
在 Facebook 上管理应用程序的大小是一个独特的挑战:开发者每天都要检查大量的代码,每行代码最终都会转化为人们下载到手机上的应用程序中的附加位。如果不加检查,这些添加的代码会使应用程序越来越大,直到下载应用程序所需的时间变得不可接受。
压缩是我们用来保持应用程序大小最小化的方法之一。这些压缩过的文件占用更少的空间,这意味着更小的应用程序下载地更快,全球数十亿用户使用更少的带宽。在移动宽带有限的地区,这样的节省尤其重要,因为有限的带宽会使下载大型应用程序的花费很高。但单靠压缩还不足以跟上我们所做的所有更新和添加到应用程序中各种功能的步伐。因此,我们开发了一种称为“Superpack”的技术,它将编译器分析和数据压缩相结合,开拓出超越传统压缩工具能力的优化。Superpack 突破了压缩极限,实现了比现有压缩工具更好的压缩率。
在过去两年中,Superpack 已经能够控制开发人员导致的应用程序大小增长,并保持我们的 Android 应用程序小型化。Superpack 的压缩有助于减小我们的 Android 应用程序群的大小,这与常规 Android APK 压缩相比要小得多,与 Android 的默认 Zip 压缩相比节省了 20%以上空间。使用 Superpack 的应用程序包括 Facebook、Instagram、WhatsApp 和 Messenger。这些应用程序由于 Superpack 而减小的大小如下表所示。
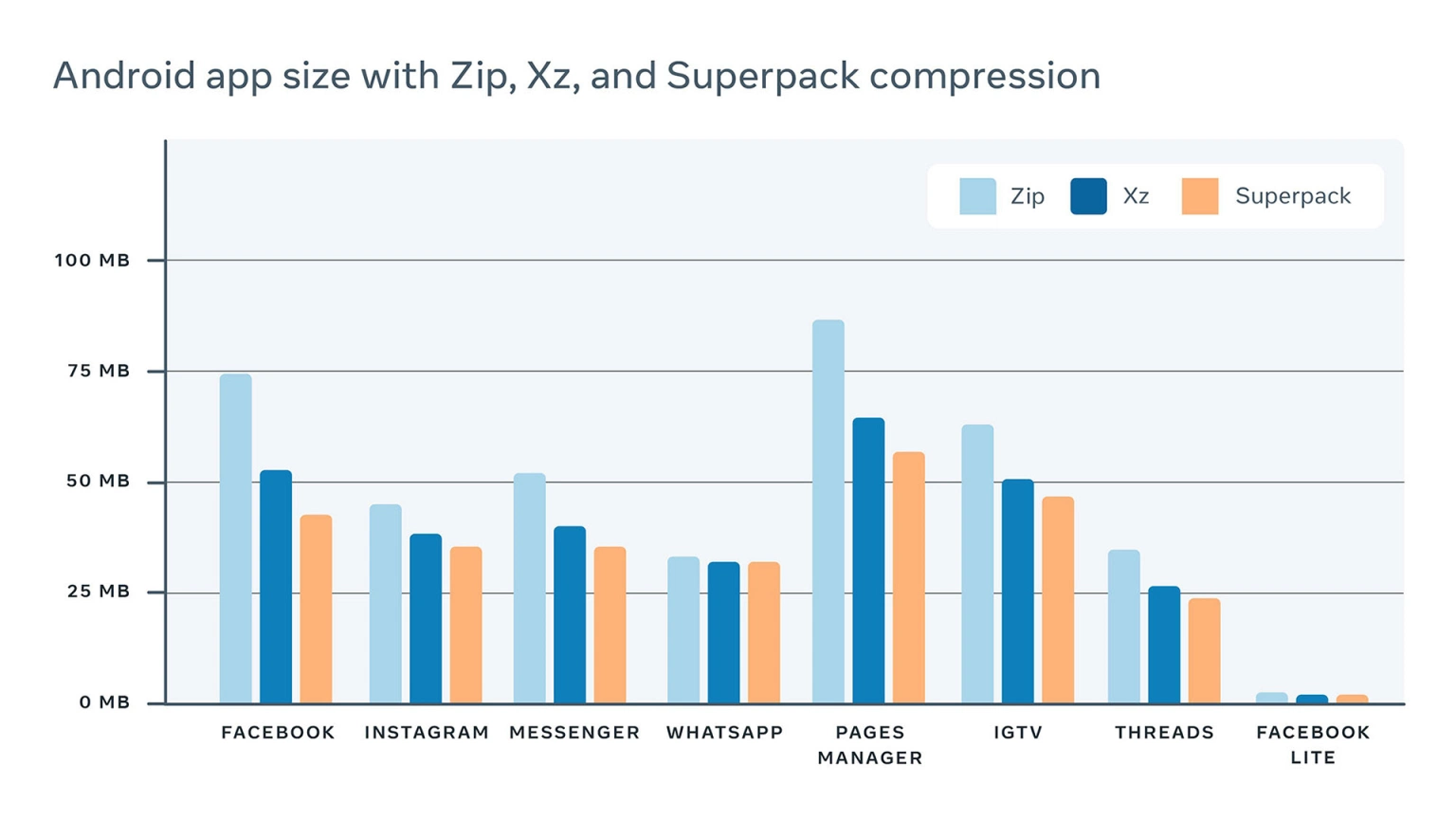
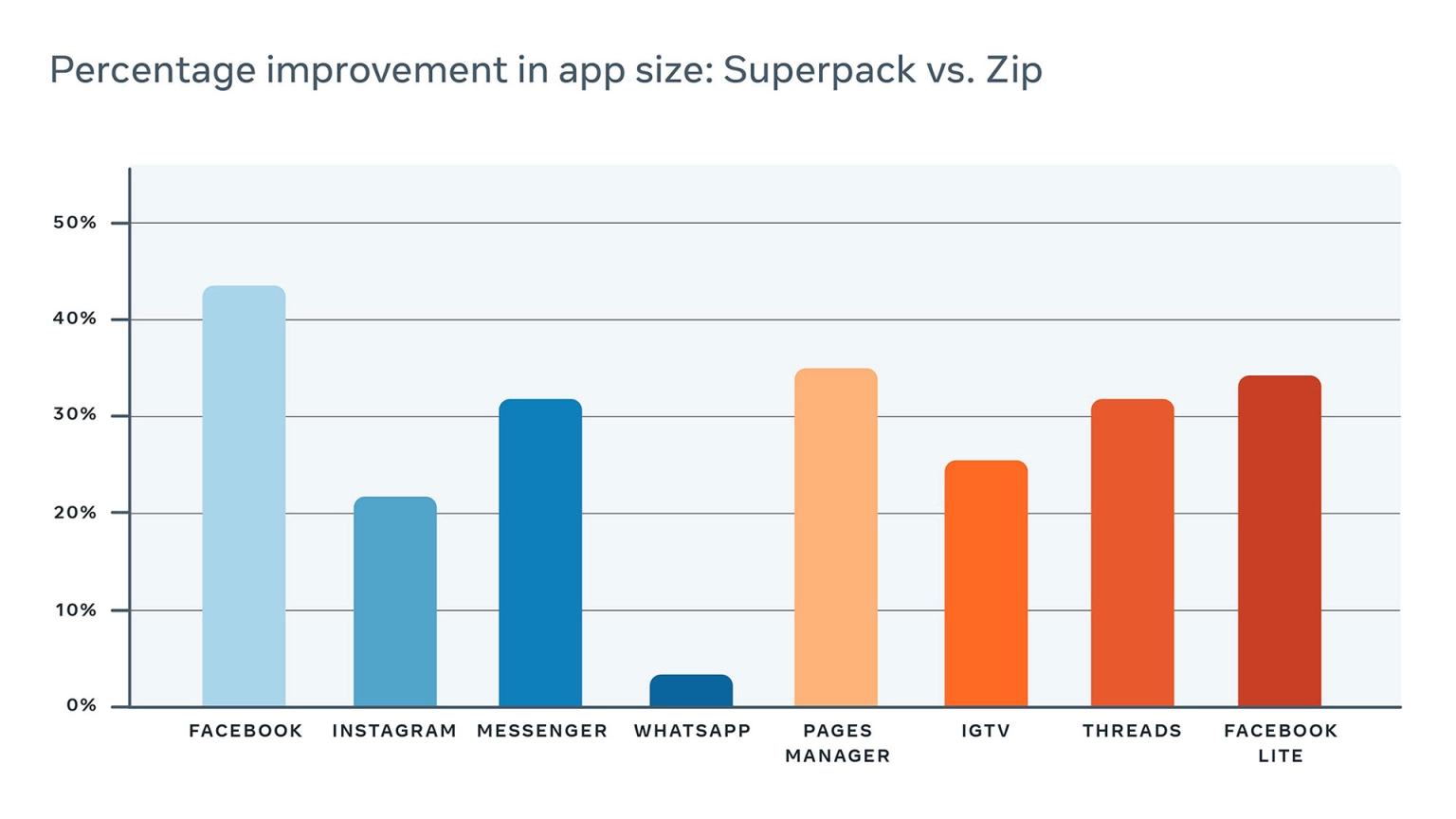
Superpack:编译器+数据压缩
虽然现有的压缩算法,例如 Zip 的 Deflat 和 Xz 的 LZMA,能够很好地处理大型单体数据,但它们不足以抵消我们在应用程序中看到的增长速度,因此我们开始开发自己的解决方案。压缩是一个成熟的领域,我们开发的技术跨越了整个压缩领域,从数据压缩和 Lempel-Ziv(LZ)解析到统计编码。
Superpack 的优势在于压缩编码,如机器码和字节码,以及其它类型的结构化数据。Superpack 的底层方法是基于Kolmogorov的算法复杂性度量的想法,将一段数据的信息内容定义为生成该数据的最短程序的长度。换句话说,可以通过将数据表示成能够生成这段数据的程序来压缩数据。当数据是代码时,可以将其转换成更小的压缩后的表示。生成斐波那契数列及其索引列表的程序,是包含这些数列的文件的高度压缩表示。降低 Kolmogorov 复杂性本身的想法对于压缩领域并不新鲜。Superpack 的新方法涉及将编译器方法与现代压缩技术相结合来实现这一目标。
将生成小型程序的生成过程作为压缩的形式有很大的好处。这为数据压缩工程师提供了一系列成熟的编译工具和技术,这些工具和技术可以更改用途进行压缩。Superpack 压缩利用常见的编译器技术,例如解析和代码生成,以及最近的创新,例如 Satisfiability modulo theories (SMT) 求解器,来找到最小的程序。
能够将这些编译器技术与主流数据压缩中使用的技术结合起来,这是 Superpack 有效性的一个重要组成部分。来自编译器的语义知识占了 Superpack 的一半,造就增强的 LZ 解析(消除冗余的压缩步骤),以及改进的熵编码(为频繁的信息片段生成短编码的步骤)。
改进的 LZ 解析
压缩器通常使用从 LZ 家族中选择的算法来识别重复的字节序列。大体上,每一个这样的算法都试图用指向以前出现的数据的指针来替换重复出现的数据序列。这个指针由上一次出现的距离(字节数)和序列长度组成。如果这个指针可以用比实际数据更少的位表示,则可以用之替换作为压缩大小。Superpack 通过发现更长重复序列,同时减少表示指针的位数,从而改进了 LZ 解析过程。
在被压缩的程序中,Superpack 通过基于 AST 对数据进行分组来实现这些改进。例如,在以下指令序列中,最长重复序列的长度为 2。然而,当根据 AST 类型(即操作码和寄存器,小表中的组 1)和立即数(下表中的组 2)进行分组时,长度增加到 4。在原始数据的原始解析中,重复序列之间的距离是 2 条指令。但在分组后的版本中,距离为 0。更小的距离通常使用更少的位数,更长的序列匹配通过在给定指针中捕获更多的输入数据来节省空间。因此,Superpack 生成的指针比简单计算的指针要小。
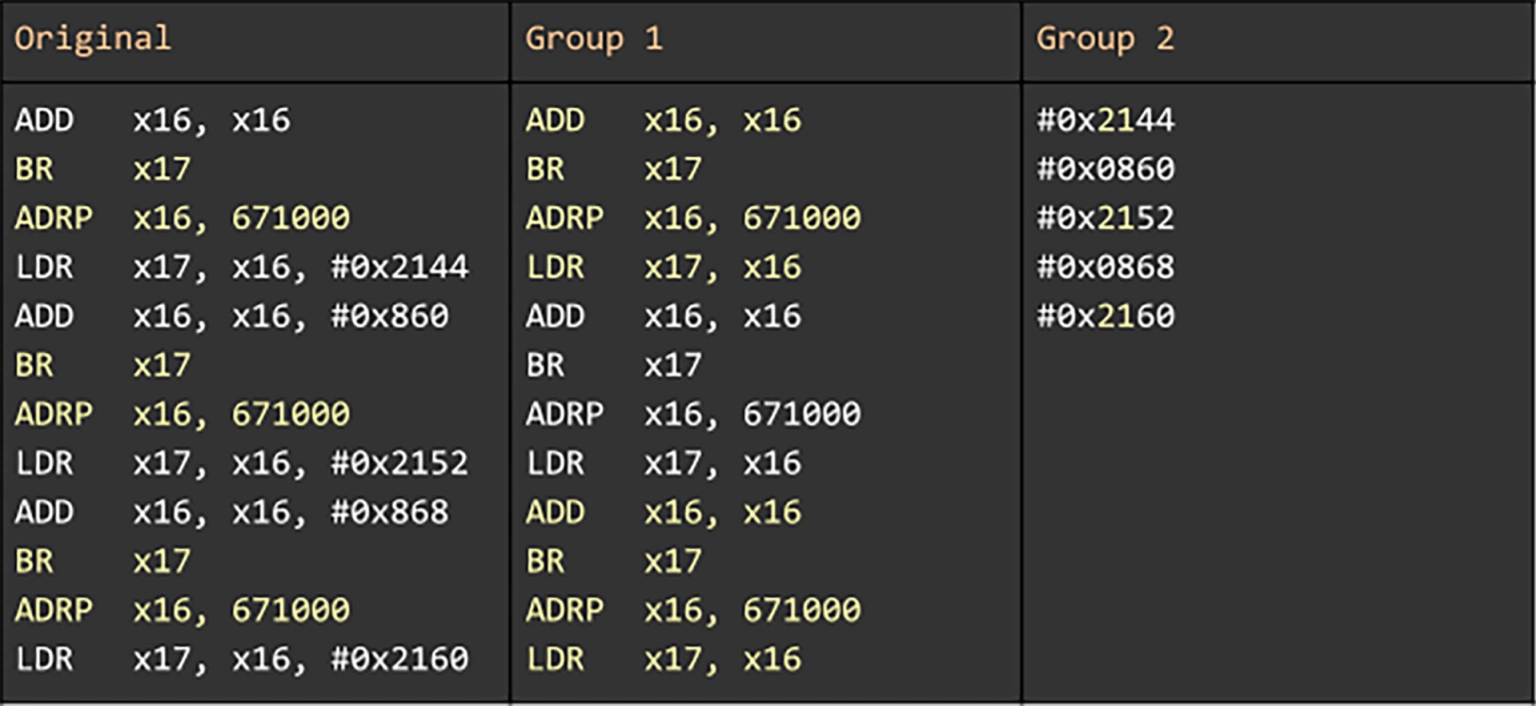
但是,我们如何决定何时分隔代码流以及何时保持原封不动?Superpack 最近的工作中引入了分层压缩,这将此决策合并到 LZ 解析的优化组件中,称为最优解析。在下面编辑过的代码中,最好将代码段的最后一段保留为原始形式,并生成一个指向前五条指令的指针的匹配项,同时拆分代码段的其余部分。在拆分余数中,利用寄存器组合的稀疏性来生成更长的匹配。以这种方式对代码进行分组还可以通过计算重复序列之间的逻辑单元数量(沿 AST 测量)而不是测量字节数,来进一步缩短距离。
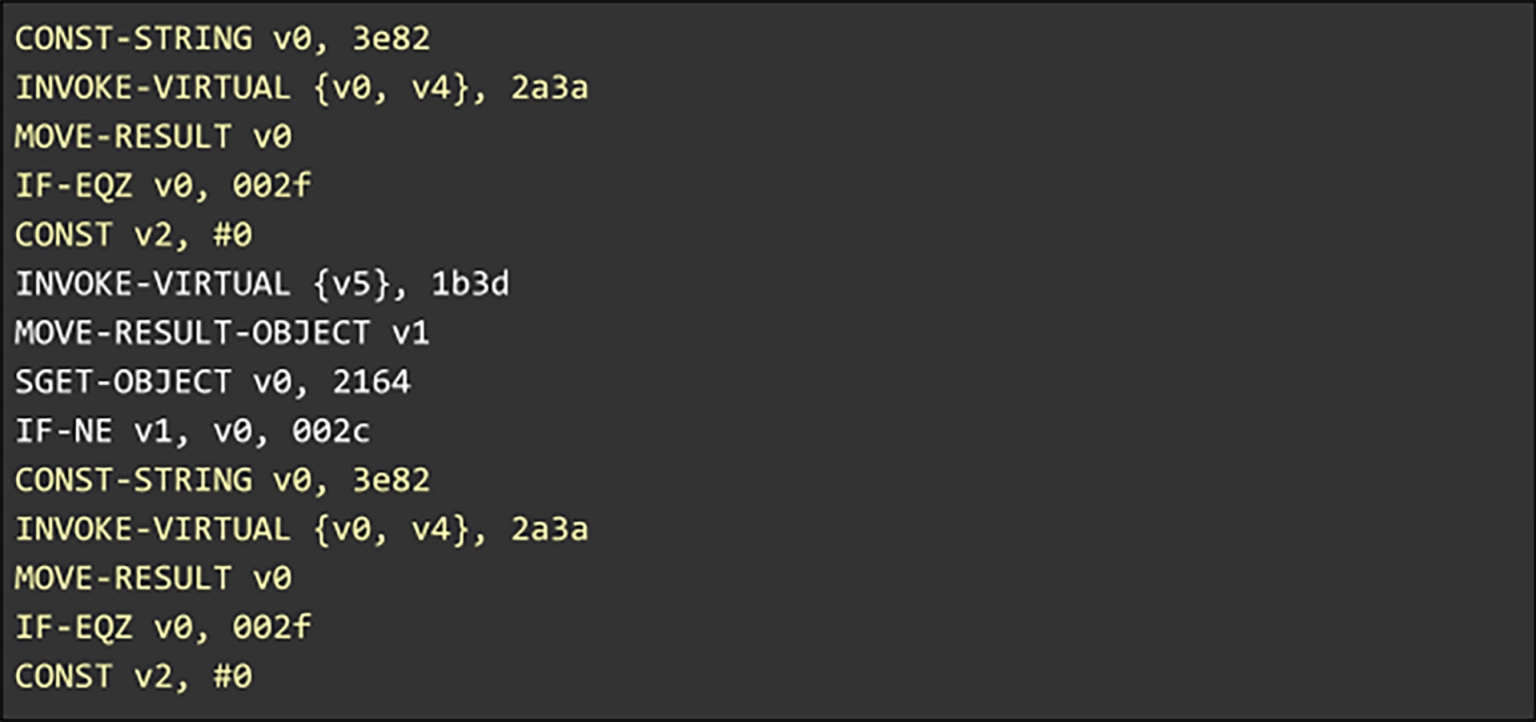
改进的熵编码
重复的字节序列被指向上一次出现的序列的指针有效地替换。但是压缩器对非重复序列或比指针表示更短的短序列能做些什么呢?在这种情况下,压缩器通过对数据中的值进行编码来表示数据。用来表示序列的位数,利用了序列可以假定的值的分布。熵编码是用数据中的值的熵的位数来表示一个值的过程。压缩器为此目的使用的一些众所周知的技术包括哈夫曼编码、算术编码、距离编码和非对称数字系统(asymmetircal numberal systems,ANS)。
Superpack 有一个内置的 ANS 编码器,还有一个可插拔的架构,支持多个这样的编码后端。Superpack 通过识别上下文(其中要表示的序列由较低的熵)来改进熵编码。与 LZ 解析类似,这些上下文是从 Superpack 对通过编译器分析提取的数据结构的了解中派生出来的。在下面简化的指令序列中,有七个不同的地址,每个地址都有前缀 0x。在该编码的大量不同排列中,常规编码器用于表示地址字段的位数将接近 3。
然而,我们注意到,七个地址中有三个与 BL 操作码配对,而另外三个与 B 操作码关联。只有一个地址与两者都耦合。如果这个模式在整个代码体中都成立,那么操作码可以用作编码上下文。在这种情况下,表示这七个地址的位数接近 2 而不是 3。下表显示了带上下文和不带上下文的编码。在第三列中的 Superpack 压缩情况下,可以将操作码视为预测丢失的位。这个简单的示例旨在说明如何使用编译器上下文来改进编码。在实际数据中,获得的位数通常是分数,上下文和数据之间的映射很少像本例中那样直接。

作为压缩表示的程序
我们解释了当被压缩的数据由代码组成时,Superpack 如何改进 LZ 解析和熵编码。但当数据包含非结构化值时会发生什么?在这种情况下,Superpack 试图通过在压缩时将值转换为程序来添加值结构。然后,在解压时,将程序进行解析来恢复原始数据。这种技术的一个例子是 Dex 索引的压缩,Dex 索引是 Dex 编码中已知值的标签。Dex 索引具有高度的局部性。为了利用这种局部性,我们将索引转换为一种将最近的值存储在逻辑寄存器中的语言,并将即将出现的值作为固定值的增量发布。

为这种表示编写一个高效的压缩器会导致编译器中常见的寄存器分配问题,该问题决定何时从寄存器中收回旧值来加载新值。虽然这种减少是针对索引字节码的,但一个通用的想法适用于任何字节码表示,即,生成的代码符合前两节中概述的优化。在本例中,LZ 解析通过将操作码、MOV 和 PIN 放在一个组中、在第二个组中收集增量、以及在第三个组中收集最近的索引而得到改进。
基于真实数据的 Superpack
Superpack 有 3 个主要的有效载荷目标。第一个是 Dex 字节码,在 Android 应用程序中 Java 被编译成的格式。第二个是 ARM 机器码,这是针对 ARM 处理器编译的代码。第三个是 Hermes 字节码,它是在 Facebook 创建的 JavaScript 的专用高性能字节码表示。所有这三种表示都使用了全方位的 Superpack 技术,这些技术由基于代码语法和语法知识的编译器分析提供支持。在这三种情况下,有一组压缩转换应用于指令流,另一组压缩转换应用于元数据。
应用于代码的转换都是相似的。元数据转换有两部分。第一部分通过按类型进行分组来利用数据的结构。第二部分利用元数据规范中的组织规则,例如导致对数据进行排序或公开可用于上下文距离和序列项之间的相关性的规则。
Zip、Xz 和 Superpack 针对这三种格式的压缩率如下表所示。

Superpack 架构和实现
Superpack 是压缩领域的一个独特玩家,因为它包含有关压缩数据的类型知识。为了在 Facebook 推广 Superpack 的开发和使用,我们开发了一个模块化设计,其中的抽象可以跨不同的压缩格式使用。Superpack 的架构类似于操作系统,其内核实现分页内存分配、文档和归档抽象、用于转换和操作指令的抽象,以及可插拔模块的接口。
面向编译器的机制属于专门的编译器层。每种格式都实现为一个可插拔的驱动程序。驱动程序利用被压缩数据的属性,并在代码中标记相关性,最终被压缩层利用。解析输入代码的机器使用基于 SMT 解析器的自动推理。我们如何使用 SMT 求解器来帮助压缩超出了本文的范围,将成为未来一篇博文的有趣话题。
压缩层还包括可插拔模块。其中一个模块是 Superpack 自己的压缩器,包括一个定制的 LZ 引擎和一个熵编码后端。在我们构建这个压缩器的过程中,我们插入了利用现有压缩工具进行压缩工作的模块。在该装置中,Superpack 的角色简化为将数据重新组织为不相关的流。随后,现有工具会尽最大努力进行压缩,这是有效的,但在识别和使用编译器信息的粒度上受到限制。Superpack 的定制压缩后端通过数据的内部表示的细粒度视图解决了这个问题,这使它能够利用单个位的细粒度的逻辑相关性。将用于执行压缩工作的机制抽象为一个模块,可以让我们在压缩率和解压速度之间选择一些平衡。
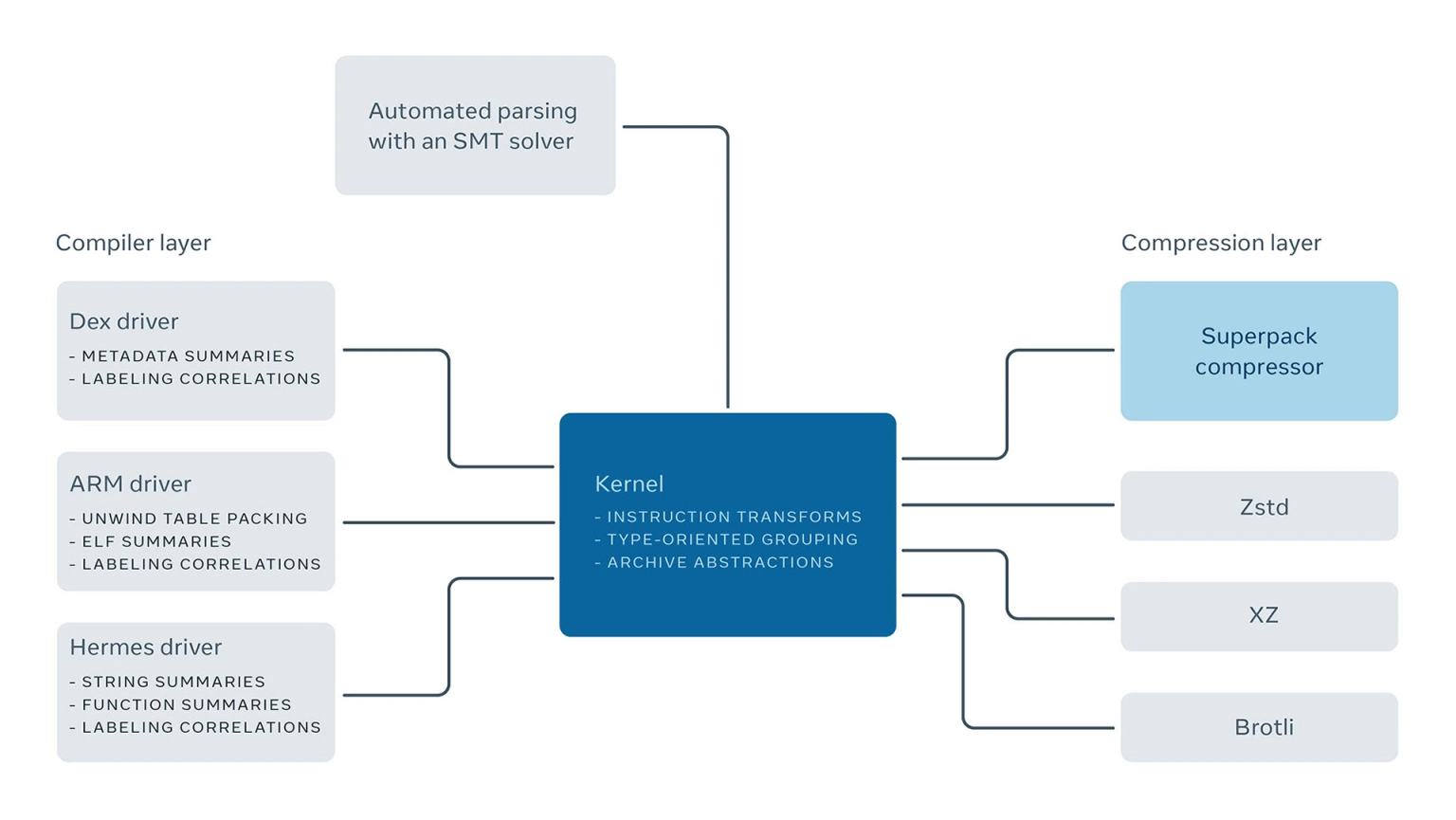
Superpack 的实现包含用 OCaml 编程语言编写的代码和 C 语言代码的混合。OCaml 在压缩端用于操作复杂的面向编译器的数据结构,并与 SMT 求解器进行接口对接。C 语言是解压逻辑的自然选择,因为它往往很简单,同时对解压代码运行的处理器的参数高度敏感,例如一级缓存的大小。
限制和相关工作
Superpack 是一个非对称压缩器,这意味着解压速度很快,而压缩速度可以很慢。流式压缩,即数据以其传输速率进行压缩,一直不是 Superpack 的目标。Superpack 无法满足流式压缩的约束条件,因为其当前的压缩速度跟不上现代数据传输速率。Superpack 已经应用于结构化数据、代码、整数和字符串数据。Superpack 当前不以图像、视频或音频文件为目标。
在 Android 平台上,在使用压缩来减少下载时间和可能增加磁盘占用和更新大小之间存在一种平衡。这种平衡不是 Superpack 的限制,而是 Facebook 使用的打包工具和 Android 上使用的分发工具之间尚未建立互操作性。例如,在 Android 上,应用程序更新是作为应用程序连续版本内容之间的增量发布的。但这种增量只能由能够解压和重新压缩应用程序内容的工具生成。由于当前工具中实现的差异对比过程无法解析 Superpack 文档,因此对于包含此类文件的应用程序,增量会变得更大。我们相信,这类问题可以通过 Superpack 和 Android 工具之间更细粒度的接口、Android 分发机制中更高的可定制性以及 Superpack 文件格式和压缩方法的公开文档来解决。Facebook 的应用程序主要由 Superpack 擅长压缩的代码组成,其压缩方式远远超过了 Android 上 Google Play 实现的现有压缩方式。因此,就目前来说,我们的压缩对我们的用户来说是有益的,尽管存在权衡。
Superpack 利用 Jarek Duda 在非对称数字化系统上的工作作为其熵编码后端。Superpack 借鉴了其“超优化(superoptimization)”思想,以及过去在代码压缩方面的工作。它利用Xz、Zstd和Brotli压缩器作为可选后端来完成压缩工作。最后,Superpack 使用微软的Z3 SMT求解器来自动解析和重构各种代码格式。
下一步计划
Superpack 结合了编译器和数据压缩技术,以一种特别适用于代码(例如,Dex 字节码和 ARM 机器码)的方式增加打包数据的密度。Superpack 大幅缩减了 Android 应用程序的大小,从而为全球数十亿用户节省了下载时间。我们已经描述了 Superpack 背后的一些核心思想,但只触及了我们在不对称压缩方面的工作的表面。
我们的旅程才刚刚开始。Superpack 通过对其编译器和压缩组件的增强来不断改进。Superpack 最初是作为一种工具来减少移动应用程序的大小,但我们在提高各种数据类型的压缩率方面的成功,使我们将目标对准了非对称压缩的其它用例。我们正在开发一种新的按需可执行文件格式,通过在加载时保留压缩和解压共享的库来节省磁盘空间。我们正在评估使用 Superpack 对代码进行增量压缩来减少软件更新的大小。我们还在研究将 Superpack 用作冷存储压缩器,以压缩很少使用的日志数据和文件。
到目前为止,我们的移动部署仅限于 Android 应用程序。然而,我们的工作也同样适用于其它平台,例如 iOS,而且我们也正在考虑将我们的实现移植到这些平台。目前,只有我们的工程师可以使用 Superpack,但我们渴望将 Superpack 的好处带给每一个人。为此,我们正在探索提高我们的压缩工作与 Android 生态系统兼容性的方法。这篇博文是朝着这个方向迈出的一步。有朝一日我们可能考虑将 Superpack 开源。
我们要特别感谢 Alfredo Altaminaro、Nikhil Prakash、Mauricio Nunes 和所有为 Superpack 做出贡献的人。
原文链接:
Superpack: Pushing the limits of compression in Facebook’s mobile apps




