
背景
日志、指标和调用链是可观测性取得成功的三要素,而这些的实现离不开数据采集,探针采集并上报数据,后端服务接收后对数据进行处理分析,从而达到可观测的目的。通常,服务器性能数据、服务相关数据、服务之间的调用等数据经由探针采集上报,经过 ETL 处理后,成为可观测性分析中的重要依据。
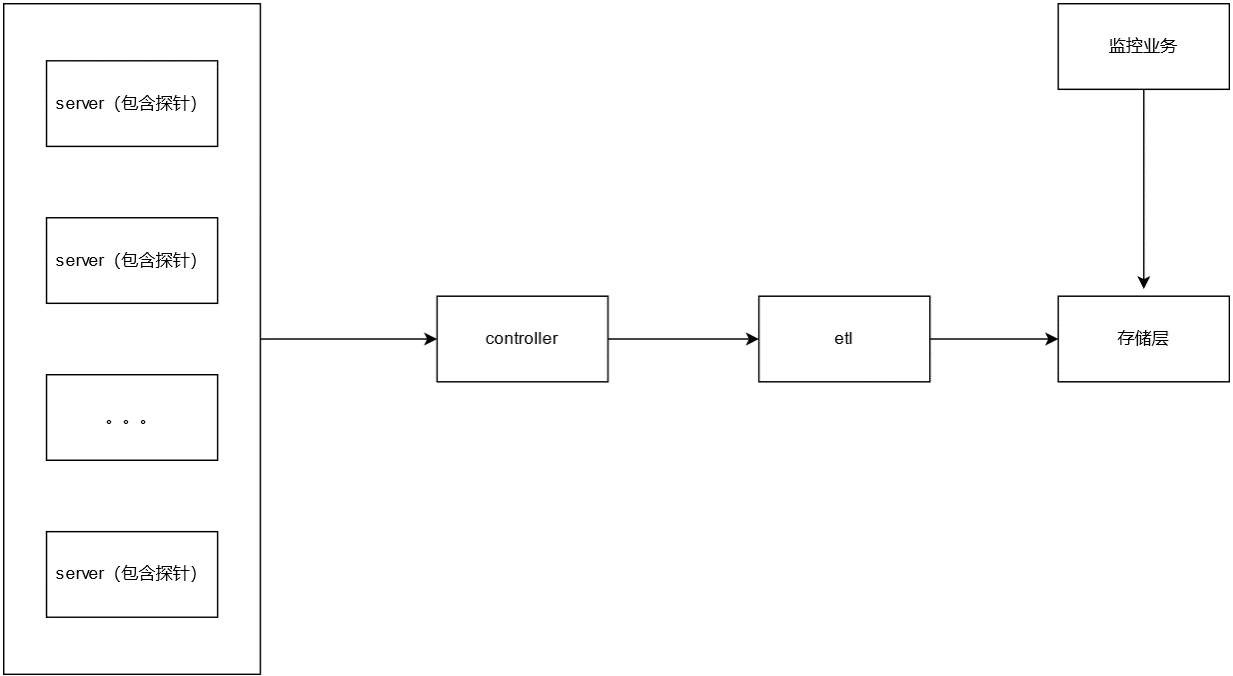
探针采集的数据量大小依赖两个要素:
采样率:采样率越高,数据量越大,对应可观测性分析会更加全面。
业务调用量:当业务服务调用频率越高, 相应的数据量越大,对应可观测性分析会更加复杂。
2000 探针难在哪儿?
由于私有化部署资源有限,需要尽可能多的满足企业监控需求,因此博睿数据的内部测试会以 5 台机器的集群作为部署标准,在资源固定的前提条件下,随着探针量的增多,主要难点如下:
业务场景存在峰值波动,高峰期的服务调用是低峰期的 2 倍+
业务数据是多种业务场景同时存储,常见的涉及调用链数据、指标数据、服务快照数据等
5 台机器是混合部署多种服务,比如数据接入的 controller 服务、报警服务、业务查询服务、数据调用链存储、数据快照存储、数据指标存储、消息中间件等,在更大数据量写入的情况下,针对 CPU、内存、磁盘 IO 的消耗都是抢占式的,影响服务的稳定性。
如何优化瘦身?
针对以上难点,首先想到的就是瘦身,即降低服务组件的数量,减少服务资源抢占的情况。其次是业务存储迁移,弃用高消耗组件,使用低消耗组件满足业务需求。最后在合理的数据存储方案的前提下,优化存储服务本身的性能,满足业务查询稳定性。
降低组件数量
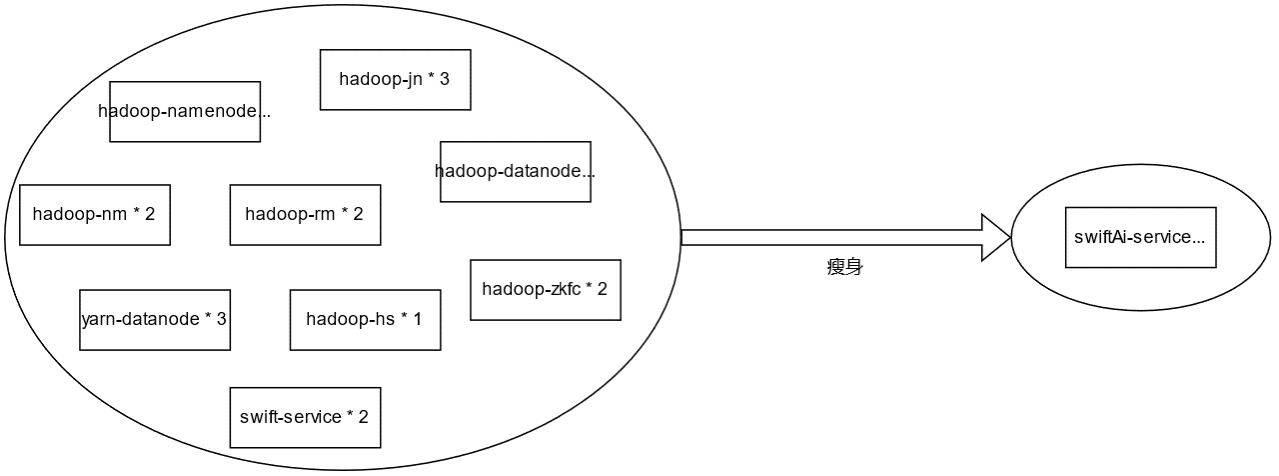
hadoop 存储套装节点数据量比较多,而且是 java 服务,资源消耗较大,内存需求较大。hadoop 的主要业务方是 AI 服务,AI 团队基于自研的数据处理框架,打造了全新一代的 swiftAI 服务,组件种类只有 1 个,部署服务最少只需要 2 个。
业务存储优化
当前 APM 业务的存储分为三大块:指标数据、调用链和快照。目前主要使用三种不同的存储系统分别来支撑,指标数据存储在 clickhouse、调用链使用 ES,快照数据存储在自研的对象存储系统中。在实际的业务场景中,会交叉访问多种存储引擎,在资源估算时,没有一个合理的尺度来衡量资源的上下界。在单台机器上,如果部署多种存储引擎,势必会对服务稳定性产生影响,所以,减少 APM 业务的存储组件,成为一个可行性较高的方案。
探针调用链数据基于 ES 来存储,有以下痛点:
调用链数据与关联的快照数据写入时机存在不一致,基于 ES 的数据写入存在延迟。
ES 消耗资源较大,在 CPU 和 IO 上消耗较多,影响其他服务稳定性。
ES 的查询效率不稳定,随着数据量越来越大,甚至出现无法查询出数据的问题。
探针调用链快照数据基于对象存储系统来存储,有以下痛点:
写入不稳定,存在毛刺。
对 cpu 和 IO 消耗较大,容易触达瓶颈。
针对以上两个组件的明显痛点,迁移数据到 clickhouse 进行存储,获益如下:
调用链数据和关联的快照数据同时写入 clickhouse,保证关联数据的一致性。
clickhouse 写入稳定,即使是针对挽回数据,资源消耗较小。
clickhouse 读取稳定,clickhouse 支持查询熔断、资源限制等手段,提高 clickhouse 查询稳定性。
基于合理的攒批策略,clickhouse 整体资源消耗平稳,毛刺点波动很小。

存储服务优化
相关的业务存储进行了聚焦,那么势必会对 clickhouse 服务产生影响, clickhouse 服务的优化以及运维监控就显得更加重要。
在优化方面,我们从以下三个方向着手:
服务参数调优
max_bytes_before_external_group_by:通过维度聚合查询时,当 RAM 消耗超过这个阈值, GROUP BY 会把多余的临时数据输出到文件系统并在磁盘进行处理计算,通常会建议配置成当前服务内存的 80%。
max_bytes_before_external_sort:涉及数据排序时,当 RAM 消耗超过这个阈值,ORDER BY 会把多余的临时数据输出到文件系统并在磁盘进行排序计算,通常会建议配置成当前服务内存的 80%。
max_memory_usage:用户单条查询可以使用的最大内存,通常会建议配置成当前服务内存的 80%。
max_execution_time:单条查询可以执行的最长时间,这个根据业务响应时间的上限来定。
物化视图、索引、projection 的合理使用
针对不同的场景,使用不同的加速手段,解决查询效率的问题。
高频查询要充分利用主键索引。
主键索引满足不了的高频查询,借助索引来加速。
涉及排序操作,利用 projection 和物化视图来加速,优先使用 projection。
无法使用 projection 的场景,使用物化视图。
监控、容错的支持
为了解决多业务接入带来的复杂影响,需要对集群有充分的监控,且在容错性上需要考虑更多因素。
监控首要跟踪的监控是写入和读取两个方向,比如每分钟写入量,写入耗时、查询 QPS 等,针对特定敏感业务可以个性化跟踪。针对节点本身的状态信息进行监控,比如服务负载、merge 任务数、parts 数量等,这些指标可以及时发现服务的稳定性风险。针对集群的均衡性进行监控,比如 parts 数据同步的延迟时间、各个节点的查询均衡性、各个节点的写入均衡性等,避免集群倾斜。
容错性写入节点单节点异常,不影响整体服务写入。clickhouse 单节点异常,不影响整体集群的写入也不影响读取。
效果
AI 组件瘦身

调用链等相关数据迁移到 CK
总结
为了实现 5 台集群可以支持到 2000 探针,我们首先要做的就是减法,减少组件之间的影响,让单个组件可以发挥更大的效能。再围绕这个组件,构建更全面的生态,包括监控、运维和操作等入口。最后在围绕业务使用场景进行深入优化,保证整体服务稳定性。
后续我们会在 clickhouse 内核上深入发力,不断拓展 clickhouse 的使用场景,与开发者一起分享博睿数据在 clickhouse 方向的探索和实践,助力 Bonree ONE 在更快、更准、更稳定的方向上走得更远。




