
如果你曾经管理过软件项目,你可能会问自己:我们团队如何才能更快地前进?现在前进的速度有多快?
面对这类问题,我们倾向于依赖指标。毕竟,我们在开发软件时经常并且已经成功地使用了指标。我们有性能、生产负载和运行时间指标,还有一些基于用户行为的指标,如转化率和留存率。这些指标不仅提供了可见性,更重要的是,它们创造了一个反馈循环。为了对一些东西加以改进,我们可以做出一个变更,并用指标来衡量改进的程度。开发者的智慧告诉我们,每一个软件性能优化都必须从指标开始。
既然指标如此有用,我们就不能把它们应用到软件开发速度中吗?既然更好的开发过程应该要给开发输出结果带来改进,那么输出结果指标应该就可以度量开发过程是否真正得到改进。那么,我们可以使用哪些指标呢?
在这方面,我们没有什么好的指标
开发速度是指单位时间内产出的工作量,所以我们需要同时衡量输出和时间。衡量时间很简单,但工作量如何衡量呢?工作量的衡量跟软件本身一样古老。多年来,每当我们决定用一个指标来衡量工作产出时,一些意想不到的事情就会出现。考虑以下这些例子:
代码行数——这可能是最古老的一种指标,但如今几乎没有人把它当回事。把代码行数作为衡量指标只会让代码变得臃肿,而且开发者只会专注于完成简单的任务;
提交次数——这样会鼓励开发者将代码提交分解为多个部分。同样,开发者会更关注简单的任务,避免去解决复杂的问题;
完成任务的数量——这样会导致任务被分割成更小的子任务。每一个问题,即使是小问题,都是作为任务提交的。这也会促使你走捷径,以最快的速度完成任务;
bug 的数量或 bug 的百分比——这不是工作输出指标,而是工作质量指标。这样会阻止开发者做出变更,并让他们不愿意报告自己发现的 bug;
工时或故事点数——当估算变成衡量团队表现的手段,那么很容易就可以猜到接下来会发生什么——夸大的估算;
……
开发者很聪明,他们擅长解决复杂的问题。对于指定的指标,他们都会找到最简单的改进方法,但很可能与工作质量或期望的项目结果不相关。但这并不意味着开发者就一定会这么做,我认为这取决于具体环境以及动机有多强。但有一件事是确定的——开发者将意识到他们的生产力衡量方式与重要的事情是相脱节的。这不仅令人感到沮丧,也会让他们在做真正的工作时分心。
为什么会这样?
为什么指标对于软件产品如此有效,而对于开发者的输出却不适用呢?这是开发者的阴谋吗?实际上,如果你观察一下软件开发之外的领域,你会发现更多例子,它们可以说明指标适用于哪些方面以及不适用于哪些方面。
指标适用的地方:制造和销售。以杯子的制造和销售为例。你可以测量产量(比如每单位时间生产的杯子数量)和质量(无法通过质检的不合格杯子的百分比)。在销售方面,你可以衡量销售额和利润率。这些指标对管理来说都非常有用。例如,制造部门的目标可以是提高成功通过质检的杯子的百分比,同时保持较低的单位成本。销售主管的目标可以是增加销量或提高利润率。这些指标的改进对业务是有好处的,因此我们也可以将其作为相应部门效率的衡量标准。
指标不适用的地方:科学产出。科学家们通过论文来发布他们的研究结果。现在科学界也有了一些衡量工作产出和质量的指标:发表论文的数量、被引用的次数、研究结果的统计学显著性。我们可以说发表 10 篇论文的科学家创造的价值是发表 5 篇论文的科学家的两倍吗?这是不太可能的,因为研究成果的价值是有差别的。即使不使用这些数字,通常也很难说哪项研究成果更有价值。因为论文数量和引文次数造假在科学界是一个众所周知的问题,它们并不被认为是衡量工作效率的可靠指标。统计学显著性也有问题——P 值篡改(p-hacking)是一个广泛存在的问题。
两个关键标准
在任何情况下,有效的指标都应该符合两个重要的标准:
它们与价值直接相关;
这些价值具有一致性,即可以用可互换的单位来表示,并具有可数的数量。
让我们来看看上面的例子:
制造和销售的指标符合这两个标准。在杯子的例子中,价值用杯子来表示。因为是大批量生产,所以杯子是一样的。在销售的例子中,价值是以美元来衡量的。业务目标是赚钱,所以钱与业务价值具有直接的关系。因为一美元可以等价其他任何一样东西,所以基于金钱的指标可以衡量恒定的价值。
科学产出的指标不符合这两个标准。我们找不到一个可以直接衡量科学研究结果价值的指标。我们只有间接的指标,比如论文和引用的数量,但这些都可能被篡改。无论如何,这些指标也不具有一致性,因为所有出版物都不是由可互换单位组成的。
开发者指标不符合这两个标准
我们需要用什么来衡量开发者的输出?代码行数、提交次数、完成任务的数量、工时、故事点数……如果将这些指标与上述两个关键标准对照一下,你会发现:
它们都与价值没有直接关系。我们不会向客户交付代码行数、工时或故事点数。他们不关心我们提交了多少次代码或完成了多少任务;
所有这些衡量结果都不具有一致性。这一次提交并不等于另一次提交,这一行代码的价值与另一行代码的价值不一样,所有的任务也都是不一样的,工时和故事点数都是估算出来的,具有不准确性。
毫无疑问,这些指标都不能很好地发挥作用。
为什么我们没有与价值直接相关的开发者指标?同样的,我们也没有给科学家用的指标。开发者就像科学家一样,总是在创造新的东西。他们不会一遍又一遍地写同样的代码——那样没有意义。代码可以被重用——可以将它们提取到模块或库中,或者直接复制粘贴。每个开发者的工作都是独一无二的。即使他们解决了相似的问题,也都是在不同的环境中或使用新的方法解决的。
是否有新的研究发现?
当然,现在没有人会真的用代码行数来衡量开发者的输出,但应该会有一些新的研究发现,对吧?
2018 年出版的“Accelerate”一书呈现了对 2000 个不同规模的组织进行研究的结果。研究的目标是确定哪些指标可以用来区分高绩效和低绩效。他们的发现如下所示:
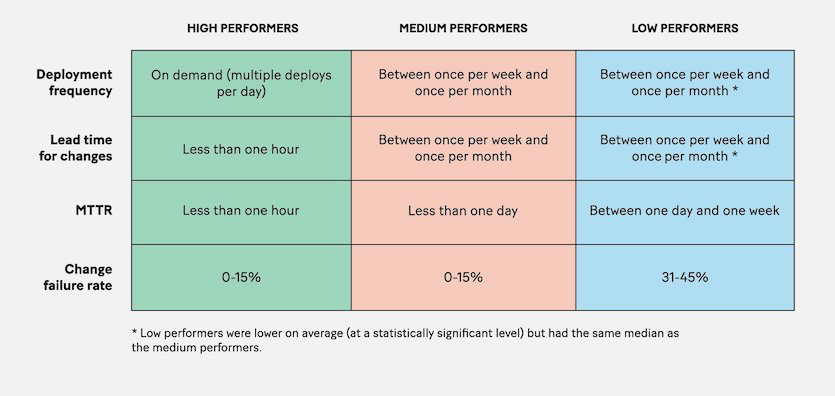
我们可以看到四个指标。接下来让我们来看看这些指标是如何与价值联系在一起的,以及它们是否具有一致性:
部署频率——我可以理解为什么它会出现在这里。你越频繁地交付,交付过程就越可靠。高效的团队往往更频繁地发布代码。然而,相关性并不一定意味着因果关系。部署频率与客户价值并没有直接的关系。人们想要一个能够满足他们需求的产品,而不是一个尽可能频繁变化的产品。这个指标也不具备一致性,因为一个变更并不等于另一个变更。
交付时间——满足客户请求的时间。这一点与价值更加靠近一些,但它不具备一致性,因为客户请求是不一样的,有些可能很简单,有些可能极具挑战性。
平均恢复时间(MTTR)——发生故障后恢复的速度。当软件出现故障时,客户会不高兴,所以这个指标与价值是有关系的,但也有不好的地方。首先,它没有考虑到故障频率。如果软件经常出现故障并迅速恢复,尽管指标看起来不错,但客户仍然会不满意。第二,它不具备一致性,因为各种故障也是不一样的。如果是整个系统出现故障,那就很严重了。如果只是一个小功能不能正常工作,大多数客户可能不会注意到。
变更故障率——导致故障变更的百分比。如果是用户自己安装的更新,那么这个指标确实与价值有关。如果用户在安装更新时体验不佳,他们就会害怕安装后续的更新。对于 SaaS 产品,这种关系就不那么直接了,因为客户不太关心服务为什么出现故障,可能是由于变更,可能是你的一个供应商出了问题,可能是服务无法处理负载,或者是服务受到了攻击。不管是什么原因,如果服务不正常,顾客都会不高兴。这个指标也不具备一致性,因为一个变更不等于另一个变更。有些变更是微不足道的,有些则可能很重要。
底线——所有四个指标都不具备一致性,而且并不总是与价值有直接关系。如果尽可能频繁地发布一些不重要的变更,那么除交付时间之外,其他指标看起来都不错。
至于交付时间,即使我们忽略了它不具备一致性的事实,将这个指标作为目标会导致我们优先考虑客户的简单请求,却忽略了客户没有说出的请求。这通常包括重构、测试和所有其他客户没有考虑到的改进。
这就是为什么我不推荐使用这些指标作为开发目标。
或许我们可以找到更好的指标?
你可能会说:等等,虽然我们还没有找到好的指标,但这并不意味着它们不存在,人们很聪明,他们会找到更好的方法。但我恐怕他们是找不到的。我们找不到好的开发者指标是有根本原因的。好的指标应该满足两个关键标准:
它们与价值直接相关;
它们具有一致性,即基于某些相等值的可数数量。
我们不能直接度量开发者的输出,因为他们的产出结果总是不一样的。每个任务和项目都有独特的要求,所以不存在重复的结果。如果没有重复的结果,就没有一个可靠的度量基础。我们所拥有的只是间接指标,这些指标并不总是与价值相关,将它们作为目标最终带来的伤害将大于好处。
无法被度量的东西可以得到改进吗?
指标很方便,因为它们为我们提供了一个反馈循环——你可以了解你做出的改变是否改进了某些东西。如果没有指标,反馈循环就不会那么简单了。有时候你甚至会觉得自己像瞎子一样。彼得·德鲁克有句名言:
如果你不能度量它,就不能管理它。
但这不是真理。根据德鲁克研究所的说法,彼得·德鲁克并没有幻想可以为所有事情找到一个度量标准。事实上,他从来没这么说过。并不是所有重要的东西都可以被度量,也不是所有被度量的东西都很重要。
没有好的指标并不意味着我们不能提高开发速度。有些公司的软件开发速度肯定比其他公司更快,而且不会因为速度更快而导致质量下降,因此,改进是可能的。
底线
你可以并且应该使用指标来改进软件产品。你可以考虑使用性能指标(如延迟或 CPU 负载)、可靠性指标(如正常运行时间)和用户行为指标(如转化率或留存率)。
但是,当你想要提高软件开发速度,不应该依赖指标,因为我们没有合适的可用指标。我们可以度量很多东西,但不幸的是,我们可以度量的所有东西都与价值没有直接联系,或者没有足够的价值一致性,或者两者都不具备。如果你基于这样的指标设定目标,就不会有什么好结果。
原文链接:




