
近些年,各家公司都在不断推出各种新的 App,百万 DAU 成为各种 App 的最基本目标。本文将详解如何通过大规格服务器 +K8s 的方案简化这些新项目的成本评估、服务部署等管理工作,并在流量增长时进行快速扩容。同时,本文还介绍了微博核心业务采用此方案部署时遇到的问题以及对应的解决方案。
问题与挑战
以一个常见的社交 App 后端服务为例,如果采用主流微服务架构进行设计,通常会包含用户、关系、内容、提醒、消息等多个模块;每个模块又会分别包含各自的 Web 接口服务、内部 RPC 服务、队列处理机等几部分;同时为了保证高可用,通常每个模块还需要部署 2 个及以上的实例,算下来仅部署上述列出的应用服务就超过 30 多个实例。而对于依赖的数据库和缓存,甚至每个业务功能都需要部署独立的实例,若再考虑读写分离、预留分库分表等,则 App 上线前需要部署的数据库和缓存实例可能多达上百个。
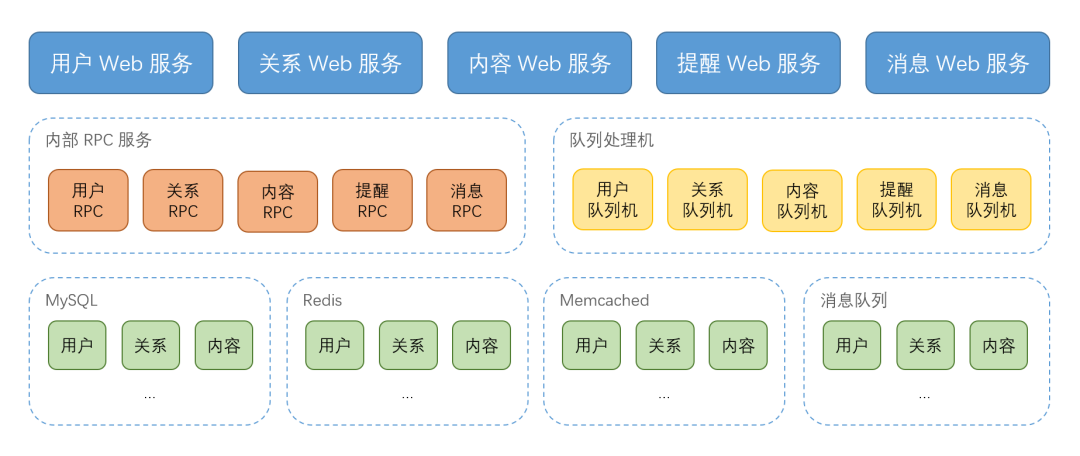
(常见的社交 App 后端架构)
对于上述这样一个典型的 App,如果采用传统的部署模式,则需要使用至少数十台服务器才能满足部署数十个应用服务实例以及上百个数据库和缓存实例的需求。若要对整个服务占用资源情况进行全面了解,或是对整个服务进行翻倍扩容,则还需要梳理清楚各个服务的依赖和部署情况,管理复杂度高。
而如果还要进一步提升服务器的利用率,可能还需要使用不同规格的服务器部署不同的实例,或是将新的实例与其他业务或者已有集群混部。在这种情况下,不论是服务部署、成本评估还是扩容缩容都变得相当困难,甚至连 App 下线时都需要做很多盘点和梳理工作才能完成。
用一台服务器解决问题
对于任意一个业务,显然其使用的服务器规模越小、使用的服务器规格越少、提供和依赖的服务数量越少,其服务部署、成本评估以及扩容缩容就会更加容易。而对于一个新业务的后端服务,若其提供和依赖的服务数量没办法减少的话,减小服务器的规模、减少使用的服务器规格也是一种解决问题的方法。
选择合适规格的服务器
在使用 Kubernetes 之前,出于运维复杂度的考虑,单台服务器常常只部署一个服务。而由于各自成本的原因,公司在为自建 IDC 采购服务器时通常都会指定标准规格的服务器,云厂商在为大家提供服务器时也是按预先设定的规格来提供。所以,不论是业务的应用服务还是数据库、缓存等资源,往往都是选择能满足需求的最小实例,这也就导致了业务需要大量不同规格的服务器,提升了管理的复杂度。
尽管如此,业务的应用服务或者数据库、缓存资源的单个实例还是很难将单台服务器完全用满。导致这种现象的原因很简单,即需求的服务器规格与实际提供的服务器规格不一致。
举个例子,服务器厂商与云厂商提供的服务器的 CPU 核心数(指超线程后的核心数,下同)与内存容量(GB)的比例(以下简称“CPU 与内存比”)通常在 1:2 - 1:8 之间,如果业务实例不进行混部,在实际使用过程中通常会遇到如下情况:
需要的 CPU 与内存比过小。很多服务会通过使用大量缓存来支撑更多流量,单个用途的缓存经常需要 10GB 甚至数十 GB 不等的内存空间,而支持每秒数千甚至数万的缓存请求可能只需要 1 个 CPU 核心,需要的 CPU 与内存比能达到 1:16 甚至是 1:32。
需要的 CPU 与内存比不标准。对于应用服务来说,由于各业务实现逻辑均不相同,需要的 CPU 核心数和内存可能不尽相同,例如 6 核 8GB、8 核 12GB、12 核 16GB,而即使将多种不同的规格合并标准化后也可能会出现 1:1.33 或是 1:1.5 等比例。
诸如上述 CPU 与内存比是 1:1.33 或 1:32 的非常规比例,服务器厂商或云厂商通常都不会提供。
虽然不同服务对 CPU 和内存的需求不同,但一个业务所需的 CPU 与内存的总和是确定的,所以我们可以据此选择更大规格的服务器,然后再切分出各个服务需要的规格。
切分的方式也有很多,以往通常会采用虚拟化的方案进行切分,但虚拟化也伴随着额外的性能及资源开销,Hypervisor、Guest OS 等等都需要消耗额外的 CPU 和内存,在虚拟机中运行应用的性能也比在宿主机中直接运行的性能要差一些。容器的出现使得大家有了更轻量级的服务隔离方案,减少了因虚拟化带来的 CPU 和内存开销,而 Kubernetes 的出现又使得容器的编排、调度和部署变得更为容易。
通过 Kubernetes 将不同的缓存、数据库、应用服务进行搭配混部,很容易就能将单台服务器的 CPU 和内存都充分利用起来。而通过搭配选择多种 CPU 核心数与内存比的服务器,又能满足业务对计算资源和内存的不同需求。
以微博为例,我们的新 App 后端服务由数十个 Java 应用实例构成,使用了数百 GB 的 Memcached、Redis 等缓存,最终我们选择了一台 104 核 768GB 内存的云上裸金属服务器,单台服务器就可以满足整个业务的需求。
可用性的问题
与传统将服务部署在多台小规格服务器中不同,将全部服务部署在几台大规格服务器甚至单台服务器上,可用性会明显降低。当单台服务器出现故障时,影响的不再是某个服务或是 App 中的某个功能,而是整个 App。
业务对服务可用性的要求一定是随着业务重要性提升而不断提高的。在业务初上线时,双机互备或单机 + 快速迁移的模式都是可选的方案。但随着业务不断发展,对可用性的要求会不断提升。与此同时,伴随着业务发展和服务规模扩大、业务需求与功能不断迭代,应用服务、数据库以及缓存的种类和数量也会不断变多,一定会出现单台服务器无法部署所有服务的情况,各个服务实际需求的资源和数量也会变得与最初不同。届时,我们需要根据资源的实际需求重新分配和部署资源,这在一定程度上能够降低单台服务器故障对整体的影响。
快速翻倍扩容
在 App 刚上线时,流量的增长并不总是呈线性增长的,很多时候会受用户传播或推广等因素影响而出现增长速度明显加快甚至流量翻倍的情况。同时,由于新 App 存在不确定性,也不会像公司里已有的成熟 App 那样,能够比较容易地预判接下来的流量情况。所以对于一个新 App 而言,更需要能进行快速和全面的扩容。在新 App 用户量快速上升的阶段,快速翻倍扩容是最有效也是最稳妥的手段。
与传统分散部署的方式相比,单台集中部署的方式能让我们更清晰地了解整个服务所需的服务器资源。以这种方案进行部署时,翻倍扩容仅需要将之前服务器上部署的所有服务在新服务器上再部署一次即可。其中根据服务的不同类型,主要分为以下三种情况:
无状态的服务,如业务自身的 Web 服务、RPC 服务、队列处理机等,只要配置好上游的负载均衡或者配置好对应的服务发现即可。
有状态但自身提供主从同步的服务,如 MySQL、Redis 等数据库或缓存,可以通过其自身的主从同步机制进行相关的同步并完成从库的搭建。
有状态但自身不提供主从同步的服务,如微博使用最广泛的 Memcached 缓存,其自身并没有提供主从、分片以及高可用等逻辑。微博以 Memcached 为基础提供了 Cache Service 服务,在 Cache Service 内部实现了主从、分片和高可用的逻辑,在业务自身的队列处理机中对 Memcached 的各个实例进行数据同步。
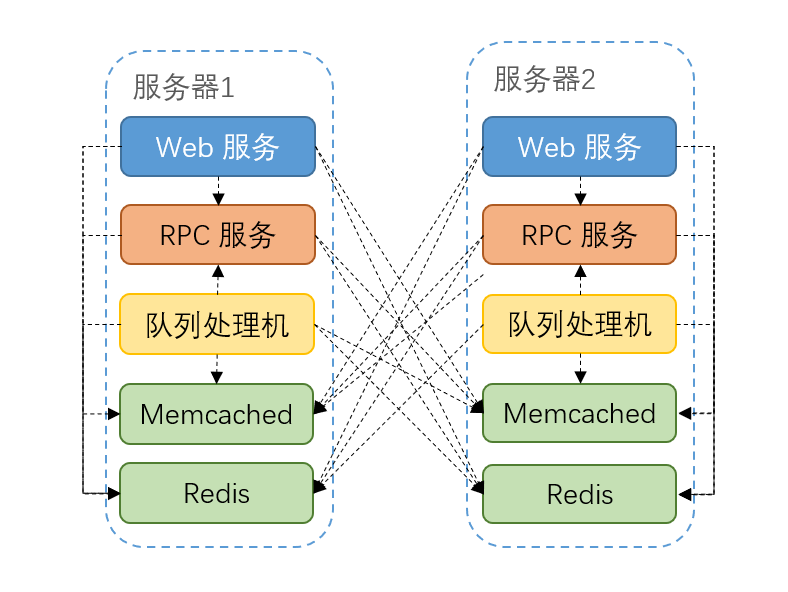
(服务器翻倍扩容后的调用关系)
按照翻倍扩容的方式,App 上线前期能够及时支撑 App 流量的快速增长,同时让物理服务器数量依旧维持在较少的规模,管理复杂度依然维持在较低的水平。
新的挑战
最初使用这套方案时,我们选择了 104 核 768GB 内存的云上裸金属服务器,虽然 App 的 DAU 超过百万,但是 Web 服务的每秒接口请求量并不多。不论是 Web 服务、RPC 服务还是缓存等部署的实例个数都是根据最小规模部署个数确定的,与实际流量相比,压测值的吞吐量要数倍于日常流量,整体运行一直也比较平稳。
后来我们部署了更大规模的集群,在服务器选型上也选择了单台规格更大的 AMD 256 核 2TB 内存的服务器。随着我们将核心业务迁到了新的集群中,出现了比较明显的业务抖动问题。
绑核策略的优化
与 Intel 的机型相比,AMD 的服务器虽然也是 2 个 Socket,但由于 CPU 架构设计原因,实际上有 8 个距离不同的 NUMA 节点,跨 NUMA 访问的开销相比之前变大了。同时,由于部署了更多负载更高的业务,最早不绑核只限定 CPU、内存使用量的方式,也导致 CPU 调度的开销也变得更大。
我们在大规模部署和使用的时候分别经历了 3 个阶段:
所有容器不绑核,仅限定 CPU、内存使用量;
在线应用容器绑核、缓存容器不绑核;
在线应用容器绑核、多个缓存部署在同一个绑核的容器里。
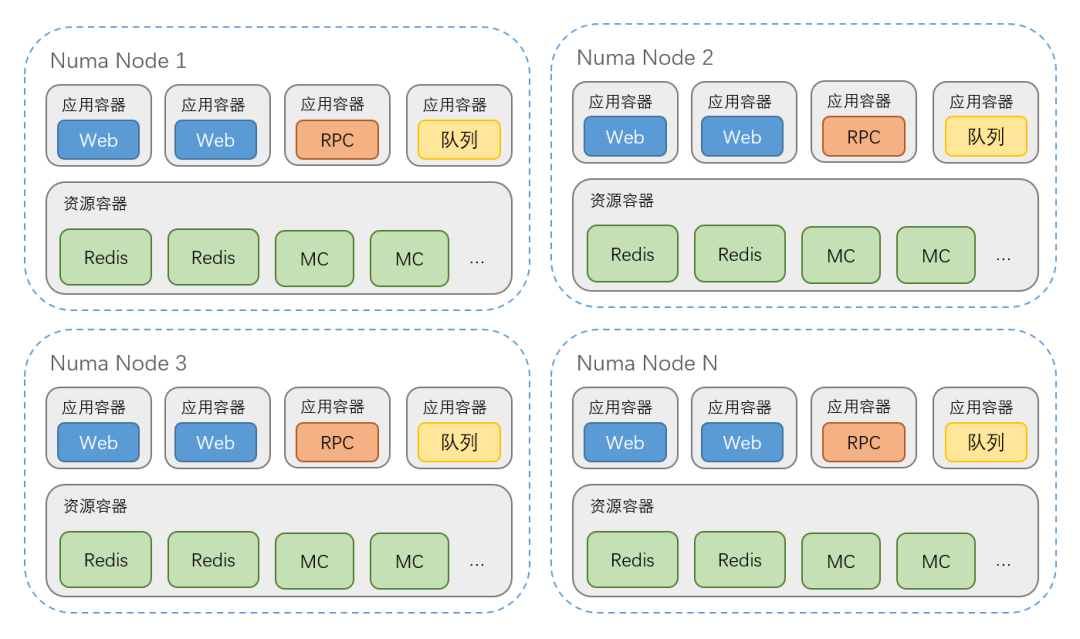
(单台物理机中容器部署架构)
由于 Redis、Memcached 等缓存对 CPU 资源消耗较少,很多缓存实例甚至都用不满 1 个核心,我们将多个缓存部署在同一个绑核容器中集中管理。当我们对在线应用服务和缓存等资源都进行了绑核后,业务抖动问题得到了解决。
除了解决了业务性能抖动的问题外,这种绑核策略也降低了管理的复杂度。在宿主机使用了 lxcfs 后,容器内 CPU 与内存等的监控也接近于原有使用物理机或 ECS 的方式。
调用链路的优化
随着部署了更多的核心服务,通过网络对各种 RPC、缓存的请求数量也逐渐增多,从单台服务器来看,网络请求所带来的开销也越来越大。对于需要大量网络请求 RPC、缓存的服务而言,如果能显著减少网络的请求,就能显著减少接口的耗时。
在以往的部署模式下,由于各个 RPC、缓存等都是独立进行部署的,并没有有效的方式减少网络请求的开销,唯一能做的就是尽可能让请求就近访问。
而当我们使用的单台服务器规格达到 256 核 2TB 内存时,我们发现可以在单台服务器上部署 16 个 12 核的在线应用服务或是 24 个 8 核的在线应用服务或是 32 个 6 核的在线应用服务,单台服务器能塞下的实例数量甚至比用 16 核 1U 的服务器装满一个机架时塞的还多。在这种情况下,如果部署的服务之间有相互依赖关系,就有必要对部署服务的编排方式、路由或是负载均衡策略进行优化,使相互依赖的服务尽可能同机部署,调用依赖的服务尽可能同机访问。
除此之外,以往为了减少跨网络的数据传输量和传输时间,通常还会对跨网络的服务请求和响应数据进行压缩。这种方式虽然降低了网络开销和整体请求耗时,但也增加了请求双方的 CPU 负载,并增加了一定的耗时。
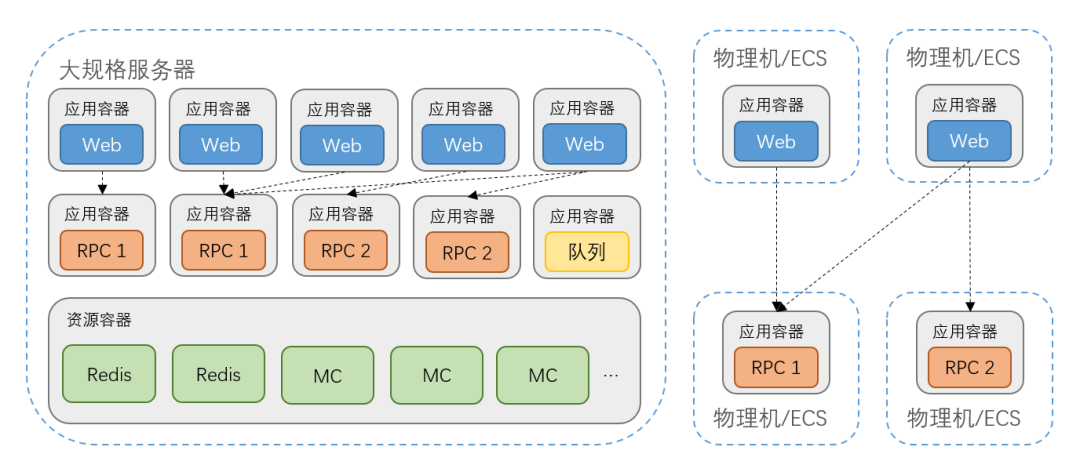
(优先调用同机内提供的服务)
我们基于新的部署方式调整了部署后的负载均衡策略,在已有的负载均衡策略之前增加了一层本地优先策略。在 RPC 调用负载均衡策略时判断目标实例列表中是否有本机部署的 Pod 的 IP,如果有则优先访问。同时,由于本机内部的调用并没有产生跨网络传输的开销,我们取消了对这种请求及其结果的压缩,进一步降低了请求耗时。
在实际线上对比测试时,我们发现,很多耗时短、结果简单的 RPC 接口,在采用了新的部署方式和负载均衡策略后,平均耗时比之前单独部署时还能降低 2ms 及以上。而当单个请求流程中需要跨网络调用更多种类和次数 RPC 的时候,整体平均耗时还能下降更多。例如我们很多接口在一次请求中需要调用不同的 RPC 接口数十次,从接口整体响应耗时来看,能降低 10ms - 30ms,接口整体耗时能下降 10% - 30%。
后记
正如前文中所述,目前我们搭建的 Kubernetes 集群使用的物理机规格主要以 256 核 2TB 内存的服务器为主,包括微博核心业务在内的很多在线应用服务和 Redis、Memcached 缓存等也已经稳定运行在这个集群中。在这种规格的服务器上,由于单机可以部署更多数量和类型的服务,借助基于本地优先调用的负载均衡策略,部分核心接口的平均耗时和 P99 时间相比传统的部署方式,还下降了 10% 以上,在日常流量低的时间段甚至能下降 30%。
而且,由于扩大了集群中的物理服务器规模,单台物理机对单个服务的影响已经非常低。同时,伴随着之前文章所述的数据恢复中心的使用,即使有状态服务所在的物理机宕机,也可以在短时间内将实例重新迁移到集群中其他宿主机上,快速重新部署、快速恢复,进一步减少对业务的影响。
作者简介
孙云晨,微博基础架构部业务改造负责人。2015 年加入微博,参与并负责微博多个业务系统架构升级改造工作。目前主要关注资源服务化及业务研发效率的提升。
系列文章推荐:




