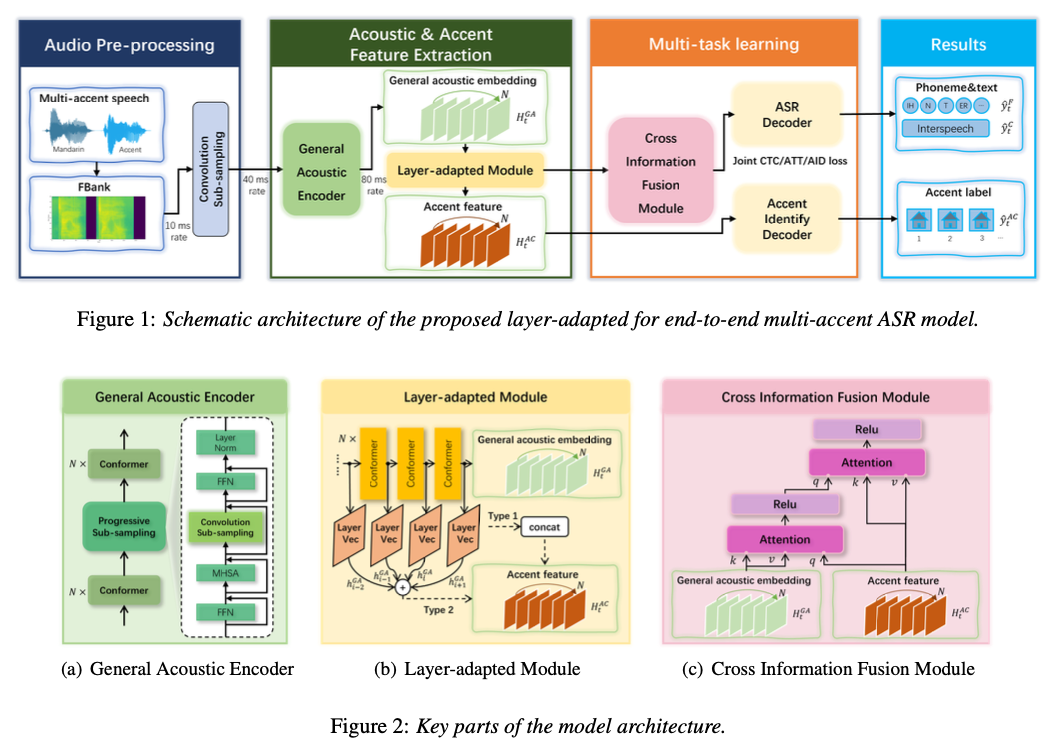
近日,奇富科技智能语音团队论文《Qifusion-Net:基于特征融合的流式/非流式端到端语音识别框架》(Qifusion-Net: Layer-adapted Stream/Non-stream Model for End-to-End Multi-Accent Speech Recognition)被全球语音与声学顶级会议 INTERSPEECH 2024 收录。

我国地域广阔,方言种类繁多,其语法和语音特征存在显著差异。同时,由于噪声的干扰、方言的混杂现象、主观感知在标注过程中的偏差,以及人力标注工作的复杂性和系统性不足,语音识别技术的准确性和智能化水平受到了一定程度的限制。
在金融服务领域,现有的通用语音识别技术在处理方言时往往难以达到理想的效果,不仅影响了人机交互的准确性和智能化水平,也对服务的效率和质量产生了负面影响。
奇富科技引入了全自研 Qifusion 框架模型,并将其集成到智能营销及贷后提醒等业务场景中。在应用上,Qifusion 框架模型能够提升智能营销、贷后提醒、风险控制业务应用场景识别准确率,帮助解决以上问题。并且在复杂的通话环境中,Qifusion 的语音识别准确率达到了 93%以上,意图识别准确率超过 95%。
方言种类丰富:凭借丰富的数据样本,Qifusion 框架模型在原有东北官话、胶辽官话、北京官话、冀鲁官话、中原官话、江淮官话、兰银官话和西南官话等国内八种主流方言的基础上,强化了四川、重庆、山东、河南、贵州、广东、吉林、辽宁、黑龙江等用户密集地区的方言识别能力。
方言识别准确:Qifusion 框架模型具备自动识别不同口音的能力,并能在时间维度上对解码结果进行口音信息修正,使方言口音的语音识别误差率降低了 30%以上,整体语音识别字错率降低了 16%以上,提升了用户体验。
方言识别高效:Qifusion 框架采用了创新的层自适应融合结构,能通过共享信息编码模块,更高效的提取方言信息。同时,该框架模型还支持即说即译功能,能在无需知晓额外方言信息的前提下,对不同方言口音的音频进行实时解码,实现精准的识别和转译。