
本文是 Uber 在 Go 代码中数据竞争经验两篇文章中的第一篇。详细版本将在 2022 年 ACM SIGPLAN 编程语言设计与实现(Programming Languages Design and Implementation,PLDI)中发表。在本文系列的第二部分,我们将介绍关于 Go 中竞争模式的学习。
Uber 已将 Go 作为主要编程语言,广泛用于开发微服务。我们的 Go 单体仓库由大约 5000 万行代码组成,包含大约 2100 个独特的 Go 服务。Go 使并发性成为一流公民;在函数调用前加上 go 关键字,就会异步运行调用。在 Go 中,这些异步函数调用被称作 goroutines。开发人员通过在单个运行的 Go 程序中创建 goroutines,从而隐藏了延迟(例如,对其他服务的 IO 或 RPC 调用)。goroutines 被认为是 “轻量级的”,Go 的运行时上下文在操作系统(OS)线程上切换它们。Go 程序员经常随意使用 goroutines。两个或多个 goroutines 可以通过消息传递(通道)或共享内存进行数据通信。共享内存恰好是 Go 中最常用的数据通信方式。
在 Go 中,如果两个或更多的 goroutines 访问同一个内存地址时,那么至少有一块是写入的,而且它们之间没有排序,这就是 Go 内存模型所定义的数据竞争。在我们的微服务中,由于数据竞争而导致的 Go 程序的中断是一个反复出现的、令人头疼的问题。由于上述问题,我们关键的、面向客户的服务总共瘫痪了数个小时,造成客户的不便,也影响了我们的收益。在本文中,我们将会讨论 Go 的一个默认动态竞争检测器,它将会在 Go 的开发环境中不断检测数据竞争。这一部署实现了对 2000 多个竞争的检测,使两百多名工程师修复了约 1000 个数据竞争。
动态检测数据竞争
动态竞争检测包括通过检测共享内存访问和同步构造来分析程序的执行。在 Go 中进行单元测试,生成多个 goroutine,这是一个很好的开始,可以进行动态竞争检测。Go 有一个内置的竞争检测器,可以用来在编译时检测代码,以及检测执行过程中的数据竞争。在内部,Go 的竞争检测器采用了 ThreadSanitizer 运行时库,通过结合锁集和基于之前的算法来报告数据竞争。
与动态竞争检测相关的重要属性如下:
由于动态竞争检测依赖于分析的执行,所以不会报告源代码中的所有竞争。
检测到的竞争集依赖于线程交错,甚至程序的输入没有变化,但会在多次运行中发生变化。
何时部署动态数据竞争检测器?
我们在仓库中使用了超过 10 万个 Go 单元测试来执行代码和检测数据竞争。然而,我们面临着一个具有挑战性的问题,即何时部署竞争检测器。
在拉取请求(pull request,PR)时,运行动态数据竞争检测器存在以下问题:
竞争检测具有不确定性。这样,拉取请求所引起的竞争可能不会被曝光,并且可能不会被检测到。这种行为的后果是,随后的良性拉取请求可能会受到检测到的休眠竞争的影响,从而被错误地阻止,进而影响开发人员的生产力。此外,由于在我们 5000 万行的代码库中存在预先存在的数据竞争,这也是一件不可能的事情。
动态数据竞争检测器占用的空间是 2~20 倍,内存开销是 5~10 倍,这可能导致违反我们的 SLA,或者增加硬件成本。
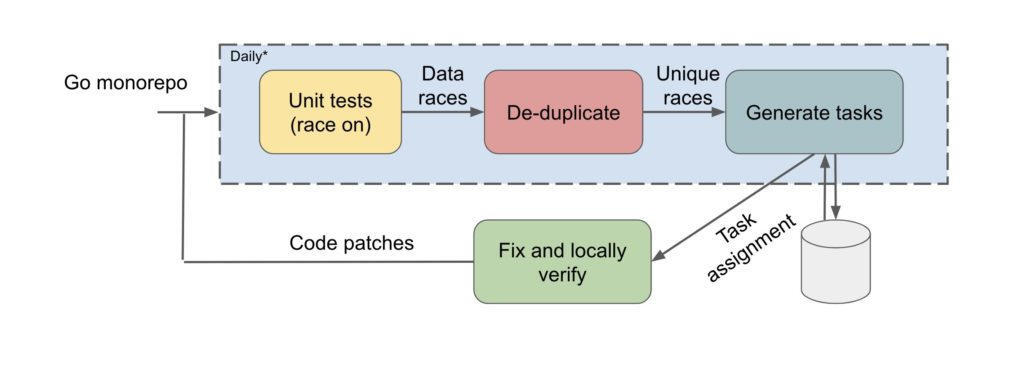
图 1:动态竞争检测工作流的架构
基于这些考虑,我们决定在事后定期在代码快照上部署竞争检测器,这包括以下步骤:
(a) 通过执行仓库中的所有单元测试来进行动态竞争检测。
(b) 通过向适当的 bug 所有者提交任务来报告所有未解决的竞争。
一个检测到的竞争报告包含以下细节:
冲突的内存地址。
2 个冲突访问的调用链(又称调用上下文或堆栈跟踪)。
与每个访问相关的内存访问类型(读取或写入)。
我们解决了几个问题,通过对报告的堆栈竞争进行散列,并应用启发式方法来确定负责修复该错误的潜在开发人员,这样就可以避免重复的竞争。尽管我们已经选定了这种部署路径,但是,如果所检测到的竞争不会妨碍构建,并作为警告通知开发人员,或者对动态竞争检测进行了改善,使得 CI 时间的确定性检测是可行的,那么 CI 时间的部署是可以实现的。
部署的效果
我们在 2021 年 4 月推出了这一部署,并在 6 个月里收集数据。我们的方法帮助检测了单体仓库中的 2000 个数据竞争,每天有数百名 Go 开发人员提交的数据。在报告的 2000 个竞争中,有 1011 个竞争被 210 个不同的工程师修复。我们观察到,有 790 个独特的补丁来修复这些竞争,这表明了独特的根源数量。我们还收集了 6 个多月期间未解决的故障总数的统计数据,并将其报告如下:
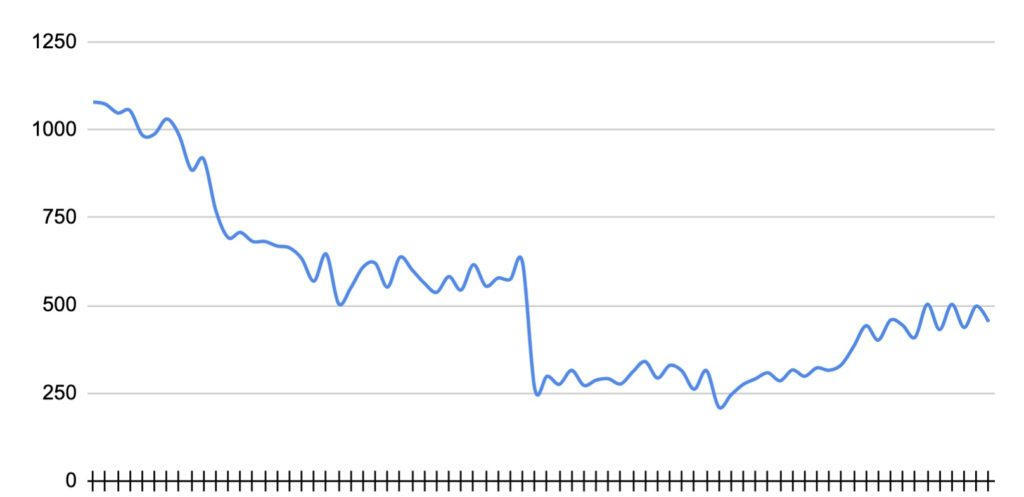
图 2:6 个月内未解决的数据竞争的数量(2021 年 4 月~2021 年 9 月)
在推出的初始阶段(2~3 个月),我们向受让方提供了关于解决数据竞争问题的建议。在这一阶段,未解决的竞争已经出现了明显的减少。后来,随着指导工作的减少,我们注意到,未解决的竞争总数在逐渐增加。该图还表明,未解决的竞争数的波动,这是由于对竞争的修复、新竞争的引入、开发人员对测试的启用和禁用,以及动态竞争检测的基本非确定性。在报告了所有预先存在的竞争后,我们还观察到,工作流平均每天会创建大约 5 个新的竞争报告。
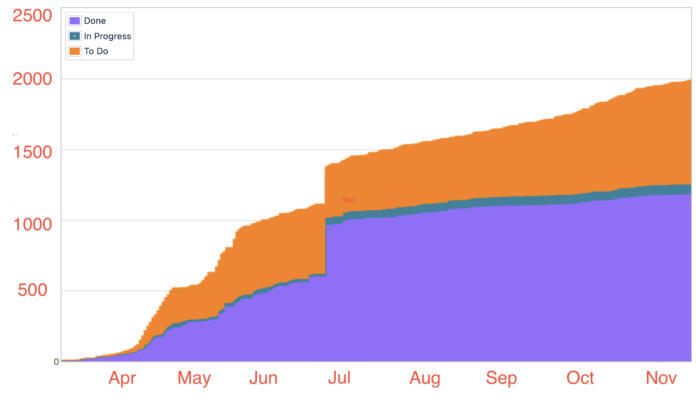
图 3:提交和修复的 Jira 任务的数量说明
就运行我们的离线数据竞争检测器的开销而言,我们注意到,在没有数据竞争检测的情况下,在所有的测试中,95% 的运行时间是 25 分钟,而在启用数据竞争之后,增加了 4 倍,达到约 100 分钟。在数十名工程师的调查中,大约在推出该系统 6 个月后,52% 的开发人员认为该系统有用,40% 的人没有参与该系统,8% 的人认为该系统没有用。
展望未来
我们在这次部署中的经验表明有以下进展:
需要建立可在持续集成(CI)期间部署的动态竞争检测器。这需要新的检测器有效解决由于非确定性和开销带来的挑战。
在这之前,设计算法为检测到的数据竞争寻找根源并确定适当的拥有者,有助于加速数据竞争的修复。
我们已经确定了与 Go 中的数据竞争有关的基本编码模式(在本博客系列的第二部分中将会介绍),而 CI 时间的静态分析检测可能会捕捉到其中一个子集。
所检测的竞争集依赖于输入的测试套件。能够在其他类型的测试(除单元测试外)上运行竞争检测,如集成测试、端到端测试、黑盒测试,甚至生产跟踪,都能帮助检测更多的竞争。
我们还认为,对输入测试套件的时间表进行模糊处理的程序分析工具可以暴露出线程交错,从而增强检测到的竞争集。
最后,目前的方法依赖于通过单元测试的多线程执行的可用性,而手动构建此类测试时,不一定能考虑到所有可能的情况。自动生成多线程执行,其中包含 racy 行为,并且利用检测器来验证竞争,这是一种高效的调试工具。
作者介绍:
Murali Krishna Ramanathan 是一名高级软件工程师,负责 Uber 工程的多项代码质量计划。他是 Piranha 的架构师,Piranha 是一个重构工具,可以自动删除因特性标记过期而导致的代码。他的兴趣是开发工具来解决软件开发的挑战,包括特性标记、自动代码重构和开发人员的工作流,以及自动测试生成以提高软件质量。
Milind Chabbi 是 Uber 编程系统研究团队的一名员工研究员。他领导整个 Uber 在编译器优化、高性能并行计算、同步技术和性能分析工具方面的研究计划,使大型复杂的计算系统变得可靠和高效。
原文链接:
https://eng.uber.com/dynamic-data-race-detection-in-go-code/




