
本文整理自百度云智峰会上的主题演讲《工商银行 Serverless 函数计算落地实践》,工商银行软开云计算实验室的高级经理周文泽分享了工行使用百度函数计算产品的落地过程。
工行云平台从 2012 年开始建设,基于业界领先云产品和主流开源技术,结合工行特色实现了金融级的自主定制研发和加固。
2012 年:基于服务器虚拟化软件,自主研发和推广第一代基础设施云
2015 年:率先于同业首家基于开源 Docker 容器技术、微服务,建设应用平台云,并在生产运用
2016 年:完成互联网金融高并发场景的试点并顺利支撑快捷支付“双 11”大促、鸡年贺岁币云上发行
2017 年:基于 OpenStack、Ceph 等业界开源技术,建设新一代基础设施云;同时基于 Kubernetes,建设企业级应用平台云 PaaS 2.0
2018 年:金融生态云 SaaS 上线,启动 Serverless1.0 自研工作
2020 年:建设新一代云平台建设,包括分行云,与此同时也是启动了 Serverless2.0 相关的规划研究和建设工作。
工行云平台包含如下四个方面的技术特色:
引入业界领先的云产品,结合生产运营运维需求进行客户化定制,构建新一代基础设施云。
通过引入开源容器技术 Docker、容器集群调度技术 Kubernetes 等,自主研发建设应用平台云。
基于 HAProxy、Dubbo、ElasticSearch 等建立负载均衡、微服务、全息监控、日志中心等配套云生态。
基于 Kubernetes Operator 机制提供有状态应用容器化部署及自动化运维能力,实现基础技术平台弹性扩缩,落地 ElasticSearch、Zookeeper 等复杂应用容器化部署场景。
为什么要做 Serverless?
"不是说 Serverless 发展好就去做,而是考虑了具体业务场景",周文泽表示。
一方面工行已建立了较为完备的云计算、分布式架构体系及容器云平台,分布式服务体系建设成效也比较显著,包括积累了大量可复用的业务服务资产,同时业务量上涨较快,核心业务平均交易量超 5 亿笔每天,大量的业务往线上走,对业务改造压力非常大,大量的业务需要快速做线上化的处理,针对手机银行或者其他的 PC 端都会面临这样的情况;另一方面,商业银行竞争加剧及互联网企业的跨界渗透,要求银行信息系统必须满足快速创新需要。
在这个背景下,工行看到了 Serverless 的能力,它可以帮助快速上线服务。
Serverless 函数计算的技术优势总结下来有以下几个方面:
开发:无需担心基础服务的稳定可靠,无需设计复杂的分布式架构,无需关心灰度限流日志方案的实现,只需专注业务代码开发。
上线:无需像普通容器镜像一样对应用进行各种部署配置,只需发布即可运行。
运维:无需关心扩缩容,无需担心底层资源问题,无需担心高故障恢复问题。
这些优势对业务开发有非常大的吸引力。
工行函数计算技术选型
如前文所述,工行于 2018 年启动了 Serverless 1.0 的设计,下图就是 1.0 的技术架构,主要是以 Knative+自研事件驱动框架并存为核心的一套技术方案,提供了以 FaaS+BaaS 模式的函数计算能力和 Serverless container 模式。
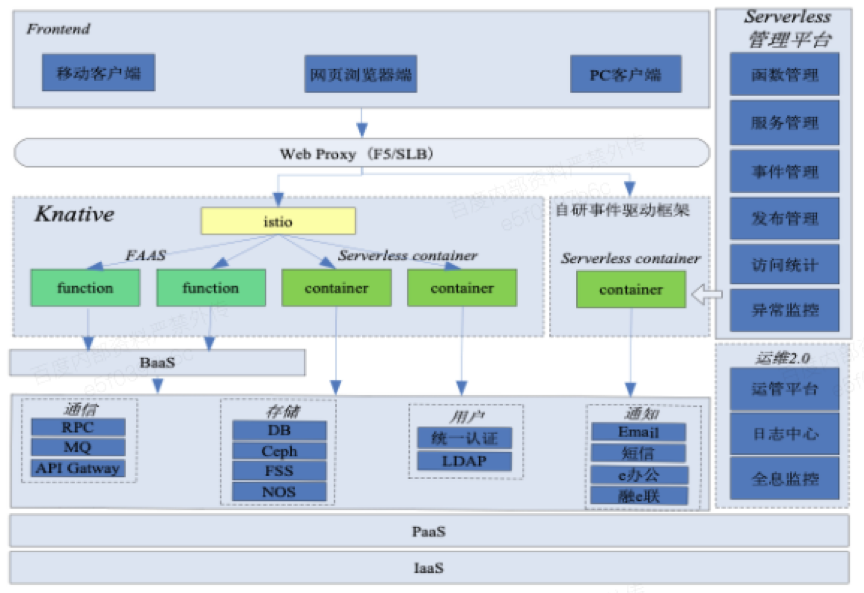
工行 Serverless 1.0 平台技术架构
Serverless 1.0 平台在工行内部进行了小规模的落地试点工作,实现了动态伸缩过程中应用实例数 0 到 N,N 到 0 的能力。但随着一些对请求响应要求较高的应用开始接入,Serverless 平台也逐渐出现一些问题,比如实例冷启动速度较慢,每次发布都需要制作新的镜像等等。

工行 Serverless 2.0 平台技术架构
2020 年,基于 Serverless 1.0 平台的不足,设计了 2.0 函数计算平台技术架构。2.0 平台在技术选型上以百度天合 Stack 的函数计算产品为核心,并与工行现有的分布式、云计算技术平台做对接,为应用提供完整的函数核心引擎、函数管理能力、开发交付能力。
具体来讲,Serverless 2.0 平台主要提供了以下三个方面的能力:
函数事件触发器:捕获外部事件,形成统一的事件规范,并将事件指定给函数核心引擎进行执行。
函数核心引擎:函数控制器实现事件解析和事件转发并实现函数实例的扩缩容,同时实现与行内各系统模块对接,实现统一的资源供给、监控、报警、运维等能力。
函数管理:为应用提供 API 和 WEB 服务实现函数编辑和发布,对接行内 VCDS 持续交付系统实现函数生产交付。
综合上述能力,使用百度私有化 Serverless 函数计算产品对接工行存储、日志、监控、持续集成等能力,构建了工行函数计算平台。
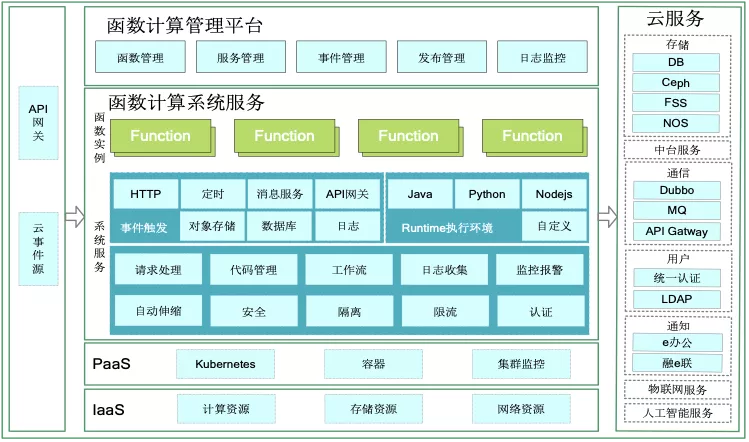
工行函数计算平台能力视图
上图是工行函数计算平台能力视图,基本上包含了函数计算该有的标准能力:
管理平台:面向开发运维人员,提供函数管理、发布管理和日志监控功能,覆盖函数的开发测试、运维监控全链路环节。
事件触发器:目前已支持 HTTP 触发器、定时触发器、Kafka 触发器,并将陆续提供对象存储触发器、数据库触发器和日志触发器。
Runtime 执行环境:支持 Java(1.8)、Python(3.6)、Node.js(10)三大行内主流运行时,支持自定义运行时(自定义镜像)。
平台底层支撑:下沉日志、监控、报警等应用基础支撑能力,降低应用开发成本。
落地场景介绍
周文泽认为 Serverless 目前更适合作为微服务的一种补充而存在,多用于相对独立、架构简单的业务应用。
他具体介绍了三个主要场景:
一个是应用后端服务,通过在函数内组合多个 API、渲染页面、直接编写业务逻辑等方式构建后端服务,主要有 BFF 接口聚合服务、服务端渲染 SSR、静态资源服务三种主流场景,这个多用于小程序、H5 等场景;
第二是批量任务,主要是批量运行时间不一定,但是运行的时候占用大量的资源,平时空闲着,这种时候其实这种技术非常适合它,可以通过在函数内编写批量处理逻辑,再通过函数工作流实现多个批量逻辑的组合,如文本批量核对;
第三是模型发布,模型一个是用量不稳定,涉及到 AI 相关的服务,发布频率非常高,将训练好的模型通过函数计算快速发布提供服务,如 RAS 智能基金组合回测模型。
接下来对具体使用的场景实例进行了展开介绍:
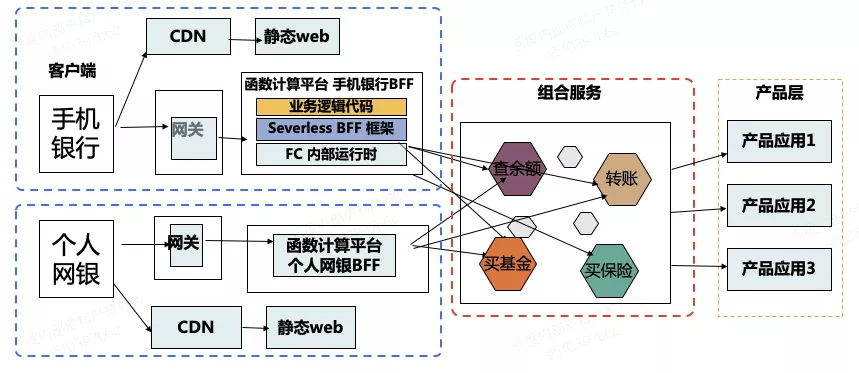
首先是接口聚合的内容,以上是手机银行和 PC 银行简单的示意图,手机银行和 PC 端个人网银需求变动较多,手机端和 PC 端的背后对接了大量子应用,这些子应用边界较强,每个渠道都有各自的研发运维团队,实现需求时需要多个团队相互配合联动,导致需求响应可能不够及时。
跟团队沟通后,解决思路是部分业务场景使用 Nodejs 构建 BFF 层,基于 Midway.js 构建前后端一体化框架,业务功能使用函数计算进行开发,前端适配 H5/RN/Vue 大前端组件,后端适配原生 Node.js、Egg、Koa 等应用开发框架,以 JS 方法调用替换 HTTP 调用开发,实现业务开发前后端技术栈、研发模式统一,这样在开发的时候响应速度得到明显提高。
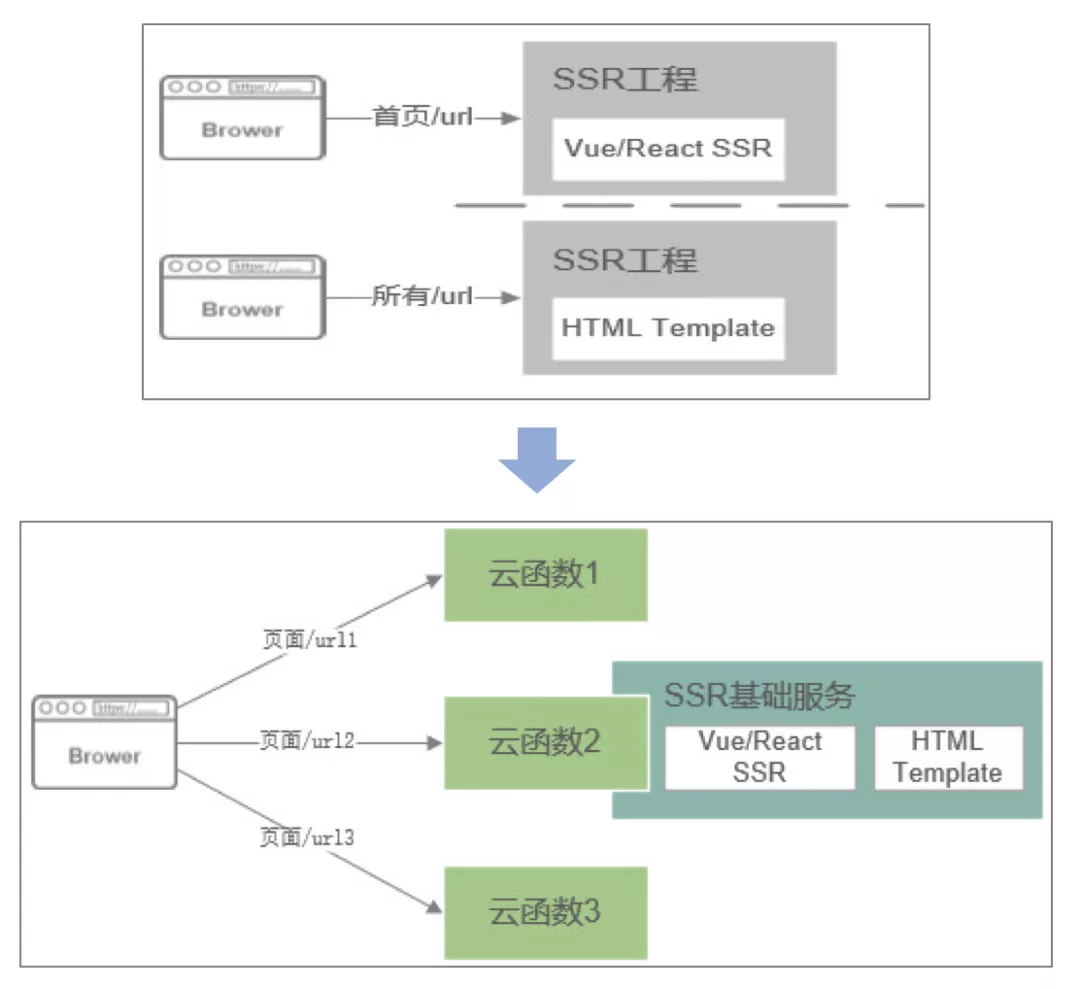
第二个是场景服务端渲染,本身是不错的技术,但是存在一个问题,对现有的应用来说如果做服务端渲染的改造成本非常高,要配置一系列负载均衡实现这个能力,想用但是觉得成本太高还是不用了,通过函数计算把这个服务端渲染整个包装成一个技术的服务,在上面只需要把逻辑写完之后把函数发布出去就可以渲染这个能力,不用部署额外负载均衡的能力,不用关心怎么部署、怎么高可用、怎么监控......一系列不用关心,这样服务端渲染采用的接受度非常强,这样做出来的功能比如说针对移动端、PC 端速度有明显的提高。
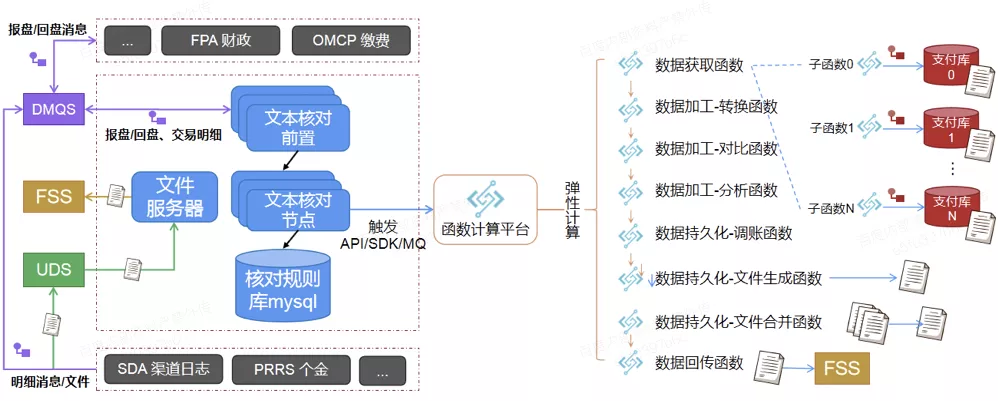
第三个是批量场景,最开始做 Serverless 的原因,是因为有一个应用的批量任务场景有高可用的要求,在批量文本核对任务对数据库进行分库之后,需要多个节点运行支撑,由于文本核对任务不定期执行,存在大量空闲时间段资源冗余问题。这种情况下可以通过函数计算实现文本核对资源弹性化,抽取共性的数据获取、数据加工、数据持久化和数据回传等关键文本核对步骤为函数,通过函数计算平台弹性执行;依托函数计算服务,实现定时或 kafka 消息触发的方式触文本核对任务执行;利用函数工作流机制编排执行函数任务。
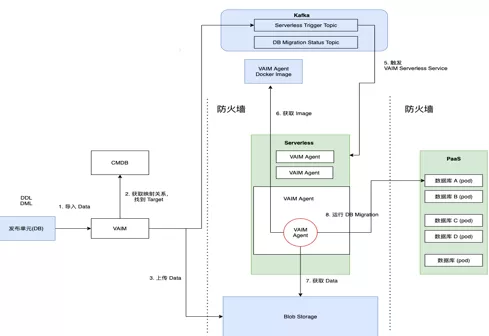
第四个场景是数据库安装的场景,在 MySQL 数据库上云之前,使用部署在每台宿主机上的 agent 进行数据库脚本部。MySQL 上云后,由于数据库容器未部署 agent ,应用数据库版本安装时需申请跳板机进行中转安装,目前跳板机节点存在多应用共用、多节点共用时资源无法隔离,跳板机与数据库关系映射无序,跳板机部署完后资源闲置浪费等问题。这种情况下,使用函数计算运行 agent 直接连接节点进行 DB 更新,并利用 Kafka 触发器进行事件触发执行,同时在投产高峰期,可以同时运行更多的 agent 函数实例。
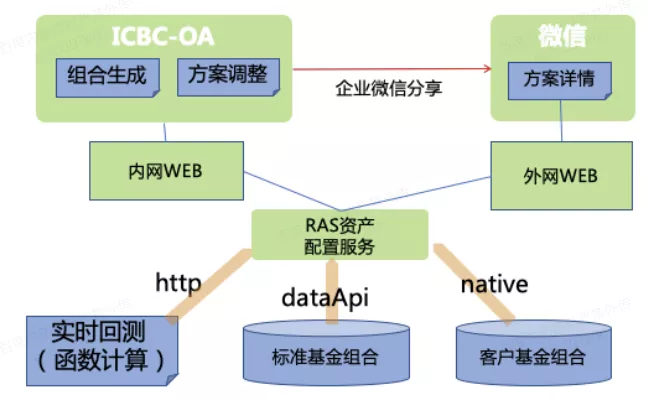
最后是模型发布场景,工行的线下投顾业务需要针对客户出具千人千面的基金组合策略,但是缺乏对基金组合历史业绩及表现的回测展示,需要有在线能力支撑准实时的回测,并需要频繁且快速地发布模型,对基金配置模型进行优化与提升,目前发布机制上不够灵活,每次新的模型一出来都要去发版是非常繁琐的事情。 研发思路将基金组合回测迁移到函数计算平台,采用线上直接发布模式,快速上线不同种类模型进行计算,快速向用户展示结果。
未来规划
最后简单分享工行对函数计算的下一步发展规划:
第一,统一 BaaS 服务接口规范,通过类似微服务构建框架 Dapr 思路,形成通用接口形式如 HTTP API、gRPC API,供函数内部进行调用,加快业务函数构建;
第二,运用云原生 Java 技术,Java 是工行最主要的开发语言,而普通的 Java 存在启动缓慢,内存占用大的问题,在 Serverless 场景下的运用会出现启动缓慢的问题,需要引入 Quarkus、Spring Native 等云原生 Java 框架;
第三,推进 Serverless CloudIDE 建设,使用更加强大的 CloudIDE 产品如 JetBrains 的 Projector,支付相对复杂的应用程序开发,同时也能最大程度保持现有开发人员使用 IDEA 的开发习惯;
第四,构建函数模板中心,函数计算整体开发较为方便,但仍可以进一步抽取通用的函数代码,形成函数模板,供开发人员进行使用,实现技术资产复用,从而更快实现业务功能开发。
通过提供以上四种产品能力,从开发、运行层面,为应用提供更友好的开发体验,更快的启动速度,从而增加业务应用的对产品的接受度。
关于百度 Serverless 函数计算产品:
官网地址:https://cloud.baidu.com/product/cfc.html
百度函数计算引擎 EasyFaaS 已开源: github.com/baidu/EasyFaaS
原文链接:




