
从高资源语言进行迁移学习是一种提高低资源语言端到端自动语音识别(automatic speech recognition,ASR)的有效方法。然而,预训练编码器 / 解码器模型并不能共享同一语言的语言模型,这使得它不适用于外来目标语言。为进一步吸收目标语言的知识,并能从目标语言转换,语音到文本翻译(speech-to-text translation,ST)是辅助任务。
该方法通过语音到文本翻译作为中间步骤,改进了针对端到端自动语音识别的跨语言(高资源到低资源)迁移学习。它使学习迁移成为一个两步过程,提高了模型的性能。
目前,该方法是基于注意力的编码器 / 解码器结构。然而,该团队打算将这种迁移学习方法扩展到端到端架构,如 CTC 和 RNN Transducer。
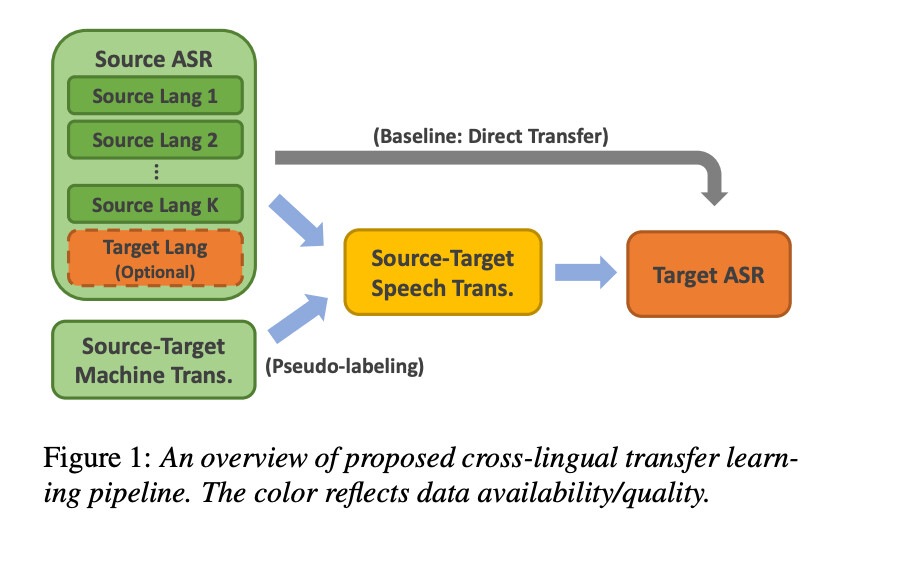
与之前利用转换数据方法不同,这种方法不需要对自动语言识别模型架构进行任何修改。语言到文本翻译和目标自动语言识别都具有相同的基于注意力的编码器 / 解码器架构和词汇表。高资源的自动语音识别转录本被翻译成目标低资源语言来训练语音到文本翻译模型。
这种方法不使用文本到文本的转换数据进行语音到文本翻译训练,而是利用语音到文本翻译的数据,这避免了编码器中的语音到文本的模态自适应。它仅利用了机器翻译伪标签来训练语音到文本翻译,并且不需要高资源的机器翻译训练数据。
这表明,用人工翻译训练语音到文本翻译并不是必要的,因为用机器翻译伪标签训练语音到文本翻译可以带来兼容的结果。这就克服了实际语音到文本翻译数据的不足,并且不断地给迁移学习带来收益。
基于伪标签训练的语音翻译
词级或序列级知识提取(knowledge distillaction,KD)降低了噪声,简化了训练集中的数据分布,有助于训练机器翻译和语音到文本翻译模型。训练端到端的语音到文本翻译模型很有挑战性,因为它们需要同时学习声学建模、语言建模和校准。此外,语音到文本翻译标签的获取成本更高。
现有语音到文本翻译的文本语料库的规模和语言集的局限性,使得训练语音到文本翻译模型变得更困难。因此,团队提出了基于机器翻译伪标签自动语音识别语料库,提供了一个更加多样化、更大规模的数据集来训练语音到文本翻译。用机器翻译伪标签训练的语音到文本翻译模型可以被识别为序列级知识提取过程。虽然伪标签可能会降低模型的效率,但真正的标签很难学习,而伪标签是一个舒适的选择。
实验还表明,使用伪标签训练的语音到文本翻译模型比使用实际标签的模型表现更好。机器翻译伪标签还简化了语音到文本翻译模型训练,并允许束搜索(beam-searching)各种标签以减少过拟合。
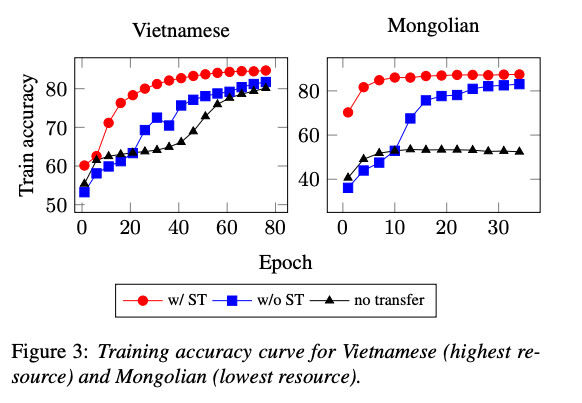
语音翻译的预训练自动语音识别
目标自动语音识别是对源到目标的语音到文本翻译进行预训练,而不是直接在(多语言)源(高资源)自动语音识别上进行预训练目标(低资源)自动语音识别。后者根据源自动语音识别进行预训练,并利用源自动语音识别数据上利用机器翻译伪标签进行训练。
这种分两步进行的方法有助于将语言建模(解码器)和声学建模(编码器)的传递解耦,使得迁移学习变得无故障且更加有效。用自动语音识别对语音到文本翻译进行预训练可以热启动声学建模,
因此,语音到文本翻译训练可以专注于学习语言建模和对齐。语音到文本翻译模型利用目标语言的附加数据(机器学习伪标签),从而更好地对目标语言进行建模。
自动语音识别和语音到文本翻译模型使用相同的模型架构以便于迁移: ASRSource → STSource-Target 1 and STSource-Target → ASRTarget.
论文:https://arxiv.org/abs/2006.05474
作者介绍:
Tanushree Shenwai,是 MarktechPost 的咨询实习生。她目前在 Bhubaneswar 的印度理工学院攻读理工科学士学位。她还是数据科学爱好者,对人工智能在各个领域的应用有浓厚的兴趣,热衷于探索新技术的进步及其在现实生活中的应用。
原文链接:




