
9 月 7 日,Modular 公司宣布正式发布 Mojo:Mojo 现在已经开放本地下载——初步登陆 Linux 系统,并将很快提供 Mac 与 Windows 版本。据介绍,Mojo 最初的目标是比 Python 快 35000 倍,近日该团队表示,Mojo 将动态与静态语言的优点结合起来,一举将性能提升达 Python 的 68000 倍。那么未来的人工智能的语言,是 Rust 还是 Mojo ?张汉东从 Rust 和 Mojo 语言的特性、生态和其在 LLM 大模型时代的角色进行了剖析。
编程语言是推动时代齿轮的抓手
我从 2006 年入软件行业,截止今年我的职业生涯已经走过十七个年头。
这十七年我虽然没有什么光彩履历,但却很幸运,我还能在这个行业坚守,并能不断成长。同样很幸运,我经历了桌面软件没落, Web 2.0 崛起,以及移动互联网的兴盛,当下基础设施系统软件开始复兴的诸多历程。
这么多年我思考最多的两个问题就是:
编程语言对于程序员来说到底意味着什么?
我们为什么要不断地学习新的编程语言?能不能学一门就行?
这两个问题的答案,取决于你如何看待编程语言。
在社区经常会听到一句话:“编程语言就是工具”。编程语言确实是工具,用于谋生的工具,用于编写软件的工具。在我看来,编程语言不仅仅是工具,更是思想的集合时代的缩影。编程语言的发展跟随计算机的发展一路走来,其中蕴含着推动时代变革的解决不同问题的思想。
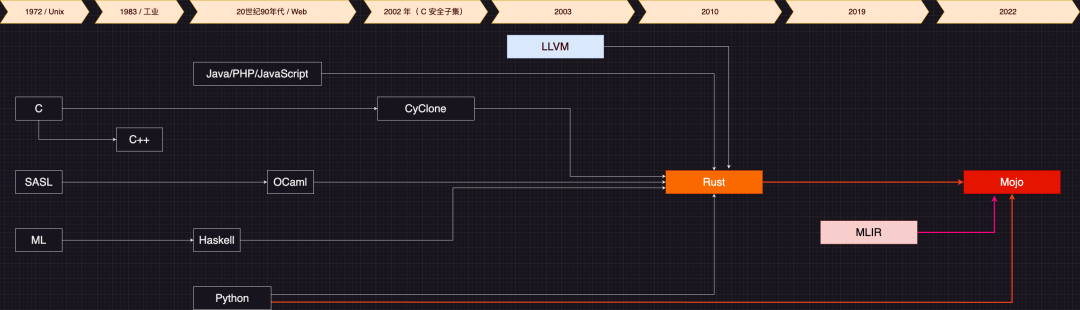
编程语言背后都有共同的东西,比如计算机基础和其他领域知识。这些是可以在不同语言之间迁移的知识,只需要学一遍。但是编程语言的设计思想却是不同的,这就是编程语言吸引人的地方之一。就像同样都叫威士忌,可能会有不同的味道。
编程语言如何设计,一般都和它想要解决的问题有关。而它想解决的问题,通常都与语言创造者所处的时代和眼界有关。
C 语言的诞生,是为了解决操作系统快速交付的难题,背后是 70 年代操作系统的发展;Cpp 语言的诞生,是为了给 C 语言引入面向对象,提升开发效率,背后是 80 年代工业软件快速增长需求;Python / Java 语言的诞生,是为了让开发者专注于业务而非语言细节,背后是 90 年代日益增长的 Web 开发需求。
随着互联网的高速发展,2010 年编程语言领域迎来一个拐点,Rust 语言之父 Graydon 认为未来互联网应该是安全和性能并重,所以他集过去四十年众语言优势为一体,创造了 Rust 语言。到了 2022 年, Mojo 语言作者 Chris 认为 AI 基础设施生态的碎片化已经阻碍了 AI 的发展,所以他创造 Mojo 语言,想一统 AI 生态,解决碎片化问题,实现 All in One 理想。
回顾历史,我们看得出来。时代在不断变化,编程语言是推动时代齿轮的抓手。当新的时代到来时,有些语言是必须要学习的。让我们从 Rust 和 Mojo 语言的特性、生态和其在 LLM 大模型时代的角色来探索这两门语言的未来。
Rust vs Mojo :雄心与现状
Rust 语言
Rust[1] 语言之父 Graydon 带着内存安全和性能并重的设计初衷于 2009 年创立了 Rust 语言,幸运的是,这颗种子是种在了 Mozilla 这片开放的土壤中,在 2015 年结出了开放的花朵。
Rust 语言并不是要百分百地解决内存安全问题,而是消除过去五十年导致系统编程语言中 70% 安全 Bug 中的内存安全问题:
引用空指针。
使用未初始化内存。
释放后使用,即悬垂指针。
缓冲区溢出,比如数组越界。
非法释放已释放过或未分配的内存。
并发场景下的数据竞争。
为了达成此目标,语言设计需要在六个原则中进行权衡:
可靠性。代码编译即正确。
高性能。代码执行效率可以媲美 C/Cpp。
支持性。为用户提供多方面支持,比如 IDE、用户友好的编译错误信息等。
生产力。让开发更有效率,事半功倍。
透明性。让用户对底层资源具有透明控制力。
多样性。多个领域都可以用 Rust 。
Rust 语言是在这些原则中权衡的结果,客观情况无法做到同时满足这六大原则。所以,导致的问题就是学习曲线较其他语言更高,对学习和使用者的基础有一定的要求。
因为 Rust 语言面对的这个问题领域本身就非常复杂。从 Rust 语言架构层面来看,Rust 语言为了解决内存安全和高性能并重的问题,给出的方案其实非常简洁。
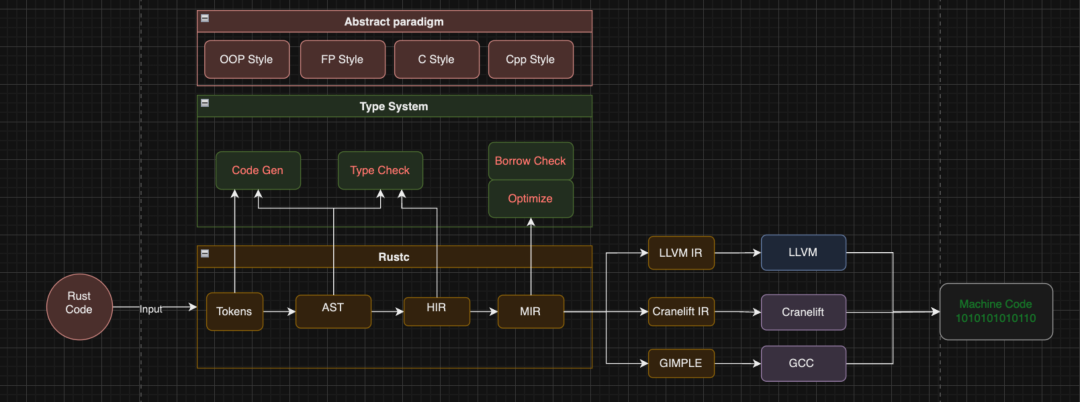
首先,Rust 语言是一门编译语言。Rustc 是其编译前端,在编译过程中,通过精心设计的类型系统,通过对代码中类型的检查,来实现对内存安全进行管理,以及更好地优化代码。编译后端包括 LLVM 和 Cranelift,以及正在支持的 GCC 后端和 SPIR-V GPU IR。
其次,在类型系统之上,Rust 语言也提供了更高级的抽象范式,支持面向对象风格和函数式编程风格,甚至可以直接向写 C 那样遵循过程式范式。并且引入了很多现代化语言特性,比如 trait 和 enum ,允许开发者易于编写出更具可扩展性的系统。
从 2015 年 Rust 1.0 稳定版发布到写本文之时 (2023 年 9 月),Rust 已经发布了 72 个语义化版本,三个 Edition 版次(每三年发布一次的大版本)。在 Stackoverflow 的年度调研报告中,Rust 连续八年收获最受欢迎语言称号。
一门语言最重要的就是其生态。截止目前,crates.io 上面 crate 数量已经超 12 万,下载量已达到 393 亿次。虽然,Rust 学习曲线较高,但也没有阻碍生态的发展。
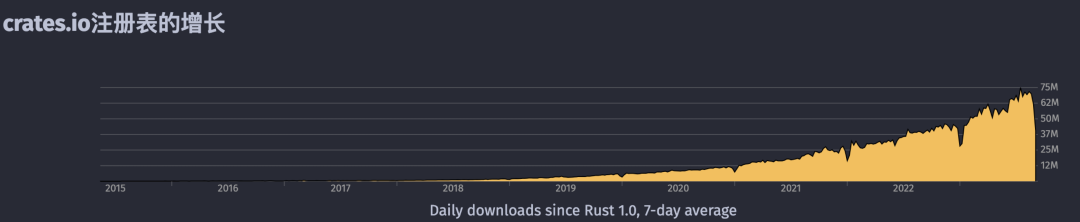
并且其生态从 2020 年起,每年下载量以 1.7 倍速度增长。
并且其生态基本能覆盖到 C/Cpp/Java/Go 等语言的应用领域。
截止今年,Rust 语言已经证明了其在系统编程领域的优势。曾经流行的 Rewrite it in Rust 梗,已经变为了现实,目前能用 Rust 重写的基本都已经用 Rust 重写了。包括一些新的系统,Rust 也是第一选择。这里说的系统,目前是指基础设施领域的系统,包括 AI 基础设施。
Mojo 语言
据 Mojo 官方声称,Chris 在 2022 年创建 Modular 公司时,并未打算创造 Mojo 语言。他们在构建下一代推理引擎 Modular 时,发现整个技术栈的编程模型过于复杂,并且手动编写了大量的 MLIR,开发效率极低。因此,他们萌生了创建新的编程语言来统一整个技术栈的想法,Mojo 就诞生了。
Mojo 想要的是一种创新且可扩展的编程模型,能够针对在人工智能领域中普遍存在的加速器和其他异构系统进行编程。这意味 Mojo 要成为一种具有强大的编译时元编程能力、集成自适应编译技术、在整个编译流程中进行缓存以及其他现有语言不支持的功能的编程语言。
从 Mojo 语言架构层面来看,Mojo 如何解决这个问题:
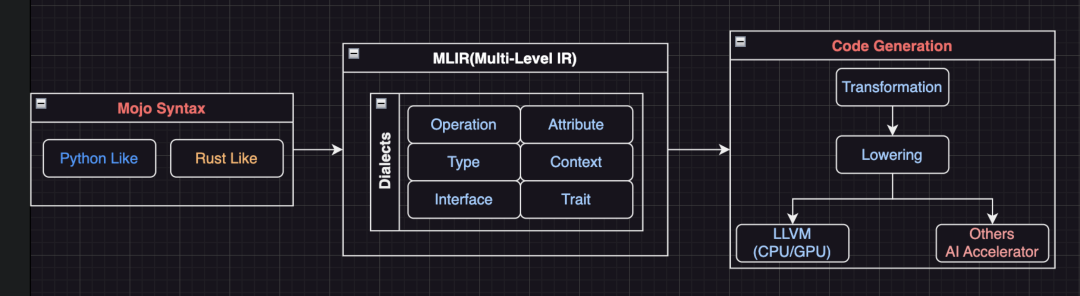
首先,Mojo 的语法兼容了 Python 语法。因为 AI 生态中 Python 库占据生态位,想要一统天下,必须坐拥 Python。曾经 Chris 在 Apple 就有过类似经历,Swift 可以与 ObjectiveC 的库混编,用了五年时间完成了语言之间的过渡。
$ cat hello.🔥def main(): print("hello world") for x in range(9, 0, -3): print(x)$ mojo hello.🔥hello world963$语法虽然与 Python 相似,但是 Mojo 的 def 定义中允许强类型检查。因为 Mojo 是 Python 的超集。
struct MyPair: var first: Int var second: Int # We use 'fn' instead of 'def' here - we'll explain that soon fn __init__(inout self, first: Int, second: Int): self.first = first self.second = second fn __lt__(self, rhs: MyPair) -> Bool: return self.first < rhs.first or (self.first == rhs.first and self.second < rhs.second)看上去像不像 Rust 代码?更准确来说是披着 Python 皮的 Rust 。从这一点来看,Chris 也许也很喜欢 Rust 的设计,否则不会借鉴。
话说回来,Mojo 提供了 fn ,相比 def 具有更加严格的检查,适合于系统编程。而 struct 的结构和内容是预先设置的,在程序运行时无法更改。与 Python 不同,你无法在运行过程中随意添加、删除或更改对象的属性。Mojo 不允许这样做。Mojo 支持 AOT 和 JIT 两种方式。
在 Mojo 语法之下是 MLIR。
MLIR,即 Multi-Level IR,是一种可扩展的中间表示(IR)格式,用于编译器设计。许多不同的编程语言和编译器将其源程序转换为 MLIR,因为 Mojo 提供了对 MLIR 功能的直接访问,这意味着 Mojo 程序可以享受到这些工具的好处。
Mojo 可以使用 MLIR 自定义类型。比如,使用 Mojo 的 struct 关键字来定义一个新的类型 OurBool:
struct OurBool: var value: __mlir_type.i1 fn __init__(inout self): self.value = __mlir_op.`index.bool.constant`[ value : __mlir_attr.`false`, ]()一个布尔值可以表示 0 或 1,true 或 false。为了存储这个信息, OurBool 有一个单一成员,称为 value 。它的类型使用 MLIR 内置类型 i1 。实际上,在 Mojo 中可以使用任何 MLIR 类型,只需在类型名称前加上 __mlir_type 。
为了初始化底层的 i1 值,我们使用了来自 index 方言的 MLIR 算子,称为 index.bool.constant 。
let a = OurBool()# error: 'OurBool' does not implement the '__copyinit__' methodlet b = a创建一个 a ,然后将其赋值给 b,则会报错。因为 Mojo 语言中默认为 值语义,OurBool 并未实现 copyinit 方法,所以无法复制。
@register_passable("trivial")struct OurBool: var value: __mlir_type.i1 fn __init__() -> Self: return Self { value: __mlir_op.`index.bool.constant`[ value : __mlir_attr.`false`, ]() }通过为结构体增加装饰器 @register_passable(“trivial”) ,就可以复制其实例变量了。trivial 代表是“平凡的”或“平平无奇的”简单值,可以安全复制。这里有点类似于 Rust 语言的复制语义。
MLIR 是模块化和可扩展的。MLIR 由越来越多的“方言(Dialects)”组成。每个方言定义了算子(Operation)和优化:例如,“math”方言提供了诸如正弦和余弦等数学操作,“amdgpu”方言提供了针对 AMD 处理器的特定操作,等等。方言经过降级之后,Mojo 代码将被编译到指定平台的机器指令。
MLIR 的每个方言都可以互操作。这就是为什么说 MLIR 可以解锁异构计算的原因。随着新的、更快的处理器和架构的开发,新的 MLIR 方言被实现以生成适用于这些环境的最优代码。任何新的 MLIR 方言都可以无缝地转换为其他方言,因此随着更多方言的添加,所有现有的 MLIR 都变得更加强大。
利用 MLIR 这种特性,就实现了底层异构系统大统一。这就是 Mojo 解决问题的方式。
Rust vs Mojo : 对立还是融合?
Mojo 官方观点
七月份,Modular 官方博客发布标题为《未来的人工智能的语言,是 Rust 还是 Mojo ?》[2] 的一篇文章。其中谈到 Rust 的语言特性,在 AI 领域相比于 Python 和 Cpp ,是一门更好的语言,这是一种认可。但是因为 Rust 语言是从零开始设计,其在 AI 领域的生态位还相当年轻,不如 Python 和 Cpp 。虽然生态中有一些 Rust 绑定库,比如 OpenCV-rust [3] 或者 libonnxruntime 的绑定 ort [4] ,都是独立贡献者维护的,从 2019 年到现在进展不大。虽然现在也有更好的 Rust 实现,比如 tract-onnx [5] ,但是缺乏贡献者和运营者,进展缓慢。并且声称绝大多数人工智能研究人员都是使用 Python,而且对学习 Rust 不感兴趣,因此很不可能在机器学习领域得到广泛应用。
反观 Mojo ,可以复用任何一个 Python 库。并且在语法上兼容 Python ,会受到广大人工智能研究人员的喜爱。除此之外,Mojo 也能简化当前 Python + Cpp 的麻烦,比如如果想加速代码,可能还得学习如何在 C++ 中使用 SIMD 指令集作为备选方案等。官方给出了一个用 Mojo 做快速均值模糊 (Box Blur) 的示例。其中用到了 MLIR 提供的 SIMD 功能和 自己编写的用于将表示地址的 Python 整数转换为具有给定数据类型的 Mojo 指针的功能(代码如下)。
from DType import DTypefrom Pointer import DTypePointerfn numpy_data_pointer(numpy_array: PythonObject) raises -> DTypePointer[DType.uint32]: return DTypePointer[DType.uint32]( __mlir_op.`pop.index_to_pointer`[ _type:__mlir_type.`!pop.pointer<scalar<ui32>>>` ]( SIMD[DType.index,1](numpy_array.__array_interface__['data'][0].__index__( "DType.index,1")).value ) )其中,pop 是 Modular 团队开发的 MLIR 方言。它并不是为了普通程序员需要理解这个语法,随着时间的推移,有用的东西将会被编译器工程师封装成一个漂亮的 API,供系统工程师和 Python 程序员(未来的 Mojo 程序员)在更高的层次上使用。但开发者仍然有能力定义自己的方言或使用 MLIR 生态系统中已经定义好的方言之一,这使得供应商可以轻松加速他们的硬件,例如 gpu 方言 [6] 。
以上,是 Mojo 官方的观点。总结为一句话就是:Rust 很好,但其生态位不足;Mojo 才是 AI 的未来。
Mojo 官方忽略的问题:大模型时代开启,资本推动与时间差
Mojo 官方提供的观点论据都很足,很有道理。但是我认为官方忽视了一个重要问题:一门语言成熟所需的周期。
虽然 MLIR 功能强大极具潜力,但 Mojo 语言当前还是一个小火苗。它还需要很长时间来兑现它的承诺:安全、高性能、像 Python 一样简单易用。Rust 语言从发布到成熟,花了八年;Go 语言十三年;Swift 差不多也是八年。那么 Mojo 语言需要几年呢?
从上面官方给出的各种示例中发现,Mojo 标准库目前还未建立,如果用 Mojo 开发,还需要开发者懂 MLIR 各种方言,这学习曲线也许比 Rust 更高一个量级。难道这就是 Python 开发者喜欢的?
“话说,过去八年 Rust 最受欢迎语言榜首投票中难道没有 Python 程序员?
Mojo 语言目前只被用于其母公司产品 Modular 推理引擎的开发中。从小道消息处得知,有些 AI 公司也已经投入了 Mojo 的前期培训。
而 Rust 语言,2023 年之前确实在 AI 生态上进展缓慢,但今年大语言模型时代开启,资本大量涌入 AI 生态。在 Mojo 兑现承诺的这段时间差中,Rust 语言极有可能在 AI 生态中占据一席之地。
因为,据我观察,2023 年 AI 领域的一些独角兽已经开始采用 Rust 了。
Rust 的 AI 生态位
我们简单盘点一下当前 Rust 在 AI 领域的生态位。
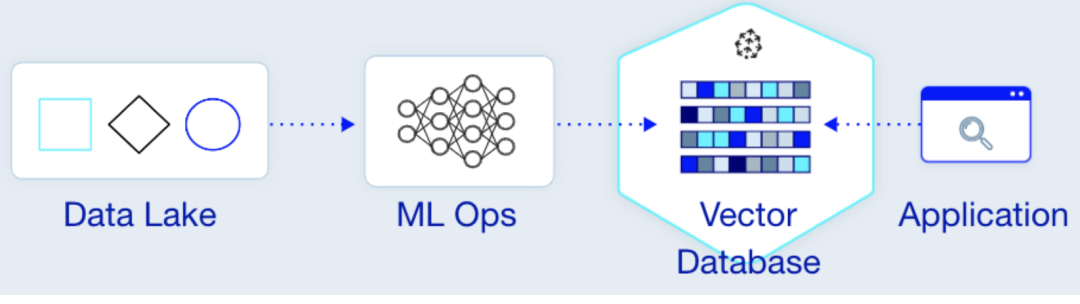
AI 领域涉及模型训练、模型部署、到智能应用这一系列流程。在这整个流程过程中,都能看到 Rust 语言的影子。我们简单将其分为下面五类:
高性能数据分析
深度学习框架及其依赖
推理引擎
开源大模型
大模型应用相关基础设施
高性能数据分析
Polars 在数据操作层面,每个人都喜欢 Pandas 的 API。它快速、简单且有据可查。但在生产方面,Pandas 有点棘手。Pandas 不能很好地扩展……没有多线程……它不是线程安全的……它不是内存效率。这一切都是 Rust 存在的理由。
Polars[7] 用 Rust 实现的新 Dataframe 库,具有方便的 Python 绑定。它试图做到以线程安全的方式进行读取、写入、过滤、应用函数、分组和合并。Polars 建立在 Apache Arrow 规范 [8] 的 安全 Arrow2 实现 [9] 之上 ,可实现高效的资源使用和处理性能。它还可以与 Arrow 生态系统中的其他工具无缝集成。
Polars 有两个优势:
它是性能杀手,参考 db-benchmark[10] 。
它的 API 非常简单。哪怕不懂 Rust 语法也能看懂该接口要做什么。
也有三个缺点:
构建 Dataframe API 很困难,Pandas 花了 12 年才达到 1.0.0,而 Polars 很年轻,所以目前还不够成熟。
使用它的时候,不仅仅要熟悉 Polars API,还需要熟悉 Arrow API,因为很多繁重工作是 arrow 来完成的。
编译时间太慢,可能需要 6 分钟左右。
Polars 现在主要由 Xomnia[11] 公司赞助。Xomnia 是荷兰一家人工智能公司,在研究自动驾驶船只,被人称为水上特斯拉。
Linfa
Linfa [12] 是一组 Rust 高级库的集合,提供了常用的数据处理方法和机器学习算法。Linfa 对标 Python 上的 scikit-learn,专注于日常机器学习任务常用的预处理任务和经典机器学习算法,目前 Linfa 已经实现了 scikit-learn 中的全部算法,这些算法按算法类型组织在各子包中。
目前 Linfa 的中期 Roadmap[13] 距离与 Python 的 scikit-learn 目前可用的 ML 算法和预处理程序相媲美的实现的最终目标。
其他
nalgebra[14] ,是 Rust 的通用线性代数库,和 Rapier 一起都是 ,Dimforge 开源组织[15] 开发的。
深度学习框架及其依赖
HuggingFace 出品:Candle
candle[16] 是 AI 独角兽 HuggingFace 出品的专注于性能(包括 GPU 支持)和易用性的 Rust 极简机器学习框架。
candle 框架的特点是:
语法简单,看起来和使用起来都像 PyTorch。多后端支持。
优化的 CPU 后端,可选支持 x86 的 MKL 和 mac 的 Accelerate
CUDA 后端以高效地在 GPU 上运行,通过 NCCL 实现多 GPU 分布。
WASM 支持,允许在浏览器中运行模型。
多模型支持。
LLMs: LLaMA v1 和 v2,Falcon,StarCoder。
Whisper(多语言支持)。
Stable Diffusion。
计算机视觉:DINOv2,EfficientNet,yolo-v3,yolo-v8。
支持从 safetensors、npz、ggml 或 PyTorch 文件中加载模型
支持在 CPU 上 Serverless 部署
使用 llama.cpp 的量化类型来支持量化
Candle 的核心目标是实现无服务器推理。像 PyTorch 这样的完整机器学习框架非常庞大,这使得在集群上创建实例变得缓慢。Candle 允许部署轻量级二进制文件。
HuggingFace 其他 Rust 开源库:
safetensors[17] ,安全存储和分发张量(tensor),并且是高性能(零拷贝)。该库主要是为了消除默认情况下使用的 pickle 的需要,因为 pickle 是不安全的,有运行任意代码风险。
tokenizers[18] .
新晋开源框架:Burn
Burn[19] 是一款开源的致力于成为全面的深度学习框架。它提供卓越的灵活性,并且使用 Rust 语言实现。目标是通过简化实验、训练和部署模型的过程,为研究人员和实践者提供服务。
Burn 的进展非常快,目前已经发布 0.9 版本。它的特点是:
可定制、直观且用户友好的神经网络模块。
全面的训练工具,包括 metrics 、 logging 和 checkpointing。
多功能的张量可插拔的后端工具箱:
Torch[20] 后端,支持 CPU 和 GPU
Ndarray[21] 后端与 no_std 兼容性,确保了通用平台的适应性
WebGPU[22] 后端,提供跨平台、包含浏览器的基于 GPU 的计算
Candle[23] 后端。
Autodiff[24] 自动微分后端。
Dataset[25] 包含各种实用工具和资源的容器。
Import[26] ,是用于导入一个简化预训练模型集成的包。
学习更多内容可以参考 Burn Book[27] 。
社区也有第三方基于 Burn 实现了开源大模型:
stable-diffusion-burn[28] ,将 Stable Diffusion v1.4 移植到 Burn 框架中。
stable-diffusion-xl-burn[29] ,将 stable diffusion xl 移植到 Rust 深度学习框架 burn 中。
llama2-burn[30] ,将 Meta 的大型语言模型 Llama2 移植到 Rust 深度学习框架 Burn 上。
whisper-burn[31],是使用 Rust 深度学习框架 Burn 实现的 OpenAI Whisper 转录模型的 Rust 版本。
其他框架
tch-rs[32] 是 Pytorch 的 Cpp API 的 Rust 绑定,目前正在活跃维护中。
tensorflow-rs[33] ,是 Tensorflow 官方提供的 Rust 绑定,目前正在活跃维护中。
dfdx[34],是一个强大的 crate,其中包含了类型中的形状。这样一来,编译器就可以立即检测到形状不匹配的问题,从而避免了很多麻烦。
潜力股:自动微分器 EnzymeAD Rust 前端
Enzyme[35] 是 MIT 提出的自动微分框架,用于对可静态分析的 LLVM 和 MLIR 进行自动微分。当前,PyTorch、TensorFlow 等机器学习框架已经成为了人们开发的重要工具。计算反向传播、贝叶斯推理、不确定性量化和概率编程等算法的梯度时,我们需要把所有的代码以微分型写入框架内。这对于将机器学习引入新领域带来了问题:在物理模拟、游戏引擎、气候模型中,原领域组件不是由机器学习框架的特定领域语言(DSL)编写的。因此在将机器学习引入科学计算时,重写需求成为了一个挑战。
为了解决这一问题,现在的发展趋势包含构建新的 DSL,让重写过程变得简单,或者在编程时直接进行构建。这些方法可以让我们获得有效的梯度,但是仍然需要使用 DSL 或可微分的编程语言进行重写。为了方便开发者,来自 MIT 的研究者开源了 Enzyme。
目前,Enzyme 团队 fork Rust 语言项目开始实施 EnzymeAD Rust 前端 [36] ,工作正在进行中。
依赖的基础库
pyo3[37] 主要用于创建原生 Python 的扩展模块。PyO3 还支持从 Rust 二进制文件运行 Python 代码并与之交互,可以实现 Rust 与 Python 代码共存。因此,pyo3 是 Rust 和 AI 生态中的 Python 库交互必不可少的依赖库。目前 pyo3 维护非常活跃。
llm[38] ,是一个用于处理大型语言模型的 Rust 库生态系统 - 它是基于快速高效的 GGML[39] 机器学习库构建的。llm 由 ggml 张量库提供支持,旨在将 Rust 的稳健性和易用性带入大型语言模型的世界。目前,推理仅在 CPU 上进行,但后续希望通过备用后端在将来支持 GPU 推理。
推理引擎
tract:为嵌入式而生的推理引擎
Sonos[40] 是一款家庭智能音箱,该公司开源了一款 Rust 实现的推理引擎 tract[41] 。tract 的设计是为了在小型嵌入式 CPU 上运行神经网络。
AI 大模型时代,算力是一个很大的问题。目前 AI 基本是被部署到云端,推理在云端完成:用户数据将被发送到云端,经过模型处理后,结果将被发送回终端用户的设备。有时候使用云服务并不是一个好的选择。自动驾驶汽车不能在进入隧道时停止行驶。当世界另一边的数据中心出现问题时,人们不应该被锁在家外面。而且,我们中的一些人只愿意与自己拥有的设备进行交互,而不是与那个神秘的云共享生活的一部分。所以,AI 芯片通常分为三个关键应用领域:云端训练、云端推理和边缘推理。
边缘推理场景下,大模型可以在消费级终端上面进行推理,包括 HuggingFace 开源的 candle 也是为了边缘计算。这背后有个大的目标就是万物大模型。
tract 架构背景
模型训练和推理是两个独立过程。训练模型是一项艰巨且复杂的任务,而推理则相对简单。模型设计和训练也是该领域大部分研究的重点。
在模型设计和训练过程中,机器学习团队注重预测的准确性。虽然整体计算预算是一个已知的限制条件,但目标是找出最佳的模型设计和训练过程,以获得最佳的准确性。
在推理过程中,效率至关重要。模型和硬件在这个阶段是固定的实体:问题是尽可能高效地使给定的模型在给定的硬件上运行。首先,要适应硬件,然后尽可能释放更多资源以供未来的发展使用。
一旦网络训练完成并冻结,训练的相关性就消失了。随之而来的是许多对模型设计和训练有用的抽象变得多余:当执行两个值的乘法时,CPU 并不太关心这个操作属于哪个高级神经网络概念,比如卷积或者归一化层。
当今 AI 生态中 ONNX (Open Neural Network eXchange)非常重要,ONNX 构建了一个开放的生态系统,它使人工智能开发人员在推进项目时选择合适的工具,不用被框架或者生态系统所束缚。这种针对机器学习所设计的开放式的文件格式,用于存储训练好的模型,得不同的人工智能框架(如 Pytorch、MXNet)可以采用相同格式存储模型数据并交互。
但 ONNX 仍然非常注重模型设计和训练。从推理引擎实现的角度来看,它仍然包含许多冗余的运算符。2017 年由开源组织 Khronos Group 制定的 NNEF 神经网络交换标准则使用了一个更低级的表示,其中训练语义被抹去了。
NNEF 格式对于推理目的来说几乎是理想的,但该格式并不够主流,大多数软件集成商希望能够直接支持 ONNX 或 TensorFlow。所以,tract 引入了 tract-opl,它在语义上与 NNEF 非常接近:专注于简单操作,而不考虑 ONNX 和 TensorFlow 格式编码的高级训练特性。它被设计为一组 NNEF 扩展:如果模型不使用 NNEF 不包含的任何特性或运算符,tract 实际上可以将 tract-opl 序列化为纯 NNEF。这也意味着 tract 可以从 ONNX 和 TensorFlow 转换为 NNEF。
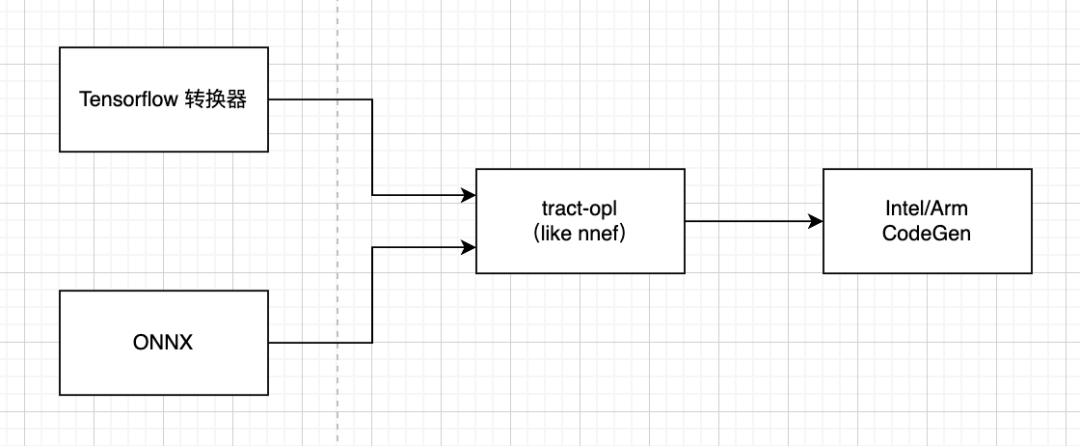
模型推理是计算密集型的任务。神经网络背后都会涉及到卷积和矩阵运算。tract 为了提供高性能和跨平台,利用 Rust 和 SIMD,以及内联汇编技术,来优化卷积和矩阵运算。比如自 2014 年至今移动 SoCs 最广泛使用的 CPU 架构 Cortex-A53,以及 苹果 M1 采用的 ARMv8 芯片,如果想充分利用这类芯片的性能,则需要汇编的加持。
目前 tract 还算是 Rust AI 生态中比较流行的推理引擎。该框架也处于积极维护中。
开源大模型
LLama2 Rust 今年 7 月份,杨立昆在 X 上转发了来自 Sasha Rush 的开源大模型 LLama2 的纯 Rust 实现[42] 。

而 Sasha Rush 是 HuggingFace 的工程师。看来 HuggingFace 内部对于 Rust 语言很是喜欢。
llama2.rs 的目标是在 CPU 上进行推理,这样的好处就是,想要部署开源大模型的公司不必要专门去寻找包括 GPU 的机器了,也算是降本增效吧?
商业大模型 Deepgram[43] 是一家基础人工智能公司,提供语音转文本和语言理解能力,使数据能够被人类或机器读取和应用。Deepgram 是人类语音识别领域真正的专家。该服务使用先进的技术将音频文件无缝转换为文本。这家自然语言处理公司提供使用该服务转换电话、会议等的选项。所有这些都可以使公司的工作变得更加简单。去年年底完成 7200 万美元 B 轮融资。
去年 Deepgram 发布了一篇官方博客文章, 介绍了其平台为何使用 Rust 重写 [44] 。Deepgram 的语音搜索 AI 大脑神经语音引擎 V4 版用 Rust 进行了重写,前三个版本都是 Python 实现的。
Rust 重写之后为他们解决了下列问题:
内存占用极大地降低了。
可以放心地引入并发,解决了 CPU 和 GPU 的性能瓶颈。在这之前,因为音频识别领域需要靠 CPU 处理很多前置工作,比如解码之类,之前用 Python ,导致 CPU 的性能跟不上 GPU 而导致了性能瓶颈。用了 Rust 之后,可以放心地使用并发,并期待 GPU 成为瓶颈了。让
开发人员专注于业务,而非把时间浪费在改 Bug 找 Bug 。
“冷知识:GPU 没有成为瓶颈,意味着是对 GPU 的浪费。Deepgram 眼里的 AI 商业趋势:语言 AI 革命在一定程度上得益于一个并行趋势:深度学习在技术行业的普及。经过精细调整的深度神经网络,这些庞大而复杂的统计模型在数百万甚至数十亿个数据点上进行训练,展现出了一种近乎神奇、不合理的有效性,几乎可以完成任何它们被设计来完成的任务。例如,端到端深度学习(E2EDL)实现了几乎与人类准确度相当的语音转文本转录结果。适当配置的深度神经网络可以以几乎无限的规模运行,并且相比于人工转录员,提供更快速、更具成本效益的转录服务。目前,在优化深度神经网络方面需要投入相当大的人力,但在不久的将来,自学习神经网络将成为新常态。综合来看,这些核心技术是未来商业建立的基石。
大模型应用相关基础设施
BlindAI : 快速且注重隐私的 Rust AI 部署解决方案
如今,大多数人工智能工具都没有隐私保护机制,因此当数据被发送给第三方进行分析时,数据就会暴露在恶意使用或潜在泄露的风险之中。比如使用 AI 语音助手时,音频录音经常被发送到云端进行分析,这样会导致对话内容暴露在外,被未经用户知情或同意的情况下进行泄露和未受控制的使用。尽管可以通过 TLS 安全地发送数据,但在其中一些利益相关者的环节中,仍然有可能被看到和暴露数据:租用机器的人工智能公司、云服务提供商或恶意内部人员。
BlindAI [45] 是一个利用安全隔离技术的 AI 部署解决方案,使远程托管的 AI 模型更加注重隐私保护。利用 tract[46] 项目作为推理引擎,在隔离环境中提供 ONNX 格式的 AI 模型服务。还使用 Rust SGX SDK[47] ,在安全隔离环境中使用 Rust 语言。用户可以从云中的 AI 模型中受益,而无需向 AI 提供商或云提供商披露其明文数据。
bastionlab[48] 提供一个简单的隐私框架,用于数据科学协作,涵盖数据探索和人工智能训练。允许数据所有者和数据科学家可以在不暴露数据的情况下安全地合作,为那些过于冒险而不敢考虑的项目铺平道路。项目使用 Polars 🐻 进行数据探索,还使用了 Torch(tch-rs) 🔥,这是一个流行的用于 AI 训练的库。
其主公司 Mithril Security 目前处于 Pre Seed 融资,120 万欧元。
向量数据库
商业向量数据库 Pinecone 向量数据库随着大语言模型时代的开启而迅速走上风口, Pinecone 则属于向量数据库行业内的独角兽。
Pinecone 虽然是闭源产品,但其在官方博客和 Rust 社区活动中都有相关的技术输出。就在去年年底,官方博客发表一篇文章《用 Rust 重写一个高性能的向量数据库》[49] ,其中记录了 Pinecone 从 Python + Cpp 到 Rust 重写的心路历程。
“虽然向量数据库的概念多年来已被许多大型科技公司使用,但这些公司都建立了自己专有的深度学习 ANN 索引算法,用于提供新闻订阅、广告和推荐。这些基础设施和算法需要大量资源和开销,而大多数公司无法支持。Pinecone 解决方案通过严格的内存管理、高效的多线程和快速可靠的性能,填补了这个空白。这就是为什么需要专门的向量数据库。面对海量数据时,向量搜索的性能和相似度准确性,都是需要专门进行优化与平衡的,而非传统数据库简单地增加向量索引能解决的。
Pinecone 在 Python + Cpp 的版本下,经常会遇到性能问题,但是却很难找到同时具备 Python 和 C++ 经验的开发人员来解决这些问题。所以 Pinecone 就用 Rust 重写了整个数据库。2023 年 4 月,Pinecone 拿到了 1 亿美元 B 轮融资。
虽然 Pinecone 用 Rust 重写了整个数据库,但并不意味着他们可以摆脱 Python ,毕竟 Python 是 AI 应用场景中占主导地位的语言 。就在前几天,Pinecone 工程师发文吐槽《 Python 的痛苦与诗意》[50] ,并指明期待 Mojo 语言的到来。文中痛斥了 Python 项目的打包、测试、分发和测试工具生态系统,并使用 Poetry 来管理 Pinecone Python 客户端,可以使用它来创建、更新和查询 Pinecone 向量数据库索引,因为他们认为它对 Pinecone 的内部维护人员、客户和社区贡献者提供了最多的好处。
开源向量数据库
Qdrant [51] 是一个向量数据库和向量相似度搜索引擎。Qdrant 是目前唯一一个纯 Rust 实现的开源向量数据库。
向量数据库作为大语言模型的「长期记忆」能力,当下很火。qdrant 目前融资 750 万美元种子轮。
传统数据库可以通过添加向量存储和向量搜索来提供向量数据库的功能,但是面对海量数据量,想要平衡向量搜索的准确度和性能,还需要专门的向量数据库。Qdrant (商业开源)和 Pinecone (商业闭源)就是专业的向量数据库。从 Qdrant 的实现看出,其在向量内存占用优化和向量海量搜索算法上下了不少功夫。内存占用优化使用 Product Quantization(乘积量化) 技术,使用 K-Means 聚类算法来平衡准确性和搜索性能。
开源 AI Agent
Chidor [52] 也许是一个 LangChain 的替代品,同样可以方便的构建 AI Agent,主要优势是反应式编程。由 Rust 开发,能支持 Python、Nodejs 和 Rust 构建 Agent。它目前处于 alpha 阶段,尚未准备好投入生产使用。以下是它的一些特点:
从头开始构建代理
运行时由 Rust 编写,开箱即支持 Python 和 Node.js
构建可实际运行的代理
LLM 缓存可最大限度地降低开发成本
针对长时间运行的人工智能工作流进行了优化嵌入式代码解释器
支持时间旅行调试
Chidori 是专注于 LLM+ 代码执行的具体操作方式,而不是提供特定的提示组合。其他框架没有关注这个领域,而这是一个重要的领域。Chidori 减少了构建长时间运行代理系统时的意外复杂性,这有助于开发人员构建成功的系统。
Chidori 是 火影忍者中卡卡西忍术的名称 ,它在日语中得名称是 Thousand Birds(千鸟),而千鸟是指一群鸟(或称为鸟群)以及由它们之间的互动产生的群体行为。千鸟是对长时间运行的代理人行为、它们内部执行的 LLM 单元以及由它们之间的互动产生的群体行为的一个很好的类比。
llm-chain[53] 提供了一组 Rust crate,帮助开发者创建高级的 LLM 应用程序,如聊天机器人、代理等等。作为一个全面的 LLM-Ops 平台,对云端和本地托管的 LLM 都有强大的支持。还提供强大的支持,包括提示模板和多步骤链式提示的链接,使得在单个步骤中无法处理的复杂任务成为可能。还提供向量存储集成,使用户的模型能够轻松获得长期记忆和专业知识。允许开发者构建复杂的应用程序。
infino[54],是 Rust 实现的一个可观测性平台,用于大规模存储指标和日志,并以更低的成本实现。可以集成到不同平台中,尤其是用于大模型相关基础设施和应用的可观测性。
总结
Rust 语言发布后,经过八年的发展,已经成为当下系统编程语言的最佳选择,目前常用于构建基础设施,包括 AI 基础设施。
Mojo 语言在 AI 领域极具潜力,但目前还未成熟,还需要很长时间来给开发者兑现承诺。
大模型时代开启,商业竞争激烈,资本推动下,Rust 将在 Mojo 成长的这段时间差内抢占一定比例的 AI 生态位。而 Mojo 目前唯一的应用很可能只是 Modular 推理引擎,这个状态和 Rust 早期与 Servo 浏览器内核共同演进的历史非常相似。
所以,短期内, Rust 和 Mojo 在各自适合的场景内逐渐发展。长期来看,Mojo 如果发展的好,就可以顺利地将 Python 生态过渡到 Mojo ,从而抢占一定的 AI 生态位。Mojo 还有一个更大的野心,就是也想成为通用语言。如果 Mojo 成熟到一定地步,那么会和 Rust 产生竞争,毕竟 Mojo 的语法相比 Rust 更好上手,但学习曲线不一定更低。在被 Rust 抢占的 AI 生态位,Mojo 也会与 Rust 进行交互融合。
以上就是我对于大模型时代编程语言的一些观点,不知道读者您有什么看法,欢迎留言讨论。
[1]Rust: https://rust-lang.org
[2]《未来的人工智能的语言,是 Rust 还是 Mojo ?》: https://mojodojo.dev/blog/2023-07-17-rust-or-mojo-ai.html
[3]OpenCV-rust: https://github.com/twistedfall/opencv-rust
[4]ort: https://github.com/pykeio/ort
[5]tract-onnx: https://github.com/sonos/tract
[6]gpu 方言: https://mlir.llvm.org/docs/Dialects/GPU/
[7]Polars: https://github.com/ritchie46/polars
[8]Apache Arrow 规范: https://arrow.apache.org/docs/format/Columnar.html
[9]安全 Arrow2 实现: https://github.com/jorgecarleitao/arrow2
[10]db-benchmark: https://h2oai.github.io/db-benchmark/
[11]Xomnia: https://www.xomnia.com/
[12]Linfa: https://github.com/rust-ml/linfa
[13]Linfa 的中期 Roadmap: https://github.com/rust-ml/linfa/issues/7
[14]https://github.com/dimforge/nalgebra: https://link.juejin.cn/?target=https%3A%2F%2Fgithub.com%2Fdimforge%2Fnalgebra
[15]https://github.com/dimforge: https://link.juejin.cn/?target=https%3A%2F%2Fgithub.com%2Fdimforge
[16]candle: https://github.com/huggingface/candle
[17]safetensors: https://github.com/huggingface/safetensors
[18]tokenizers: https://github.com/huggingface/tokenizers
[19]Burn: https://github.com/burn-rs/burn
[20]Torch: https://github.com/burn-rs/burn/tree/main/burn-tch
[21]Ndarray: https://github.com/burn-rs/burn/tree/main/burn-ndarray
[22]WebGPU: https://github.com/burn-rs/burn/tree/main/burn-wgpu
[23]Candle: https://github.com/burn-rs/burn/tree/main/burn-candle
[24]Autodiff: https://github.com/burn-rs/burn/tree/main/burn-autodiff
[25]Dataset: https://github.com/burn-rs/burn/tree/main/burn-dataset
[26]Import: https://github.com/burn-rs/burn/tree/main/burn-import
[27]Burn Book: https://burn-rs.github.io/book/overview.html
[28]stable-diffusion-burn: https://github.com/Gadersd/stable-diffusion-burn
[29]stable-diffusion-xl-burn: https://github.com/Gadersd/stable-diffusion-xl-burn
[30]llama2-burn: https://github.com/Gadersd/llama2-burn
[31]whisper-burn: https://github.com/Gadersd/whisper-burn
[32]https://link.zhihu.com/?target=https%3A//github.com/LaurentMazare/tch-rs: https://link.juejin.cn/?target=https%3A%2F%2Flink.zhihu.com%2F%3Ftarget%3Dhttps%3A%2F%2Fgithub.com%2FLaurentMazare%2Ftch-rs
[33]tensorflow-rs: https://github.com/tensorflow/rust
[34]dfdx: https://github.com/coreylowman/dfdx
[35]Enzyme: https://github.com/EnzymeAD/Enzyme
[36]EnzymeAD Rust 前端: https://github.com/EnzymeAD/rust
[37]pyo3: https://github.com/PyO3/pyo3
[38]llm: https://github.com/rustformers/llm
[39]GGML: https://github.com/rustformers/llm/tree/main/crates/ggml
[40]Sonos: https://tech-blog.sonos.com/about/
[41]tract: https://github.com/sonos/tract
[42]LLama2 的纯 Rust 实现: https://github.com/srush/llama2.rs
[43]Deepgram: https://github.com/deepgram
[44]介绍了其平台为何使用 Rust 重写: https://deepgram.com/learn/why-deepgram-built-its-platform-in-rust
[45]BlindAI: https://github.com/mithril-security/blindai
[46]tract: https://github.com/sonos/tract
[47]Rust SGX SDK: https://github.com/apache/incubator-teaclave-sgx-sdk
[48]bastionlab: https://github.com/mithril-security/bastionlab
[49]《用 Rust 重写一个高性能的向量数据库》: https://www.pinecone.io/blog/rust-rewrite/
[50]《 Python 的痛苦与诗意》: https://www.pinecone.io/blog/pain-poetry-python/
[51]Qdrant: https://qdrant.tech/
[52]Chidori: https://github.com/ThousandBirdsInc/chidori




