
OpenAI 的员工 Sherwin Wu 和 Atty Eleti 在 QCon 上讨论了如何使用 OpenAI API 将这些大语言模型集成到应用程序中,并通过使用 API 和工具将 GPT 连接到外部世界以扩展 GPT 的功能。
Atty Eleti:我想带大家回到 1973 年,也就是 50 年前。1973 年,《科学美国人》(Scientific American)发表了一篇非常有趣的文章,他们在文章中比较了各种动物的运动。他们着手比较运动的效率。换句话说,一只动物从 A 点到 B 点燃烧了多少卡路里,与它们的体重等是否有关?他们比较了各种动物,鸟类、昆虫,当然还有我们人类,并将它们根据效率从高到低进行了排名。他们发现,就运动的效率而言,秃鹫的最高。
秃鹫是一种美丽的鸟类,原产于加利福尼亚州和南美洲的一些地区,有时它可以飞数百英里而无需扇动翅膀。它具有非常好的滑翔能力。另一方面,人类行走,在榜单中的排名相当平庸,大约排在榜单三分之一的位置。《科学美国人》这篇文章的精妙之处在于,除了所有物种之外,他们还增加了一个项目,那就是骑自行车的人。骑自行车的人在竞争中大获全胜,击败了所有竞争对手,其运动效率几乎是秃鹫的两倍。
我很喜欢这个故事,因为它有一个很简单的认识,只要用一点工具,有一点机械帮助,我们就能极大地增强我们的能力。你们中的一些人可能以前听过这个故事。你可能会想,我是在哪里看到的?这个故事是苹果公司创立之初史蒂夫·乔布斯(Steve Jobs)经常讲的。他和苹果团队利用这个故事作为早期 Macintosh 的灵感来源。史蒂夫比较了这个故事,并说到:“人类是工具的制造者。”
我们制造了像自行车这样的工具来增强我们完成任务的能力。就像自行车是运动的工具一样,计算机也是我们思维的工具。它增强了我们的能力、创造力、想象力和生产力。事实上,史蒂夫曾经用这个神奇的短语来形容个人计算机。他说:“计算机是思维的自行车”。这篇文章发表十年后的 1983 年,苹果公司发布了 Macintosh,并掀起了个人计算的革命。当然,多年后的今天,我们仍然每天都在使用 mac 电脑。
2023——人工智能和语言模型
那是 1973 年。现在是 2023 年,50 年后,计算已经发生了很大的变化。如果《科学美国人》的工作人员再次进行这项研究,我敢打赌他们会在名单上再增加一个“物种”。对我们大多数人来说,这个“物种”在公众的想象中只存在了大约六个月的时间。我谈论当然是人工智能,或者具体来说是语言模型。
自去年 11 月 ChatGPT 推出以来,人工智能和语言模型已经在全球范围内引起了公众的广泛关注。更令人兴奋的是,它们吸引了世界各地开发者的想象力。我们已经看到很多人将人工智能集成到他们的应用程序中,使用语言模型来构建全新的产品,并提出与计算机交互的全新方式。自然语言交互终于成为了可能,并且质量很高。但这存在局限性,也存在问题。对于任何使用过 ChatGPT 的人来说,我们都知道它的训练数据是 2021 年 9 月之前的,所以它不知道当前的事件。
在大多数情况下,像 ChatGPT 这样的语言模型是根据训练中的记忆进行操作的,因此它们与当前事件或所有 API、我们每天使用的自己的应用程序和网站无关。或者,如果你在一家公司工作,它不会连接到你公司的数据库和你公司的内部知识库等等。这使得语言模型的使用受到了限制。你可以写一首诗,可以写一篇文章,可以从中得到一个很棒的笑话,可以搜索一些东西。但如何将语言模型与外部世界联系起来呢?如何增强人工智能的能力,让它来代表你执行行动,让它做比它固有能力更多的事情呢?
概述
如果计算机是思维的自行车,那么人工智能思维的自行车是什么?这就是我们要探讨的问题:一辆人工智能思维的自行车。我们将讨论 GPT,这是 OpenAI 开发的一组旗舰语言模型,以及如何将它们与工具或外部 API 和函数集成,以支持全新的应用程序。我叫 Atty。是 OpenAI 的一名工程师。Sherwin 是我的搭档,我们是 OpenAI 的 API 团队的成员,共同构建了 OpenAI API 和其他各种开发者产品。
我们将讨论三件事。首先,我们将讨论语言模型及其局限性。我们将快速介绍它们是什么以及它们是如何工作的。先培养下对它们的直观认识。然后还要了解它们的不足之处。其次,我们将讨论我们发布的一个全新特性,即使用 GPT 进行函数调用。函数调用是将 OpenAI 的 GPT 模型插入外部世界并让它执行操作的方式。最后,我们将通过三个快速演示样例来演示如何使用 OpenAI 模型和 GPT 函数调用功能,并将其集成到公司产品和辅助项目中。
大语言模型(LLMs)及其局限性
Sherwin Wu:首先,我想对 LLM 做一个非常高层级的概述:它们做什么,它们是什么,它们如何工作。然后再谈谈它们开箱即用的一些限制。对于那些已经关注这个领域一段时间的人来说,这可能是你们都知道的信息,但我只是想在深入讨论细节之前确保我们都能达成共识。
非常高层级的 GPT 模型,包括 ChatGPT、GPT-4、GPT-3.5-turbo,它们都是我们所说的自回归语言模型。这意味着它们是巨大的人工智能模型,它们接受过庞大的数据集的训练,包括互联网、维基百科、公共 GitHub 代码和其他授权材料。它们被称为自回归,因为它们所做的只是综合所有这些信息。它们接受一个 prompt,或者我们可以称之为上下文。它们查看 prompt。然后它们基本上只是决定,给定这个 prompt,给定这个输入,下一个单词应该是什么?它实际上只是在预测下一个单词。

例如,如果给定 GPT 的输入是,“the largest city in the United States is“(美国最大的城市是),那么答案就是 New York City(纽约市)。它会一个字一个字地思考,它会说“New”、“York”,然后是“City”。同样,在更具对话性的环境中,如果你问它地球和太阳之间的距离是多少。GPT 已经从互联网上学过这个,它将输出 9400 万英里。它是根据输入逐个单词逐个单词思考的。

在底层,它真正做的是每次输出单词时,都会查看一堆候选单词并为它们分配概率。例如,在最初的例子中,“美国最大的城市是”,它可能有很多候选城市,New 代表“纽约”(New York),或者“新泽西”(New Jersey),或者其他什么,Los 代表“洛杉矶”(Los Angeles),然后还有其他一些可能的例子。你可以看到,它确实认为“New York City”(纽约市)可能是正确的答案,因为 New 的概率为 95%。在这种情况下,它通常会选择最有可能的结果,所以它会选择 New,然后继续前进。这个单词出现后,我们现在就知道 New 是第一个单词,所以它对下一个单词是什么就有了更多的限制。
我们可以看到,现在它认为 New York(纽约)的可能性要高得多,但它也在考虑 New Brunswick(新不伦瑞克)、New Mexico(新墨西哥)和 New Delhi(新德里)等。直到完成第二个单词,这基本上是模型的叠加。它基本上知道答案是 New York City,概率几乎是 100%。但它仍在考虑其他一些剩余概率很低的选项,比如 County(县)、New York Metro(纽约地铁)、New York Times(纽约时报),但最终它选择了 City 并给出答案。
对于更机敏的 LLM 人士来说,这在技术上过于简单化了。我们并不是真正在预测单词,而是在预测 token,比如单词片段,这实际上是一种更有效的表达英语的方式,主要是因为单词片段会在一堆不同的单词中重复,而不是单词本身会重复。但概念仍然是一样的。LLM 在这种上下文中,很可能会连续输出一堆不同的 token。就是这样,这就是这些语言模型的真正含义。了解了这一点,我认为让我们很多人感到惊讶的疯狂之处在于,我们只需预测下一个单词就可以走得很远。
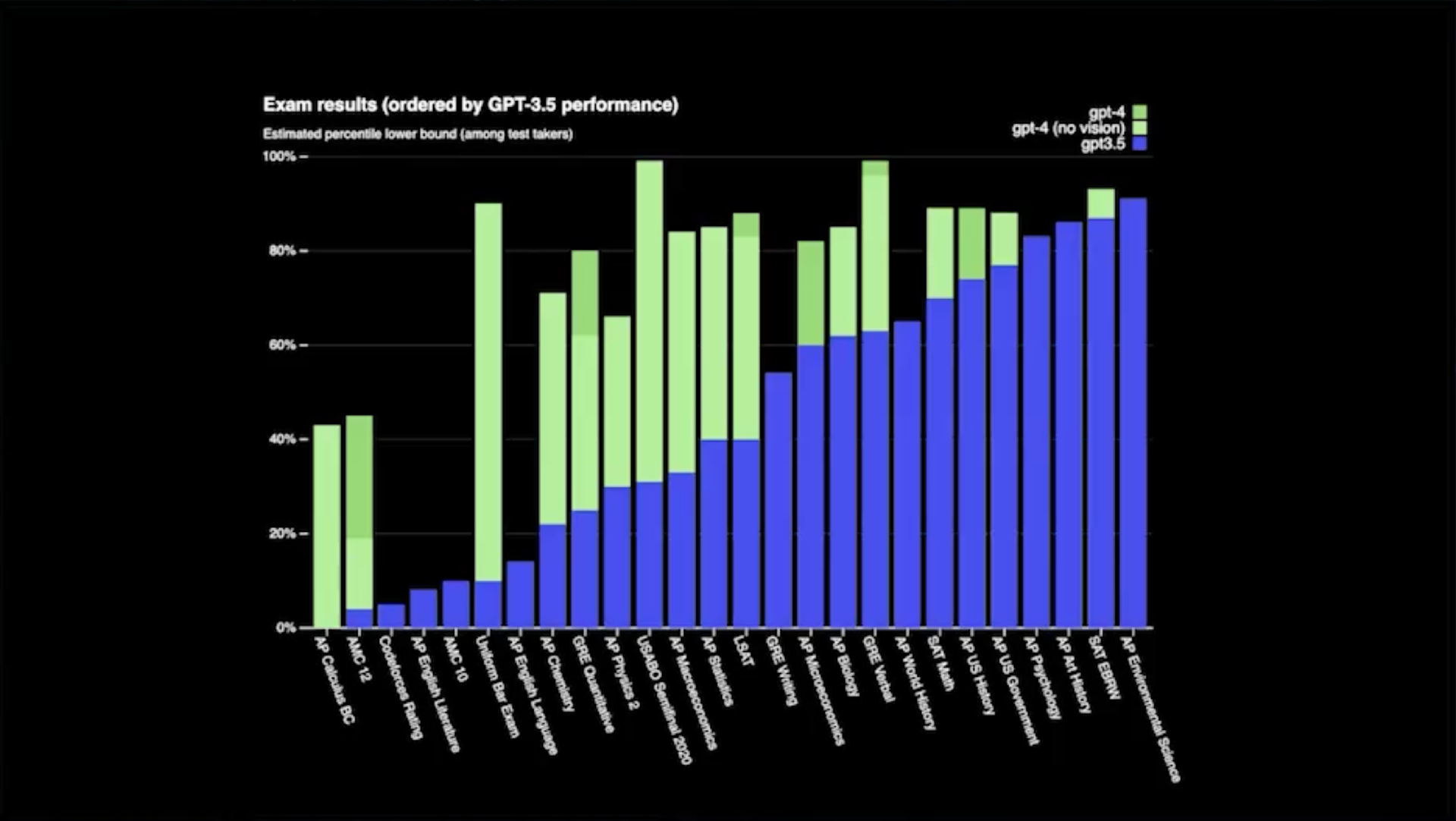
这张图表来自我们今年 3 月发布的 GPT-4 博客文章,它显示了我们最有能力的模型 GPT-4 在各种专业考试中的表现。这实际上只是 GPT-4 根据问题预测下一个单词。你可以看到,在很多不同的考试中,它的表现实际上和人类一样,甚至超过了人类的表现。y 轴是考生的百分位数。在 AP 考试、GRE 考试、LSAT 考试、美国生物奥林匹克竞赛等一系列不同的考试中,它基本上处于第 80 个百分位,有时甚至是第 90 个百分位,甚至是第 100 个百分位。
在这一点上,很多这样的测试我甚至都做不到,所以 GPT-4 远远超出了我自己的能力,而这只是来自对下一个单词的预测。这真的太酷了。你可以用它构建很多很酷的东西。任何一个已经学习了 LLM 一段时间的人都会意识到,我们很快就会遇到一些限制。当然,最大的一个是开箱即用的 LLM 或 GPT 实际上是一个装在盒子里的人工智能。它无法进入外部世界。它不知道任何其他信息。它就在那里,有它自己的记忆。感觉就像你在学校里参加考试时,只有你和考试,你只能根据记忆来回忆一些东西。
想象一下,如果考试是开放的,你可以使用手机或类似的东西,你会做得更好。GPT 今天真的只是在它自己的盒子里。正因为如此,作为工程师,我们希望使用 GPT 并将其集成到我们的系统中。限制 GPT,不允许它与我们的内部系统对话,这对于你可能想做的事情来说是非常有限的。此外,即使它确实可以访问某些工具,因为语言模型是概率性的,有时也很难保证模型与外部工具交互的方式。如果你有一个 API 或其他你想要使用的东西,当前模型不能保证总是能与你 API 可能想要的输入相匹配时,这最终也会成为一个问题。

例如,如果我正在构建一个应用程序,并将此输入提供给 GPT,基本上就是说,下面是一个剧本的文本,从中提取一些信息,并以这种 JSON 格式对其进行结构化。我真的只是给它一个剧本,让它推断出一种类型和一个子类型,以及其中的一些角色和年龄范围。我真正想要的是,我希望它能输出像这样的东西。就像 JSON 输出一样。
也许这是一个关于哈利波特的浪漫故事之类的剧本。它知道这是浪漫的,青少年的浪漫,它看到罗恩(Ron)和赫敏(Hermione),并以这种 JSON 格式准确输出。这太棒了,因为我可以获取这个输出,现在我可以使用它并将其放入 API 中。然后我就像在我的代码中一样,一切都正常。问题是,它大概只有 80%、70%的概率是这样的。
在剩下的时间里,它会尝试并提供额外的帮助,做一些像这样的事情,它会说:“当然,我可以为你做。下面是你要求的 JSON 格式的信息。”这是非常有用的,但如果你试图将其插入到 API 中,它实际上室不起作用的,因为前面所有这些随机文本,你的 API 并不知道如何解析它。这显然是非常令人失望的。这不是你真正想要的。我们真正想做的是,帮助 GPT 打破常规,或者给 GPT 一辆自行车或另一套工具来真正增强它的能力,并让它无缝地工作。
使用 GPT 进行调用函数
这就把我们带到了下一部分,那就是我们所说的 GPT 函数调用,这是我们发布的 API 的一个新变化,它使函数调用能够以一种非常一流的方式更好地使用我们的 GPT 模型。举个例子,如果你问 GPT 这样的问题,what's the weather like in Brooklyn today? (今天布鲁克林的天气怎么样?)如果你问一个普通的 GPT 这个问题,它基本上会说,“作为一个由 OpenAI 训练的人工智能模型,我无法提供实时信息。”这是真的,因为它实际上无法访问任何东西。它在一个盒子里。它怎么会知道今天天气怎么样呢?
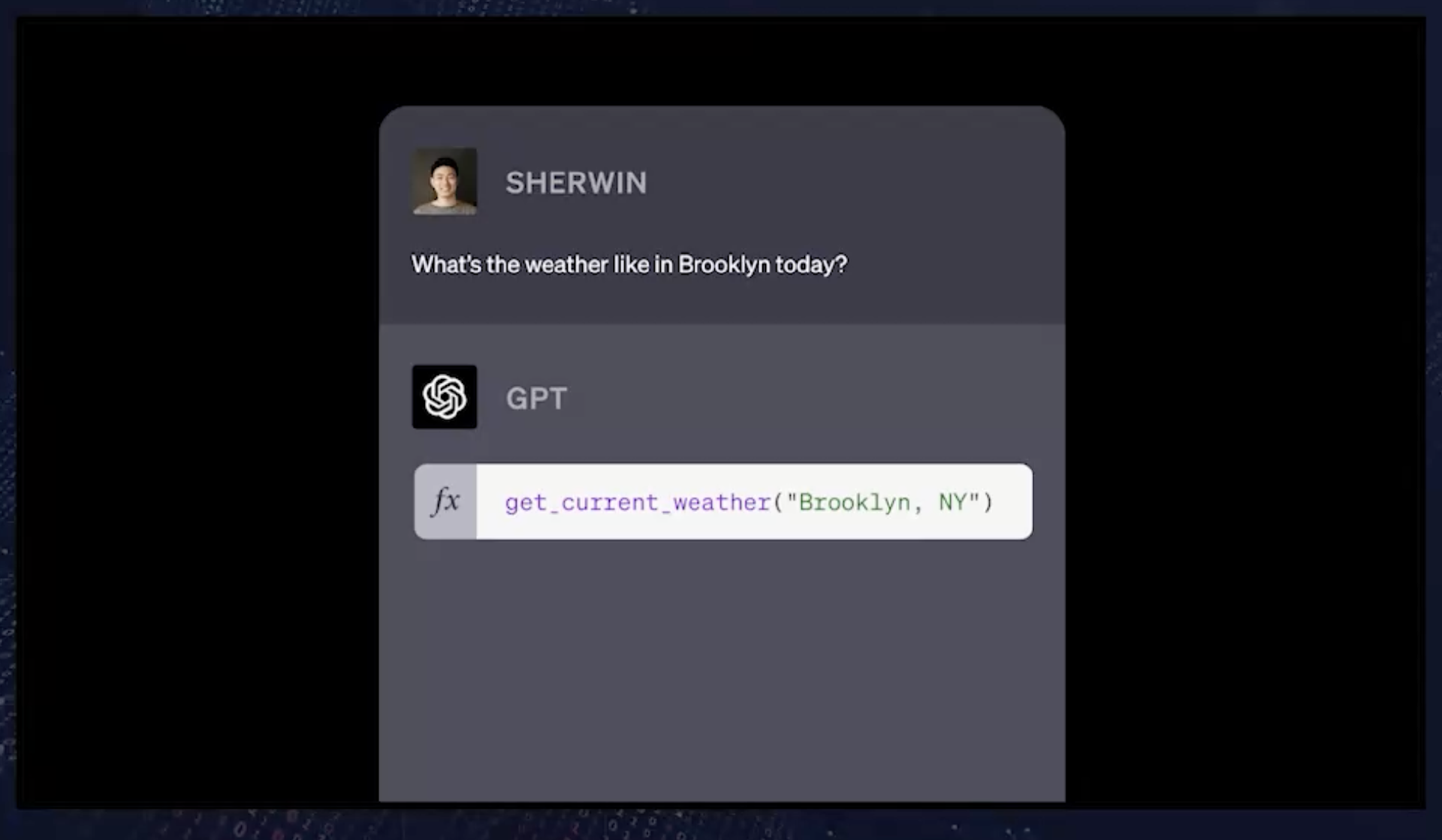
这显然确实限制了它的能力,这是不可取的。我们所做的是更新了 GPT-4 和 gpt-3.5-turbo 模型或旗舰模型。我们收集了大量的工具使用和函数调用数据,根据这些数据对我们的模型进行了微调,使其真正擅长选择是否使用工具。最终的结果是我们发布了一组新的模型,这些模型现在可以为你智能地使用工具和调用函数。在这个特殊的例子中,当我们询问模型“今天布鲁克林的天气怎么样?”时,我现在能做的就是解析这个输入,同时告诉它一组函数,或者在本例中,告诉它它可以访问的一个函数,如果需要帮助,它应该尝试并调用这个函数。在本例中,我们将为它提供一个名为get_current_filther的函数。
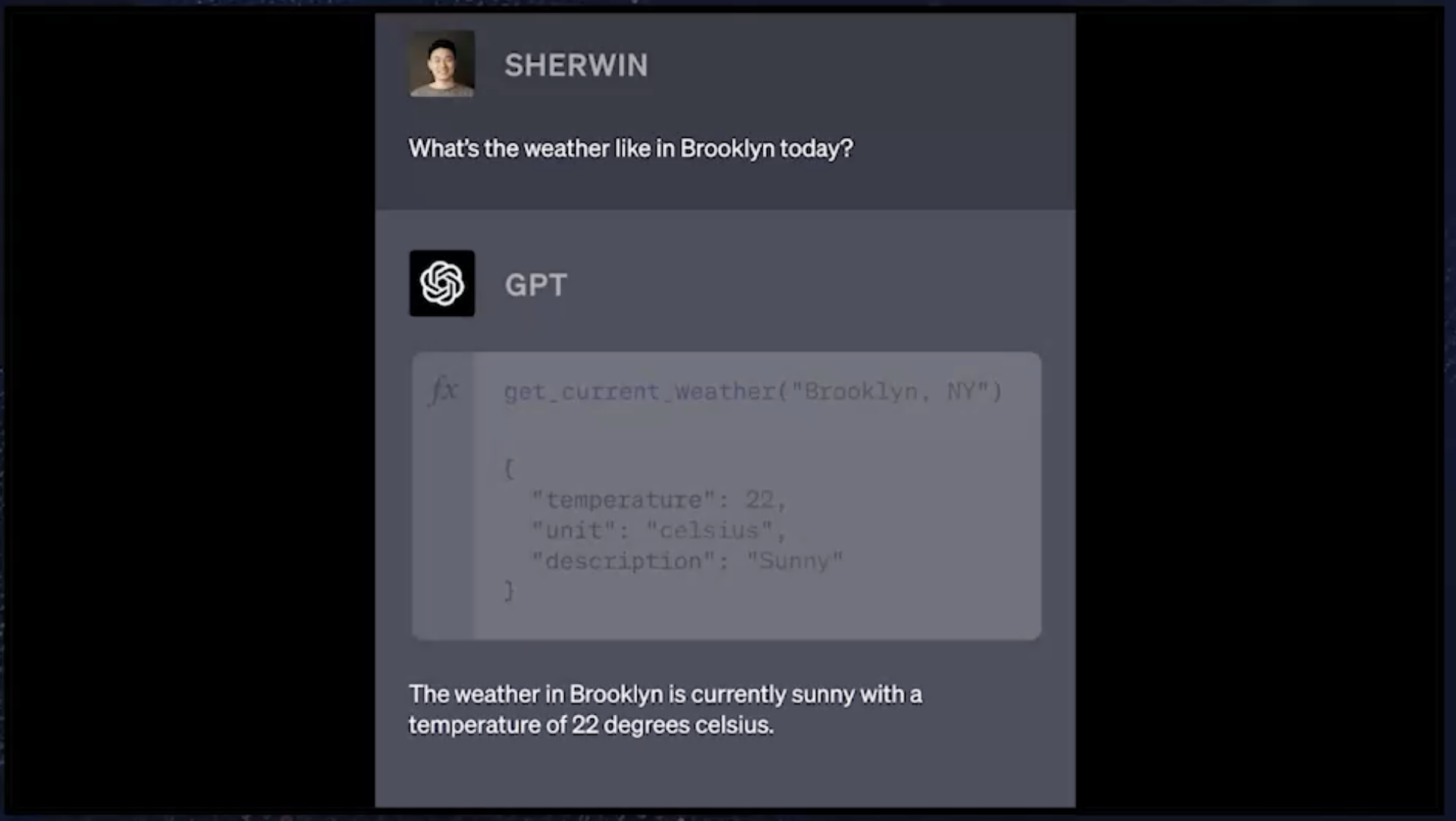
它接收一个带有 location(位置)的字符串,然后它就知道它可以使用这个。在本例中,在这个新的世界里,当你解析此输入时,GPT 将表达它打算调用get_current_filther函数的意图。然后,你可以根据需要在自己的系统中自行调用该函数。假设你得到的输出是 “22 Celsius and Sunny”(22 摄氏度和阳光明媚)。你可以将其解析回 GPT,它会综合这些信息,并返回给用户说:the weather in Brooklyn is currently sunny, with a temperature of 22 degrees Celsius(目前布鲁克林天气晴朗,温度为 22 摄氏度。)
稍微解释一下,真正发生的事情是 GPT 知道一组函数,并且它会智能地自行表达调用其中某个函数的意图。然后执行调用,并将其解析回 GPT。这就是我们最终将它与外界联系起来的方式。为了进一步了解它在高层级上到底发生了什么,其实它仍然就像是一个来回,你的用户问了一个问题,发生了很多事情后,你对你的用户做出了回应。你的应用程序在底层实际做的事情将经历一个三步的过程,首先调用 OpenAI,然后使用你自己的函数,最后再次调用 OpenAI 或 GPT。
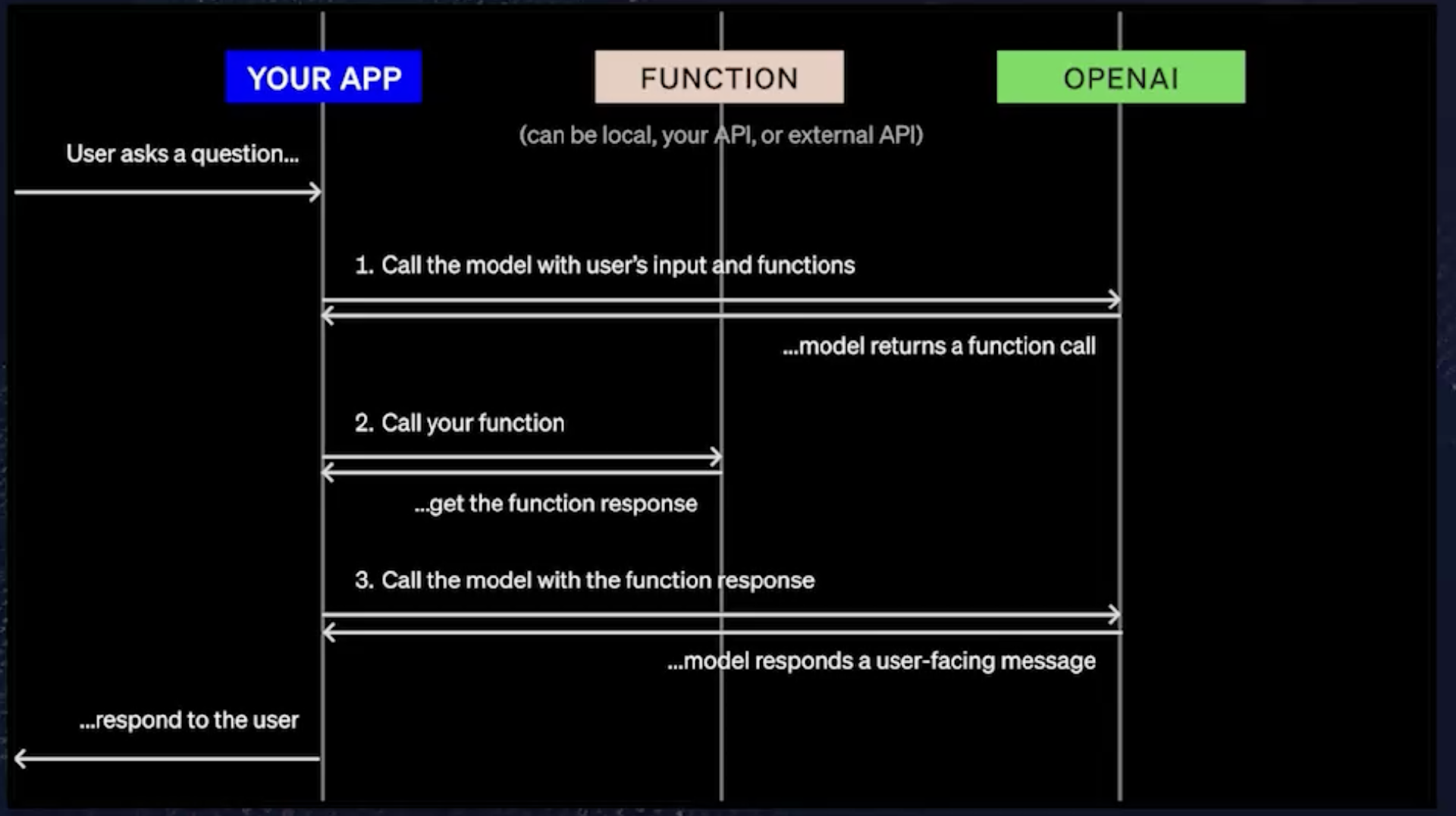
第一步,显然是用户问了一个问题,在本例中,问题是 what's the weather like in Brooklyn today?(“今天布鲁克林的天气怎么样?”)然后下一步是,在应用程序中,调用模型,调用 OpenAPI,并非常具体地告诉它它可以访问的函数集以及用户输入。这是一个 API 请求的例子,目前它实际有效且可正常工作,任何具有 API 访问权限的人都可以尝试该操作。这是一个使用函数调用能力的 curl 示例。我们可以看到,这只是我们聊天完成端点的正常 curl,这是我们发布的一个新的 API 端点,为我们的 GPT-4 和 GPT-3.5 模型提供支持。你 curl 该 API。它会在模型中进行解析。
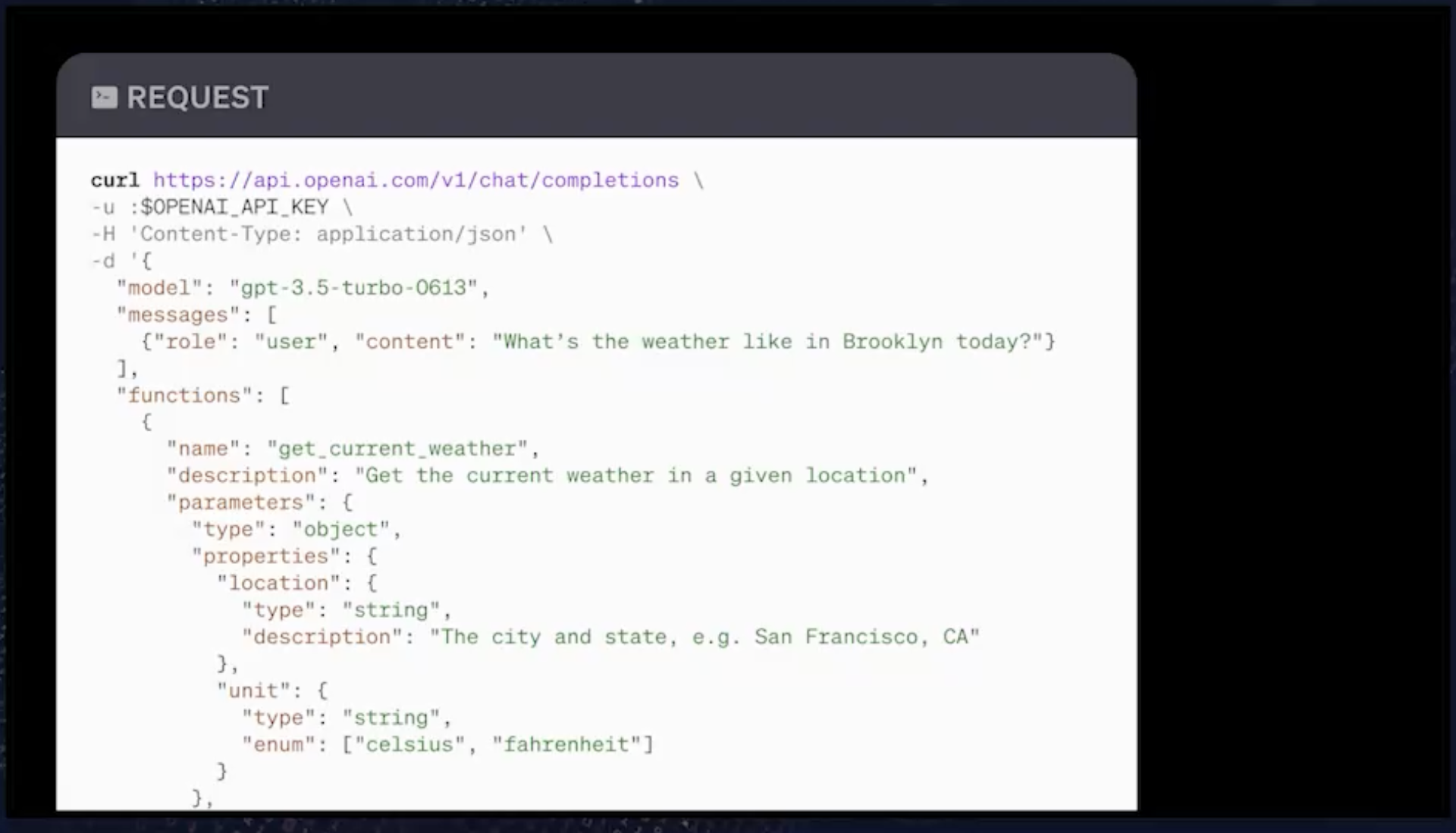
在本例中,我们将在 gpt-3.5-turbo-0613 中进行解析,它代表 6 月 13 日,一个我们发布的模型。这是一个能够进行函数调用的模型。我们还在解析一组消息。对于那些可能不熟悉我们聊天完成格式的人,你可以将其解析到我们的模型中,基本上是一个消息列表,也就是对话记录。
在本例中,实际上只有一条消息,没有历史记录。它只是用户询问“今天布鲁克林的天气怎么样”。你可以想象,随着对话的变长,它可能是一个包含 5 到 10 条消息的列表。我们正在解析消息,模型将能够看到历史记录并对此做出回应。那么,这里的新事物就是函数。
这是一个我们现在可以解析的新参数,我们在这里解析的是,我们列出了这个模型应该知道的一组函数,它应该可以访问的函数集。在本例中,我们只有一个函数,它就是get_current_tweather函数。我们在这里还放了一个自然语言描述。我们说这个函数可以获取特定位置的当前天气。我们还需要输入函数签名。并且我们告诉它有两个参数。一个参数是 location(位置),这是一个字符串,包含城市和州,格式是这样的:旧金山,加州(San Francisco, California.)。另一个参数时 unit(单位),即摄氏度(Celsius)或华氏度(Fahrenheit)。
在这里首屏的下面,还有另一个参数,该参数表示唯一必须的属性是位置。从技术上讲,你只需要解析位置,这里不需要单位。我们将该请求解析到 GPT,然后 GPT 将作出响应。在过去中,GPT 可能只会以文本形式进行响应。它会说:“我不能这样做,因为我没有访问权限。”在本例中,我们的 API 响应的是调用天气函数的意图。
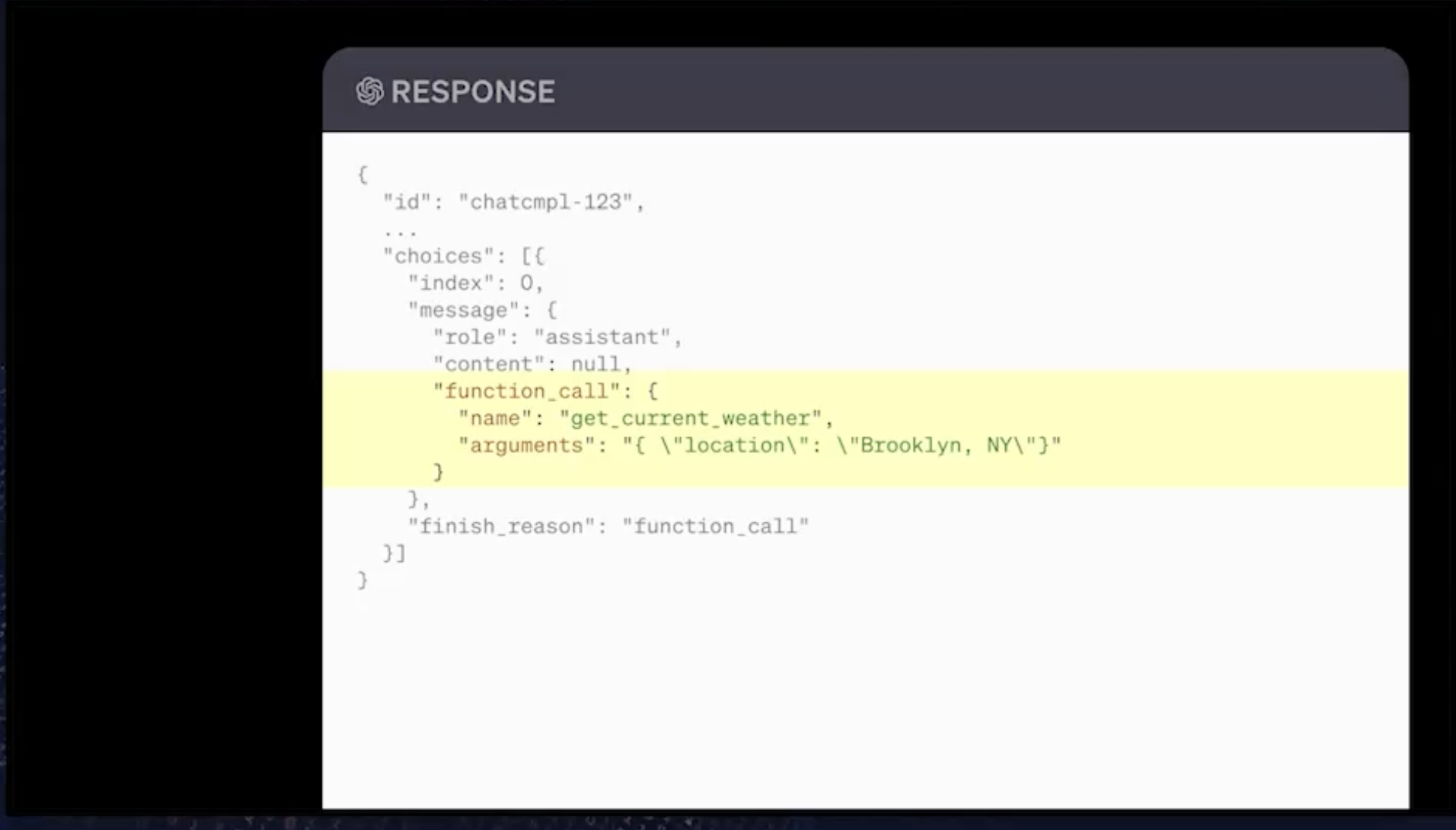
这里真正发生的事情是 GPT 凭自己的直觉,为了弄清楚今天的天气,我自己做不到,但我可以访问get_current_weither这个函数,所以我会选择调用它,所以我要表达要调用它的意图。此外,如果你还没有真正注意到的话,GPT 在这里所做的是,它在这里构造参数。我们可以看到它在告诉我们,它想调用get_current_tweather,它想用参数位置(Brooklyn, New York;纽约布鲁克林)来调用该函数。
它所做的就是看到函数签名,并为其创建请求。然后还算出布鲁克林在纽约,然后用这种方式构造字符串。它把这一切都弄清楚了。至此,GPT 就表达了现在要调用函数的意图。下一步是,我们要弄清楚我们到底想要如何调用这个函数。我们可以根据特定参数从get_current_tweather的函数调用中获取相应的返回值。然后我们可以自己执行。它可以是本地的,在我们自己的 Web 服务器上运行。它也可以是系统中的另一个 API,还可能是一个外部 API,我们可以调用 weather.com API。

那么在这个例子中,我们调用了一些东西,可能是一个内部 API,它返回的输出是我们看到的是 22 degrees Celsius and Sunny(22 摄氏度和晴天)。给定了模型的输出,就可以开始这个过程中的第三步,即调用模型,用函数的输出调用 GPT,然后查看 GPT 想要做什么。在本例中,我谈论的是消息。这次,我们在向 OpenAI API 发送的第二个请求中添加了几条消息。最初,只有一条信息,那就是“今天布鲁克林的天气怎么样?”,现在再添加两条新消息来表示函数调用时所发生的情况。
第一个基本上是对意图的重申,所以基本上是说助理或 GPT 想要用纽约布鲁克林的这个参数来调用get_current_tweather函数。然后,我们还添加了第三条消息,它基本上说明了我们所进行的函数调用的结果,因此这是get_current_filther的结果。然后,内联这里输出的数据,即温度“22”、单位“摄氏度”和描述“晴天”,然后将所有数据解析给 GPT。在此时,GPT 接收了它,并决定它想要做什么。
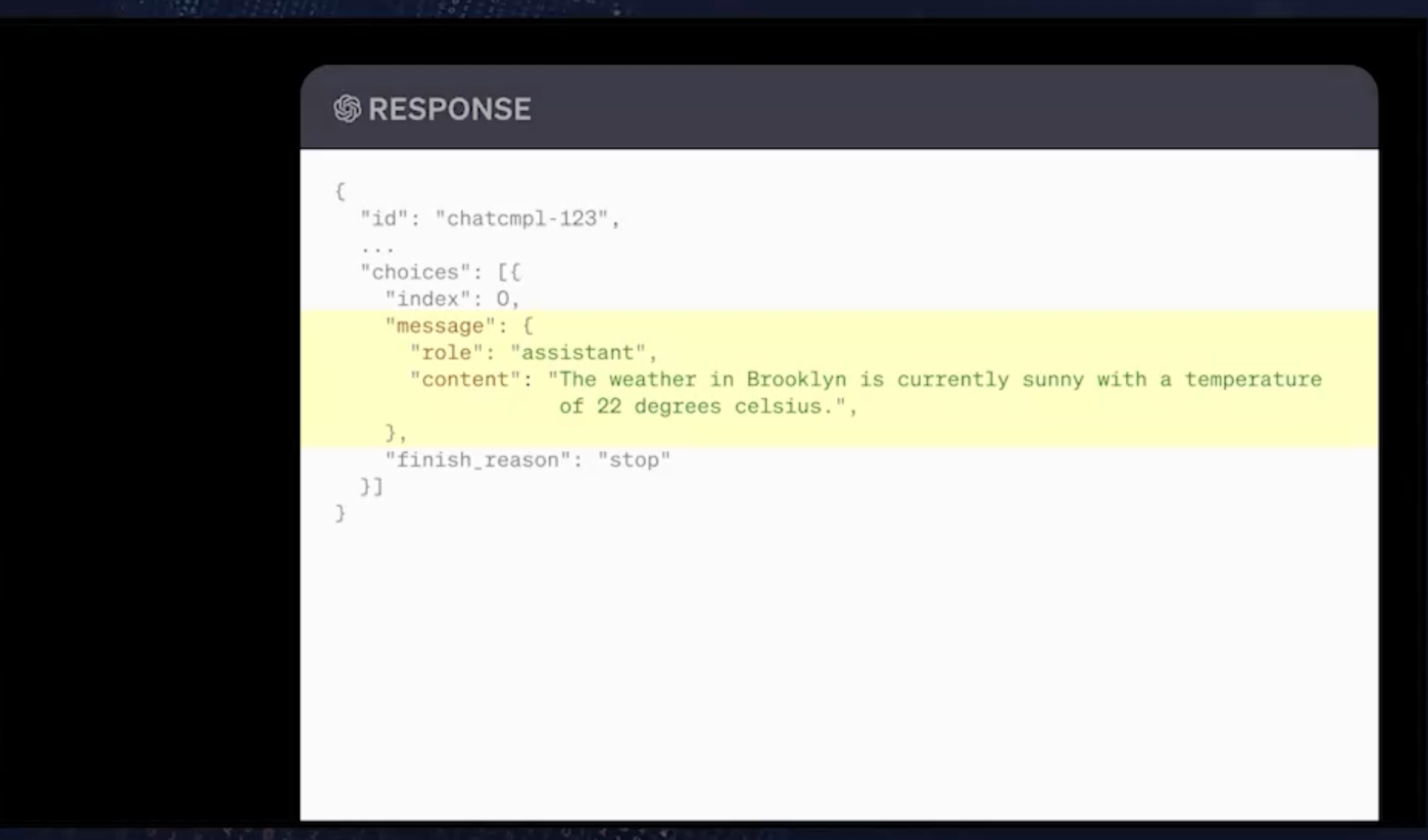
此时,模型已经足够智能了,它能够意识到“我将调用这个函数。这是输出。我实际上已经掌握了实际完成请求所需的所有信息。”它现在最终会通过文本方式来做出回应,并显示“今天布鲁克林天气晴朗,温度为 22 摄氏度”。这时,我们终于得到了 GPT 的最终输出。然后我们就可以回应我们的用户了。
将所有这些放在一起,我们最终会得到我们理想中的体验,即用户询问“今天布鲁克林的天气怎么样?”我们的服务器会思考一下,GPT 表达意图,我们完成完整的三步过程,调用了我们的函数。最终,用户看到的是“今天布鲁克林天气晴朗,气温为 22 摄氏度。成功”
演示 1——将自然语言转换为查询
Eleti:我们刚刚介绍了几个入门性的主题。首先,我们了解了语言模型是如何工作的,以及它们的一些局限性,因为它们没有所有的训练数据,它们没有连接到外部世界,它们的结构化输出并不总是可解析的。Sherwin 还向我们介绍了新特性、函数调用和 API 的工作原理,以及如何将函数解析为 API 并获取输出,以及如何让 GPT 以面向用户的方式来总结响应。让我们通过几个演示来了解如何将所有这些组合起来,并将其应用到我们的产品和应用程序中。
让我们从小事做起。我们将介绍的第一个示例是将自然语言转换为查询的内容。我们的示例是,假设你正在构建一个数据分析应用程序或商业智能工具,比如 Tableau 或 Looker。你们中的一些人可能很擅长 SQL,但我肯定不擅长了。大多数情况下,我只想问数据库,谁是顶级用户,然后得到响应。今天终于有可能了。我们将使用 GPT,将给它一个称为 SQL 查询的函数,它只需要一个参数,即一个字符串“query”。
它应该是针对我们数据库的一个有效 SQL 字符串。让我们看看它是如何工作的。首先,我们将为模型提供一条系统消息,描述它应该做什么。我们称之为 SQL GPT,可以将自然语言查询转换为 SQL。当然,模型需要访问数据库模式。在本例中,我们有两个表,用户表(users)和订单表(orders)。用户表有姓名、电子邮件和生日。订单表有用户 ID、购买金额和购买日期。现在我们可以开始使用一些自然语言来查询数据库了。
我们来问这样一个问题“根据上周的消费金额,找出排名前 10 的用户姓名”(get me the names of the top 10 users by amount spent over the last week.)。这是一个相当正常的业务问题,当然不是我可以立即编写 SQL 就能解决的问题,但 GPT 可以。让我们运行一下。我们可以看到它正在调用 SQL 查询函数。它有一个参数“query”,它创建了一个漂亮的 SQL 查询。它是选择了名称和金额的总和;它连接到订单表;并获取最后一周的订单,按总花费进行排序,并将其限制为 10 个。这看起来是正确且恰当的。让我们在数据库中运行一下它。我们得到了一些结果。
当然,这是 JSON 格式的,因此用户无法渲染它。让我们把它发送回 GPT 看看它说了什么。GPT 总结了这些信息,并表示“这些是按消费金额排名前十的用户。这是他们上周的花费,包括 Global Enterprises, Vantage Partners。”这是一个了不起的用户可读的答案。
我们要对 GPT 给予的帮助表示感谢。我们说“谢谢”,GPT 说“不客气”。这是一种快速的方法,它可以了解完全的自然语言、完全的自然语言查询是如何将结构化输出转换为有效的 SQL 语句的,我们在数据库中运行该语句,获取数据,并将其汇总回自然语言。我们当然可以在此基础上构建数据分析应用程序。
你还可以构建其他的内部工具。Honeycomb 最近为 Honeycomb 查询语言构建了一个非常相似的工具。这是使用 GPT 和函数将自然语言转换为查询的一个示例。
演示 2——调用外部 API 和多个函数
让我们来做第二个演示。这是关于将外部 API 和多个函数一起调用的。我们提高了复杂度。假设我们正在纽约参加一个会议,我们想预订今晚的晚餐。我们将使用两个函数来调用 GPT。第一个是get_current_location。它在设备上本地运行,比如在你的手机或浏览器上,并获取你所在位置的纬度(Lat)和经度(Long)。第二个函数是 Yelp 搜索,它使用 Yelp 的 API,也就是流行餐厅评价应用程序,我们可以对纬度、经度和查询进行解析。
我们来运行一下这个演示。本例中的系统消息相当简单。它所说的就是我们的私人助理,来帮助用户完成任务,把 GPT 变成了一个有用的助手。我说“我正在参加一个会议,想在附近吃晚饭,有什么选择吗?我的公司会支付这笔费用,这样我们就可以尽情享受了”。让我们用 GPT 来运行一下它,看看它是如何做的。
当然,GPT 不知道我们在哪里,所以它说get_current_location,我们将调用本地 API 来获取我们的纬度和经度。我们已经获取到了。是纽约的布鲁克林(Brooklyn, New York)的某个地方。我们会将其返回给 GPT,看它怎么说。它已经有了所需的信息,现在它想调用 Yelp,它说“纬度、经度和查询”,并且会说“美食”。这很好。这就是我想要的。让我们调用 Yelp 并获取一些数据。
我们从 Yelp API 中获取了一堆餐馆。当然,我希望它能给出一个漂亮的总结,所以让我们再次运行它。它回复说“你附近有一些高档餐饮可选择,La Vara、Henry's End、Colonie、Estuary”。上面还写着“请检查营业时间,尽情用餐。”这听起来很美味。再次感谢 GPT 帮助我们组织今晚的晚宴。
这是一个使用 GPT 和函数调用外部 API(在本例中为 Yelp API)以及协调多个函数的示例。它能够凭借推理能力解析用户意图,并依次执行多个步骤的操作,以实现最终目标。
演示 3——将高级推理与日常任务相结合
第三个演示,让我们来进一步加强。我们讨论了 GPT-4 是如何通过 SAT 和 GRE 的。如果可以的话,它一定比仅仅调用 Yelp API 或编写一些 SQL 更聪明。让我们来测试一下。我们都是工程师,我们每天都有很多事情要做。我们必须要做的任务之一是拉取请求审查。我们必须审查同事的代码。如果 GPT 能帮助我,减轻我的工作量,那就太棒了。我们将做一个 GPT 的演示,它可以进行拉取请求审查,有点像构建自己的工程师。
我们只需要一个函数submit_comments。它接受一些代码并返回一个要审查的评论列表,包括行、数字和评论。你可以想象,我们可以将其发送到 GitHub API 或 GitLab API,并发布一堆评论。当然,你还可以添加更多的功能以使其更强大。让我们看看它是如何做的。
在本例中,prompt 有点长。我们向上滚动着看下。我们说:“GPT,你记录、审查 rot,查看其差异并生成有关更改代码的审查评论,保留所有代码审查评论和相应的行号。”我们在这里也卖弄下个性。我们说 toxicity 为 10 分之 0,其实我们不希望这样。
为了好玩,让我们在 snark 上尝试 10 分之 8。我们都认识一些表现出这些个性的工程师。然后尝试 10 分之 2。让我们从这里开始吧。下面是一些我们要审查的代码。它是 SaaS 应用程序中的一个 API 方法,用于更改用户的权限。让我们运行一下它。我们看看 GPT 对这些代码有何看法。它给出了三条审查意见。我们可以看到它调用了submit_comments函数,并且它输出了完全有效的 JSON。让我们看看上面写着什么。它说,“我们现在是在捉迷藏吗?”,“当角色不在身体里时会发生什么?”,“你在那里添加一个了小转折,你就直接访问了第一项。”
我们只是随意地加入了数据库会话,是吗?这有点粗鲁。我们也不想那样。让我们来解决一下这个问题。我现在要退出并稍微修改一下 prompt。要执行该操作,请退出。在幕后,我所做的就是返回 prompt 并更改这些的数字:toxicity,然后下一个,snark,我们将其恢复到 0。我们并不希望这样。让我们礼貌一点。
我们要把礼貌做到十分之十。好吧,再给我三条审查意见。它再次使用完全有效的 JSON 调用该函数。它说,“很高兴看到你检索角色值。”;“你的错误信息简洁明了。”;“我很感激你对数据库的更改,做得很好。”。我希望有人能这样审查我的代码。感谢 GPT,我将退出了。这是第三个快速演示。
从本质上讲,它仍然在做同样的事情。它调用一个函数,给出一些 prompt,并对其做出响应。我们看到的是 GPT 的推理能力。GPT 认识代码。它已经看到了成千上万行代码,可以给出很好的评价。如果你抛开一些个性的东西,它会指出错别字,指出潜在的错误案例和边缘案例。我们在这里将高级推理与日常任务相结合。它确实非常擅长编码。它在考试方面也确实非常出色,它的智力应用范围也很广。这实际上取决于开发人员的创造力,将其应用于尽可能困难的任务,并在此基础上循环运行。
总结
这是本次内容的快速总结。我们讨论了三件事。首先,我们讨论了 LLM 及其局限性。我们了解了 LLM 是如何工作的,它是 token 预测机。我们了解了它的局限性。它被时间限制住了。它并不总是输出结构化的输出等等。其次,我们了解了这个新特性,即使用 GPT 进行函数调用,这是对我们 API 和模型的更新。它允许模型表达何时调用函数的意图,并为我们构建有效的参数,然后在我们的终端上调用该函数。最后,我们浏览了一些演示。在某个时候,我会把公关的东西产品化。
让我们回到开始的地方。我们谈到了史蒂夫·乔布斯的名言,他说“计算机是思维的自行车”。这对我来说确实如此,对你们所有人来说也都是如此。我们身处计算机行业,计算机改变了我们的生活。计算机增强了我们与生俱来的能力,给了我们更多的生产力、想象力和创造力。ChatGPT 中的人工智能和语言模型还是个婴儿。它才出生几个月。我们有责任增强人工智能的思维,赋予它超越其内在推理能力的新能力,将其与工具连接,与 API 连接,并利用这一特性开发出真正令人兴奋的应用程序。
原话对我来说非常有启发。我们永远无法公正地对待史蒂夫·乔布斯的名言。“我记得在我大约 12 岁的时候读过一篇文章,我想可能是在《科学美国人》上,他们在文章中测量了地球上所有这些物种的运动效率,它们从 A 点到 B 点需要消耗多少千卡热量。秃鹫赢了,位居榜首,超过了其他所有物种。人类排在榜单大约三分之一的位置,这对创造之冠来说并不是一个很好的表现。在那里有人有足够的想象力来测试人类骑自行车的效率。一个骑自行车的人把秃鹫吹走了,一直高居榜首。这给我留下了非常深刻的印象,我们人类是工具的制造者,我们可以制造出将这些固有能力放大到惊人程度的工具。对我来说,计算机一直是思维的自行车,它让我们远远超越了固有的能力。我认为我们只是处于这个工具的早期阶段,非常早期的阶段。我们只走了很短的一段距离,它仍处于形成阶段,但我们已经看到了巨大的变化。我认为,与未来 100 年发生的事情相比,这算不了什么。”
就像 50 年前的计算机一样,我认为今天的人工智能也是如此。技术还处于起步阶段,所以我们很高兴看到它的发展。
问答
应对错误和失败的策略
参会者 1:我们应该如何应对错误和失败,你有什么建议的策略?以你的演示为例,在你构建 SQL 查询时,如果我提出的问题导致 ChatGPT 给出了一个在语法上完成正确,但在语义上完全不正确的 SQL 查询时,该怎么办?然后我向我的用户报告一些不正确的内容。很难告诉用户,这是错误的,但你有什么建议的策略来应对这个问题吗?
Eleti:我认为首先,作为一个社会和这些语言模型的用户,我们必须了解它的局限性,几乎要围绕它的局限性来建立抗体。要知道输出可能是不准确的。我认为第二部分就像打开了盒子。我们已经将生产中的函数调用与 ChatGPT 集成在了一起。我们推出了一款名为插件的产品,它基本上可以做到这一点,它允许 ChatGPT 与互联网对话。我们要做的一件事是,如果最终用户愿意的话,那么所有的请求和响应都是可见的。这有助于信息部分。我个人认为 SQL 也是一个非常广阔的开放领域。我认为将其限制在仅在后端执行安全操作的知名 API 是一个好方法。你总是可以得到好的错误信息之类的。这些就是我即兴的建议。
LLM 和 langChain
参会者 2:有人尝试过做一些 LangChain 吗,它可以与 LangChain 一起使用吗?
Eleti:是的,事实上,LangChain、Harrison 团队在我们推出一个小时后就发布了一个集成,所以它是有效的。
数据泄漏
参会者 2:这还暴露了一个泄漏问题。SQL 示例就是一个很好的例子。如果有人读到这篇文章,他们对金融数据库进行 SQL 查询,并将其输入到 gpt-3.5-turbo,我们基本上就泄露了数据。
如果你使用的是 text-davinci-003 或不同的模型,就会出现这样的问题,一些来自查询的数据会变成模型本身。在我看来,这个例子是极其危险的。
Wu:实际上这存在一个误解,我认为我们最近没有作出很好地澄清,直到今年 3 月或 2 月,在我们为 API 提供的服务条款中,我们就说过“我们保留自己对 API 输入数据进行培训的权利”。我想这可能就是你所说的,就像你对一些 SQL 查询进行解析一样,它会在返回时以某种方式回到模型中。事实上,到目前为止,我们已经不再这样做了。根据我们的服务条款,我们实际上不会在 API 中对你的数据进行训练。我认为我们还没有把这一点说得非常清楚,所以人们对此非常偏执。到目前为止,还没有。你应该查阅我们的服务条款。我们不训练它。也就是说,解析的东西并不像企业级的那样。我们不会针对你的用户进行隔离。我们只是没有在自己的数据上训练它。这种围绕企业级数据隔离的特性显然很快就会出现。这一特定的安全层还没有出现。
Eleti:我们不使用 API 数据进行训练。
函数调用的并行化
参会者 3:你展示的演示运行有点慢。我想知道,你们支持函数调用的并行化吗?就像现在你是串行的吗,你得到了这个函数签名,然后调用它,但假设 ChatGPT 说,三个函数应该同时被调用,这可行吗?
Eleti:API 实际上不支持多个函数调用。没有输出显示“调用这三个函数”。但你可以破解它。你只需要定义一个函数,让它调用多个函数,然后你提供一个签名,让模型调用它,即可实现调用多个函数,这完全是可行的。归根结底,我们仍然是使用模型的推理能力来输出一些文本。
模型上下文的预加载
参会者 4:在你给出的 SQL 示例中,你为其提供了一些可以访问的表。我们有没有办法可以让任何人的后续调用预加载所有上下文呢?
Wu:有几个潜在的解决方案。我们有一个称为系统消息的功能,你可以在那里进行解析,它基本上设置了模型的整体对话上下文。但在当时的语境中它是完全颠倒的。目前,我们已经将上下文窗口增加到大约 16000 个 token。你可以逐渐将更多内容压缩到系统消息中。该模型经过训练,会格外关注系统消息,以指导其做出回应。在本例中,Atty 在系统消息中有两个表的模式。可以预见的是,你可以添加更多的内容来填充整个上下文。
参会者 4:这就是我们的预加载方式吗?
Wu:是的,这是最简单的。还有一些其他的方法。你可以将它连接到外部数据源、数据库之类的。微调也是另一种选择。还有其他一些。
使用 GPT 进行可靠的函数调用
参会者 5:关于将 GPT 集成到不同的软件中。我在使用枚举时遇到了一些问题,当我要求它用英语、法语或德语做一些工作时,我使用的枚举有时会出现德语或法语。API 函数也会发生这种情况吗?
Eleti:是的,很不幸。模型在正常情况下以及在这种情况下都很容易产生幻觉。我们所做的基本上是对模型进行了微调,因此我们可以看到大约 100000 个关于如何可靠地调用函数的示例。它比你自己做的任何其他提示都要好得多。它仍然会生成参数,可能会输出无效的 JSON,也可能会输出其他语言。为了防止这种情况,我们将进行更多的微调。我们也在探索一些低级推理技术来改进这一点。然后在你这边,你可以做 prompt 工程,只要提醒模型,不要输出德语,它会尽力的。
Wu:看看它在这方面是否能做得更好,这会很有趣,尤其是如果你有一个函数签名,并且你明确列出了 5 个不同的英文枚举。较新的模型可能会更好,但也不完美。我不能百分百确定,不幸的是,我们没有跨英语、法语枚举那样的评估。这可能是一个值得思考的好问题,但我们很好奇,想看看它是否会变得更好。
GPT 识别意图的能力
参会者 6:我有一个关于 API 理解意图能力的问题。函数调用是否有相似的温度(temperature)参数;如果我解析两个具有相似意图的函数,那么 GPT 对每个要调用的函数是否具有确定性;或者如果我多次询问,选择要调用哪个函数是否具有随机性?
Eleti:随机性依然是存在的。归根结底,在底层,它仍然是一个 token 一个 token 地输出,选择要调用的函数。降低温度增加了确定性,但这并不能保证确定性。也就是说,API 中有一个名为函数调用的参数,如果你知道你想让它调用哪个函数,实际上可以直接指定它,它肯定会调用该函数的。
函数调用权限
参会者 7:如果我们想限制某些用户进行某些函数调用,或者像你这样在这些 SQL 查询中访问某些表,你们有函数调用的权限吗,人们还需要实现他们自己的吗?
Eleti:所有这些都会发生在你的服务器上,因为你拥有谁可以访问什么内容的完整上下文。这个 API 提供的只是 GPT 选择要调用哪个函数以及要使用哪些参数的能力。然后,我们希望你像对待任何其他客户端一样对待 GPT 的输出,因此对于不受信任的客户端输出,你可以在你的终端上验证其权限和内容。
思维链提示和约束采样
参会者 8:我只是想知道你是否可以详细说明一下这在底层发生了什么。这是底层的思维链吗?这是这些技术之上的一个有效的 API 层吗?
Eleti:思维链提示是一种在给模型任务时的询问方式,首先,告诉我你要做什么,然后去做。如果你问“布鲁克林的天气怎么样?”它可能会说“我收到了一个天气请求,我将调用天气 API”。然后它就这样做了。这是一种快速的工程技术。这是一个微调。随着插件的推出,我们收集了大约 100000 个用户问题和函数调用示例的内部和外部数据。这一切都在模型中进行了微调。这就是它的来源。
我们还可以使用第三种技术,叫做约束采样,其中在 token 采样层,你可以确保预测的下一个 token 是值集中的一个。在 JSON 示例中,逗号之后必须是新行或类似的内容。我们可能会弄错,但是我们明白了,我们有语法要分配。这是我们正在探索的领域。这是从提示到微调再到更低层的东西的漫长旅程。这是让 GPT 输出可靠结构化数据的过程。
矢量数据库的兼容性
参会者 9:这可以与矢量数据库一起使用吗?我的想法是,我想根据我输入到向量数据库中的信息来约束信息,但它仍然能适用于函数逻辑?
Eleti:是的,和以前一样好用。
函数调用是否公开可用?
参会者 10:我们今天就能使用它了吗?它现在对公众开放了吗?
Wu:它是今天公开的,但有一个警告。它在 gpt-3.5-turbo 模型上可用。这里的任何人实际上都可以使用 gpt-3.5-turbo 访问函数调用,因为这是普遍可用的。它也可以在 GPT-4 API 上使用,但不幸的是,它仍然处于等待名单中。如果你不在该等待名单中,并且你可以访问 GPT-4 API,那么你实际上可以使用 GPT-4 进行此操作。它在这方面做得更好。进度有点慢。如果你仍在等待名单上,或者你无法访问 GPT-4 API,你今天可以在 GPT-3.5-turbo 上试用。
查看更多演示文稿字幕
原文链接:




