某一特定的应用提供一个合理的理由(比如,我们希望在每个晚上半夜收集前一天的数据),但是我们常常会发现,用户仅仅希望在一个固定的时间间隔内运行他们的作业。如果用户可以直接指定自己的 crontab,那么将会造成流量的激增,这将会对 SLO 造成影响,并且使外部系统的负载不平衡。
作为这两个问题的解决方案,我们对所有自动生成的 DAG(代表了我们绝大多数的工作流)使用一个确定性的随机时间表间隔。这通常是基于一个恒定种子的哈希值,如 dag_id。
下面的片段提供了一个简单的函数示例,该函数生成确定性的、随机的 crontab,产生恒定的时间表间隔。遗憾的是,由于并非全部间隔都可以用 crontab 表示,因此它会限制可能的间隔范围。我们并没有发现这种有限的时间表间隔的选择是有局限性的,在我们确实需要每五小时运行一个作业的情况下,我们只是接受每天会有一个四小时的间隔。
from hashlib import md5from random import randint, seeddef compute_schedule(dag_id, interval): # create deterministic randomness by seeding PRNG with a hash of the table name: seed(md5(dag_id.encode()).hexdigest()) if interval.endswith("h"): val = int(interval[:-1]) if 24 % val != 0: raise ValueError("Must use a number which evenly divides 24.") offset = randint(0, val-1) minutes = randint(0, 59) return f"{minutes} {offset}/{val} * * *" elif interval.endswith("m"): val = int(interval[:-1]) if 60 % val != 0: raise ValueError("Minutes must use a number which evenly divides 60.") offset = randint(0, val-1) return f"{offset}/{val} * * * *" elif interval == "1d": return f"{randint(0, 59)} {randint(0, 23)} * * *" raise ValueError("Interval must be (1, 2, 3, 4, 5, 6, 10, 12, 15, 20, 30)m, (1, 2, 3, 4, 6, 12)h or 1d")得益于我们的随机时间表的实施,我们能够大大平滑负载。下图显示了在我们最大的单一 Airflow 环境中,每 10 分钟完成的任务数。
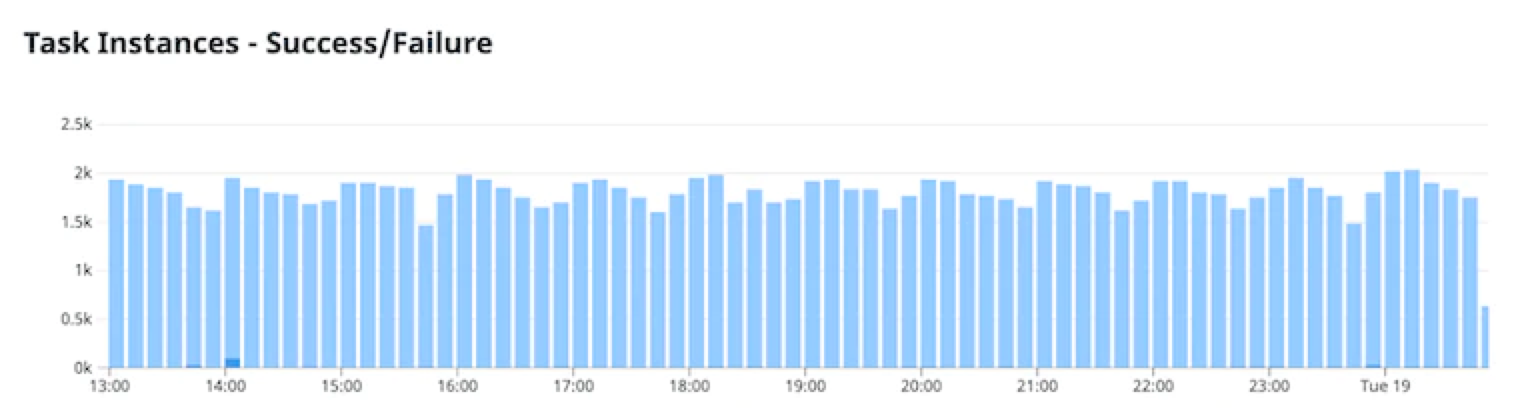
在我们的生产 Airflow 环境中,每 10 分钟执行一次任务存在许多资源争用点
在 Airflow 中,存在着很多可能的资源争用点,通过一系列实验性的配置改变,最终很容易出现瓶颈问题。其中一些资源冲突可以在 Airflow 内部处理,而另一些可能需要一些基础设施的改变。以下是我们在 Shopify 的 Airflow 中处理资源争用的几种方法:
池
减少资源争用的一种方法是使用 Airflow 池。池用于限制一组特定任务的并发性。这对于减少流量激增引起的中断非常有用。虽然池是执行任务隔离的有用工具,但由于只有管理员可以通过 Web UI 编辑池,因此在管理上是一个挑战。
我们编写了一个自定义的 DAG,通过一些简单的 ORM 查询,将我们环境中的池与 Kubernetes Configmao 中指定的状态同步。这让我们可以在管理 Airflow 部署配置的同时管理池,并允许用户通过审查的拉取请求来更新池,而不需要提升访问权限。
优先级权重
Priority_weight 允许你为一个给定的任务分配一个更高的优先级。具有较高优先级的任务将“浮动”到堆的顶部,被首先安排。虽然不是资源争用的直接解决方案,但 priority_weight 对于确保延迟敏感的关键任务在低优先级任务之前运行是很有用的。然而,鉴于 priority_weight 是一个任意的尺度,如果不与所有其他任务进行比较,就很难确定一个任务的实际优先级。我们用它来确保我们的基本 Airflow 监控 DAG(它发出简单的指标并为一些警报提供动力)总是尽可能及时地运行。
同样值得注意的是,在默认情况下,一个任务在做调度决策时使用的有效 priority_weight 是其自身和所有下游任务的权重之和。这意味着,大 DAG 中的上游任务往往比小 DAG 中的任务更受青睐。因此,使用 priority_weight 需要对环境中运行的其他 DAG 有一定了解。
Celery 队列和孤立的工作器
如果你需要你的任务在不同的环境中执行(例如,依赖不同的 python 库,密集型任务有更高的资源允许量,或者不同的存取级别),你可以创建额外的队列,由作业的一个子集提交任务。然后,单独的工作集可以被配置为从单独的队列中提取。可以使用运算符中的 queue 参数将任务分配到一个单独的队列。要启动一个从不同队列运行任务的工作者,可以使用以下命令:
bashAirflow celery worker -queues <list of queues>这可以帮助确保敏感或高优先级的工作负载有足够的资源,因为它们不会与其他工作负载竞争工作者的能力。
池、优先权和队列的任何组合在减少资源争用方面都是有用的。虽然池允许限制单个工作负载内的并发性,但 priority_weight 可以用来使单个任务以比其他任务更低的延迟运行。如果你需要更多的灵活性,工作者隔离可以对执行任务的环境进行细粒度的控制。
重要的是要记住,并不是所有的资源都可以在 Airflow 中被仔细分配:调度器吞吐量、数据库容量和 Kubernetes IP 空间都是有限的资源,如果不创建隔离环境,就无法在每个工作负载的基础上进行限制。
展望
以如此高的吞吐量运行 Airflow,需要考虑很多因素,任何解决方案的组合都是有用的。我们已经学到了很多,我们希望你能记住这些教训,并在你自己的 Airflow 基础设施和工具中应用我们的一些解决方案。
总结一下我们的主要收获:
GCS 和 NFS 的组合可以实现高性能和易于使用的文件管理。
元数据保留策略可以减少 Airflow 的性能下降。
一个集中的元数据存储库可以用来跟踪 DAG 的来源和所有权。
DAG 策略对于执行作业的标准和限制是非常好的。
标准化的计划生成可以减少或消除流量的激增。
Airflow 提供了多种机制来管理资源争用。我们的下一步是什么?我们目前正致力于在单一环境中应用 Airflow 的扩展原则,因为我们正在探索将我们的工作负载分割到多个环境。这将使我们的平台更具弹性,使我们能够根据工作负载的具体要求对每个单独的 Airflow 实例进行微调,并减少任何一个 Airflow 部署的范围。
作者简介:
Megan Parker,供职于 Shopify 的数据平台团队,致力于增强 Airflow 和 Trino 的用户体验,居住加拿大多伦多,爱好户外活动,尤其是自行车和徒步运动。
Sam Wheating,来自加拿大不列颠哥伦比亚省温哥华的高级开发人员。供职于 Shopify 的数据基础设施和引擎基础团队。他是开源软件的内部倡导者,也是 Apache Airflow 项目的贡献者。
原文链接:
https://shopify.engineering/lessons-learned-apache-airflow-scale#circle=on




