
编者按:《透过数字化转型再谈数据中台》系列连载 6-8 篇左右,作者结合自己在数据中台领域多年实践经验,总结了数据架构知识、BI 知识,以及分享给大家一些产业互联网实施经验。本文是系列文章中的第三篇。
在前面两篇 “关于数字化转型的几个见解 ”、“唯一性定理中的数据中台”提到了数据中台发展问题。比如概念发展太快,信息量过载,以及存在广义、狭义的数据中台定义的差别等,涉及到的这些知识都离不开数据架构的范畴,所以这一篇我会通过大数据架构发展的视角来总结与分享。(一些知识继承自己在 2015 年写的《从数据仓库到大数据,数据平台这 25 年是怎样进化的?》,又名我所经历的大数据平台发展史系列),主要涉及三个方面:
从数仓架构到大数据架构总共三个时代九种架构的演进
自己整理的大数据技术栈
最新一代的 Data Mesh 架构的数据平台
数据平台的发展在悄然发生变化
从现在的企业发展来看,大家的诉求重点已经从经营与分析转为数据化的精细运营。在如何做好精细化运营过程中,企业也面临着来自创新、发展、内卷等的各方面压力。 随着业务量、数据量增长,大家对数据粒度需求从之前的高汇总逐渐转为过程化的细粒度明细数据,以及从 T+1 的数据转为近乎实时的数据诉求。
大量的数据需求、海量的临时需求,让分析师、数据开发疲惫不堪。这些职位也变成了企业资源的瓶颈,传统 BI 中的 Report、OLAP 等工具也都无法满足互联网行业个性化的数据需求。大家开始考虑如何把需求固定为一个面向最终用户自助式、半自助的产品,来快速获取数据并分析得到结果,数据通过各类数据产品对外更有针对性的数据价值传递。
(关于数据产品一个题外补充:当总结出的指标、分析方法(模型)、使用流程与工具有机的结合在一起时数据产品就此产生,随着数据中台 &数据平台的建设逐渐的进入快速迭代期,数据产品、数据产品经理这两个词逐渐的升温并逐渐到今天各大公司对数产品经理岗位的旺盛诉求,目前这两方面的方法论也逐步的体系化、具象化)。
在这十几年中,影响数据仓库、数据平台、数据中台、数据湖的演进变革的因素也很多,比如
不断快速迭代的业务模式与膨胀的群体规模所带来的数据量的冲击,新的大数据处理技术的驱动。还有落地在数据中台上各种数据产品的建设,比如工具化数据产品体系、各种自助式的数据产品、平台化各种数据产品的建设。这些数据建设能力的泛化,也让更多的大众参与数据中台的建设中 ,比如一些懂 SQL 的用户以及分析师参与数据平台直接建设比重增加 。还有一些原本数据中台具备的能力也有一些逐步地被前置到业务系统进行处理。
一张图看清楚大数据架构发展
数据仓库在国外发展多年,于大约在 1998-1999 年传入中国。进入中国以后,发展出了很多专有名词,比如数据仓库、数据中心、数据平台、数据中台、数据湖等,从大数据架构角度来看可用三个时代九种架构来做总结,其中前四代是传统数据仓库时代的架构,后面五代是大数据架构模式。
其中有两个承前启后的地方:
一个特殊地方是,传统行业第三代架构与大数据第一代架构在架构形式上基本相似。传统行业的第三代架构可以算是用大数据处理技术重新实现了一遍。
传统行业第四代的架构中实时部分在现代用大数据实时方式做了新的落地。
如下图所示
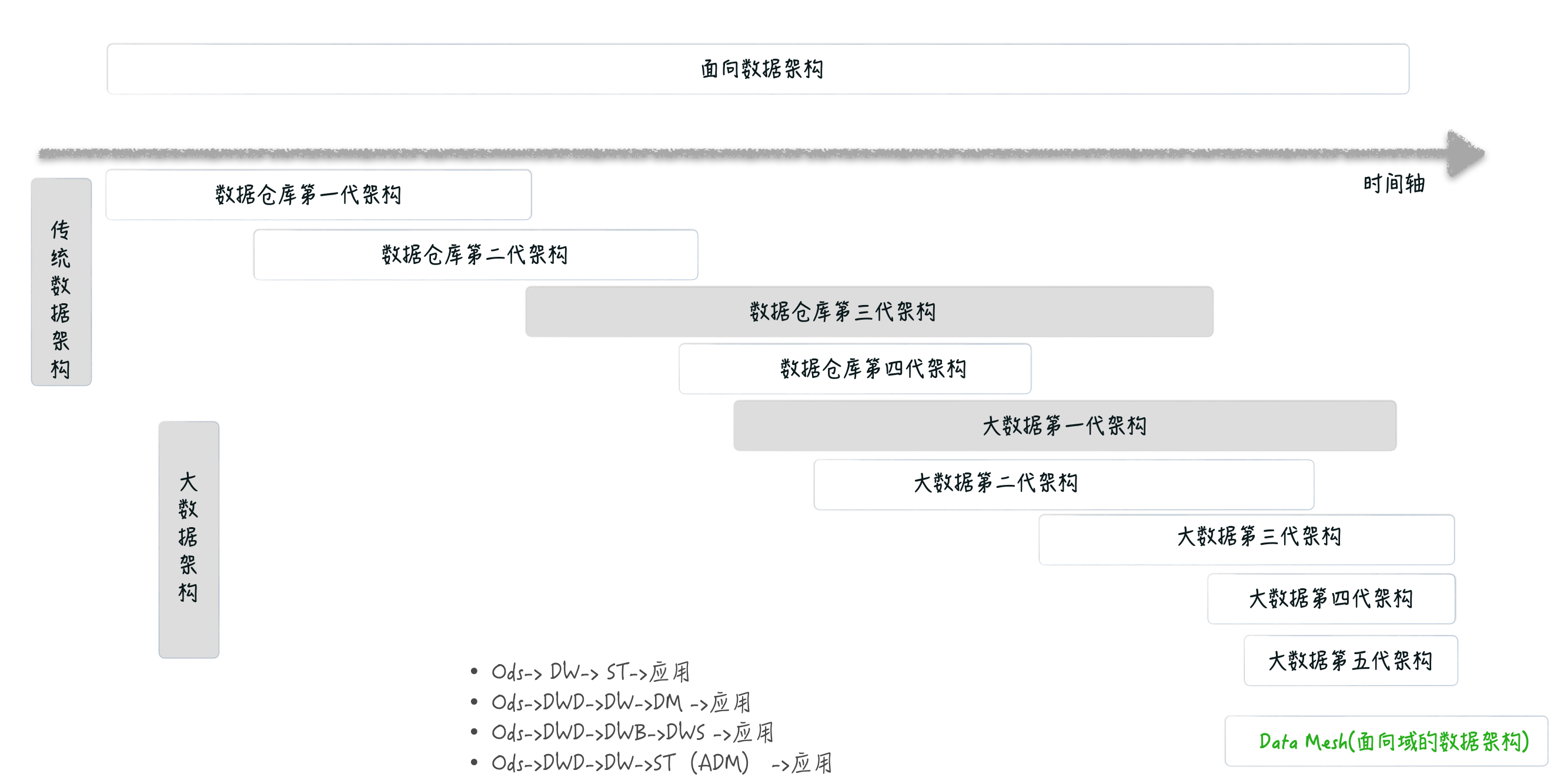
三个时代:非互联网、互联网、移动互联网时代,每一种时代的业务特点、数据量、数据类型各不相同,自然数据架构也是有显著差异的。
表格源自:《我所经历的大数据平台发展史》
从数据到大数据的数据架构总结
我自己对传统数据仓库的发展,简单抽象为为五个时代、四种架构(或许也不是那么严谨)。
五个时代大概,按照两位数据仓库大师 Ralph kilmball、Bill Innmon 在数据仓库建设理念上碰撞阶段来作为小的分界线:
大概在 1991 年之前,数据仓库的实施基本采用全企业集成的模式。
大概在 1992 年企业在数据仓库实施基本采用 EDW 的方式,Bill Innmon 博士出版了《如何构建数据仓库》,里面清晰的阐述了 EDW 架构与实施方式。
1994-1996 年是数据集市时代,这个时代另外一种维度建模、数据集市的方式较为盛行起来,其主要代表之一 Ralph Kimball 博士出版了他的第一本书“The DataWarehouse Toolkit”(《数据仓库工具箱》),里面非常清晰的定义了数据集市、维度建模。
大概在 1996-1997 年左右的两个架构竞争时代。
1998-2001 年左右的合并年代。
在主要历史事件中提到了两位经典代表人物:Bill Innmon、Ralph kilmball。这两位在数据界可以算是元祖级别的人物。现在数据中台/平台的很多设计理念依然受到他俩 90 年代所提出方法论为依据。
经典的 BIll Inmon 和 Ralph kilmball 争论
Bill Inmon 提出的遵循的是自上而下的建设原则,Ralph kilmball 提出自下而上的建设原则,两种方法拥护者会在不同场合争论哪一种方法论更有优势。
两位大师对于建设方法争论要点:
其中 Bill Inmon 的方法论:认为仅仅有数据集市是不够的,提倡先必须得从企业级的数据模型角度入手来构建。企业级模型就有较为完善的业务主题域划分、逻辑模型划分,在解决某个业务单元问题时可以很容易的选择不同数据路径来组成数据集市。
后来数据仓库在千禧年传到中国后,几个大实施厂商都是遵守该原则的实施方法,也逐渐的演进成了现在大家熟悉的数据架构中关于数据层次的划分 :
Ods-> DW-> ST->应用
Ods->DWD->DW->DM ->应用
Ods->DWD->DWB->DWS ->应用
Ods->DWD->DW->ST(ADM)->应用
上个 10 年的国内实施数据仓库以及数据平台企业,有几家专业的厂商:IBM、Teradata、埃森哲、菲奈特 (被东南收购)、亚信等。这些厂商针对自己领域服务的客户,从方案特点等一系列角度出发,在实施中对 ODS 层、EDW、DM 等不同数据层逐步地赋予了各种不同的功能与含义。
现在大家熟知的数据模型层次划分,基本上也是传承原有的 Bill Inmon 的方法论。
数据集市年代的代表人物为 Ralph kilmball,他的代表作是 《The Data Warehouse Toolkit》。这本书就是大名鼎鼎的《数据仓库工具箱》。企业级数据的建设方法主张自下而上建立数据仓库,极力推崇创建数据集市,认为数据仓库是数据集市的集合,信息总是被存储在多维模型中。
这种思想从业务或部门入手,设计面向业务或部门主题数据集市。随着更多的不同业务或部门数据集市实施落地,此时企业可以根据需要来合并不同的数据集市,并逐步形成企业级的数据仓库,这种方式被称为自下而上(Botton-up)方法。这个方法在当时刚好与 Bill Innmon 的自上而下建设方法相反。
随着数据仓库的不断实践与迭代发展,从争吵期进入到了合并的时代,其实争吵的结果要么一方妥协,要么新的结论出现。Bill inmon 与 Ralph kilmball 的争吵没有结论,干脆提出一种新的架构包含对方,也就是后来 Bill Inmon 提出的 CIF(corporation information factory)信息工厂的架构模式,这个架构模式将 Ralph kilmball 的数据集市包含了进来,有关两种数据仓库实施方法论的争吵才逐步地平息下来。
非互联网四代架构
第一代 edw 架构
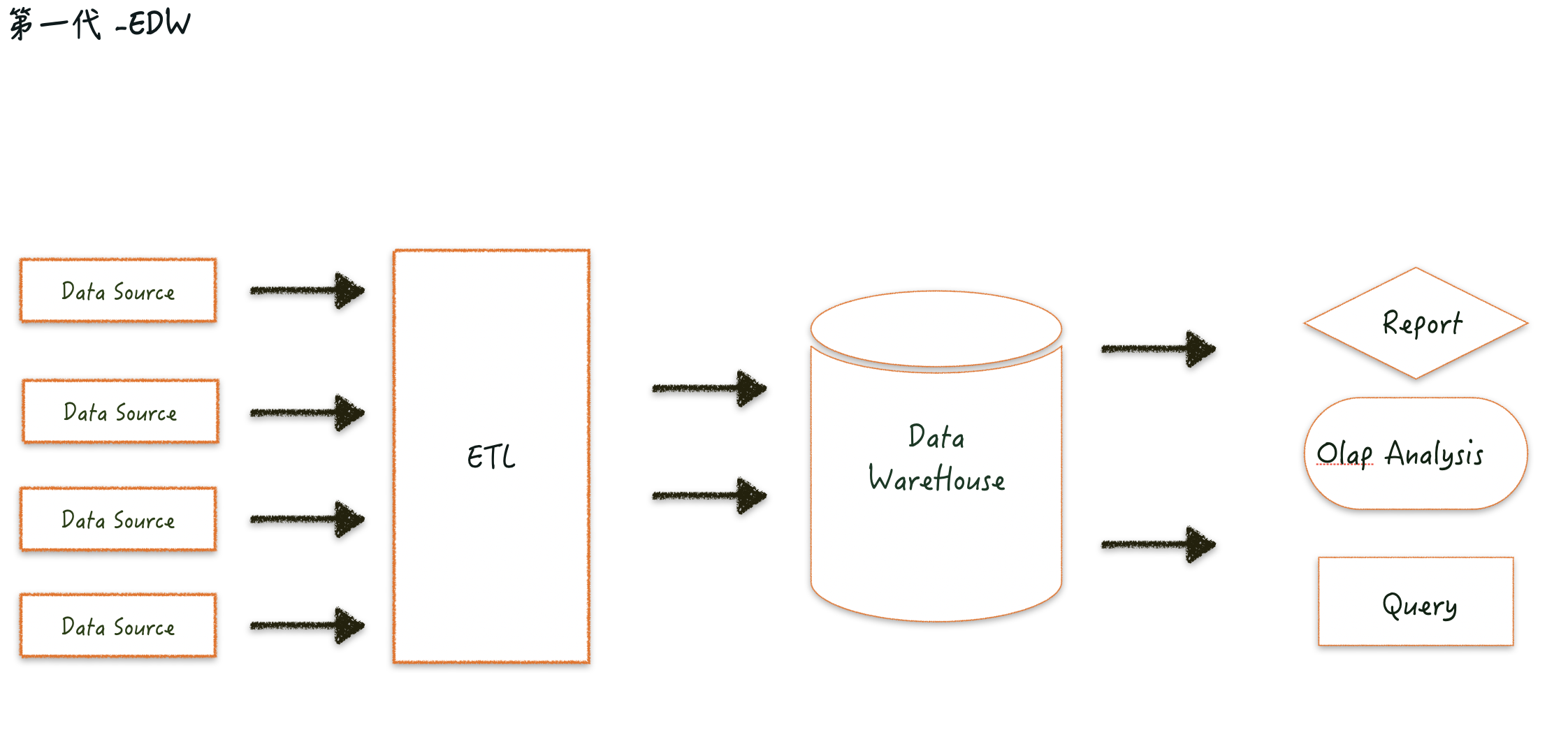
现在数据建设中使用到的“商业智能” 、“信息仓库”等很多专业术语、方法论,基本上是在上世纪 60 年代至 90 年代出现的。比如“维度模型”这个词是上世纪 60 年代 GM 与 Darmouth College 大学第一次提出, “DatawareHouse”、“事实” 是在上个世纪 70 年代 BIll Inmon 明确定义出来的,后来 90 年代 BIll Inmon 出版《如何构建数据仓库》一书更加体系化的与明确定义了如何构建数据仓库,这套方法在落地上形成了第一代数据仓库架构。
在第一代的数据仓库中,清晰地定义了数据仓库(Data Warehouse) 是一个面向主题的(Subject Oriented) 、集成的( Integrate ) 、相对稳定的(Non -Volatile ) 、反映历史变化( Time Variant) 的数据集合,用于支持管理决策( Decision Marking Support)。
首先,数据仓库(Data Warehouse)是用来支持决策的、面向主题的用来支撑分析型数据处理的,这里有别于企业使用的数据库。
数据库、数据仓库小的区别:
数据库系统的设计目标是事务处理。数据库系统是为记录更新和事务处理而设计,数据的访问的特点是基于主键,大量原子,隔离的小事务,并发和可恢复是关键属性,最大事务吞吐量是关键指标,因此数据库的设计都反映了这些需求。
数据仓库的设计目标是决策支持。历史的、摘要的、聚合的数据比原始的记录重要的多。查询负载主要集中在即席查询和包含连接,聚合等复杂查询操作上。
其次,数据仓库(Data Warehouse)是对多种异构数据源进行有效集成与处理,是按照主题的方式对数据进行重新整合,且包一般不怎么修改的历史数据,一句话总结面向主题、集成性、稳定性和时变性。
数据仓库(Data Warehouse)从特点上来看:
数据仓库是面向主题的。
数据仓库是集成的,数据仓库的数据有来自于分散的操作型数据,将所需数据从原来的数据中抽取出来,进行加工与集成,统一与综合之后才能进入数据仓库。
数据仓库是不可更新的,数据仓库主要是为决策分析提供数据,所涉及的操作主要是数据的查询。
数据仓库是随时间而变化的,传统的关系数据库系统比较适合处理格式化的数据,能够较好的满足商业商务处理的需求,它在商业领域取得了巨大的成功。
数据仓库和数据库系统的区别,一言蔽之:OLAP 和 OLTP 的区别。数据库支持是 OLTP,数据仓库支持的是 OLAP。
第二代大集市架构
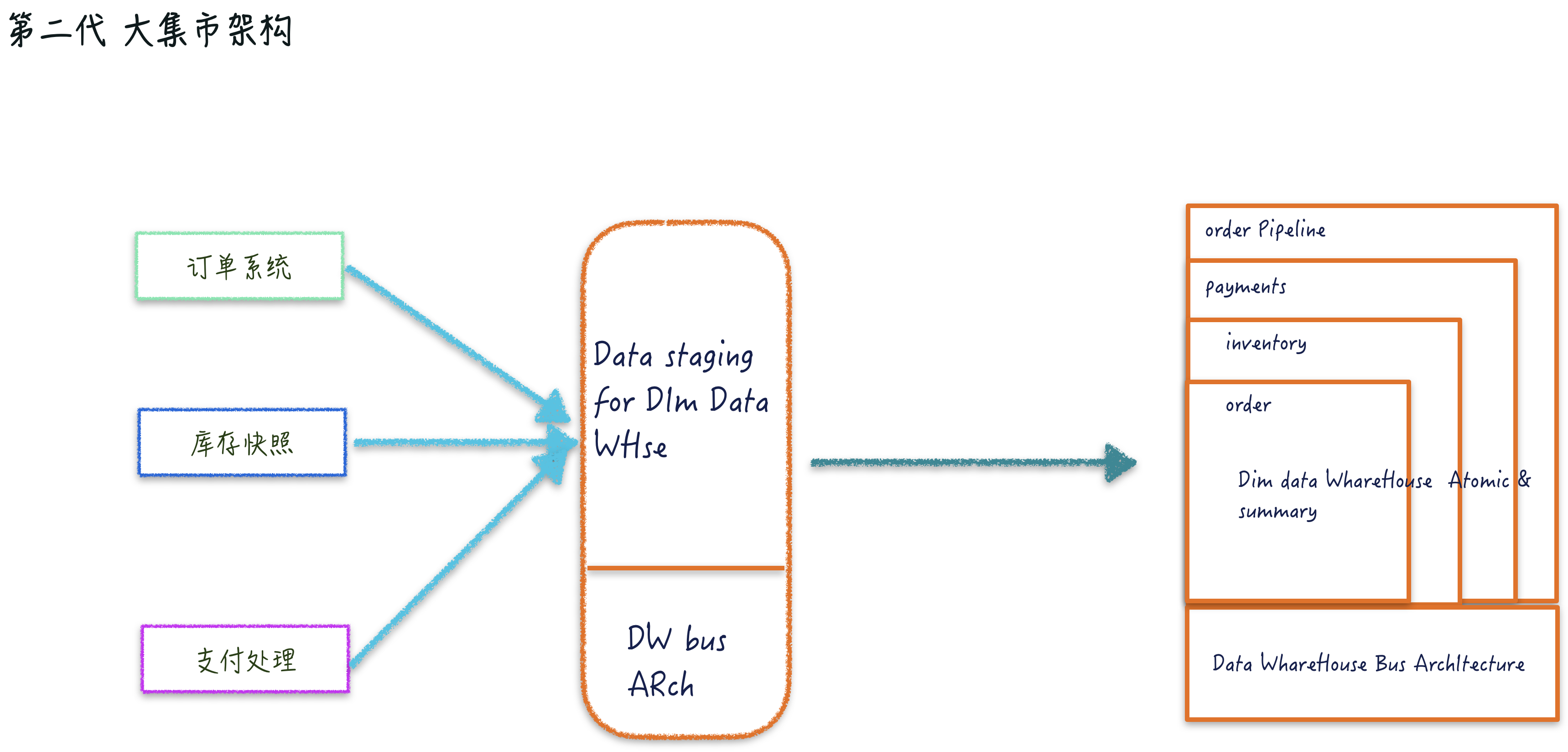
第二代就是 Ralph kilmball 的大集市的架构。第二代架构基本可以成为总线型架构,从业务或部门入手,设计面向业务或部门主题数据集市。Kilmball 的这种构建方式可以不用考虑其它正在进行的数据类项目实施,只要快速满足当前部门的需求即可,这种实施的好处是阻力较小且路径很短。
但是考虑到在实施中可能会存在多个并行的项目,是需要在数据标准化、模型阶段是需要进行维度归一化处理,需要有一套标准来定义公共维度,让不同的数据集市项目都遵守相同的标准,在后面的多个数据集市做合并时可以平滑处理。比如业务中相似的名词、不同系统的枚举值、相似的业务规则都需要做统一命名,这里在现在的中台就是全域统一 ID 之类的东西。
主要核心:
一致的维度,以进行集成和全面支持。一致的维度具有一致的描述性属性名称、值和含义。
一致的事实是一致定义的;如果不是一致的业务规则,那么将为其指定一个独特的名称。业务中相似的名词、不同系统的枚举值、相似的业务规则都需要做统一命名。
建模方式:星型模型、雪花模型。
第三代汇总维度集市 &CIF2.0 数仓结构
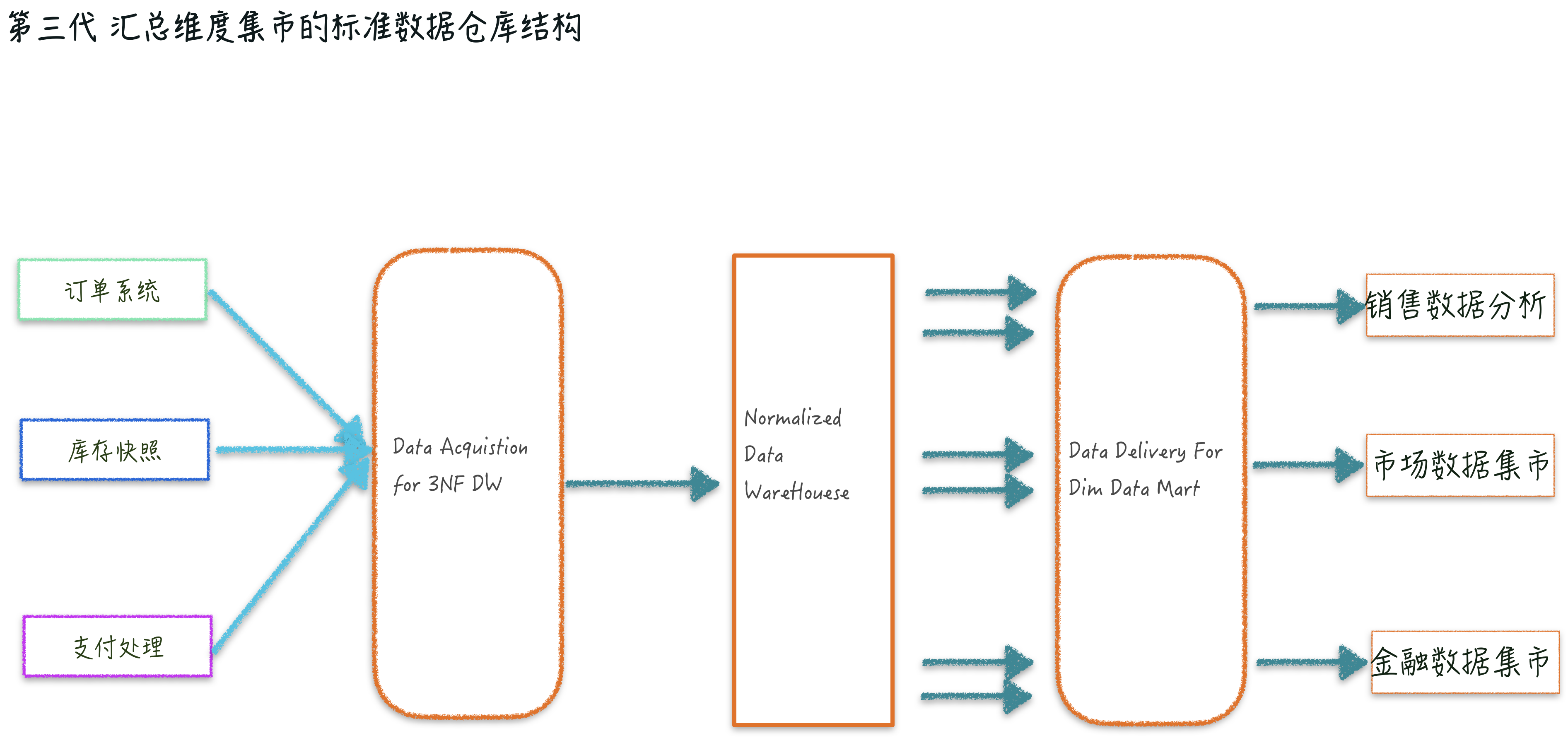
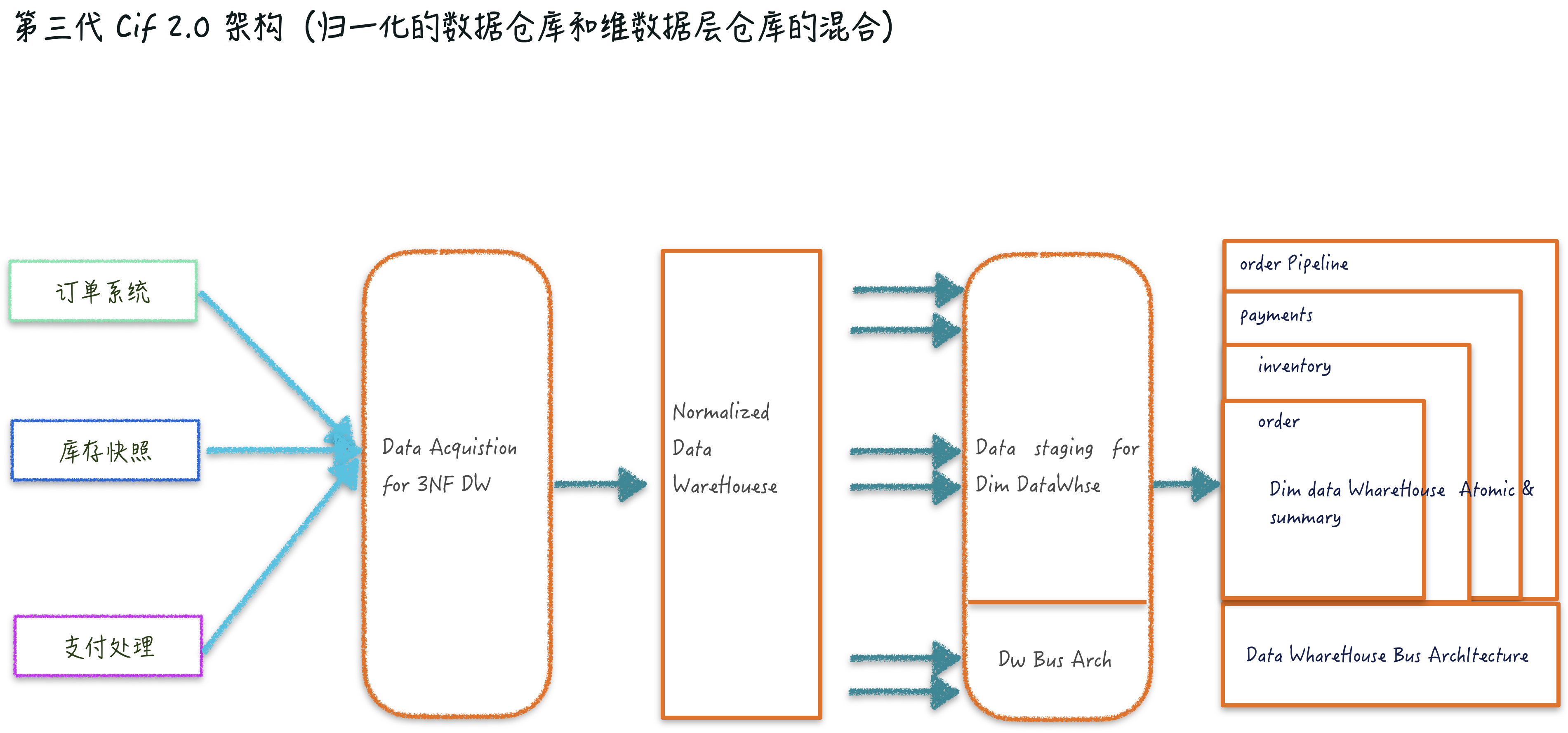
CIF(corporation information factor)信息工厂(作者备注,关于 Cif 的英文版文章名字 Corporate Information Factory (CIF) Overview),Bill Inmon 认为企业的发展会随着信息资源重要性会逐步的提升,会出现一种信息处理架构,类似工厂一样能满足所有信息的需求与请求。这个信息工厂的功能包含了数据存储与处理(活跃数据、沉默数据),支持跨部门甚至跨企业的数据访问与整合,同时也要保证数据安全性等。
刚好 CIF 架构模式也逐步的变成了数据仓库第三代架构。为什么把这个 CIF 架构定义成一个经典架构呢,因为 CIF 的这种架构总结了前面提到的两种架构的同时,又把架构的不同层次定义得非常明确。
例如 CIF 2.0 主要包括集成转换层(Integrated and Transformation Layer)、操作数据存储(Operational Data Store)、数据仓库(Enterprise Data Warehouse)、数据集市(Data Mart)、探索仓库(Exploration Warehouse)等部件。Data Mart 分为后台(Back Room)和前台(Front Room)两部分。后台主要负责数据准备工作,称为数据准备区(Staging Area),前台主要负责数据展示工作,称为数据集市(Data Mart)。
这个经典的架构在后来 2006 年~2012 年进入到这个领域的从业者,乃至现在有些互联网企业的数据平台架构也是相似的。
第四代 OPDM 操作实时数仓
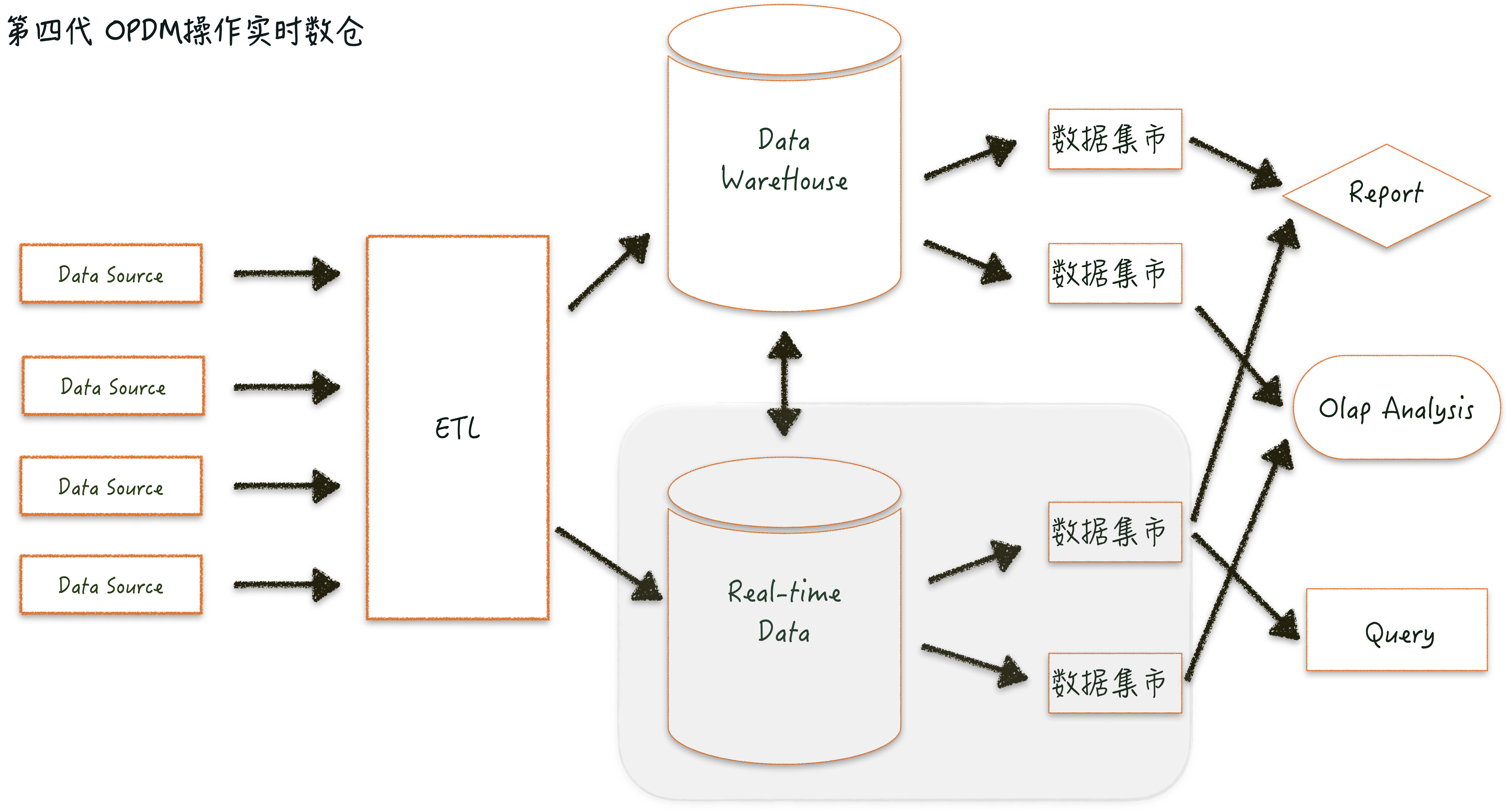
OPDM 大约是在 2011 年提出来的,严格上来说,Opdm 操作型数据集市(仓库)是实时数据仓库的一种,他更多的是面向操作型数据而非历史数据查询与分析。
在这里很多人会问到什么是操作型数据?比如财务系统、CRM 系统、营销系统生产系统,通过某一种机制实时的把这些数据在各数据孤岛按照业务的某个层次有机的自动化整合在一起,提供业务监控与指导。
互联网的五代大数据处理架构
备注:互联网这五代数据处理技术架构是参考了下面这两篇文章并有在具体实施中一些总结
《4 big data architectures, Data Streaming, Lambda architecture, Kappa architecture, and Unifield architecture 》 作者 :Sajjad Hussain
《常用的几种大数据架构剖析》作者:白发川 https://mp.weixin.qq.com/s/i01zzVG0iVQjRx5ctiNuqQ
在文章的开头有提过,传统行业第三代架构与大数据第一代架构在架构形式上基本相似,只不过是通过大数据的处理技术尝试对传统第三架构进行落地的。
比如说在 Hadoop&Hive 刚兴起的阶段,有用 SyaseIQ、Greenplum 等技术来作为大数据处理技术,后来 Hadoop&hive 以及 Facebook Scribe、Linkedin kafka 等逐步开源后又产生了新的适应互联网大数据的架构模式。
后续阿里巴巴淘系的 TImeTunnel 等更多的近百种大数据处理的开源技术,进一步促进了整个大数据处理架构与技术框架的发展,我在后面会给出一个比较完善截止到目前所有技术的数据处理框架。
按照大数据的使用场景、数据量、数据的类型,在架构上也基本上分为流式处理技术框架、批处理技术框架等, 所以互联网这五代的大数据处理框架基本上是围绕着批处理、流式处理以及混合型架构这三种来做演进。
第一代离线大数据统计分析技术架构
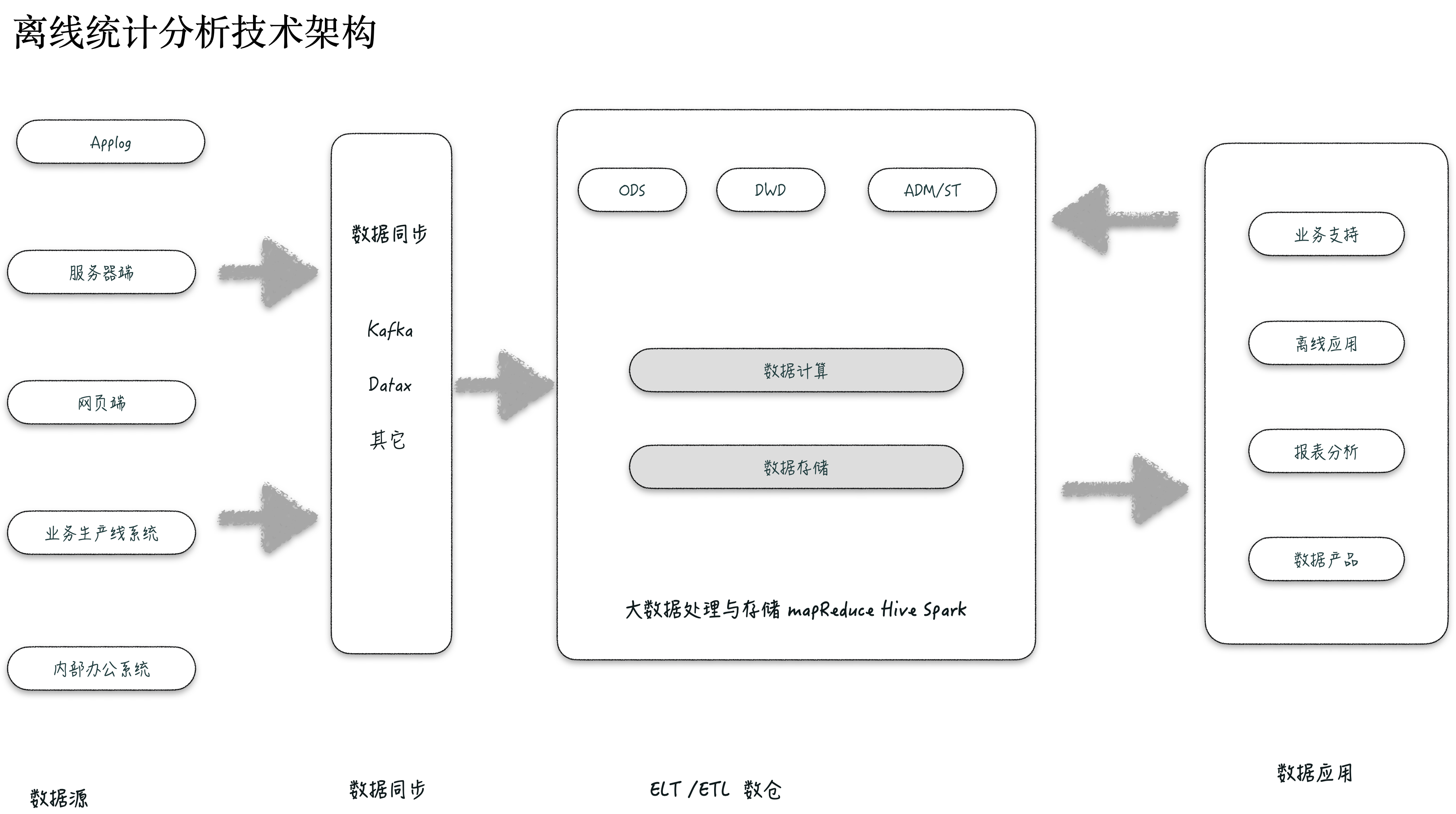
这个结构与第三代的数据处理架构非常相似,具体如下图所示:
第二代流式架构
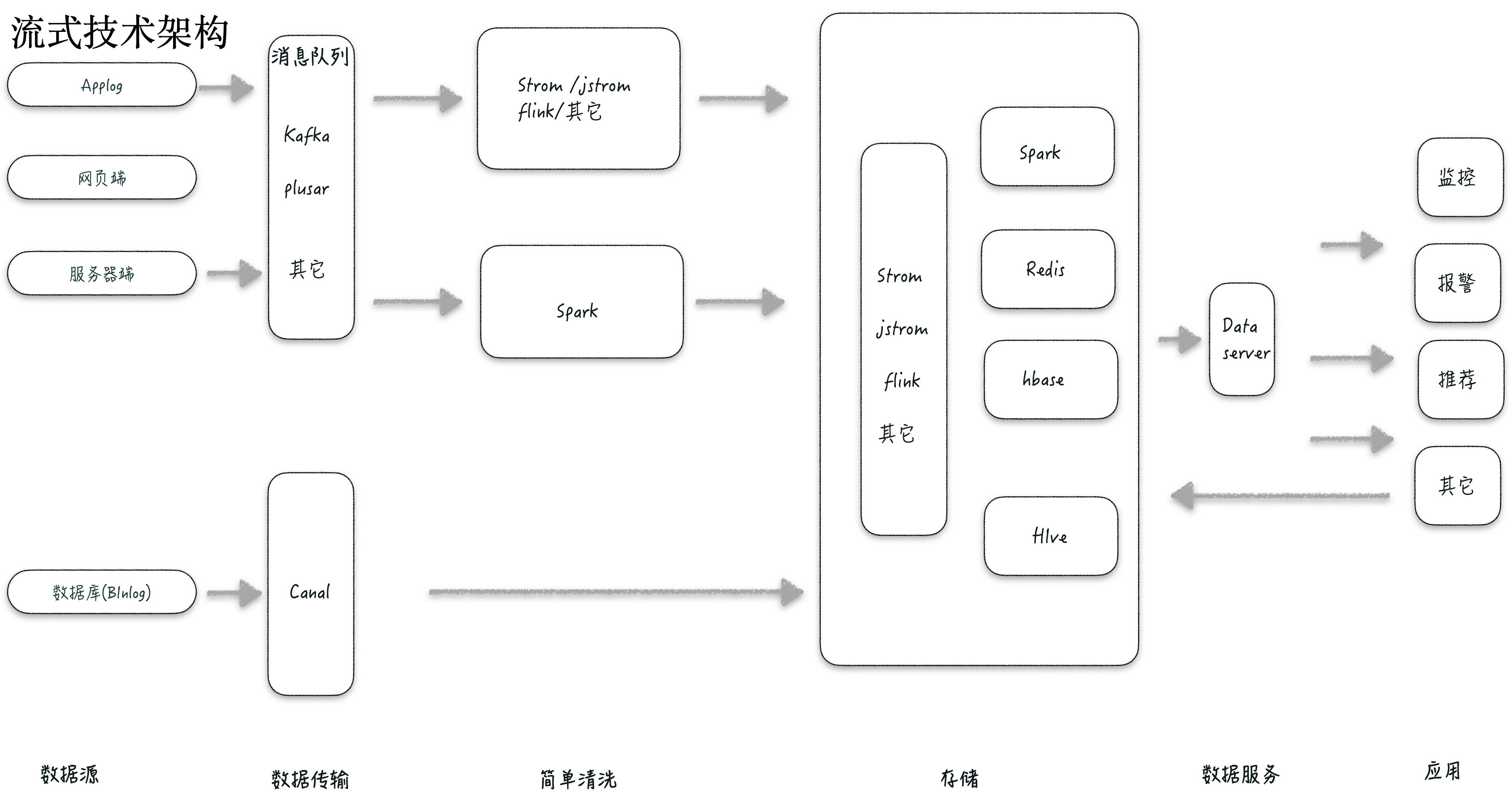
流式的应用场景非常广泛, 比如搜索、推荐、信息流等都是在线化的,对数据实时性的要求变更高,自然计算与使用是同步进行的。
随着业务的复杂化,数据的处理逻辑更加复杂,比如各种维度交叉、关联、聚类,以及需要更多算法或机器学习。这些应用场景可以完全地分为两类:事件流、持续计算。
事件流,就是业务相对固定,只是数据在业务的规则下不断的变化。
持续计算,适合购物网站等场景。
流失处理架构比上一代离线处理框架相比省掉了原有的 ETL/ELT 过程,数据流留过数据处理通道并进行实时处理与计算,处理结果通过消息的方式推送数据消费者。
流式计算框架舍弃了大数据离线批量处理模式,只有很少的数据存储,所以数据保存周期非常短。如果有历史数据场景或很复杂历史数据参与计算的场景,实现起来难度就比较大。
现在一些场景,会把流式计算的结果数据周期性地存到批处理的数据存储区域。如果有场景需要使用历史数据,流式计算框架会把保存的历史结果用更新的方式进行加载,再做进一步处理。
第三代 Lambda 大数据架构
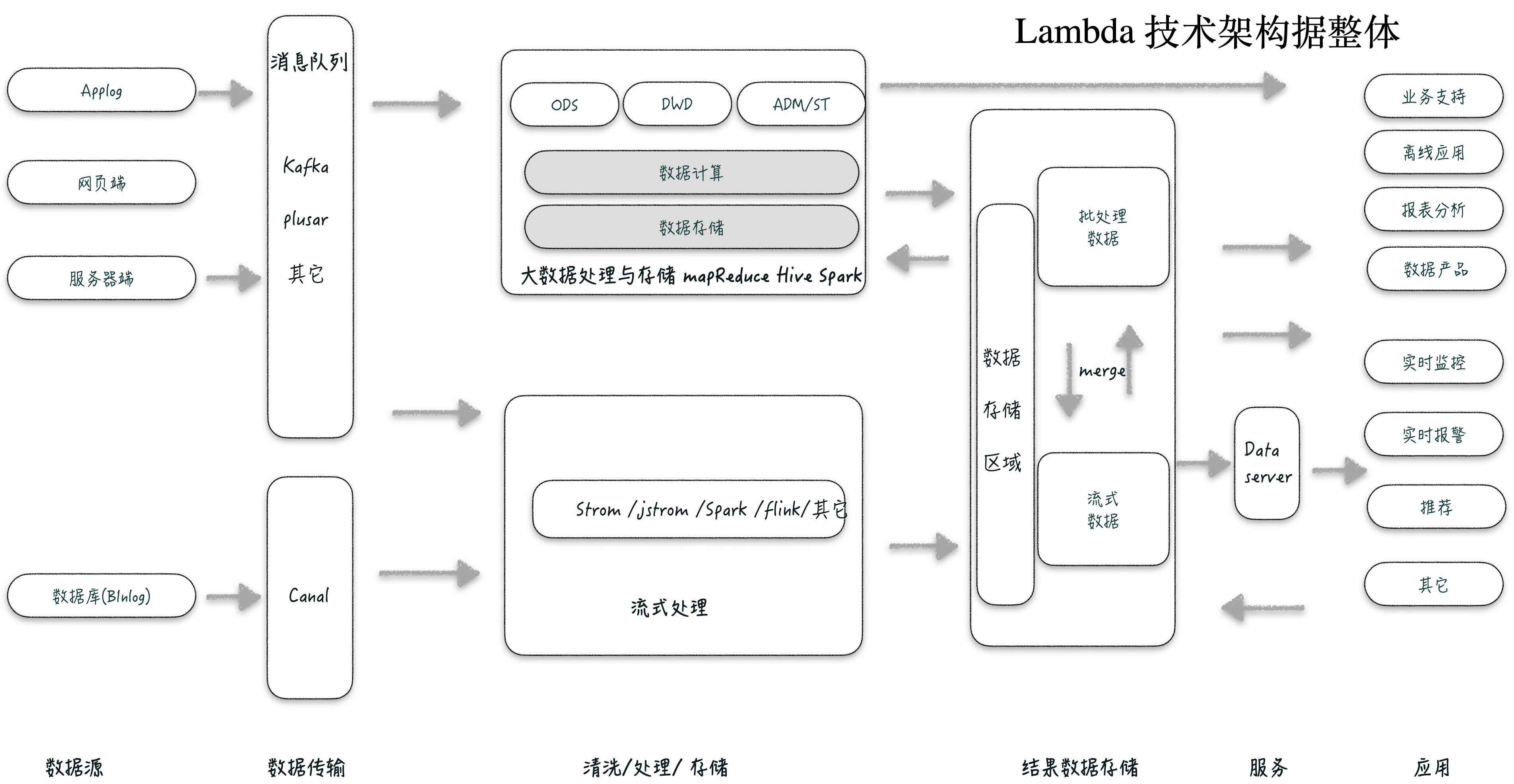
Lambda 架构是由 Twitter 工程师南森·马茨(Nathan Marz)提出的,是一种经典的、实施广泛的技术架构。后来出现的其他大数据处理架构也是 Lambda 架构的优化或升级版。
Lambda 架构有两条数据链路,一条兼顾处理批量、离线数据结构,一条是实时流式处理技术 。
批量离线处理流在构建时大部分还是采用一些经典的大数据统计分析方法论,在保证数据一致性、完整性的同时还会对数据按照不同应用场景进行分层。
实时流式处理主要是增量计算,也会跑一些机器学习模型等。为了保证数据的一致性, 实时流处理结果与批量处理结果会有一个合并动作。
Lambda 架构主要的组成是批处理、流式处理、数据服务层这三部分。
批处理层(Bathchlayer) : Lambda 架构核心层之一,批处理接收过来的数据,并保存到相应的数据模型中,这一层的数据主题、模型设计的方法论是继承面向统计分析离线大数据中的。 而且一般都会按照比较经典的 ODS、DWD、DWB、ST/ADM 的层次结构来划分。
流式处理层(Speed Layer) : Lambda 另一个核心层,为了解决比如各场景下数据需要一边计算一边应用以及各种维度交叉、关联的事件流与持续计算的问题,计算结果在最后与批处理层的结果做合并。
服务层( Serving layer) :这是 Lambda 架构的最后一层,服务层的职责是获取批处理和流处理的结果,向用户提供统一查询视图服务。
Lamabda 架构理念从出现到发展这么多年,优缺点非常明显。 比如稳定与性能上的优势,ETL 处理计算利用晚上时间来做,能复用部分实时计算的资源。劣势,两套数据流因为结果要做合并,所有的算法要实现两次,一次是批处理、一次是实时计算,最终两个结果还得做合并显得会很复杂。
Kappa 大数据架构
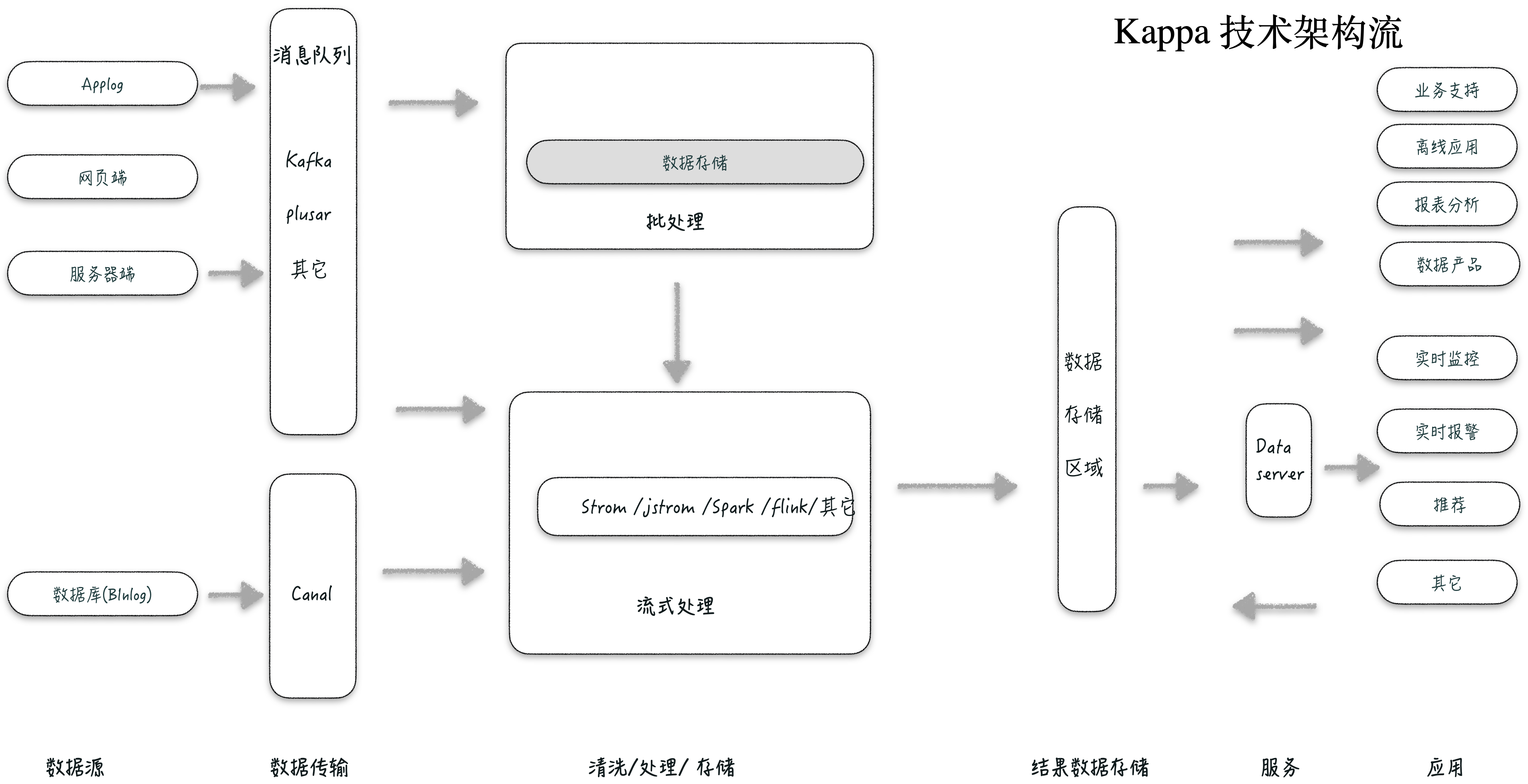
在 Lamadba 架构下需要维护两套的代码,为了解决这个问题,LinkedIn 公司的 Jay Kreps 结合实际经验与个人思考提出了 Kappa 架构。
Kappa 架构核心是通过改进流式计算架构的计算、存储部分来解决全量的问题,使得实时计算、批处理可以共用一套代码。Kappa 架构认为对于历史数据的重复计算几率是很小的,即使需要,可以通过启用不同的实例的方式来做重复计算。
其中 Kappa 的核心思想是:
用 Kafka 或者类似 MQ 队列系统收集各种各样的数据,需要几天的数据量就保存几天。
当需要全量重新计算时,重新起一个流计算实例,从头开始读取数据进行处理,并输出到一个新的结果存储中。
当新的实例做完后,停止老的流计算实例,并把一些老的结果删除。
Kappa 架构的优点在于将实时和离线代码统一起来,方便维护而且统一了数据口径。
Kappa 架构与 Lamabda 架构相比,其优缺点是:
Lambda 架构需要维护两套跑在批处理和实时流上的代码,两个结果还需要做 merge, Kappa 架构下只维护一套代码,在需要时候才跑全量数据。
Kappa 架构下可以同时启动很多实例来做重复计算,有利于算法模型调整优化与结果对比,Lamabda 架构下,代码调整比较复杂。所以 kappa 架构下,技术人员只需要维护一个框架就可以,成本很小。
kappa 每次接入新的数据类型格式是需要定制开发接入程序,接入周期会变长。
Kappa 这种架构过度依赖于 Redis、Hbase 服务,两种存储结构又不是满足全量数据存储的,用来做全量存储会显得浪费资源。
Unified 大数据架构
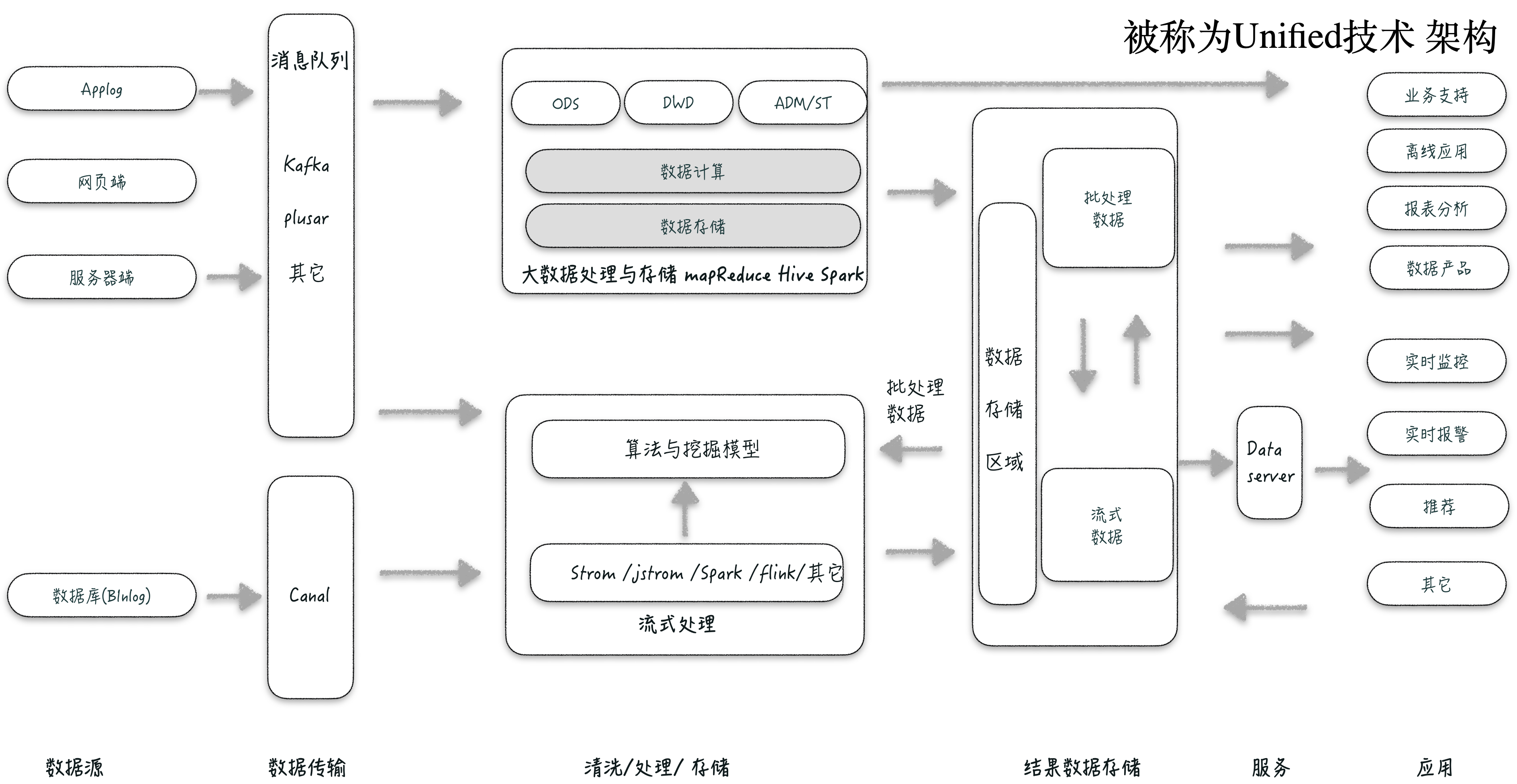
“Unifield 架构则更激进,将机器学习和数据处理整合为一体,Unifield 在 Lambda 基础上进行升级,在流处理层新增了机器学习层。数据经过数据通道进入数据湖,新增了模型训练部分,并且将其在流式层进行使用。同时流式层不单使用模型,也包含着对模型的持续训练。”
来自《常用的几种大数据架构剖析》作者白发川 https://mp.weixin.qq.com/s/i01zzVG0iVQjRx5ctiNuqQ
IOTA 架构
IOTA 大数据架构是一种基于 AI 生态下的、全新的数据架构模式,这个概念由易观于 2018 年首次提出。IOTA 的整体思路是设定标准数据模型,通过边缘计算技术把所有的计算过程分散在数据产生、计算和查询过程当中,以统一的数据模型贯穿始终,从而提高整体的计算效率,同时满足计算的需要,可以使用各种 Ad-hoc Query 来查询底层数据。
主要有几个特点:
去 ETL 化:ETL 和相关开发一直是大数据处理的痛点,IOTA 架构通过 Common Data Model 的设计,专注在某一个具体领域的数据计算,从而可以从 SDK 端开始计算,中央端只做采集、建立索引和查询,提高整体数据分析的效率。
Ad-hoc 即时查询:鉴于整体的计算流程机制,在手机端、智能 IOT 事件发生之时,就可以直接传送到云端进入 real time data 区,可以被前端的 Query Engine 来查询。此时用户可以使用各种各样的查询,直接查到前几秒发生的事件,而不用在等待 ETL 或者 Streaming 的数据研发和处理。
边缘计算(Edge-Computing):将过去统一到中央进行整体计算,分散到数据产生、存储和查询端,数据产生既符合 Common Data Model。同时,也给与 Realtime model feedback,让客户端传送数据的同时马上进行反馈,而不需要所有事件都要到中央端处理之后再进行下发。
可能是由于我接触到的范围有限,暂时还没有遇到一家企业完整按照 IOTA 这个架构模式来实施的,暂时没有更多的个人经验来分享这块。
小结
大数据架构的每一代的定义与出现是有必然性的, 当然没有一个严格上的时间区分点。直接给出一个每种架构比较:
架构讲完了,落地肯定是离不开技术的,我之前花了不少时间整理了一下目前大数据方向的技术栈的内容。
大数据处理技术栈
分享完了架构,在从大数据技术栈的角度来看看对应的数据采集、数据传输、数据存储、计算、ide 管理、分析可视化微服务都有哪些技术,下图的技术栈我花了蛮多的时间梳理的。

按照数据采集-传输-落地到存储层,再通过调度调起计算数据处理任务把整合结果数据存到数据仓库以及相关存储区域中。
通过管理层/ide 进行数据管理或数据开发。
通过 OLAP 、分析、算法、可视化、微服务层对外提供数据服务与数据场景化应用。
这个技术栈暂时没有按照没有按照批处理、流式技术的分类的角度来分类,稍微有点遗憾。
Data Mesh 面向域的分散式数据架构
Data Mesh 是在 2019 年左右,由 ThoughtWorks 的首席技术顾问 Zhamak Dehghani 提出的(《How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh》https://martinfowler.com/articles/data-monolith-to-mesh.html)。她将对客户进行企业数据平台实施过程出现的问题和面向领域设计中的微服务结合了起来,思考出来了一种新式面向域的数据架构。
企业面向数据平台的实施中,不管是数据 BI 系统,还是基于大数据(数据湖)架构模式,或者是基于云数据平台,无一例外地延续着一个架构(Monolithic Architecture)的核心模式,只是这个架构的表现形式从一个严格规范化的数据仓库,到更加专业的大数据(数据湖),最终转化成一个多种实践模式的混合。
现在这些大数据平台实施与解决方案难以通过简单复制来达到规模化、商业化,企业数据平台项目实施要三到五年的时间,巨大的投入使得投入产出比不够高,很难获取预期的收益。原文提到 Zhamak Dehghani 基于对企业数据平台架构现状和弊端以及微服务的视角提出了 Data Meth 面向域的分布式架构模式。这个架构模式有四个特点:
面向域的数据架构
自服务式的平台基础设施
数据产品导向的管理与角色
基于灵活、规模化、演进式的基础设施交付能力
讲一下自己的理解(可能理解还是比较浅):
面向域的数据架构:对数据内容即插即用的类似一种 SaaS 能力,比如根据领域建模来设计数据模型,比如之前 IBM 的 IAA 模型,Teradata 金融标准模型提到的用户主题域,参与者主题域、地址主题、集团客户主题等等,这类主题有自己的数据接入标准。比如通过数据处理流程、统计指标、数据资产管理的模板化配置,只关心输入内容就可以得到完整输出,并且自动完成合规、安全、管理以及运营型的一些工作。
自服务式的平台基础设施:为数据域架构中提到落地功能提供必要的产品能力,例如提供各种快速组件化、配置化的基础模板工具。像是提供自动化数据加工管理,数据模型建模到自动化 ETL 过程,指标维度分析模板、数据应用模板等,最终实现自动化与规模化。(以前自己设计过一个自动化 ETL 引擎,并实现了最小迷你版落地,但是待解决的问题还比较多)。
数据产品导向的管理与角色,数据的价值本身就是透过数据产品对外进行传递,从数据产品的角度来说偏业务数据产品、偏工具平台数据产品,这些都是在推进数据平台的建设,自然不管数据价值的透传方式、效率、洞察等都会通过租户使用平台工具去建设自己的数据能力。
自己也在思考未来给企业提供的数据服务能力是什么样子,以及基于元数据驱动数据中台/平台是什么样子的。
写在结尾
自己在 2015 年时曾经写过一篇从数据团队组织变化角度来分享大数据的架构进化的文章,这次从大数据处理架构做了一个发展总结,两个角度基本上涵盖了数据中台/平台建设比较重点两个问题。
在上一篇中提到一个话题:数据中台是有组织结构的保障,很多地方都有提到数据中台必须得有强力的组织上的保障!确实需要吗?我的观点是什么呢?这个系列的下一篇给大家讲解数据中台的组织结构。
参考与引用
互联网的五代数据处理架构:《4 big data architectures, Data Streaming, Lambda architecture, Kappa architecture, and Unifield architecture》 作者 :Sajjad Hussain
《常用的几种大数据架构剖析》作者:白发川 https://mp.weixin.qq.com/s/i01zzVG0iVQjRx5ctiNuqQ
相关文章:
作者简介:
松子(李博源),BI& 数据产品老兵一枚,漂过几个大厂。2016 年到现在持续输出原创内容几十篇,《中台翻车纪实》 、《从数据仓库到大数据,数据平台这 25 年是怎样进化的》 、《数据产品三部曲系列》等系列有思考深度的文章。




