本文主要介绍在数据驱动和 AI 时代 Open Data Catalog 的重要性,并介绍小米 AI 数据管理的痛点问题,如何使用 Gravitino 和 Fileset 来管理 AI 数据资产的实践案例。
1 数据驱动时代的 Open Data Catalog
在当今以数据为驱动的商业环境中,数据的价值不仅取决于其规模,更在于其质量和可用性。Open Data Catalog 作为一种新兴的数据管理组件,其核心优势在于提供一个集中的、可搜索的元数据存储,提升数据资产的发现、理解和治理效率。Datastrato 公司开源的新一代的元数据湖 Gravitino(近期已成为 Apache 软件基金会孵化项目), 以及随后 Databricks 和 Snowflake 开源的 Unity Catalog 和 Polaris,不仅为开源社区带来了深远的影响,也标志着数据管理领域的一个新纪元。
2 Open Data Catalog 带来了哪些?
在人工智能时代,数据成为了创新和决策的核心资源。Open Data Catalog 在这一背景下扮演着至关重要的角色,它不仅是数据的管理者,更是 AI 发展的催化剂。
1. 数据治理与数据安全:安全可信数据环境的基石
数据治理和数据安全是构建一个安全可信数据环境的基石。Open Data Catalog 通过精细的元数据管理,使企业能够对数据进行有效分类和标记,从而加强数据隐私的保护和合规性实施。统一的权限管控确保了数据访问的安全性,有效降低了数据泄露的风险。此外,完整的审计功能帮助企业追踪数据访问和使用情况,满足合规性要求,提供数据使用的透明度。
2. 数据的互操作性与数据质量:数据协作的桥梁
Open Data Catalog 的标准化和开放性显著提升了数据的互操作性,使用户能够在标准的存储格式和访问协议下跨不同云服务提供商进行数据操作,从而降低了厂商锁定的风险。Open Data Catalog 可以帮助更好的进行数据探索和血缘追踪,用户可以更快的发现和理解数据资产,了解数据的来源和流动路径。同时围绕 Open Data Catalog 构建的数据质量分析和诊断工具可以帮助企业构建完善的数据质量监控体系以确保数据的准确性、完整性和一致性。这些优势大大促进企业内跨部门和跨组织的数据协作。
3. Data 与 AI 的融合:Open Data Catalog 的新篇章
Open Data Catalog 不仅是数据管理的工具,更是 AI 应用的助推器。它通过提供高质量的数据,支持 AI 算法的训练和优化,实现 Data for AI。同时,AI 技术也被用于改进数据管理过程,比如通过机器学习算法优化数据分类和搜索功能,提高数据治理的智能化水平,从而实现 AI for Data。Open Data Catalog 与 AI 技术的结合,为数据驱动的创新提供了无限可能。
3 小米基于 Apache Gravitino 的 AI 数据管理实践
1. 小米 AI 数据管理的痛点
小米公司作为一家领先的科技公司,其业务运营中积累了大量的非结构化数据。然而,这些数据的复杂性给数据管理带来了一系列挑战:
资产抽象的缺失:小米的非结构化数据主要以文件形式存储在 HDFS 上,这些数据缺乏统一的资源抽象,使得数据的组织和管理变得复杂。由于缺乏有效的资产抽相关,数据的发现和利用变得困难,影响了数据的可访问性。
数据血缘和审计的不足:对于非结构化数据的存取过程缺少对数据血缘的追踪和审计机制。这不仅使得数据的来源、流向和变更历史难以追踪,也增加了数据治理的难度。
生命周期管理能力不足:非表格数据缺乏有效的生命周期管理,文件目录的灵活性导致了目录命名的滥用,文件无法找到有效的时间属性表示进行生命周期管理。此外由于数据血缘的缺失,一数多存,过期未清理的现象非常严重。
安全隐私保护的薄弱:对文件的使用的安全隐私保障措施不足,一方面缺乏有效的权限管控,数据访问权限在多个团队之间共享,数据泄漏的风险很大。另一方面由于缺乏使用方式的收敛,导致数据的访问审计不完整,增大了数据保护的难度。
2. Fileset 的技术原理
为了解决上述问题,小米引入了 Gravitino,并与社区一起跟进了 Fileset 的能力构建。Fileset 提供了一个逻辑文件集的抽象,可以托管实际的物理存储如 HDFS、S3、OSS、JuiceFS 等,并且通过 catalog.schema.fileset 三级结构进行标识。
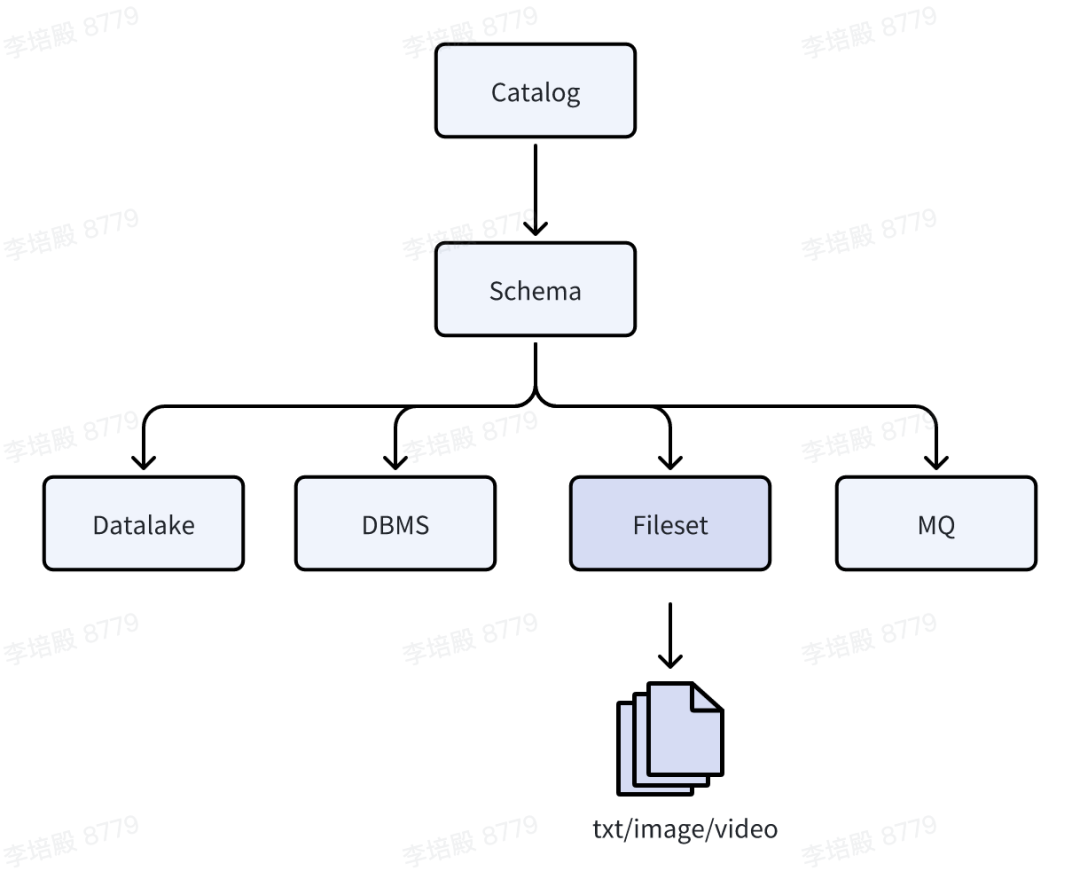
此外,Fileset 提供了在 Java 和 Python 环境下统一的访问协议 gvfs。对于 Java 体系,Fileset 实现了 GravitinoVirtualFileSystem 代理底层真实存储的 Hadoop Filesystem 实现,因此可以无缝对接 Spark、Flink 等常用的大数据计算引擎 。对于 Python 体系则提供了 fsspec 支持以纯 python 的方式进行读写访问。
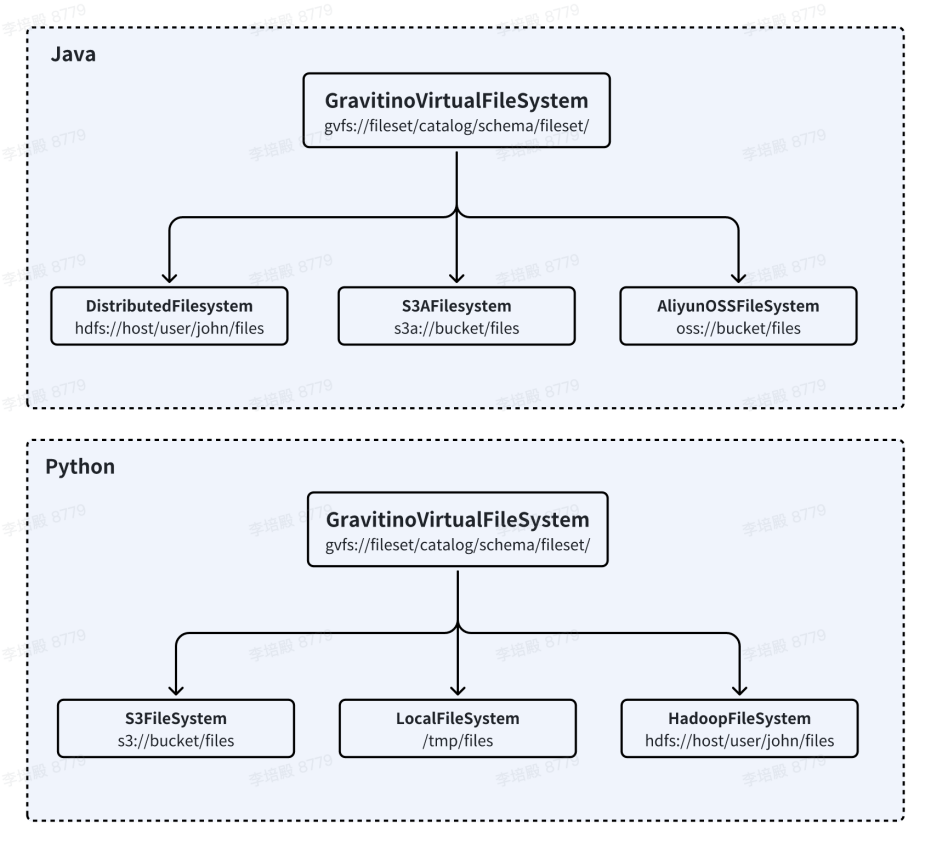
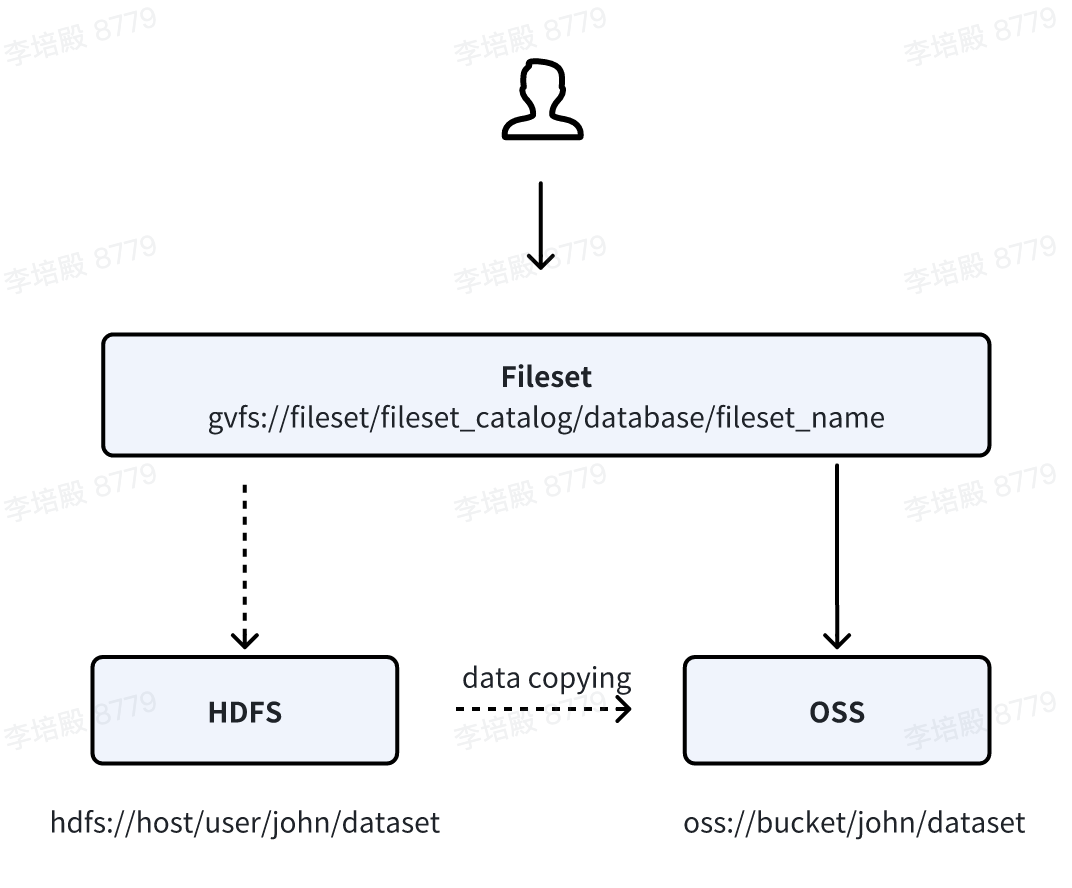
Fileset 统一了文件存储的权限管理和使用方式,极大降低了用户的接入和使用成本。Fileset 的逻辑目录抽象与底层真实物理存储解耦,对用户屏蔽底层的存储细节,这也给文件存储介质的迁移提供了便利性。如下图所示,用户通过修改 Fileset location 可以实现底层存储介质从 HDFS 切换至 OSS,而不需要修改用户代码。
3. 小米的 AI 数据资产治理实践
数据资产
通过 Fileset 小米有效的管理了非结构化数据,包括训练数据、模型数据、数据库备份数据、引擎 checkpoint、作业 Jar 包、配置文件等。Fileset 托管非表格数据加深用户对非表格数据的数据资产理念,使非表格数据可识别、可搜索、可统计、可治理。
审计、数据血缘
我们围绕 Fileset 构建了数据血缘和数据审计。通过血缘地图可以非常清晰的看到数据的来源和流动路径。此外我们根据 Fileset 元数据和 HDFS 文件的审计日志梳理出 Fileset 的审计信息,提高非表格数据的使用透明度。

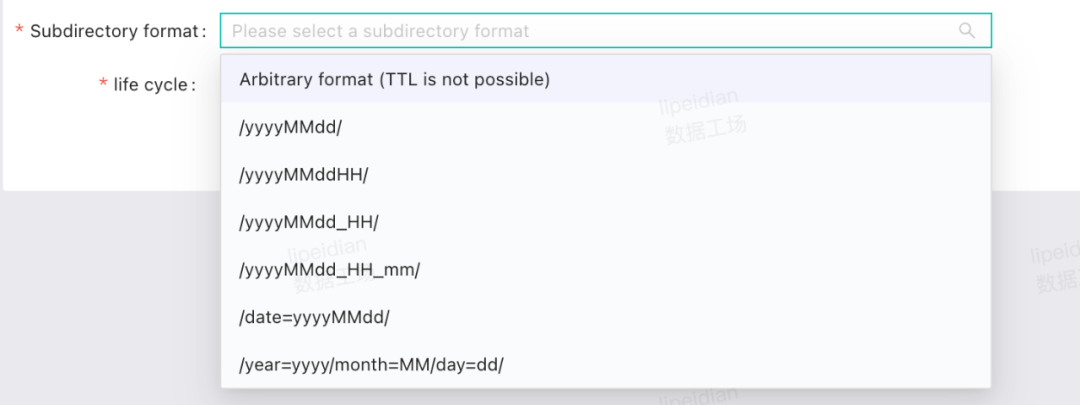
生命周期管理与子目录约束
我们对 Fileset 的子目录进行了约束限制以更好的规范用户的使用和进行生命周期的管理。我们在产品上为用户预设了几种日期格式的子目录规范,用户可以根据自己的需求选择合适的子目录格式并设置生命周期,我们将在后台进行过期数据的清理操作。规范的目录使用不仅帮助我们对 Fileset 进行有效的生命周期管理,更方便对不同目录的分层存储,例如将高频访问数据存放在 HDFS,对于低频访问数据存放在对象标准存储,对于无访问的数据进行归档操作。
权限管控
相比文件在多个用户共用,使用 Fileset 管理文件可以支持更加细粒度的权限控制。在 Fileset 元数据层面,我们使用 Ranger 管理 Fileset 的读写权限信息,对于实际的数据存储 HDFS,则以 Fileset 的粒度对底层的 HDFS location 进行授权和鉴权。
4. 业务使用案例
非表格数据在小米的算法场景有着广泛的使用,但在业务使用过程中有着较多痛点:
数据处理和模型训练由不同的团队完成,以文件路径的方式进行交付,冗长和不规范的路径增加了交付成本和出错概率
文件路径方式缺乏使用规范,使用方式各异,交接和维护十分困难
算法作业和存储介质强耦合,数据迁移成本较高
针对这些痛点,我们基于 Fileset 覆盖了特征处理、模型训练、数据分析等算法训练的全流程,提高数据质量和数据流转效率。
1. Spark 特征处理
用户会使用 Spark 或 PySpark 对原始数据进行清洗、转换和特征提取。小米的一个典型场景是通过 Spark 进行数据处理后产出 tfrecord 数据提供给下游 Tensorflow 进行算法训练使用。代码示例如下。
// read a iceberg tabledf = spark.table("iceberg_catalog.database.table") .select('col1', 'col2') .where('date=20240401')// feature processingassembler = VectorAssembler(inputCols=["feature1", "feature2", ...], outputCol="features")df_features = assembler.transform(df)// use spark to write a tfrecord fileset.val outputPath = "gvfs://fileset/fileset_catalog/database/fileset_name/date=20240204/hour=00"df_features.write() .format("tfrecord") .mode(SaveMode.Overwrite) .save(outputPath)2. Tensorflow 算法训练
在算法训练场景,我们适配了 tensorflow 框架支持原生的 gvfs 协议进行读写访问 Fileset,用户代码只需要修改路径即可实现 Fileset 的访问。
// read a tfrecord in tensorflowdata_dir = "gvfs://fileset/fileset_catalog/database/fileset_name/date=20240204/"filenames = tf.data.Dataset.list_files(data_dir.split(','), shuffle=True)data = filenames.apply( tf.contrib.data.parallel_interleave( lambda filename: tf.data.TFRecordDataset(filename), cycle_length=48, block_length=1024, prefetch_input_elements=1024 * 1, buffer_output_elements=1024 * 1, sloppy=True ))3. 数据分析
在算法开发过程中,经常需要对文件进行预览和简单的查询分析。因此我们支持使用 spark sql 对 parquet、csv 等进行查询分析。
// use spark sql to read a csv file.SELECT _c0 as col0, split(_c1, ',')[0] as col1 FROM csv.`gvfs://fileset/fileset_catalog/database/fileset_name/date=20230130/config.csv` limit 10对于其他类型的文件,我们也支持了 python gvfs 进行交互式查询分析。
import pandas as pdfrom gravitino import gvfs# pandas + pygvfs to write a filedata = pd.DataFrame({'Name':['test']}, 'ID':[20])storage_options = {'server_uri': server_uri, 'metalake_name': metalake_name}data.to_csv('gvfs://fileset/fileset_catalog/database/fileset_name/date=20240310/test/test.csv', storage_options=storage_options)# list a directoryfs = gvfs.GravitinoVirtualFileSystem(server_uri, metalake_name)print(fs.ls('gvfs://fileset/fileset_catalog/database/fileset_name/date=20240310'))# use pygvfs to read a filewith fs.open(path='gvfs://fileset/fileset_catalog/database/fileset_name/date=20240310/test/test.csv', mode='rd') as file: print(file.read().decode('utf-8'))未来规划
未来小米会在以下方向继续推进对 Gravitino 的整合:
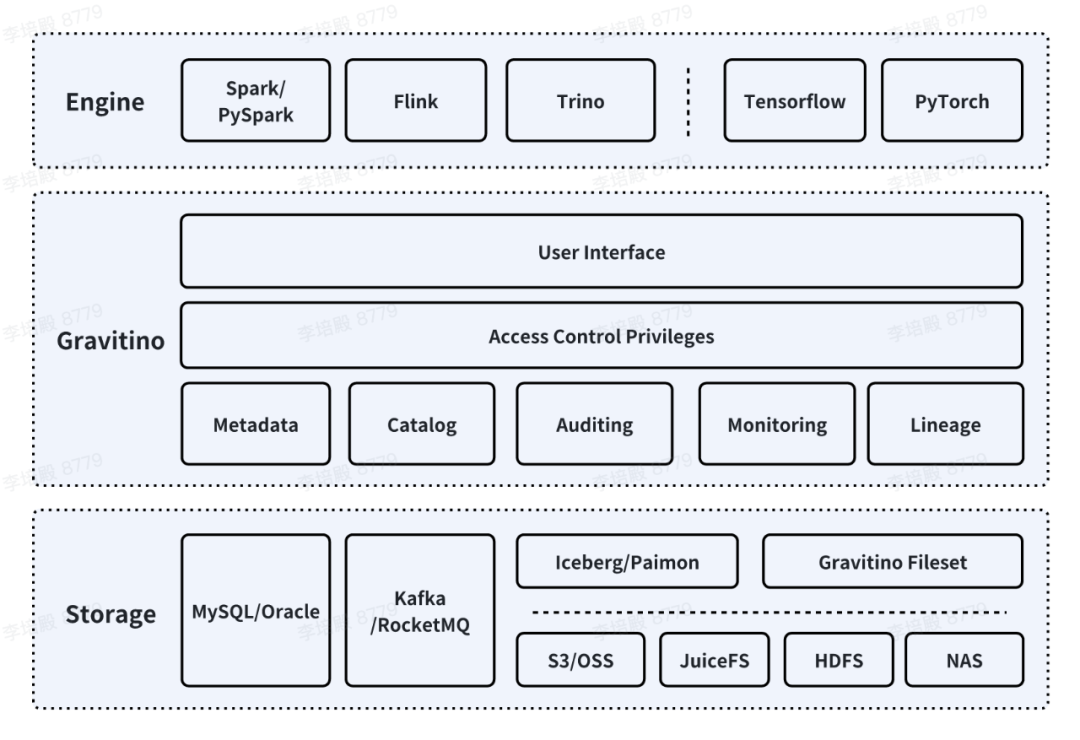
使用 Gravitino 作为元数据中心,管理包括 MySQL、Oracle 等数据库,RockerMQ 等消息队列,Iceberg、Paimon 等数据湖表格。
使用 Gravitino 提供的 Iceberg Rest Catalog Service 替换当前的 Iceberg 使用的 Hive Catalog 。
跟进社区的统一鉴权体系,提供更加便捷的多云存储的接入方案。
在 Data for AI 方面,针对 Fileset 支持多种物理存储介质,支持在用户无感的情况下进行存储介质的无缝切换及数据的搬迁。
4 总结
小米公司通过 Apache Gravitino(incubating) 及 Fileset 有效管理非表格数据,显著提升了数据管理的效率和数据隐私安全性,并降低企业成本,在实际落地中取得了理想的效果。随着开源社区的快速发展和功能的不断完善,Gravitino 有望成为下一代开放数据目录的事实标准,进一步推动数据管理和 AI 领域的融合与发展。
作者简介
李培殿,小米数据湖研发工程师,目前负责数据湖 Iceberg, Paimon 数据湖研发及元数据组件 Gravitino 落地研发相关工作。
今日好文推荐
剥离几百万行代码,复制核心算法去美国?TikTok 最新回应来了
GitHub 删除代码等于“任何人均可永久访问”!微软回应:我们有意为之
中科大保卫处要求硕士以上学历,校方回应:偏技术型;字节跳动“代码抄袭”案在美获受理;私人文档被“投喂”豆包?官方否认 | Q资讯
程序员三个月前就攻破并玩透的 SearchGPT,OpenAI 可算发布了