
Airflow 作为一款开源分布式任务调度框架,已经在业内广泛应用。本文总结了 Freewheel Transformer 团队近两年使用 Airflow 作为调度器,编排各种批处理场景下 ETL Data Pipelines 的经验,希望能为正在探索 Airflow 的技术团队提供一些参考价值。
为什么选择 Airflow?
FreeWheel 的批数据处理使用场景主要分成两种,一种是固定时间调度的 ETL pipelines , 比如 hourly、daily、weekly 等 pipelines,用于日常数据建仓;另一种是没有固定调度时间的修数据 pipelines 。
ETL pipelines
基于业务的不同使用场景,有很多流程不同的 ETL pipelines。这些 pipelines 可以设置不同的 schedule mode:hourly、daily、weekly 等。各种 pipelines 协同工作可以满足数据业务方不同粒度的数据建仓需求。
修数据 pipelines
无论是系统服务还是数据服务,Design For Failure 是一个重要的原则,也是我们在实践过程中必须考虑的。遇到错误的配置、代码缺陷等问题,可能会导致已经发布的数据需要重新计算和发布。这种情况往往需要处理的 batch 会很多,如果在原来的 ETL 上操作的话,会影响日常 pipelines 的运行和资源分配,因此修数据 pipeline 需要设计成独立运行的,专门用于处理这种情况。
针对以上应用场景,我们在 pipeline scheduler 选型之初调研了几种主流的 scheduler, 包括 Airflow、Luigi、AWS Step Function、oozie、Azkaban,主要从易用性、扩展性、社区评价和活跃程度进行了综合调研评估和体验。得益于 Airflow 自带 UI 以及各种便利 UI 的操作,比如查看 log、重跑历史 task、查看 task 代码等,并且易于实现分布式任务分发的扩展,最后我们选择了 Airflow。
Airflow 架构
下图是 Airflow 官网的架构图:

Airflow.cfg:这个是 Airflow 的配置文件,定义所有其他模块需要的配置。例如:meta database、scheduler& webserver 配置等
Metadata Database:Airflow 使用 SQL Database 存储 meta 信息。比如 DAG、DAG RUN、task、task instance 等信息。
Scheduler:Airflow Scheduler 是一个独立的进程,通过读取 meta database 的信息来进行 task 调度,根据 DAGs 定义生成的任务,提交到消息中间队列中(Redis 等)。
Webserver:Airflow Webserver 也是一个独立的进程,提供 web 端服务, 定时生成子进程扫描对应的 DAG 信息,以 UI 的方式展示 DAG 或者 task 的信息。
Worker:Airflow Worker 是独立的进程,分布在相同 / 不同的机器上,是 task 的执行节点,通过监听消息中间件(redis)领取并且执行任务。
更多详细信息可以参阅 AirFlow 官方文档。
Airflow 实践总结
Data Pipelines(同 Airflow DAG)是包括一系列数据处理逻辑的 task 组合。Data Pipeline 不仅要实现 Extract-Transform-Load(ETL)数据, 而且要做到自动扩/缩容,完善的报警和容错机制。
我们对 pipelines 的要求:
稳定高效:稳定高效是对生产环境 pipeline 最基本的要求。 稳定主要是指保证数据的正确性,高效主要是指能够保证数据处理的时效性。
易于扩展: 我们的业务特点是处理小时级别的 batch 数据。每个小时的数据量大小从几十 G 到几百 G 不等,所以 pipeline 可以根据数据量大小可以自动的扩/缩容量,方便地实现分配资源调节的目标。
易于维护:搭建在 AWS EMR 上的数据 pipeline,为了最大程度减少 AWS Cost,我们选择使用 Spot Instances。折衷考虑 pipeline 人工干预或者维护的成本,就需要及时报警、自动恢复以及容错的能力。
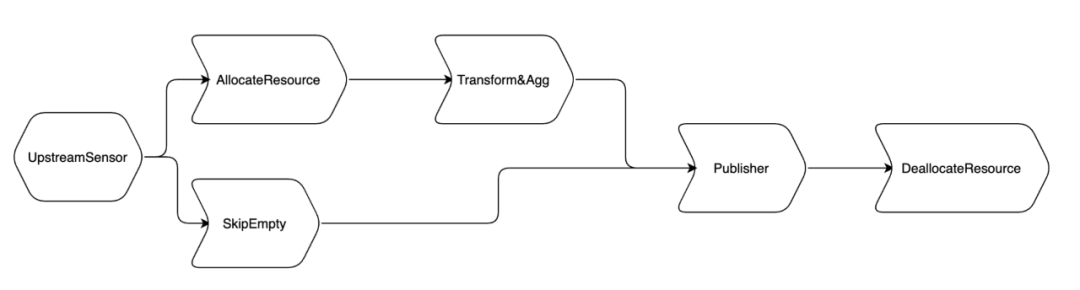
FreeWheel 所有的 pipeline 搭建在 AWS EMR 环境中。结合业务的应用场景,我们所需的 pipeline 主要功能包括:等待上游数据 ready ,根据上游数据大小动态计算分配 AWS 资源,Transform&Aggregate 上游 batch 数据,Publish batch 数据和回收 AWS 资源 。
为了满足需求,最初的 ETL Pipeline 设计如下图:

1 最大化实现代码复用
遵循 DRY 原则:指不写重复的代码,把能抽象的代码抽象出来,尽管 pipeline(DAG)的实现都是基于流程的,但在代码组织上还是可以利用面向对象对各个组件的代码进行抽象,减少冗余代码。
由于业务需要,我们有各种各样的 pipelines。我们分析抽象了不同 pipeline 的各个模块的异同,提取相同部分,对不同的部分进行了不同实现。具体来说,不同 pipeline 虽然特性完全不一样,但是相同点是都是数据的 Extract & Transform & Load 操作,并记录 track 信息, 并且都是运行在 AWS EMR 上的 SPARK jobs。在实践中,我们发现很多模块的 task 有可复用的流程。由于 Airflow DAG 是面向过程的执行,并且 task 没办法继承或者使用 return 传递变量,但是代码组织结构上还是可以面向对象结构组织,以达到最大化代码复用的目的。
比如 Task A 和 Task B 是对不同的数据源进行 transform 操作, workflow 可以抽象为准备工作、执行工作、tracker 及 teardown。如果 Task A 和 Task B 的执行工作不一样, 只需要在子类中分别实现两种 task 的执行过程, 而其他准备工作,tracker, teardown 是可以在基类中实现,所以代码依然是面向对象的实现方式。
2 保证 pipeline &task 幂等性可重试
由于业务特性和 AWS spot instances 被回收的问题,经常会有 task 需要 rerun 的情况,基于这样的前提,我们要保 task 和 pipeline 都是要幂等可重试。如果 pipeline 上的任意 task 失败都可以自动或手动进行重试,不需任何额外的步骤,则整条 pipeline 也是幂等可重试。
DAG 幂等如何定义每个 pipeline 需要处理的 batch_id?保证 pipeline 幂等可重试呢?
方案 1 : 判断上游处理 latest_batch_id 是否等于已经处理过的最新 batch_id, 如果新于处理过的 batch,则这个 latest batch 为 pipeline 本次运行需要处理的 batch_id, 否则继续等待上游更新下个 latest_batch_id。
方案 2 : pipeline schedule mode 是 hourly 情况下,AirFlow 计算出的 DAG.execution_date, 进而演算出 batch_id。
最终我们选择了方案 2。方案 1 的问题在于每次处理的时候 batch id 需要依赖历史上处理过的最新 batch。如果 rerun 处理过的 batch 则会得到和 pipeline 运行时不一样的结果。而采用方案 2 的好处是每次 pipeline 执行的 batch 都是固定的。不依赖任何其他状态文件或者状态变量,保证无论何时 rerun pipeline 的某次执行(DAG RUN)都是处理一样的 batch。
Task 幂等 Task 也不会保存任何状态,也不依赖任何外部的状态,这样反复 re-run task 也会是得到一样的结果。因此 track database 只是存储状态信息,并不会被 task 使用或依赖。例如 publish task,非首次跑的时候需要先清理之前 publish 过的数据,通过 Airflow 提供的接口 context["task_instance"].try_number 来判断是否是首次执行 task, 在 task 中实现这样的判断逻辑,就可以实现是否需要清理之前 publish 过的数据的逻辑,进而保证 task 本身是幂等的。
3 保证 pipeline 鲁棒性
上述 pipeline 完成了基本功能,为了增加鲁棒性,我们增加了下面的功能:
增加了上游 batch 空数据判断逻辑,skip 掉所有下游的 task,节约使用的 AWS 资源。我们使用了 branchOperator,增加了 skipEmpty(DummyOperator) task 来处理整个 batch 空数据的情况。节省几个 task 执行的时间。注意一点,publish 是必须要走的,因为需要更新 api。这因为发布空数据和没发布还是有区别的。
根据各个 task 的本身特性,增设了 DAG&task 级别不同的 retries,实现了 DAG&task 级别的自动 retry/recover。
4 灵活使用各种 Callback & SLA & Timeout
为了保证满足数据的质量和时效性,我们需要及时地发现 pipeline(DAG)运行中的任何错误,为此使用了 Airflow Callback、SLA、Timeout 功能。
on_failure_callback&on_retry_callback&on_success_callback &reties:在 DAG 和 task 级别都可以设置参数, 这样的设置可以实现 task 的自动的 retry 和 task 成功/失败/重试的自动通知, 可以及时发现问题并且自动重试。
SLA & Timeout:SLA 是相对 DAG_RUN execution date 的。timeout 是相对 task instance 的 start time。 合理利用这两个参数,可以保证实现 pipeline 及时性的监控。需要注意的是 Airflow 1.10.4 在是用 SLA 对 schedule=None 的 DAG 是有问题的, 详情AIRFLOW-4297。
5 保证 pipeline 并发时的正确执行顺序
没有多个 batches 并发跑的时候,pipeline 执行顺序是没有问题。但是如果多个 batches 并发执行,有没有可以改善的空间呢?
当两个 batch 同时执行时,因为需要共享 EMR 资源,每个 batch 要都先申请 AWS 资源,执行任务后回收资源,两个 batch 可以通过优化执行顺序来节约 AWS 费用。比如两个 batch 都执行之后一起回收资源,而不是各自申请自己的资源然后分别回收。
公司业务方对 batches 之间的执行顺序是有要求的,即需要保证 batch 按照时间顺序来对下游发布。
Airflow 默认情况配置中,pipeline 上 weight_rule 设置是 downstream,也就是说一个 task 下游的 task 个数越多。priority_weight 越大,那么优先级越高。所以执行效果如下图,即优先执行上游 task,也就不能保证早 batch 优先执行。
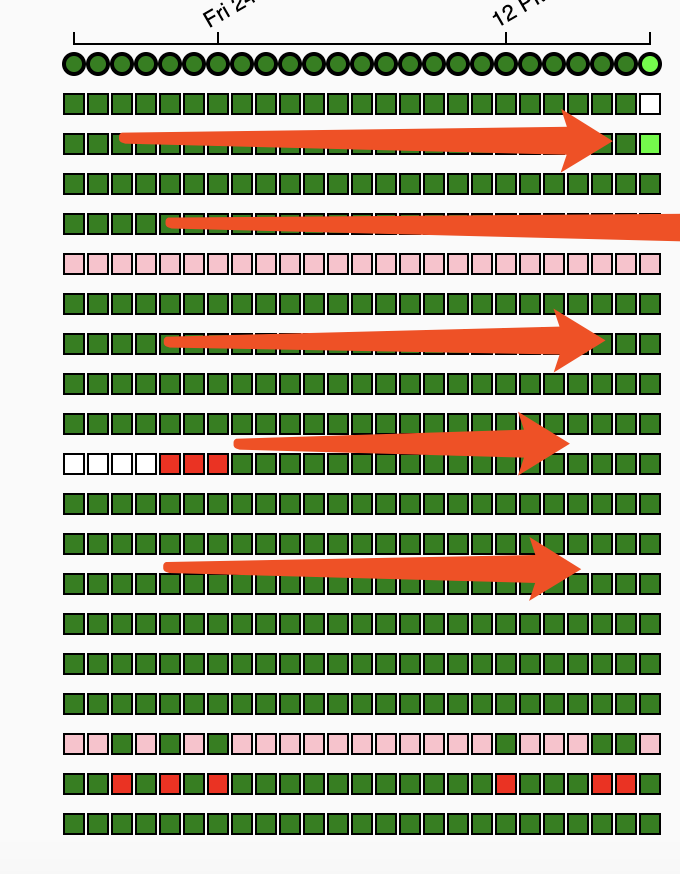
一列代表一次 pipeline 的执行过程,即 DAG RUN
如果改成 upstream(即一个 task 的上游越多,它的 priority_weight 越大,优先级越高),执行效果如下图,执行中会把早 batch 执行完,晚 batch 稍后执行。

基于业务方的需求,pipeline 希望执行顺序是 upstream mode, 这样可以尽早发布早 batch。但是会造成 AWS EMR 资源必须先回收后申请,带来时间和费用的浪费。所以这个问题不能够通过简单的 Airflow 配置来改变。需要修改一下申请资源 task 和回收资源 task 来传递一些信息。 比如在回收资源的时候的时候发现有 batch 等待申请资源那么就不执行回收。
如此结合的方式,可以实现:早 batch,早发布,有 batch 等待的时候不用回收资源,来节约 cost 的同时保证发布顺序。更多关于 EMR 使用的细节,详见《“榨干”EMR开销!AWS EMR在搭建大数据平台ETL的应用实践》。
6 安全与权限管理
Airflow 是一个公用组件,各个团队都可以部署自己的 pipeline 到公共的 Airflow。这种情况下,权限管理就尤为必要了。
我们采用了 LDAP + Muti-Tenant 的方式来管理团队在 Airflow 的权限。
需要实现的功能 :Admin & RW & RO 账户, 可以将读写权限分离定义 Pipeline Owner Group,pipeline 只对 Owner Group 内人员可见,Owner group 信息可能随时更新人员信息多个 Pipeline 可以拥有变动 Oncall Group 并授权只读权限, Oncall Group 也会随时更改
方案 :使用 Airflow RBAC 管理权限,提供 Admin User, Op, Viewer 和 Public 权限分离;利用 LDAP Group 划分 pipeline owner group, pipeline 对 LDAP group 人员增删改透明, 不需要额外的操作维护 group 和人的对应关系。定义 variable 存储 On-Call 名单,可以通过 Airflow UI 随时修改。
针对这个方案,我们重新实现了 AirflowSecurityManager, 将上面三种逻辑进行了封装。
7 修数据 pipeline 的解决方案
经过了反复几轮迭代演进,ETL pipeline 最终能稳定运行了。但是我们的需求又来了:如果需要对历史数据做重新处理?这样的 pipeline 还能否胜任呢?
由于 ETL pipeline 的 task 都是原子性的,也就是说任何时间去 rerun task 都是能拿到相同的结果的。所以当重新处理,是可以直接 clean 已经跑过的对应 batch 的 DAG RUN 的。
上述解决办法在只需要重新处理历史上少数 batch 的情况下,是没有什么问题的。但是如果处理成百上千的 batches 呢?是不是就会影响正常的 pipeline 执行了呢?
针对以上的问题,我们需要扩展 ETL pipeline,即需要一个 DAG 能够处理多个 batches,并且与原有的 ETL pipeline 相互隔离。虽然修数据 pipeline 是一个 DAG 处理多个 batches,但每个 batch 执行的过程和 ETL pipeline 都是一样的。 仅仅有以下区别:
修数据 pipeline 需要处理的 batches 需要外部传入。
修数据 pipeline 需要可以支持多集群并发的处理,加快数据发布速度。
为了解决以上两个问题,我们开发了 DAG Generator 工具,同时把 ETL pipeline 抽象成了模板, 通过这个 DAG Generator 指定处理的 batch 的范围就可以生成修数据 pipeline,并且动态计算分配 queue 和 pool 实现多集群的并发处理。
遇到的问题
分布式与代码同步问题
Airflow 是分布式任务分发的系统, master 和 worker 会部署在不同的机器上,并且 worker 可以有很多的类型和节点。 当 master 与 worker code 不一致时,会引入一些奇怪的问题,所以需要解决分布式系统中代码升级与同步的问题。
为了解决 code 一致性问题, 我们引入了 efs 作为代码存储。所有的 worker&master 都 mount 到相同 efs。经过实践,code 同步和部署的问题都能迎刃而解。
Customized Operator
Airflow 原生的 Operator 十分丰富,我们可以根据自己的使用场景去丰富实现需要的 Operator。如下图:
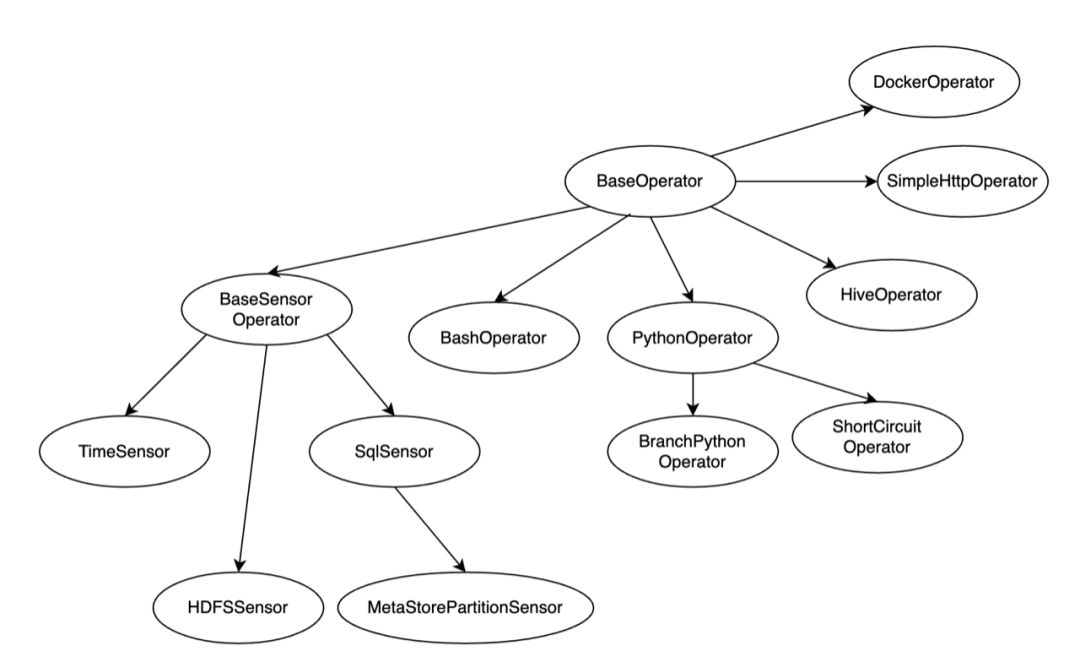
比如,我们的应用场景中,有一种场景是需要轮询上游 API,如果上游 api 同时发布多个 batch 的数据,我们只需要执行最新的一个 batch, 这种行为类似将 Sensor 和短路行为结合在一起,没有现有的 Operator 可以使用。所以我们实现了定制化的 Operator,实现了业务场景的需求。
Scheduler Hang
我们使用的 Airflow 版本是 1.10.4,scheduler 并不支持 HA。在实际使用中,Airflow scheduler 和 meta database 是单点。为了增加系统的健壮性,我们曾经尝试过给 database 加上 load balancer。然而遇到 hang 的问题,经过反复的 debug, 我们遇到的 hang 是来自于 SQL Pool(sqlAlchmy)维护的 connection pool 和 database load balancer 的冲突。基于这种分析,通过直连 Database 解决了 scheduler hang 的问题。
实践成果
经过几轮的迭代改进,目前 Airflow 集群可以支持多条 ETL pipeline,能自适应处理 300 多 G 的数据量,最大化利用 Airflow 特性自动 retry,配合合理的报警通知,目前在较少人力成本下,已经稳定运行超过 2 年时间,并没有发生故障。自动化修数据 pipeline 也能够有力支持多种修数据的方案。
此外,团队搭建了自动生成 DAG code 的工具,可以实现方便快捷创建多条相似 pipeline。
在安全认证和权限管理的保障下,Airflow 平台已经被公司内部多个团队采用,使得 AWS 资源的利用变得更加合理。
值得一提的是,2020 年 Spark3.0 版本发布,经过组内调研分析和性能测试,Spark3.0 AQE 的特性给我们 pipeline 带来了高达 40%的性能提升。更多信息请参考《Apache Spark 3.0 新特性在 FreeWheel 核心业务数据团队的应用与实战》。
未来展望
接下来我们会根据项目的安排,调研 Airflow2.0 特性,继续丰富完善各种 pipeline ,期待能够搭建更稳定、更智能的 pipelines。
作者介绍
董娜,高级工程师,毕业于北京邮电大学,目前就职于 Comcast FreeWheel 数据产品团队,主要负责广告数据平台数据仓库的建设。
想要了解更多 Spark 和 EMR 相关实践,请参阅团队其他文章:




