
音频编解码器的用途是高效压缩音频以减少存储或网络带宽需求。理想情况下,音频编解码器应该对最终用户是透明的,让解码后的音频与原始音频无法从听觉层面区分开来,并避免编码/解码过程引入可感知的延迟。
在过去几年中,业界已经成功开发了多种音频编解码器来满足这些需求,包括Opus和增强语音服务(EVS)。
Opus 是一种多功能语音和音频编解码器,支持从 6kbps(千比特每秒)到 510kbps 的比特率,已广泛部署在从视频会议平台(如 Google Meet)到流媒体服务(如 YouTube)的多种类型的应用程序中。
EVS 是3GPP标准化组织针对移动电话开发的最新一代编解码器。与 Opus 一样,它是一种支持多种比特率(5.9kbps 至 128kbps)的编解码器。使用这两种编解码器重建的音频质量在中低比特率(12–20kbps)下表现很出色,但在以极低比特率(⪅3kbps)输出时质量会急剧下降。
虽然这些编解码器利用了人类感知领域的专业知识以及精心设计的信号处理管道来最大限度地提高压缩算法的效率,但最近人们开始将兴趣转向了用机器学习方法替换这些手工制作的管道。这些机器学习方法会使用一种数据驱动的方式来学习音频编码技能。
今年早些时候,我们发布了Lyra,一种用于低比特率语音的神经音频编解码器。在“SoundStream:一款端到端的神经音频编解码器”论文中,我们介绍了一种新颖的神经音频编解码器。
这种编解码器是上述成果的进一步发展,提供了更高质量的音频并能编码更多声音类型,包括干净的语音、嘈杂和混响的语音、音乐和环境声音。
SoundStream 是第一个既能处理语音也能处理音乐的神经网络编解码器,同时能够在智能手机 CPU 上实时运行。它能使用单个训练好的模型在很大的比特率范围内提供最一流的质量,这标志着可学习编解码器的一项重大进步。
从数据中学习的音频编解码器
SoundStream 的主要技术组成部分是一个神经网络,由编码器、解码器和量化器组成,它们都经过了端到端的训练。编码器将输入的音频流转换为编码信号,量化器压缩编码信号,然后解码器将其转换回音频。
SoundStream 利用了神经音频合成领域最先进的解决方案,通过训练一个鉴别器来计算对抗性和重建损失函数的组合,使重建的音频听起来接近未压缩的原始音频,从而提供高感知质量的音频输出。经过训练后,编码器和解码器可以分别运行在独立的客户端上,以通过网络高效传输高质量的音频。
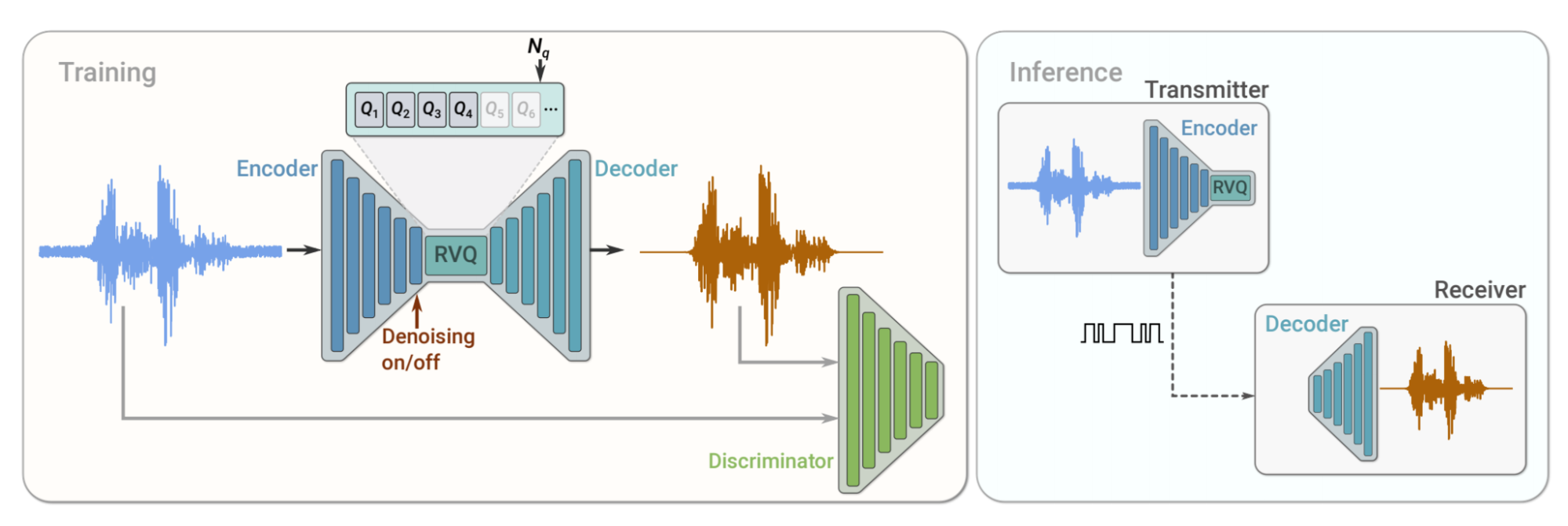
SoundStream 的训练和推理过程。在训练期间,编码器、量化器和解码器参数使用重建和对抗性损失的组合进行优化,并由鉴别器计算;后者经过训练以区分原始输入音频和重建音频。
在推理期间,发送器客户端上的编码器和量化器将压缩过的比特流发送到接收器客户端,然后接收器客户端负责解码音频信号。
使用残差向量量化学习可扩展的编解码器
SoundStream 的编码器生成的向量可以采用无限的数量值。为了使用有限数量的比特将它们传输到接收器,必须用来自有限集(称为码本,codebook)的近似向量替换它们,这一过程称为向量量化。
这种方法适用于大约 1kbps 或更低的比特率,但在改用更高的比特率时很快就会达到其极限。例如,即使比特率低至 3kbps,假设编码器每秒产生 100 个向量,也需要存储超过 10 亿个向量的码本,这在实践中是不可行的。
在 SoundStream 中,我们提出了一种新的残差向量量化器(RVQ)来解决这个问题。该量化器由多个层组成(在我们的实验中多达 80 个)。第一层以中等分辨率量化码向量(code vector),接下来的每一层都处理前一层的残差。
将量化过程分成几层可以大大减少码本大小。例如,3kbps 时每秒 100 个向量,使用 5 个量化层,码本大小从 10 亿减少到了 320。此外,我们可以添加或移除量化层来轻松增加或减少比特率。
由于传输音频时网络条件可能会发生变化,理想情况下,编解码器应该是“可伸缩的”,这样它可以根据网络状态改变其比特率。虽然大多数传统编解码器都是可伸缩的,但以前的可学习编解码器需要专门针对每种目标比特率进行训练和部署。
为了规避这个限制,我们利用了 SoundStream 中量化层数控制比特率的机制,提出了一种称为“量化器丢弃”的新方法。
在训练期间,我们随机删除一些量化层来模拟不同的比特率。这会让解码器针对任何比特率的传入音频流都学到良好的表现,从而帮助 SoundStream 变得“可伸缩”,让单个训练模型可以运行在任何比特率下,表现还能与专门针对这些比特率训练的模型一样好。
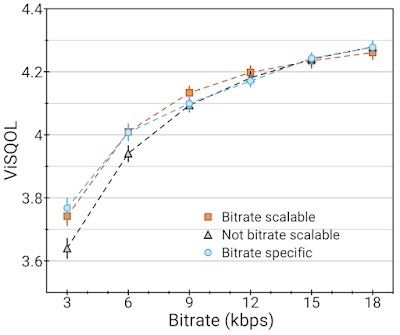
SoundStream 模型的对比(越高越好):在 18kbps 下训练,有量化器丢弃(Bitrate scalable);没有量化器丢弃(No bitrate scalable)并使用可变数量的量化器评估;或以固定比特率进行训练和评估(Bitrate specific)。加入量化器丢弃后,与针对特定比特率的模型(每个比特率专门训练一个模型)相比,比特率可伸缩模型(所有比特率使用一个模型)不会损失任何质量。
最先进的音频编解码器
SoundStream 在 3kbps 下的质量就优于 12kbps 的 Opus,接近 9.6kbps 的 EVS 质量,同时使用的数据量减少到了 3.2 到 4 分之一。这意味着使用 SoundStream 编码音频可以使用低得多的带宽提供类似的质量。
此外,在相同的比特率下,SoundStream 的性能优于基于自回归网络的 Lyra 当前版本。与已经针对生产用途进行部署和优化的 Lyra 不同,SoundStream 仍处于试验阶段。未来,Lyra 将整合 SoundStream 的组件,以提供更高的音频质量并降低复杂性。
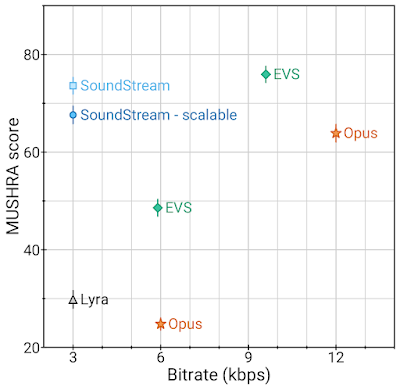
3kbps 的 SoundStream 与最先进的编解码器的质量对比。MUSHRA分数是主观质量的指标(越高越好)。
这些音频示例展示了 SoundStream 与 Opus、EVS 和原始 Lyra 编解码器的性能对比。
联合音频压缩和增强过程
在传统的音频处理管道中,压缩和增强(去除背景噪声)通常由不同的模块执行。例如,音频增强算法可以应用在发送端(在压缩音频之前),或接收端(在音频解码之后)。在这样的设置中,每个处理步骤都会带来端到端的延迟。
相反,SoundStream 的设计是压缩和增强可以由同一模型联合执行,而不会增加整体延迟。在以下示例中,我们展示了通过动态激活和停用去噪(5 秒不去噪、5 秒去噪、5 秒不去噪,以此类推)来融合压缩与背景噪声抑制过程。(示例见原文
结论
在需要传输音频的场景,无论是在流式传输视频时还是在电话会议期间,都需要高效的压缩过程。SoundStream 是改进机器学习驱动的音频编解码器的重要一步。
它的表现优于之前最先进的编解码器,如 Opus 和 EVS;它可以按需增强音频,并且只需部署一个(而非多个)可伸缩的模型即可处理多种比特率。
SoundStream 将作为 Lyra 下一个改进版本的组件发布。将 SoundStream 与 Lyra 集成后,开发人员可以在他们的工作中利用现有的 Lyra API 和工具链,从而兼顾灵活性和更好的音质。我们还将发布一个单独的 TensorFlow 模型用于实验目的。
致谢
本文介绍的工作由 Neil Zeghidour、Alejandro Luebs、Ahmed Omran、Jan Skoglund 和 Marco Tagliasacchi 完成。我们非常感谢谷歌的同事提供的关于这项工作的所有讨论和反馈。
原文链接:https://ai.googleblog.com/2021/08/soundstream-end-to-end-neural-audio.html




