
背景
大页技术是操作系统中优化内存访问延迟的一种技术,其优化原理与 CPU TLB 硬件有直接关系,而其优化效果不仅受 CPU TLB 硬件影响,还需要看应用访存特点。只考虑 Arm 和 x86 两种平台,已知的大页技术包括透明大页、hugetlbfs、16k 和 64k 全局大页。在合适的场景,大页技术可以提升应用性能达 10% 以上,尤其是针对当前云上应用逐年增长的内存使用趋势,使用大页技术是其中重要的提升“性能-成本”比例的优化手段。
透明大页(Transparent Huge Pages,THP)从 2011 年开始在 Linux 内核中已经支持起来,其通过一次性分配 2M 页填充进程页表,避免多次缺页开销,更深层次从硬件角度优化了 TLB 缺失开销,在最好情况下,对应用的优化效果达到 10% 左右。除以上优点外,透明大页(主要供堆栈使用)使用过度也会导致严重的内存碎片化、内存膨胀和内存利用率低等问题,这就是当前透明大页没有在数据库中使用的核心原因,只能感叹“卿本巧技,奈何有坑”。
代码大页在透明大页的基础上,将支持扩展到可执行二进制文件,包括进程二进制文件本身、共享库等可执行数据。与透明大页相比,由于代码大页仅将占比较低且有限的可执行文件页部分转换为大页,从根本上避开了内存碎片以及内存不足的问题。与此同时,由于代码类数据和普通堆栈数据访问热度对整体性能影响不同(主要指代码数据或堆栈数据访问缺页一次的性能影响),导致代码类数据使用大页所提升的性能远大于同样分量的透明大页。所以推广和完善代码大页相比透明大页更加简单和容易。
本文主要介绍我们的代码大页方案以及一些实验阶段性能测试。为了方便阅读,在这里简单归纳了一下 Linux 系统中大页的支持现状和和必要的数据库相关背景。
大页现状
当前 Linux 内核支持的大页包括 THP 和 hugetlb,其页大小分别是:
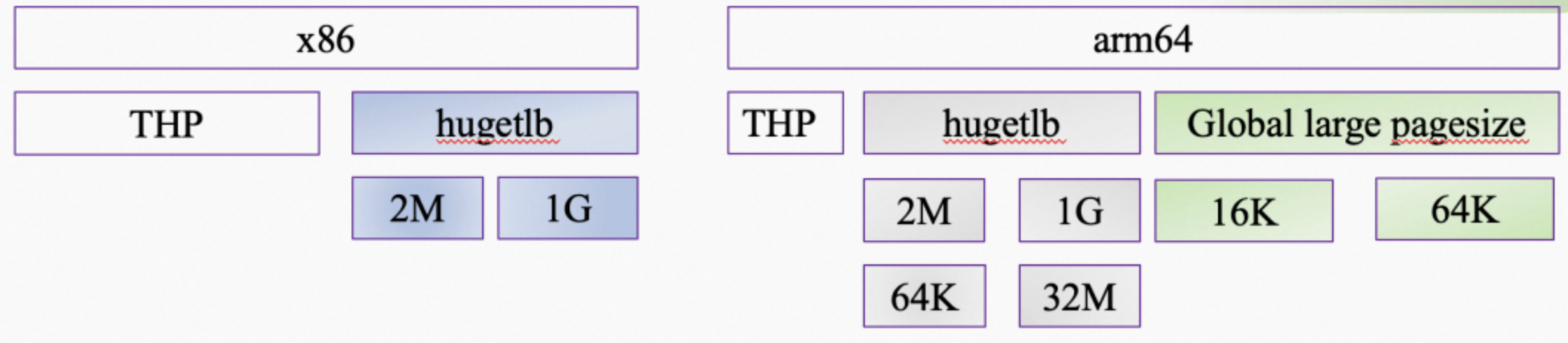
不考虑其他架构,在 x86 和 Arm 架构中,提到 THP,我们可以一股脑地认为其大小就是 2MB,当前内核暂时还不支持 1GB THP,技术上实现没有什么问题,社区隐隐约约也有人曾经发过相关补丁。回到这里,Arm64 相比 x86,hugtlb 多两种大页支持,主要是 contiguous bit,该特性主要是针对 TLB entry 的优化(连续的 16 个 PTE/PMB,若其上的 PFN 也是连续的,cont bit 会将其使用的 16 个 TLB entry 优化仅占一个 TLB entry)。这里的 64KB 和 32MB 的由来就是 16*4KB 和 16*2MB。
另外,在全局页粒度的支持上,Arm64 也比 x86 更会玩,提供的 16KB (CONFIG_16KB 表示)和 64KB(CONFIG_64KB 表示)两种选择,这两种页相比 4KB 页,在 TLB 和 cache 上都有明显的优化相关,从而优化宏观指标,当然也并非所有 benchmark 表现出性能提升,例如在 SPECjvm2008 和 stream 中,我们就发现有多项指标在使用 CONFIG_64KB 的时候有较严重的性能下降。除以上问题,还想再啰嗦一下,CONFIG_64KB 中,THP 的大小着实有点“吓人”,有 512MB。
因此,大伙对 16KB、64KB 还是又爱又恨。
Mysql、PostgreSQL 和 OceanBase
站在内存管理的角度,我们仅仅关心 Mysql、PostgreSQL 这些数据库用了多少内存、页缓存占多少、匿名页占多少以及代码段还有 iTLB/dTLB miss 到底高不高。当然还随便想知道 THP 有没有优化,下面几个是简单归纳的几点我们关系的数据库特点:
Mysql
Mysql 是一个多线程模式的数据库,其代码段大小一般 18M 左右。
THP 不敏感,打开 THP,大约仅有不到 3% 的性能提升。
跨 NUMA 敏感,本地虚拟机 32 核验证跨 NUMA 抖动在 5~7% 左右。
PostgreSQL
多进程模型,代码段大小大约 10M 左右。
应用 iTLB-load-misses 较高,大约 1.41% 左右。
OceanBase
多线程模型,代码段大小大约 200M~280M。
一般独占单机使用,性能验证过程中并发数要求高:128、1000、1500。
THP 本地验证不敏感。
这些数据库大约至少有两个共同点:代码段大、iTLB Miss 高。本文也是基于这两个特征进行的优化,当然代码大页优化目标也不局限于这三种数据库。
代码大页
接着前面数据库背景介绍,这里直接开始代码大页方案。
代码大页大致实现分为:整理结构、大致实现、填充功能简介还有最后的代码大页性能评估(包括 Mysql 和 PostgreSQL),最后是我们专门为解决 x86 平台设计的自适应功能。
整体结构与实现
基于透明大页异步整合大页(主要指 khugepaged 内核线程)的框架:
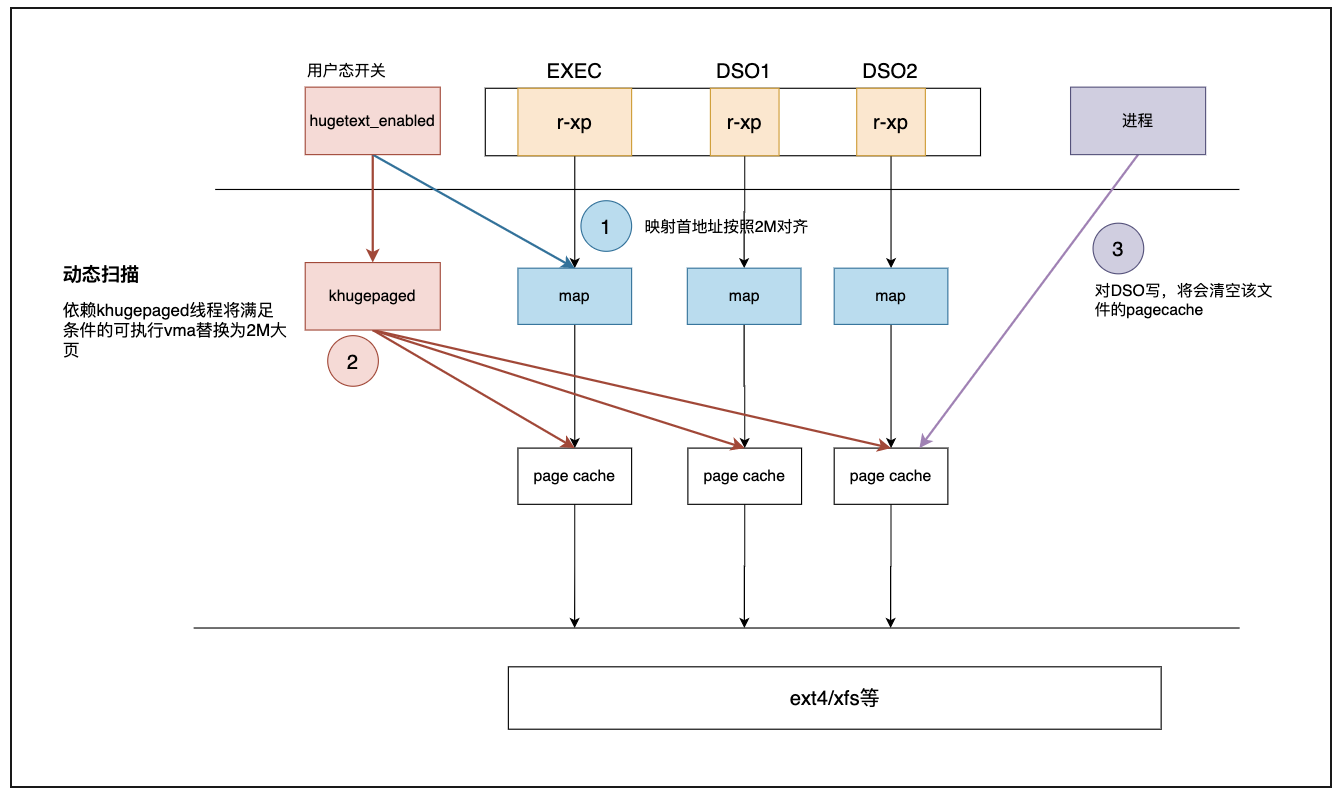
上图所展示的代码大页方案主要包括三个部分:
(1)映射首地址对齐(蓝色高亮):这个部分主要是在 elf binary 和 DSO 建立映射的过程中,优先考虑分配 2M 对齐的虚拟地址空间,便于映射到 2M 大页。
(2)异步 khugepaged 扫描整合以及加速(橙色高亮):与 THP 相似,单独设计用户态接口 hugetext_enabled 控制。复用 khugepaged 整合 2M 大页。此外,由于 hugetext 与 THP 共用 khugepaged,在 THP=always 时,也能整合部分符合条件的代码大页;关于加速部分,我们解决了在 THP 使能的场景中,代码段整合慢的问题,这也是我们改进 READ_ONLY_THP_FOR_FS 带来的挑战之一。
(3)DSO 写回退(紫色高亮):对于 DSO 所建立的映射,内核屏蔽了 MAP_DENYWRITE,导致用户态可以写打开共享库文件(尽管一旦对该共享库写,进程多数情况会 core dump)。针对这种情况,在检测到该共享库存在写者时,对其 pagecache 进行清空;DSO 为什么有这么多顾虑可以跳转:
https://developer.aliyun.com/article/863760
注意:首地址 2M 对齐的本意是 mmap addr = mmap pgoff (mod 2M),由于 elf binary 和 DSO 的可执行 LOAD 段的 pgoff 一般为 0,这里为了叙述方便,我们简称地址 2M 对齐。
另外,在开发和测试过程中,我们的实现方案解决了 file THP 相关的三个 bug 的补丁,Linux 社区已经合入,glibc 社区也合入了一个 p_align 修复补丁。
除以上部分,我们目前已经完成的自适应代码大页已经完成,主要解决 x86 平台使用代码大页过多的问题。详细见“自适应处理”一节。
代码段填充功能
前面,我们已经描述代码大页方案支持动态链接库(DSO)和二进制文件本身,对于 libhugetlbfs 方案,其仅仅支持二进制文件本身的大页转换,虽转换比较完全,但是它无法同时让 DSO 使用大页。显而易见,与 libhugetlbfs 相比,我们提供的 hugetext_enabled 方式更加完整,性能优势更大。填充功能主要是我们为弥补在某些场景中,其大量的热点发生在代码段的尾部,libhugetlbfs 天生可以做到,所以我们也不得不解决这个问题。
言归正传,回到代码段填充。首先用一张图来表示代码段填充具体是什么。
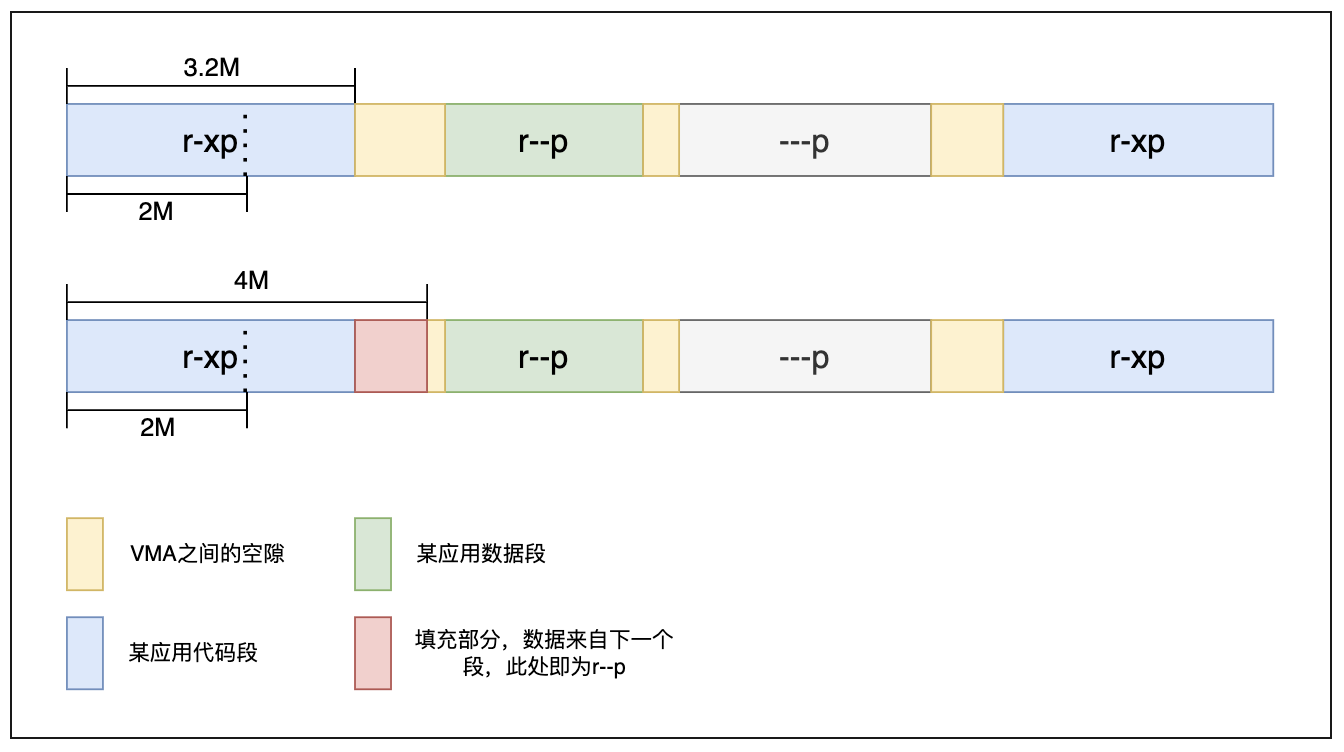
大多数应用并不能完全保证其代码段都会 2M 对齐,如上图所示,一个应用第一个 r-xp 有 3.2M,其中 2M 我们的 hugetext_enabled 本身即支持,后面的 1.2M 我们不得不向后填充这个 vma,保证其映射大小 2M 对齐,其填充的内容其实就来自于下一个 r--p 的数据(r-xp 和 r--p 在 ELF 磁盘中是两个相邻的 PT_LOAD 段,具体可以通过 readelf 观察)。
当然我们在填充过程中会判断填充后大小不会超过原文件大小和不会与下一个 r--p 属性的 vma 重叠。下面是我们新引入的代码大页填充使能开关,例如将 0x1000 写入 hugetext_pad_threshold,表示需填充内容超过 4k 时填充功能才会使能。
/sys/kernel/mm/transparent_hugepage/hugetext_pad_threshold最后再夹带一点私货,以上代码段填充主要是在不重新编译应用程序的情况的一种内核方式,还有一种方式是在应用的链接脚本中加入“. = ALIGN(0x200000)”,将代码段直接按照 2M 对齐,如此不需要填充或进行填充更加安全。例如以一个简单的测试程序 align.out 为例。设置链接脚本后 Section 出现对齐:
$ readelf -l align.outElf file type is EXEC (Executable file)Entry point 0x400520There are 9 program headers, starting at offset 64Program Headers: Type Offset VirtAddr PhysAddr FileSiz MemSiz Flags Align PHDR 0x0000000000000040 0x0000000000400040 0x0000000000400040 0x00000000000001f8 0x00000000000001f8 R 0x8 INTERP 0x0000000000000238 0x0000000000400238 0x0000000000400238 0x000000000000001b 0x000000000000001b R 0x1 [Requesting program interpreter: /lib/ld-linux-aarch64.so.1] LOAD 0x0000000000000000 0x0000000000400000 0x0000000000400000 0x0000000000200194 0x0000000000200194 R E 0x200000 LOAD 0x0000000000400000 0x0000000000a00000 0x0000000000a00000 0x0000000000010040 0x0000000000200008 RW 0x200000 DYNAMIC 0x0000000000400010 0x0000000000a00010 0x0000000000a00010 0x00000000000001d0 0x00000000000001d0 RW 0x8 NOTE 0x0000000000000254 0x0000000000400254 0x0000000000400254 0x0000000000000044 0x0000000000000044 R 0x4 GNU_EH_FRAME 0x000000000020004c 0x000000000060004c 0x000000000060004c 0x000000000000004c 0x000000000000004c R 0x4 GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 RW 0x10 GNU_RELRO 0x0000000000400000 0x0000000000a00000 0x0000000000a00000 0x0000000000010000 0x0000000000010000 R 0x1 Section to Segment mapping:从上面 readelf 文件输出可以看出:两个 PT_LOAD 的 offset 已经按照 2M 对齐,并且两个 PT_LOAD 完全分布到不同的 2M 页中,如此,若进行填充,完全不需要用后一个 PT_LOAD 数据。测试方法:导出默认并修改默认的 lds 文件,在代码和数据段前加上". = ALIGN(0x200000);"即可。备注:“gcc -Wl,--verbose”可查看默认的链接脚本。另外,在编译过程中需要加上“-z max-page-size=0x200000”选项,否则对齐会被约束为 4K 或 64K,如下:
$ gcc main.c test.c -o align.out -Wl,-T ld-align.lds -z max-page-size=0x200000链接脚本加 hugetext_pad_threshold 结合使用,可以让应用对代码大页使用更加友好。
快速试用
为了方便业务使用,我们扩展了两种打开方式:启动参数和 sysfs 接口。
启动参数
打开:hugetext=1 or 2 or 3
关闭:缺省即为关闭
sysfs 接口
仅打开二进制和动态库大页:echo 1 > /sys/kernel/mm/transparent_hugepage/hugetext_enabled
仅打开可执行匿名大页:echo 2 > /sys/kernel/mm/transparent_hugepage/hugetext_enabled
打开以上两类大页:echo 3 > /sys/kernel/mm/transparent_hugepage/hugetext_enabled
关闭:echo 0 > /sys/kernel/mm/transparent_hugepage/hugetext_enabled
查看/proc/
扫描进程代码大页使用数量(单位 KB):
cat /proc/
padding 接口
/sys/kernel/mm/transparent_hugepage/hugetext_pad_threshold
echo [0~2097151] > /sys/kernel/mm/transparent_hugepage/hugetext_pad_threshold
当二进制文件末尾剩余 text 段由于不足 2M 而无法使用大页,当剩余 text 大小超过 hugetext_pad_threshold 值,可将其填充为 2M text,保证可使用上大页。hugetext_pad_threshold=0,表示填充功能关闭,该接口依赖 hugetext_enabled 接口。
建议一般情况写 4096 即可:echo 4096 > /sys/kernel/mm/transparent_hugepage/hugetext_pad_threshold
当然,如果想完全回退代码大页对应用的影响,可以采用下面的回退方式:
在打开 hugetext_enabled 后,若关闭 hugetext_enabled 并且完全消除 hugetext_enabled 影响,可以下面几种方式:
清理整个系统的 page cache:echo 3 > /proc/sys/vm/drop_caches
清理单个文件的 page cache:vmtouch -e /
/target
清理遗留大页:echo 1 > /sys/kernel/debug/split_huge_pages
代码大页性能评估
Mysql 性能评估
为了充分挖掘代码大页的收益,我们针对不同的平台,包括 x86、Arm,分别对 mysql、python 以及 jvm 等应用进行了测试,由于数据太多、混乱,我们挑选出 mysql 上的测试数据,测试数据包括 TPS、QPS 以及 iTLB miss 数据。
本文数据的测试环境:
5.10(alios 5.10-002)
mysql 版本:MariaDB-10.3.28
虚拟机配置:32 核、128G 内存
物理机配置:打开透明大页
由于在 Arm 平台和 x86 平台测试的数据指标和测试方法相同,所以我们挑选出 Arm 篇对这些数据进行了较详细的描述和分析,在 x86 篇中,仅仅简单描述数据统计图中代码大页与 4k 代码页的性能差异。
Arm 篇
下面展示在 Arm 平台上,代码大页对 mysql 的性能提升。
测试过程中,mysql 并发数分别是 1、8(25%)、16(50%)、32(100%)。测试结果与普通的 4K 代码页数据对比如下:
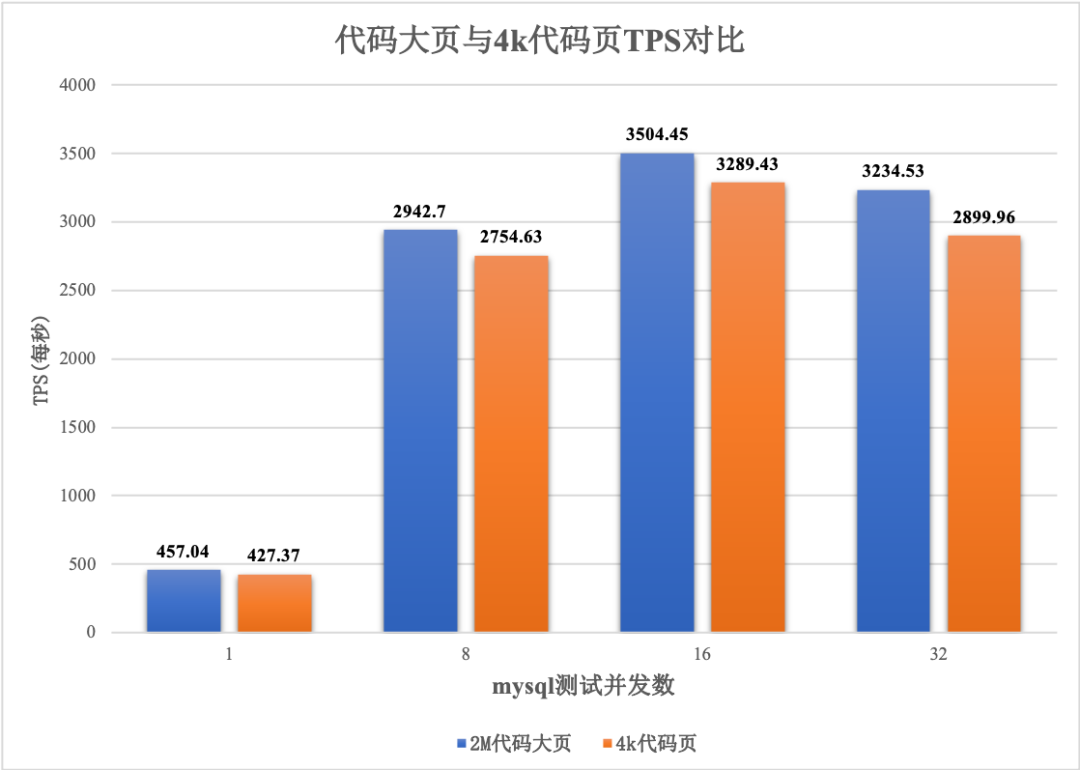
上图 TPS 对比可以看出:代码大页的性能始终高于普通的代码页。关于这张图中其他的结论,还有:
并发数为 1 时,外在的影响因素最小,此时,代码大页相比普通代码页,性能提升大约在 6.9%。
并发数 8、16 基本可以保证没有 CPU 的竞争,代码大页的性能提升大约也在 6.5% 以上。
并发数 32 时,由于总核数为 32,存在于其他应用竞争 CPU,所以 TPS 较低于前面的测试结果。但是代码大页的鲁棒性更好,此时相比普通代码页,性能提升大约在 11% 左右。
另外,还有 RT 的对比,如下图:
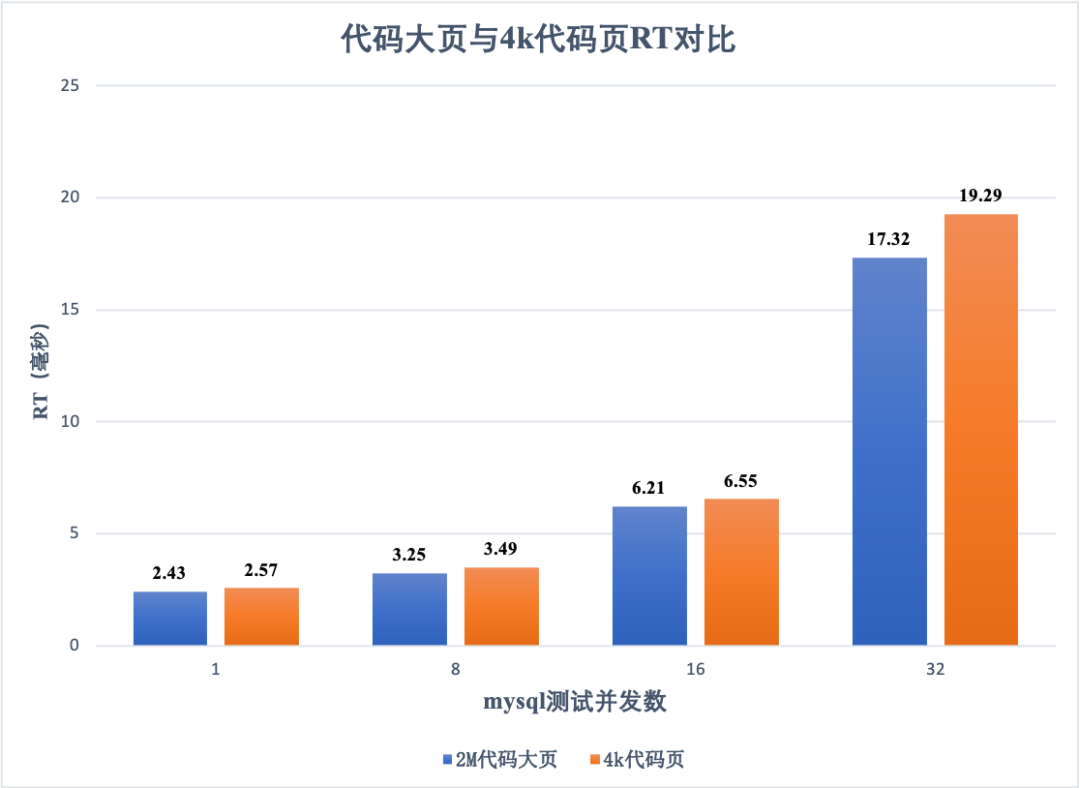
RT 的数据主要是前 95% 的请求的最大响应时间(95th percentile)。代码大页在 RT 上的表现与图 1 一致,大约提升在 5.7%~11.4% 之间。
最后的展示的数据是微架构数据,我们在分析代码大页对性能的影响过程中,主要观察 iTLB miss,如图:
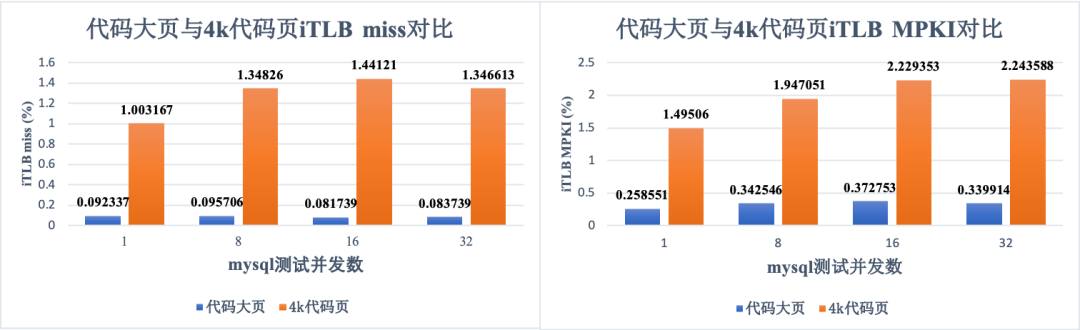
图 5(a)和图 5(b)都展示的是 iTLB 的数据,但是考虑到不同读者的偏好,我们在测试的过程中 iTLB miss 和 iTLB MPKI 也一并记录。如这两图所示:
mysql 使用代码大页后,iTLB miss 大约下降了 10 倍左右,数值大小从原来的 1% 下降到 0.08% 左右。
在 iTLB MPKI 上,大约下降了 6 倍左右。
经过上述数据的对比,以及我们在实验阶段进行的 THP(这里主要指 anon THP)数据对比, 在 mysql 场景下,大致可以得出一个简单的公式:
收益:代码大页 > anon THP > 4k
x86 篇
与上一小节相同,这里分别对代码大页和 4k 代码页进行 TPS、RT 对比、iTLB miss 对比。
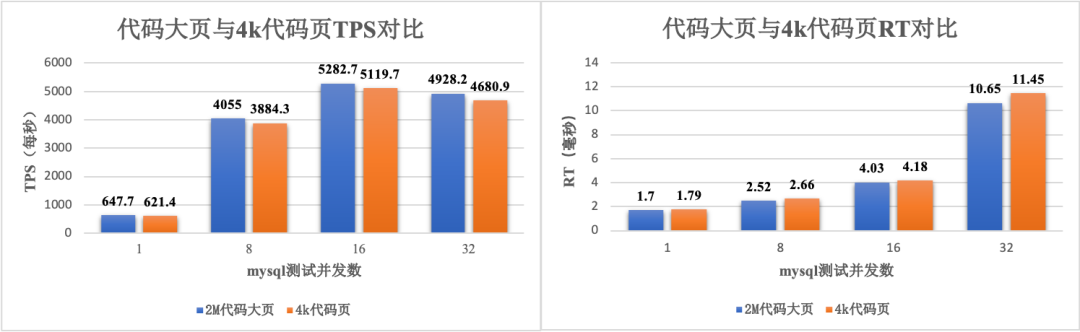
由于 TLB 硬件的差异,代码大页在 x86 和 Arm 上性能提升存在差异,根据图 6(a、b)中的测试数据,代码大页在 x86 上,对 TPS 的提升大致在 3%~5 之间,在 RT 上大致有 5%~7.5% 的收益。
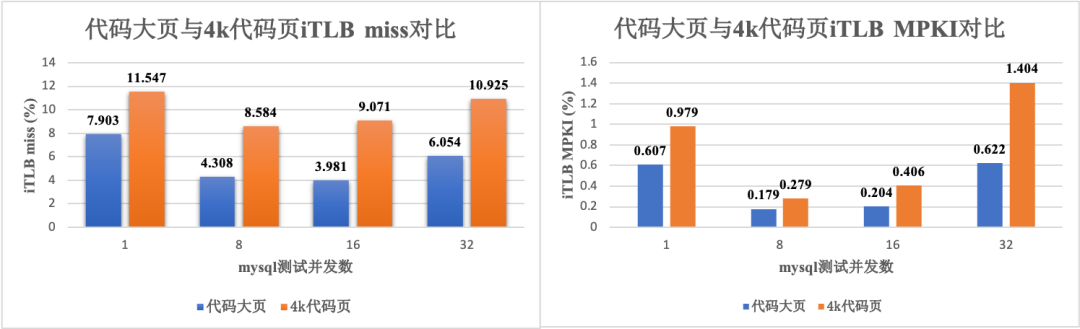
在图 7 中,可以看出:
从 iTLB miss 的数据看,代码大页相比 4k 代码页大约下降了 1.5~2.3 倍左右。
从 iTLB MPKI 的数据看,代码大页相比 4k 代码页大约下降了 1.6~2.3 倍之间,与 iTLB miss 效果相似。
到这里,我们结束对代码大页性能数据的展示。关于在物理机的测试,感兴趣的读者可以自行在 alios 5.10-002 上进行测试。
PostgreSQL 性能评估
代码大页相比 libhugetlbfs 方案,不仅仅解决了使用 libhugetlbfs 后无法使用 perf 观察热点问题,这里在 PostgreSQL 上 padding 功能派上了作用,最终代码大页性能提升较 libhugetlbfs 多 2% 左右。
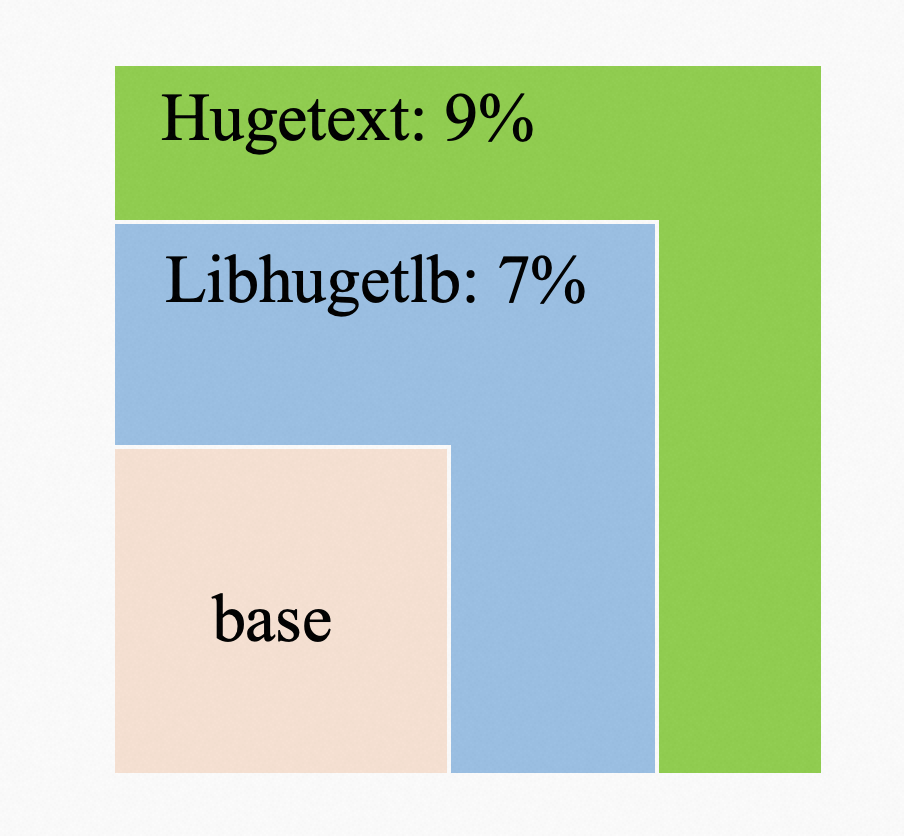
上述测试数据主要在 Arm 环境中。
小结
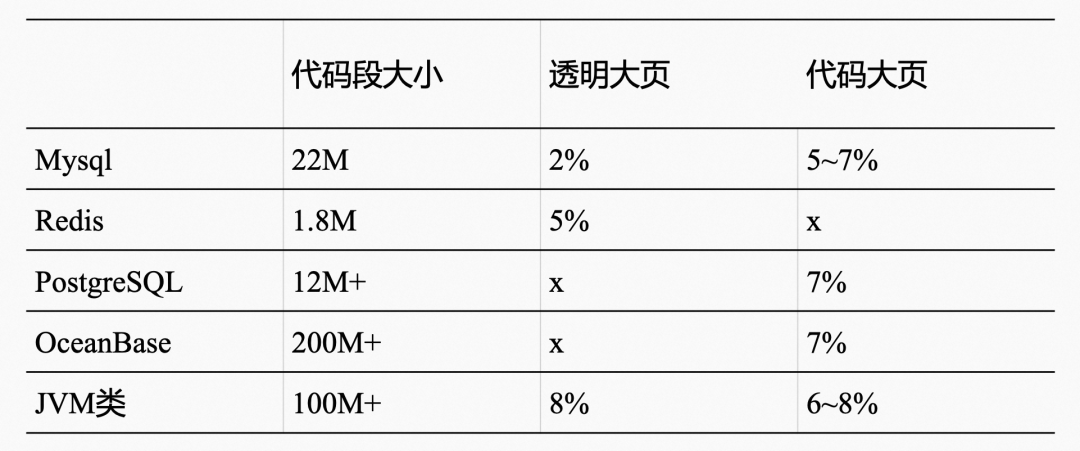
注:以上主要为 Arm 平台测试数据。符号 x 可以认为该应用没有采用该技术,或优化效果几乎是 0。
最后归纳一下,归根结底,代码大页对性能的提升也是采用的内存领域常用方法:热点+大页。
自适应代码大页
自适应代码大页在代码大页的基础上,考虑到 x86 平台上 2MB iTLB entry 不足的问题,进行的“热点采集+大页整合”的大页使用数量限制策略,该特性基本解决了代码大页在某些特大代码段上的负优化问题。
云上 JVM 类应用大约占比 60% 以上,这类应用在阿里内部大约可发现所使用的 code cache 大约有 150M~400M 情况,这类 code cache 是比较特殊的匿名页,属于 JIT 热点代码缓存在此处,属于特殊的代码数据。对于 Arm 平台,其 TLB 硬件社区并未区域 2M 或 4k 的页表项,而对于 x86 平台,其 TLB 命中有页大小要求,例如:4k 页只能使用 4k TLB entry、2M 页使用 2M TLB entry。这种设计要求应用本身使用的页表不会超过硬件支持,否则易出现严重的 TLB 未命中情况,导致性能骤降。
当前我们对云上常用的 x86 平台情况进行了一个调研,主要包括以下三类服务器在役:
从上面的数据可以看出,当前在 x86 平台,基本无法使用代码大页,2M code TLB 资源使用率基本为 0。下面我们以蚂蚁的 Java 的业务为例说明由于 TLB 资源匮乏导致的性能问题。在蚂蚁的 Java 业务总通过 hugetext 让 code cache 使用大页,出现性能回退:iTLB miss 上升 16% 左右,CPU 利用率上升 10% 左右。其原因可以确定在于 code cache 大约 150M,需要覆盖 70 多个 2M iTLB entry,而当前蚂蚁环境使用的机器基本都是 Intel 机器,以 skylake 为例,仅仅 82M iTLB entry,造成 2M iTLB entry 竞争激烈。
下表为测试的代码大页负优化数据:
上面的数据表示在打开 hugetext 后,icache_64b.iftag_stall 反而上升了 16% 左右,另外在 STLB 命中的比例上升了 0.48%,造成的结果就是 CPU 利用率上升 10% 左右。
将上面描述的问题可以简单总结为以下:
(1)Intel 机器普遍存在大页 iTLB entry 数量较少的问题,大多数服务器集中在 8~16 之间。当前 Arm 平台由于不区分 4k 和 2M iTLB,尚未发现类似问题。
(2)诸如此类,其他业务,如 flink、容器场景,代码大页使用过多造成上述问题。
以 Intel skylake 为例,iTLB entry 信息:
另外,也发现 STLB 命中后,替换 L1 iTLB entry 的惩罚较重,大约占 22 cycles。因此需要避免代码在 STLB 命中。简而言之,在 Intel 系列普遍存在 2M iTLB entry 有限的问题,是代码大页在此类平台性能提升不明显或存在负优化的核心原因。
针对上面描述的问题,自适应代码大页采用限制大页使用数量的方式,将较热点的数据整合为大页。在使用时,仅需在用户态设置自适应大页的数量接口。自适应代码大页处理流程如下:

使用该方案,可以解决代码大页在 x86 平台上负优化的问题,可以应用到 JVM 类应用和 oceanbase 数据库上。
自适应代码大页使用接口:/sys/kernel/mm/transparent_hugepage/khugepaged/max_nr_hugetext,只要为该接口设置一个值,就可以约束单个应用使用的最多代码大页数量,且不会影响 THP 的正常逻辑。
除了大页,代码段优化还有什么
代码段的优化除了大页的方案,业内还包括 PGO/autoFDO、LTO 等。
按代码段优化时间,可以将当前在编译器和链接器所做优化,简单分为:post-link optimization、link-time optimizations 以及比较混合的 BOLT optimization,如下。这些优化都是对应用代码段布局的优化。
feedback-driven optimizations (FDO) or called profile-guided optimizations (PGO)(一般用 PGO 统称)
sample-based profiling
instrumentation-based profiling (基本都是线下训练)
hardware-event sampling e.g. LBR (e.g. SampleFDO, AutoFDO)
profile-guided function reordering algorithm
Pettis-Hansen (PH) heuristic (weight dynamic call-graph, instrumentation-based profiling)
Call-Chain Clustering (C3) heuristic (weight and directed call-graph, hardware-event sampling or stack traces sampling)
link-time optimizations (LTO, [27, 28])
only depend on function reordering algorithm (PH heuristic, C3 heuristic)
post-link optimization (e.g. Ispike Spike [5], Etch [6], FDPR [7])
BOLT optimizations (大杂烩)
(不需要看懂,只要知道有 autoFDO 和 BOLT 就行)
所以这个东西干嘛用的?举一个简单例子,实验课上老师给大家一段排序的代码,让大家进行优化,将排序的时间开学降低 10 倍,这个时候就可以用上面的工具,再加上简单的 perf 使用,而不需要看具体的代码实现。
代码大页支持产品
当前,代码大页已经支持龙蜥操作系统(Anolis OS)和阿里云 ECS 支持,参考链接如下:
龙蜥操作系统(Anolis OS):https://gitee.com/anolis/cloud-kernel
龙蜥操作系统 4.19 和 5.10 最新版本默认打开 CONFIG_HUGETEXT(代码大页的主要配置)。“代码大页性能评估”一节的数据可以在龙蜥操作系统 5.10 内核复现,使用镜像可选择:
镜像缺省 sudo 用户为 anuser,对应登录密码是 anolisos。
链接:
https://docs.openanolis.cn/products/anolis/rnotes/anolis-8.8.html
阿里云 ECS
若使用环境为阿里云 ECS,可参考:
https://help.aliyun.com/document_detail/462660.html 使用代码大页。
后续展望
最后头脑风暴一下,代码大页也许还可以:
代码只读文件系统,专门用于放置 lib 库。
64kB、32MB 代码大页,接近特殊场景 2MB 代码大页无法使用的问题。
多种代码大页支持。
靶向代码大页。
从 iTLB miss 角度看,这些也许只能算是功能完善,并没有太大的性能优化。
参考:
阿里云 ECS 上使用代码大页说明:
https://help.aliyun.com/document_detail/462660.html
将 mysql 可执行文件的代码段和数据段加载到大页上:
https://jira.mariadb.org/browse/MDEV-24051
社区讨论:
https://sourceware.org/pipermail/libc-alpha/2021-February/122334.html
如何将自己的代码段和数据段映射到大页:hugepage_text.cc
MAP_DENYWRITE:被 Linux 内核屏蔽的 flag




