
9 月 21 日,OpenAI宣布,已经训练并开源了一个名为 Whisper 的神经网络,它在英语语音识别方面接近人类水平的鲁棒性和准确性。
Whisper 是一个自动语音识别 (ASR) 系统,它使用从网络上收集的 680,000 小时多语言和多任务监督数据进行训练。使用如此庞大且多样化的数据集可以提高对口音、背景噪音和技术语言的鲁棒性。此外,它还支持多种语言的转录,以及将这些语言翻译成英语。
OpenAI 开源了模型和推理代码,以作为构建有用应用程序和进一步研究稳健语音处理的基础。
查看论文:https://cdn.openai.com/papers/whisper.pdf
开源代码:https://github.com/openai/whisper
查看模型卡:https://github.com/openai/whisper/blob/main/model-card.md
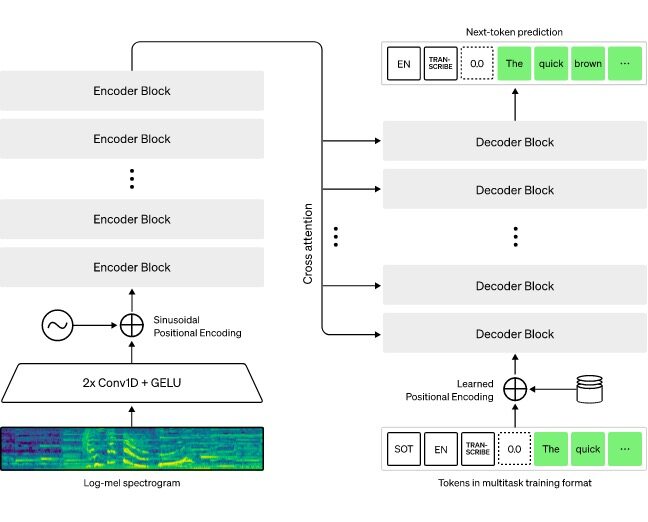
Whisper 架构是一种简单的端到端方法,实现为编码器-解码器 Transformer。输入音频被分成 30 秒的块,转换成 log-Mel 频谱图,然后传递到编码器。解码器被训练来预测相应的文本标题,并与特殊标记混合,这些标记指导单个模型执行诸如语言识别、短语级时间戳、多语言语音转录和英语语音翻译等任务。

其他现有的方法经常使用更小、更紧密配对的音频-文本训练数据集,或使用广泛但无监督的音频预训练。因为 Whisper 是在一个庞大而多样的数据集上训练的,没有针对任何特定数据进行微调,所以它无法击败专门研究 LibriSpeech 性能的模型,这是语音识别领域一个著名的竞争基准。然而,当我们在许多不同的数据集上测量 Whisper 的零样本性能时,我们发现它比那些模型更健壮,并且错误率降低了 50%。
Whisper 的音频数据集中大约有三分之一是非英语的,它被轮流分配任务,将原始语言转录或翻译成英语。并且优于 CoVoST2 到英语翻译零样本的监督 SOTA。

Whisper 的高精度和易用性能够让开发者将语音界面添加到更广泛的应用程序中。




