
本文是数据库内核系列文章之一。
从本文开始,我们一起来学习一下数据库引擎执行器中非常出名的两种优化方式,code generation(代码生成;以下简称 code-gen)和 vectorized execution(向量计算;以下简称 vec-exec)。为什么说学习呢,因为自己确实也没做过。所有的学习资料也是阅读一些技术博客和技术论文,我会仔细阅读,争取可以用深入浅出的语言写出来。
说到 code-gen 和 vec-exec,这两个概念出自两篇非常有名的文章。code-gen 出自 Thomas Neumann 的文章:Efficiently Compiling Efficient Query Plans for Modern Hardware;vec-exec 出自 MonetDB/X00: Hyper-Pipelining Query Execution。MonetDB 的作者之一是 Marcin Zukowski。他的博士毕业论文就是详细阐述了 vec-exec(目前暂定计划是,仔细阅读一下他的博士毕业论文,然后输出一到两期)。他也是目前超级火热的 Snowflake 数据库公司的创始人之一,Snowflake 的执行器就是基于 vec-exec 的。讲到这,我得说一个没吃到葡萄,觉得葡萄特别酸的故事:早先在数据库会议上见过 Marcin 几次,是个非常 nice 的人。当时 Snowflake 也刚开始做没多久吧。Marcin 说,他想招做 optimizer 的。我说,我就是啊。Marcin 说,我想招个女性。。。我说,为啥。。。因为 diversity?他说,不是,因为现在 optimizer 组全是女性,他希望能保持 optimizer 组全女性阵容(强迫症晚期患者)。然后我还去问了 Lyublena,但是 Lyublena 当时也刚加入 Datometry,没有去。我,因为性别,错过了一次财务自由的机会。
后来,Andy Pavlo(CMU 数据库教授)把 Thomas 和 Peter(MonetDB 另一位作者)组在一起,写了一篇 survey paper: everything you always wanted to know about compiled and vectorized queries but were afraid to ask(不得不说,Andy 的所有论文,名字起的都特别网红)。今天的内容,咱们从读懂这篇 survey paper 开始。
绝大部分的现代数据库的执行器引擎都是基于 code-gen 或者 vec-exec 的。 有意思的是,它们都为了提升性能而生,但是却走了不同的两条路。目前,两种技术都被成熟应用到数据库系统中。但是,至今为止,也没能很客观地去比较这两种技术的好坏。因为,对于一个数据库系统而言,一般只会选择点选一个技能树,然后,就沿着这条技能树发展,所有的发展都是围绕这个技术的。如果比较不同的数据库,由于不可控的因素太多了,很难可观地比较这两种技术。这也是 Andy 他们写这篇文章的初衷:为了可以公正地比较这两种技术,专门在自己开源的数据库上实现了两种技术,而且,尽量做到客观,公正,使用相同的算法和类型模型。
在杂谈第四章,介绍执行模式的时候,我们介绍过传统的执行器执行模式,Volcano-style 模型(火山模型)。Volcano-style 的优点在于,非常的 general,容易扩展和理解,实现也相对容易。并且,当还处于读写磁盘是主要性能瓶颈的年代,并没有察觉,这个模型会对性能造成太多损失。但现在不同了,所有硬件的性能都提升了不止几个数量级。数据库也在为了追求极致性能不断优化。 普通硬盘慢,那就用 SSD,再不行,就纯 in-memory 数据库。行存(row-store)对于读海量数据的 OLAP 语句来说没有优势,那就改为列存(column-store)。在执行器这方面,就衍生出了两种技术,code-gen 和 vec-exec。主流的数据库几乎都使用了其中一种来作为执行器。用 vec-exec 的有,DB2-BLU,Columnar SQL Server, 以及 QuickStep 等等. 而 code-gen 则有 Apache Spark 以及 Peloton 等等,包括 Pivotal 的 GPDB 也有 code-gen 模式。
下面,先简单介绍下这两项技术。
Vec-exec
Vec-exec,类似于 Volcano-style,也是基于拉模式的方式来处理。区别在于,next 方法不再只返回一个 tuple,而是一个 batch 的 tuples。因此在处理的时候,可以批量一起处理一波 tuples。读者可能会有疑问,诚然,每一次拉取了一波 tuples 一起处理,确实是节省了总共调用 next 的次数。但是说到底,总共要处理的 tuple 是没有变化的。为什么 vec-exec 能带来可观的性能提升呢?其实是基于硬件的提升:SIMD: single instruction multi-data。即,单个指令直接作用到多个数据,比如,可以同时计算多个 vector 里数据的 hash 值。因此,vec-exec 更适合配合 column-store。
Code-gen
而 code-gen,虽然也是利用硬件带来的性能提升。相比 vec-exec,使用了完全不同的模式。虽然还是有 operator,但 operator 不再是相互独立地处理数据,而是把所有的 operator 当成一个整体,然后生成出一段代码来实现整个逻辑:为每个 query 都会单独去生成一段代码来实现。可能读者会有相同的疑问,性能提升是从何说起。举个例子,大家都听说过 Google 大神 Jeff Dean 的故事。传言 compiler 从来不给他优化提示,因为他手写的代码比 compiler 更优化。你大致可以想象,code-gen 呢就是,对于每个语句,都找一个 Jeff Dean 一样的高手,根据数据的类型,数据的大小,然后结合硬件 CPU,寄存器,内存等的信息,手写一段代码来实现这个语句。不需要兼顾 general 属性,因此可以更高效。而传统的 volcano-style,因为兼顾 general,因此代码本身是并不优化的。而且,code-gen 生成的代码可以进一步通过编译优化生成性能更高的机器代码(比如,通过 LLVM)。
稍微展开一点,怎么才可以生成出性能更高的机器代码呢?一个衡量的标准就是运行这个语句,总共的 CPU 指令更少。如何才能生成 CPU 指令更少的机器代码呢。我也不是专家,阅读文章后,这是我自己的理解。CPU 运行的时候,需要通过和寄存器交互来处理数据,而把数据从内存换到寄存器中是需要消耗 CPU 指令的。那一个简单的思想就是,如果生成的代码,可以尽可能地提高寄存器的利用率,即,使得连续的 CPU 指令都能 hit 寄存器中的数据,而不是消耗在不停地交换内存数据中,这样的代码就更高效。
什么传统的 volcano-style 对 CPU 或者寄存器不是很友好。原因之一就在于设计模式非常 general(好处在于比较容易实现)但劣势在于,为了追求通用性,会增加额外方法调用的开销,并且大大增加了寄存器 miss 的可能性。为什么这么说呢。来看一个示例。假设处理下列的语句
SELECT COL1 + 10 as NEW_COL1, COL2, COL3, COL4, ...., COL20 FROM TABLE1WHERE COL1 > 10;
因为 tuple 是一条一条处理的,因此,第一个 filter operator 会不停地从 TableScan 读取数据,然后判断是否 COL1>10。判断完了后,上层的 projection operator 会得到这个 tuple,然后处理 COL1+10。但是,这边多了一次方法调用,是有开销的。并且,假设 tuple 过长,极有可能数据就被从寄存器换出,执行加法操作还要再多一条指令将 COL1 读进寄存器。

那 code-gen 可以怎么做呢?对于每一个 COL1,可以把 COL1+10 的这个操作合并到 filter operator 一起,这样,就可以保证寄存器 hit,而且,生成的 code 可以直接是一个大 for 循环,完全去掉不必要的方法调用。
论文种给出的 HashJoin 示例比较
文中给出 HashJoin 的 code-gen 和 vec-exec 的代码比较。
可以看到,code-gen 的做法就是先读取用来构建 hash 表一侧的所有数据,构建 hash 表。然后读取右侧 table 来判断 hash 条件是否某满足。从这个实现上看,也没有特别神奇的地方。但总结来说,去掉了一个一个 tuple 处理的模式,对 cache hit 更有利;并且,去掉了 next 方法调用的额外开销。而且,对于这类 for 循环,通常编译器还能更好地做优化来生成机器代码。
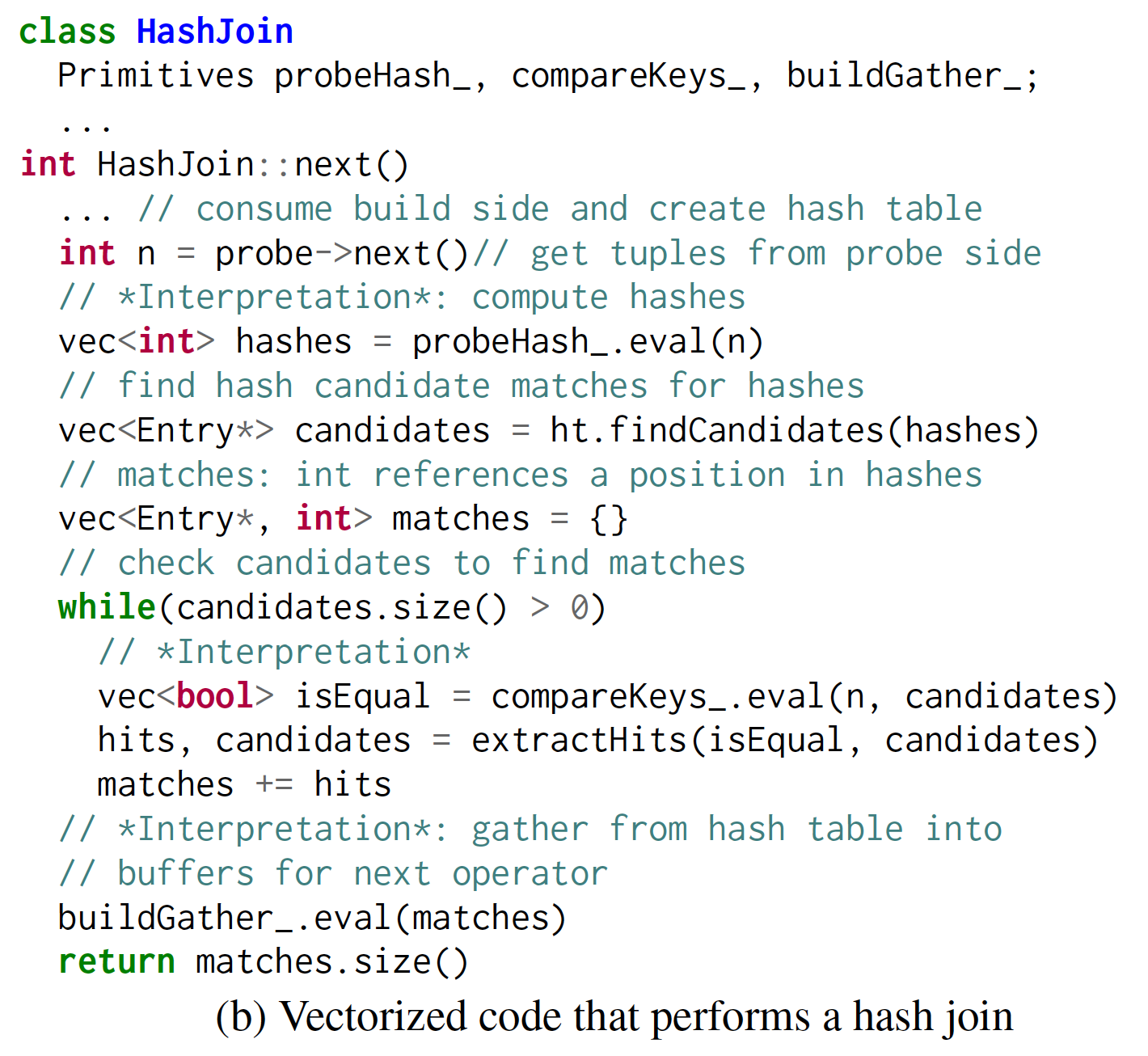
上图种 vec-exec 所用的代码,在构建 hash 表时,代码类似,因此省略了。在 hash probe 时,和单个 tuple 比,每次读取一个 batch 的 tuples,来处理,也没有特别多神奇的地方。
比较结果总结
文中用了大段来陈述比较结果,并且从多个维度进行了比较。例如,分别考虑了单线程模型,多线程模型的实现;不同的硬件场景;是否使用 SIMD。比较的维度也有 CPU cycles,指令数,L1 Cache miss, LLC (Last-level cache) miss, branch miss 等等。我在这就不一一复述了,相信大家也不是特别感兴趣。
翻译一下最后的总结:
1)code-gen 对于计算复杂性更高的语句来说,更有优势,因为可以通过代码优化来提高寄存器利用率,从而需要更少的指令来执行整个计划。
2)对于并行处理数据 SIMD 来说, vec-exec 更适合。
3)对于多 CPU 环境,两项技术都可以 scale。
4)对于不同硬件环境,两项技术也是伯仲之间。
用一句话而言,两项技术都可以提升性能,侧重点不同,语句的不同,带来的性能提升也不同。
说一下我自己肤浅的理解。首先,code-Gen 的实现更复杂。特别是要实现高质量的代码,毕竟,你不会真有一个 Jeff Dean 在后台给你写代码,相当于实现了一个 compiler。另外要提的是,Code-gen 的本身从 query 到 generated code 是需要花时间的。这个时间,通常和 Query Optimization 的时间合并在一起了,但肯定是比普通的优化时间更长的。 此外,还要把这个生成的 code 再翻译成机器代码。文中提到了用 LLVM:LLVM 会进一步对代码优化,生成机器码,时间复杂度基本和代码量成线性。
我个人觉得,code-gen 应该会比 vectorized execution 性能更高一些,如果实现的好的话。其实大家可以想一下,code-gen 完全可以生成类似 vec-exec 的代码,如果在某些场景下,后者性能更高的话。
2021 年的愿景之一是做更多对于技术和管理的输出,如果想要和我更多交流,欢迎关注我的知识星球:Dr.ZZZ 聊技术和管理。




