
摘要
eBPF 已在云原生生态环境中众多项目和产品中的底层使用,通过实现丰富的云原生上下文,eBPF 使内核具备进入云原生条件。eBPF 所创造的悄无声息的基础设施运动,使其随处可见,且实现了许多先前不可能实现的新用例。
eBPF 已经在互联网规模的生产环境与生产验证中,于全球数百万服务器和设备上全天候运行超过五年。
eBPF 在操作系统层实现了新的抽象,为平台团队提供了云原生网络、安全和可观测性的高级能力,以安全地定制操作系统,满足其工作负载的需求。
扩展操作系统内核是一个艰难而漫长的过程,应用一个变化可能需要数年时间才能完成。但现在随着 eBPF 的应用,这种开发者-消费者的反馈循环几乎是即时可用的,变化可以优雅地推送到生产中,而不必重新启动或改变应用程序或其配置。
未来十年的基础设施软件将由平台工程师来定义,他们可以使用 eBPF 和基于 eBPF 的项目来为更高层次的平台创建合适的抽象概念。以 eBPF 为驱动的 Cilium 等开源项目,在网络、可观测性和安全性上,已经开创并将这种基础设施运动带入到了 Kubernetes 和云原生中。
Kubernetes 和云原生的出现至今已经将近十年了,在这段时间内,我们见证了软件基础设计领域的项目与创新的寒武纪大爆发。在实验与深夜努力中,我们认识到了生产中大规模运行这些系统时,有什么是可行的,又有什么是不可行的。在这些基础项目和关键经验的帮助下,平台团队开始将创新带向了堆栈,但堆栈能跟得上他们的速度吗?
随着应用设计开始向以 API 为驱动的微服务转变,以及基于 Kubernetes 的平台工程、网络、安全的兴起,Kubernetes 对传统网络和安全模式的打破,让团队追赶的步伐变得吃力。上云的转变至少让我们见证了相似技术的海量变化,但 Linux 将“云上”打包,开启世上最为流行的服务,则是完全改写了数据中心基础设施和开发者工作流程的规则。我们如今所处的境况也是类似,云原生领域基础设施的出现如雨后春笋,不是人人都清楚这股潮流前进的方向,看看 CNCF 的情况就知道了;我们的服务通过 Linux 内核上的分布式系统与彼此通信,但其中许多功能和子系统在设计之初就没有考虑到云原生。
基础设施软件的未来十年将由平台工程师来定义,他们将利用这些基础设施构件,正确地为更为高层的平台搭建抽象。建筑工程师利用水电、建筑材料搭建供人类使用的建筑,而平台工程师则利用硬件和软件基础设施,搭建可用开发者安全可靠地部署软件,在大规模下仍能以最小劳动量频繁且可预测地进行高影响力改动的平台。对于云原生年代的下一步发展,平台工程师团队必要能提供、连接且可观察的可扩展、动态、可用且高性能的环境,让开发者能全心全意集中于业务代码逻辑。许多支撑这类工作负载的 Linux 内核构件都已经有十多年的历史了,它们需要新的抽象才能跟得上云原生世界的需求。但好消息是,这些构件已经能满足上诉的诉求,并也已经在最大规模的生产环境中经过了多年的验证。
eBPF 通过允许开发者们以安全、高性能、可扩展的方式动态编程内核,从而创建了云原生抽象和云原生世界所需的新构件。在不修改内核源码或加载内核模块的前提下,eBPF 可安全且高效地扩展云原生和内核的其他功能,将内核本体从单体应用转换至具备丰富云原生环境的多模块化架构,从而解锁了创新。这些能力允许我们安全地抽象 Linux 内核,并以紧密的反馈循环对这一层进行迭代和创新,从而准备好进入云原生的世界。随着 Linux 内核新能力的加入,平台团队已经具备进入云原生世界后的第二步,他们或许也在不知不觉中在项目里采用了 eBPF。这四一场无声的 eBPF 革命,重塑着平台与云原生世界的形象,而在本文中,我们将讲述它的故事。
出于兴趣和利润的数据包过滤扩展
自从1992年的 BSD 数据包过滤(BPF)起,eBPF 这项技术已经有了数十年了历史。在当时,Van Jacobson 试图对网络问题进行诊断,但当年现有的网络过滤都过于缓慢,为此,他的实验室设计并创建了 libpcap、tcpdump。以及 BPF 为所需功能提供后端。BPF 的设计使其能快速、高效,且易于验证地在内核中运行,但其功能仅仅包含对 IP 地址和端口号等简单数据包的头字段进行只读过滤。随着时间的推移和网络技术的发展,“经典”BPF(cBPF)的局限性更为突出,具体来说,它的无状态性导致其在复杂数据包操作上束手束脚,对开发者而言也是难于扩展。
尽管限制重重,这种围绕 cBPF 的高层级概念仍是为将来的创新提供了灵感和平台,即通过一个最小可验证指令集允许内核证明用户所提的应用程序安全性,并能够在内核中运行这些程序。在 2014 年,一项新技术加入 Linux 内核,极大地扩展了 BPF(“eBPF”因此得名)的指令集,为我们带来了一个更为灵活且更为强大的版本。在最初,取代内核中的 cBPF 引擎并不是目标,因为 eBPF 是通用的概念,可被用于网络之外的许多地方。但在当时,将这项新技术融入主流内核的确是一条可行的道路,这也是 Linus Torvalds 这段话的背景:
和疯子们一起工作对我来说不是问题,他们只需要用不那么疯狂的论点短小精悍地向我推销他们的疯狂想法。在我问他们要杀手级功能时,我希望他们能说服我这些推销的东西首先要对主流来说的确有用。换句话说,任何疯狂的新功能都应该被牢牢包裹在一个“特洛伊木马”中,第一眼看上去至少要明显觉得不错。
简单来说,这段话是对 Linux 内核开发模式中“根本”机制的描述,与 eBPF 融入 Linux 的方式不谋而合。为实现增量形式的优化,第一步自然是取代内核中 cBPF 的基础设施以提高其 i 性能,随后再一步步地在其基础上暴露并改进全新的 eBPF 技术。自此之后,早期的 eBPF 发展有了两条并行前进的路线,即网络与跟踪。以 eBPF 为中心的每一个被合并至内核的新功能都解决了这类用例下的切实生产需求,这一需求至今仍然适用。而 bcc、bpftrace,、Cilium 等项目则是早在 eBPF 生态系统搭建成功并成为主流之前,变开始协助塑造了 eBPF 基础设施的核心构件。如今的 eBPF 是一项通用技术,可在内核等特权环境中运行沙盒程序,这与“BSD”、“数据包”,或“过滤器”已经没有什么共同点了,如今的 eBPF 只是个缩写的,代指操作系统内核根据用户需求安全地扩展和定制的技术革命。
具备运行复杂但安全程序能力的 eBPF 已经是一个极为强大的平台,可用堆栈更为高层的云原生环境丰富 Linux 内核,从而执行更优的策略决策、更有效地处理数据、让操作与其源头更为接近,也更为迅速地进行迭代和创新。简言之,我们将不再是修补、重构,或是推出新内核变动,而是削减基础设施工程师们的反馈循环,让 eBPF 程序可以在无需重启服务或中断数据处理的情况下进行即时更新。eBPF 的多功能性也使其在网络之外的其他领域也有应用,在安全、可观察性、跟踪等方面,eBPF 可被用于实时监测并分析系统事件。
加速中的内核实验与进化
从 cBPF 向 eBPF 不仅改变了我们的现状,也影响了我们即将构建的。从简单的数据包过滤发展到通用沙盒运行时,eBPF 在网络、可观察性、安全性、跟踪和剖析方面开创了许多新用例。作为 Linux 内核中的通过计算引擎,eBPF 允许我们对内核中发生的任何事情挂钩、观察,并采取行动,与网页浏览器中的插件很是类似。其中的一些关键功能设计允许了 eBPF 对创新能力的加速,从而为云原生世界创建性能更强的可定制系统。
首先,eBPF 能够挂钩在内核中任何地方,并修改功能和自定义行为的是不需要对内核源码修改的,这意味着从用户提出需求到具体实施的时间将从以年为单位缩减为几天。由于 Linux 内核被数十亿的设备所广泛采用,导致上游的改动并不轻松。举例来说,假设我们想要一个观察应用的新方式,并能够从内核中提取指标,那么我们首先要做的是说服整个内核社群这个主意不错,并且是对所有运行 Linux 的人而言都不错,然后才能开始实施,并最终在几年后才能真正用得上这个功能。但随着 eBPF 的出现,我们能直接不重启机器就把这个观察功能写成代码,并在不影响其他人的前提下根据自身特定的工作负载需求对内核定制化。“eBPF 非常有用,其真正强大的点在于它能让人们自行定制化代码,除非特地要求否则这些代码是不会被启用的,”Linus Torvalds 说。
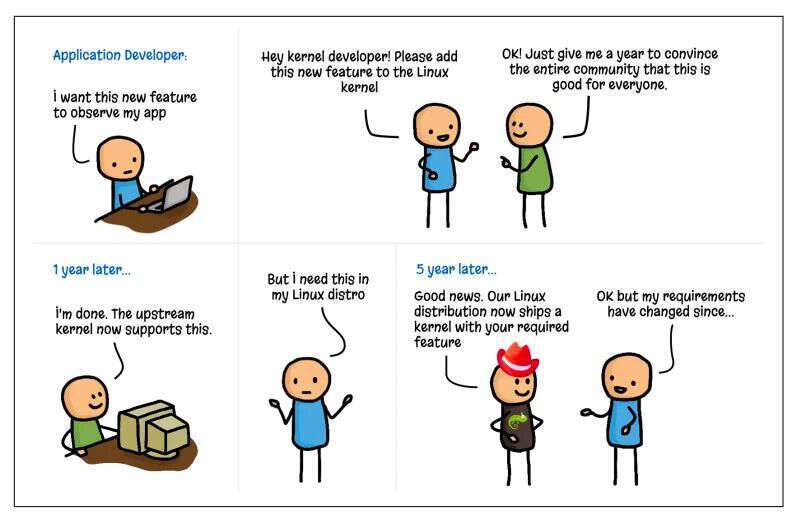
图配文:
应用程序开发者:我想要这个功能观察我的应用
—— 哈喽,内核开发者!请把这个新功能加到 Linux 内核中!—— 好啊,给我一年时间让我说服整个社群这是个对所有人都好的功能
一年后…… 完事了,主流内核已经可以支持了
但我想把这个加到我的 Linux 版本里……
五年后…… —— 好消息,我们的 Linux 版本已经可以提供带有你需要功能的内核了—— 但我的需求已经变了啊……

图配文:
应用开发者:我想要这个新功能观察我的应用
eBPF 开发者:行!内核现在没有这个功能,让我拿 eBPF 快速搞定
几天后……
这个是我们包含这个功能的 eBPF 项目版本,顺带一提,你还不用重启机器
其次,由于对程序执行的安全性验证,eBPF 的开发者们可以在无需担忧内核崩溃或其他不稳定因素而继续进行创新。开发者和最终用户都能更自信地说自己送上生产的代码是稳定且可用的。对平台团队和 SRE 而言,使用 eBPF 也是安全地在生产环境中排障的关键因素。
在应用程序准备投产时,eBPF 程序无需中断工作负载或重启节点便可添加至运行时,从而极大地减轻了平台更新维护所需的工作量,也减少了因版本更新出错导致工作负载中断的风险,这对大规模项目而言是个极大的好处。JIT 编译让 eBPF 程序具备了接近本地的执行速度,将上下文从用户空间转移到内核空间则允许用户跳过不需要或未使用的内核部分,进而提升其性能。然而,与用户空间中的完全跳过内核不同,eBPF 仍可利用全部的内核基础设施和构件而不用重新发明轮子。eBPF 可以挑选内核中的最优部分,结合自定义业务逻辑,从而解决特定问题。最后,运行时可修改内核行为以及跳过部分堆栈的能力,为开发者创建了一个极短的反馈循环,进而允许在网络堵塞控制和内核中进程调度等方面进行试验。
eBPF 从经典的数据包过滤中成长,并在传统用例中进行的的大飞跃,解锁了内核中资源使用优化、添加自定义业务逻辑等许多新的可能性。eBPF 让我们可加速内核创新、创建新抽象、大幅提升性能,不仅缩短了在生产负载中新增功能的时间、风险、开销,甚至在某些情况下让不可能成为可能。
数据包与日常:eBPF 在谷歌、Meta 和 Netflix 的应用
在见识到 eBPF 如此之多的优点后,人们不禁要问了,eBPF 是否能在现实世界中实现?答案是肯定的。Meta 和谷歌坐拥部分世界上最大的数据中心、Netflix 占据互联网流量中的 15%,这些公司都已在生产中使用 eBPF 多年,其结果不言而喻。
Meta 是第一家将 eBPF 及其负载均衡项目 Katran 大规模投产的公司。自 2017 年起,所有进入 Meta 数据中心的包都是通过 eBPF 处理的,那可是不少猫猫图片呢。Meta 也将 eBPF 用于许多更高级的用例,如最近的调度器效率优化,可将吞吐量提升15%,对该公司的规模而言这是个极大的提升和资源节约。谷歌也利用 eBPF 的运行时安全性和可观测性处理其多数的数据中心流量,谷歌云的用户也是默认使用基于 eBPF 的数据平面进行联网。安卓操作系统支持了 70%的移动设备,拥有遍布 190 多国家的 25 亿活跃用户,其中几乎所有的网络数据包都接触过 eBPF。Netflix 在很大程度上依赖于 eBPF 对其机群进行性能监控和分析,而 Netflix 的工程师也创造了 bpftrace 等 eBPF 工具,绘制基于 eBPF 收集器的 On-CPU 和 Off-CPU 火焰图,为生产服务器排障的可见性方面带来了重大飞跃,
eBPF 的有效性的显而易见的,在过去的十年中一直为“互联网规模”的公司带来大量收益,这些收益也应该转换为其他人所用。
eBPF 的演变:让云原生速度和规模成为可能
在云原生时代初期,GIFEE(谷歌为其他所有人提供的基础设施)是个流行词,但因为不是所有人都在用谷歌或谷歌的基础设施,这个词已经不再热门。人们希望能用简单的解决方案解决问题,这也是 eBPF 脱颖而出的原因。云原生环境是为“在现代且动态的环境中运行可扩展应用程序”,其中可扩展和动态是 eBPF 成为云原生革命所需的内核演变关键。
Linux 内核一如既往地是云原生平台构建的基础,应用现在只需使用套接字作为数据源和接收器,网络作为通信总线。但云原生所需的是目前 Linux 内核中所无法提供的新抽象,cgroups(CPU、内存处理)、命名空间(net、mount、pid)、SELinux、seccomp、netfiler、netlink、AppArmor、auditd、perf 等等这些构件远比云原生这个名字的出现早诞生了数十年,这些构件不总是在一起使用,有些也不甚灵活,缺乏对 Pod 或任何更高级别服务抽象的认知,且完全依赖 iptables 联网。
对于平台团队而言,为云原生环境提供的开发者工具,很可能还被囿于这个云原生环境无法被有效表达的盒子里。在未来,没有合适的工具平台团队也将无从下手。eBPF 则是允许工具从无到有地重建 Linux 内核中的抽象概念,而这些新抽象则会解锁下一次云原生创新的潮流,为云原生的革命奠定方向。
举例来说,传统的网络下,数据包是由内核处理的,经过数层网络堆栈对所有数据包的检查后方能到达目的地。这一过程无疑会带来极高的开销和处理时长,对含有大量数据包的大规模云环境而言则更是如此。与之相反,eBPF 允许在内核中插入自定义代码,并在每个数据包经过网络堆栈时执行,带来了更为有效且更具针对性的网络流量处理,减少开销并提升性能。Cilium 的基准测试表明,从 iptables 切换至 eBPF 提升了六倍吞吐量,从基于 IPVS 的负载均衡器切换至以 eBPF 为驱动,不仅使 Seznam.cz 的吞吐量增加了一倍,CPU 使用率也减少 72 倍。eBPF 不是在旧的抽象概念上缝缝补补,而是实现了巨大优化改进。
与其前身不同,eBPF 的优化没有仅仅停留在网络层面。作为通用计算环境且可挂载到内核的任何位置,eBPF 的优化也扩展到了可观测性、安全等更多领域。“我认为云原生中安全性的未来将会是基于 eBPF 技术的,这是一种全新且强大的获取内核可见性的方式,过去想做到这一点是很难的,”云原生计算基金会的 CTO Chris Aniszczyk 说过,“在应用和基础设施监控的交界处,(eBPF)可以为团队提供一个检测、缓解和问题解决的,更为全面的方式。”
eBPF 以云原生的速度和规模,让人们可以连接、观察并保护应用程序。“随着应用程序逐渐向着以云原生模式为驱动的基于 API 的服务集合,所有应用的安全性、可靠性、可观测性、性能都将从根本上依赖于以 eBPF 为驱动的全新连接层”,Isovalent 的联合创始人 Dan Wendlandt 说,“它将成为新云原生基础设施堆栈中的一个关键层。”
eBPF 的革命正在改变云原生,而其中最好的部分已经得到了实现。
无声的 eBPF 革命已经成为平台的一部分了
虽然 eBPF 的好处显而易见,但这种过于底层的形式意味着缺乏 Linux 内核开发经验的平台团队还需要一个更为友好的接口。这也是 eBPF 的魔力所在,eBPF 如今已经在多个运行云原生平台的工具中存在,或许你已经在不知不觉中用过它了。通过任何主流云供应商的 Kubernetes 集群启动,都是通过 Cilium 用到了 eBPF;通过 Pixie 的观测性实施或 Parca 的连续分析,也都用到了 eBPF。
eBPF 这股强有力的浪潮正在改变软件行业。Marc Andreessen 那句著名的“软件正在吞噬世界”已经被 Cloudflare 玩笑似地改成了“eBPF 正在吞噬世界”。然而,eBPF 的成功不在于让所有开发者得知其存在,而是在当开发者们对更快的网络、毫不费力的监控及可观测性,以及更易使用且安全的解决方案之中。曾用过 eBPF 编程的开发者可能不足 1%,但却能让其他 99%的人受益。在各类项目和产品通过 Linux 内核上游代码或 Linux 内核模块编写,从而为开发者们提供大幅度的体验优化时,eBPF 将完全占领世界。我们已经踏上了这条通往现实的大路。
eBPF 彻底改变了现在与将来基础设施平台的构建方式,实现了许多全新的云原生用例,这些用例在过去很难或根本不可能实现。平台工程师能在 eBPF 的帮助下安全且高效地扩展 Linux 内核能力,让快速创新成为可能。为适应云原生世界的需求,新的抽象和构件得以创建,开发人员也能更轻松地大规模部署软件。
eBPF 的大规模投产已有半个世纪之久,也已被证明是一种安全、高性能、可扩展的动态内核编程方式。悄无声息的 eBPF 革命已经扎根,并在云原生生态系统及其他领域的产品和项目中得到应用。随着 eBPF 的出现,平台团队已做好进入云原生时代下一阶段的准备,他们可以配置、连接、观察并保护可扩展的、动态可用高性能环境,从而使开发人员将精力集中于业务逻辑的编程。
查看英文原文:The Silent Platform Revolution: How eBPF Is Fundamentally Transforming Cloud-Native Platforms
延伸阅读:




