
历经十五年的发展,区块链技术以完整的技术生态系统重塑千行百业,其广泛应用也为金融、医疗、物流等多个领域带来巨大变革。但凡事皆有两面性,技术向善,也能为恶。
区块链技术在普及应用的同时,也滋生了一系列的安全风险,尤以涉虚拟货币犯罪为重。此类新型科技犯罪形式,不仅对人民及社会的安全造成了严重威胁,也对现有法律和执法提出了全新挑战。本文主要讲述了我们如何用机器学习模型来打击虚拟货币违法犯罪行为。
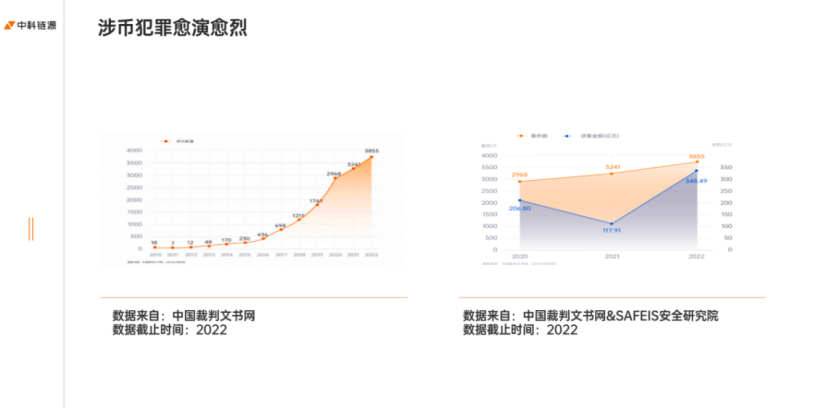
图 1:数据显示,涉币犯罪愈演愈烈
区块链:“黑暗森林”的形成
区块链技术的核心特点是去中心化、匿名性,参与区块链交易的真实主体难以追踪,犯罪分子在链上自由交易,不必担心执法小队的追踪猎杀。
图 2:区块链技术:去中心化、安全透明、可追溯的分布式账本技术
虚拟货币具有去中心化、无法监管、无国界、跨境限制、交易无限制和交易低成本的特征。不仅如此区块链技术还为犯罪分子提供了丰富的手段来隐匿踪迹、抵挡追踪。“混币器、隐私币”等的出现,进一步增强了其匿名性,为犯罪分子创造了毁灭追踪路径的“迷雾地带”。违法犯罪活动多以稳定币 USDT(泰达币)为主要犯罪媒介,此外也常见于通过 BTC(比特币)、ETH(以太坊)、XRP(瑞波币)、XMR(门罗币)等虚拟货币作为载体的犯罪行为。
尽管区块链技术为不法分子实施犯罪带来诸多便利,但链上交易数据完全公开透明的特性,也为涉币案件的分析研判提供了海量数据。很多安全专家试图将分析传统法币犯罪案件的实战经验,应用在链上交易数据分析。但鉴于区块链技术的独特性,这些传统方法仍需与时俱进优化。
涉币案件的侦破流程耗时很长,一个案件从获取线索到结案,通常会超过半年。为了提升结案成果率,案件的线索阶段就需广撒网、多线跟踪,这对于办案人员的分析产出质量与时效要求甚高。办案人员不仅需要具备深厚的区块链技术知识,也要深刻了解犯罪分子的行为模式与作案策略,门槛较高。目前,业内优秀的办案人员实属稀缺。为更高效精准打击涉币犯罪,执法领域在招募并培养复合型涉币案件办案人员的同时,要不断引进相关创新技术进行赋能,进一步提升侦破能力。
利用大数据和机器学习技术来分析海量链上数据,帮助发现人力难以识别的线索,从而找到犯罪分子的踪迹”,已成为当前打击涉虚货币犯罪领域创新探索与方法研究的重要而前沿的方向,并在业内释放了巨大的应用价值与潜能。
机器学习如何用于涉币犯罪分析
机器学习新技术已在合规领域尤其是金融犯罪风险防控方面,如金融风险评估、反洗钱等场景有了较为广泛的应用。近年来,业内不断布局探索图计算技术的动作,旨在进一步提升模型表现。
相较基于人工经验主观判断的风险评估系统,机器学习模型的优势在于:
最大限度利用获取的信息,发现人力难以找到的规律。如在反洗钱领域,机器学习技术这一优势得到充分发挥。洗钱活动往往涉及复杂的交易链和隐蔽的资金流向,机器学习模型通过对大量交易数据进行分析,可自动识别出可疑的交易模式与行为,从而帮助金融机构及时发现和阻止洗钱犯罪;
判断更加精准高效,摆脱人工经验的主观性。如在金融风险评估中,传统方法十分依赖人工经验主观判断,效率低下,且仅能针对划分出的人群进行粗略判断;机器学习技术可以自动为每位客户甚至每笔交易进行分析推断,生成风险评分,并且确保这些评分均基于完整和准确的信息客观计算产出,精准度和可靠性极大提升;
数据资源是人工智能发展的驱动力之一。随着数据量的快速增长和技术的飞速进步,机器学习模型可不断进行迭代优化,从而确保其表现始终处于最佳状态。
上述机器学习模型,在传统金融安全领域发挥的优势,同样也可在涉币案件侦查中发挥巨大作用。我们基于区块链交易特征进行迭代完善,形成了图计算机器学习模型,并将其应用于涉币案件侦查平台的实战后,证实卓有成效。
图计算模型:判断涉案地址关联度
在涉虚拟币新型网络犯罪案件中,起始线索地址往往是犯罪活动的初始资金归集地址。以涉币网络赌博案件为例,该地址可能是用于归集赌客充值兑换筹码资金的地址,以此线索地址作为追踪犯罪团伙,开展侦查工作的实战开端,但从起始线索地址追踪到犯罪团伙的各个核心职能地址,中间分析过程可能涉及数十万个相关联的地址。如何在这些大量地址中,准确又快速找到相关性最强的可疑地址,是侦查工作突破的关键。
传统的人工侦查方法存在以下痛点:
主要依赖人工操作,侦查效率低下,且容易出错。由于人本身的能力有限,即使投入大量人力成本,去追踪覆盖数十万个地址的可能性也微乎其微;
展开链上节点数量、层级有限。由于技术与资源的限制,传统侦查方法往往只能展开有限的节点数量和层级(最多 3 层),这样的实战节奏可以窥见,追踪到犯罪团队的核心地址并不明朗。
人力能够并行处理的特征数量少。依靠人工经验,往往只能综合考虑有限的主要特征(5-10 个),无法同时考虑更多维度特征。
人为主观因素影响巨大。优秀的涉币案件分析师人才十分稀缺,已从业人员专业水平参差不齐,业内也并没有形成公认的标准侦查方法并培训普及,每个办案人员的方法与历史实战经验均不相同,便会导致结果因人而异;即使拥有培训经历,分析师也只能综合考虑 5-10 个标准化的主要特征,且每个人基于自身经验赋予各特征的权重也不一样,也会造成结果因人而异。
所有机器学习产品功能的成功落地应用,皆是一个公司“业务、算法和工程”三方实力的综合体现,三者相辅相成。图计算模型的成功开发落地,首先根植于案件分析师团队依托大量案例实践沉淀的业务理解。在近一年多的时间里,分析师们通过借鉴大量传统法币案件的侦破经验,并结合虚拟币交易的特征,针对几十起具体涉币案件的情况深入分析研判,积累了极具价值的“特征判定规则”。这些规则可以帮助分析师更加准确地判断虚拟货币交易是否涉及犯罪行为,以及发现和追踪可疑交易。人力发掘出案件中的可疑涉案地址后,通过警方向交易所调取涉案地址的身份与交易信息,进一步确认了结果的准确性,并根据结果来修正“特征判定规则”。
涉案团伙分工明确,资金归集、洗钱、收益发放、资金沉淀和兑换等各类职能划分清晰,此类多层级的组织结构和交易行为模式形成了复杂的网络关系。应用风险管理领域最前沿的图计算模型,可以将涉案团伙的成员、职能以及交易活动等数据信息整合成“点和边”的形式呈现,从而构建出复杂的不限层级的全币种全链路的网状图,并自动学习其中包含信息;此外,网图的拓扑结构也释放了高价值信息,可以深入揭示出团伙内部的组织关系、资金流动路径以及犯罪收益的分配情况等关键线索与证据。
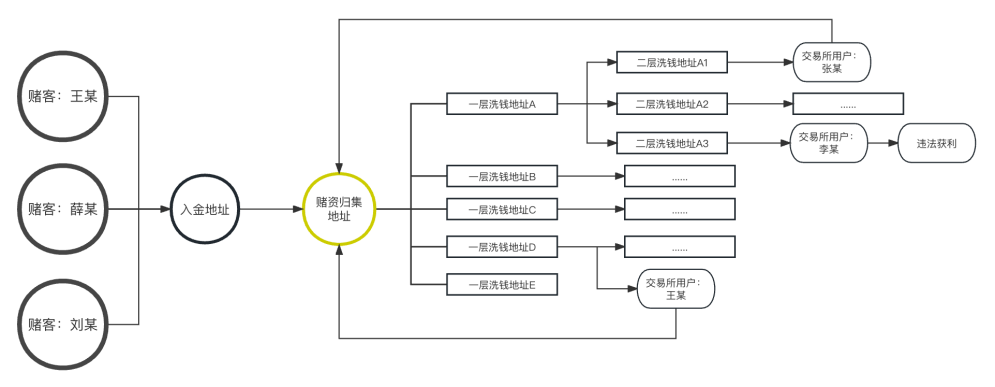
图 3:涉币网络赌博案件的资金流转脉络
模型实现步骤
图计算模型实现的步骤如下:
搜索提取全量交易数据。首先获取一个起始线索地址,通常是一个案件初始资金的归集地址。从数据库中搜索并提取从该地址出发的所有下游交易,可根据案件类型灵活设置向后搜索的层级。随着搜索层级的增加,对计算资源要求也呈指数加大,但并不会发现更多高价值的涉案地址,增量价值递减;
根据交易数据构建网图(Graph)。网图的“节点”是交易对手方的地址,“边”是两个地址之间的交易关系,链路则是一个起始地址到一个终点地址之间的交易通路。起始线索地址与任意一个终点地址之间,可能存在多条不同长度的链路。这将构建一个包含数十万节点与边的复杂网络。
提取特征。生成网图后,按照链路维度,从链路中每个地址和每笔交易中提取关键特征。这里,我们主要用到了 5 大类,共计超过 100 个特征,包括:
地址资金余额相关特征:比如平均账户余额、账户余额的标准差、最新余额等;
交易模式相关特征:比如平均交易频率、交易频率的标准差、交易总次数、交易间隔等;
交易金额相关特征:比如除了均值、中位数、标准差等,还有异常大额交易等;
交易时间特征:比如时间戳分布(是否有特定的交易活动时间段),交易时间重合度等;
社交网络相关特征:用户的连接度(用户连接的其他用户数量),用户的社交网络位置(中心性),用户所属社群的数量等。
模型训练。搭建基于特征的规则模型,并用机器学习方法不断迭代规则阈值和注意力权重。规则模型为特征进行打分,最后加权求和,得出各链路分数,再根据链路数量、各链路分数,综合计算出起始线索地址与某个终点地址之间的“关联度”。
结果产出。计算从起始线索地址到所有终点地址的“关联度”并进行排序,关联度最高的终点地址,就是高度可疑的涉案地址,用户可以针对这些涉案地址进行下一步的分析侦查,比如发函向其所在的交易所要求调取证据。
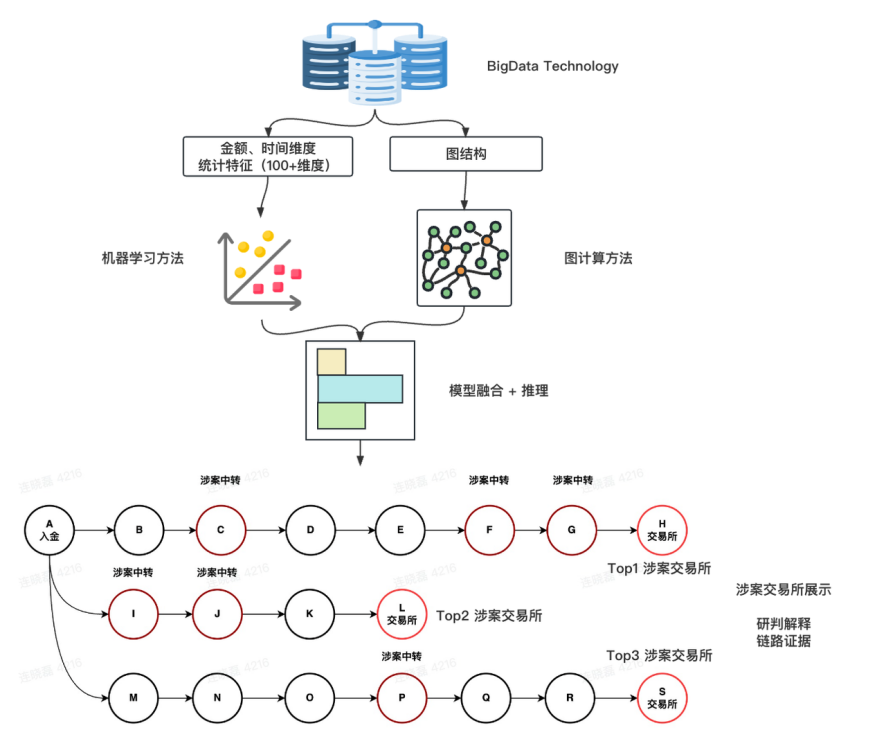
图 4:多特征图计算模型
能快速实现上述大规模计算,主要依赖区块链大数据积累。区块链 AI 安全厂商中科链源自建了三大区块链(以太坊、币安智能链和波场链)的全节点,并实时将交易数据解析处理,以确保数据的及时性和准确性,同时,为提高数据的安全性与可靠性,将数据存储到实时和离线两套数据库中,便于后续的数据分析和挖掘,这样就拥有了从链的创世区块到最新的所有完整交易数据的优势;并且根据模型特征计算需求,在数仓中建立了按天更新的业务中间表,以确保数据的新鲜度和准确性,同时提高计算效率,在接到用户发出的计算任务后,调用中间表,在 30 分钟内完成计算并产出结果。
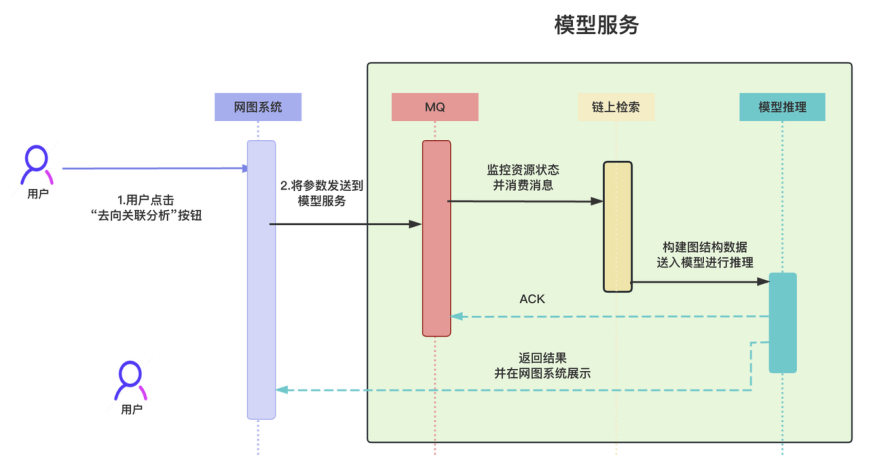
图 5:用户使用去向关联分析功能,体验多特征图计算模型服务
模型结果计算完毕后,中科链源自研的 SAFEIS 安士区块链 AI 信息作战系统会为用户呈现计算结果。作战系统的核心组件是以区块链交易资金流向形成的网状分析视图,在这里,用户可以点击任意地址,对其有交易关联的相关地址进行展开,从而形成巨大的网状图,便于追踪分析。该组件的使用场景与图计算模型的功能高度匹配,所以模型功能便深度融合到此数智执法产品的核心组件中。用户通过右键菜单,可以对任意地址调用模型,来计算其资金关联高的涉案地址,并将结果也展示在网状图上,直观揭示出犯罪行为的动态演变过程,方便进一步研判分析。
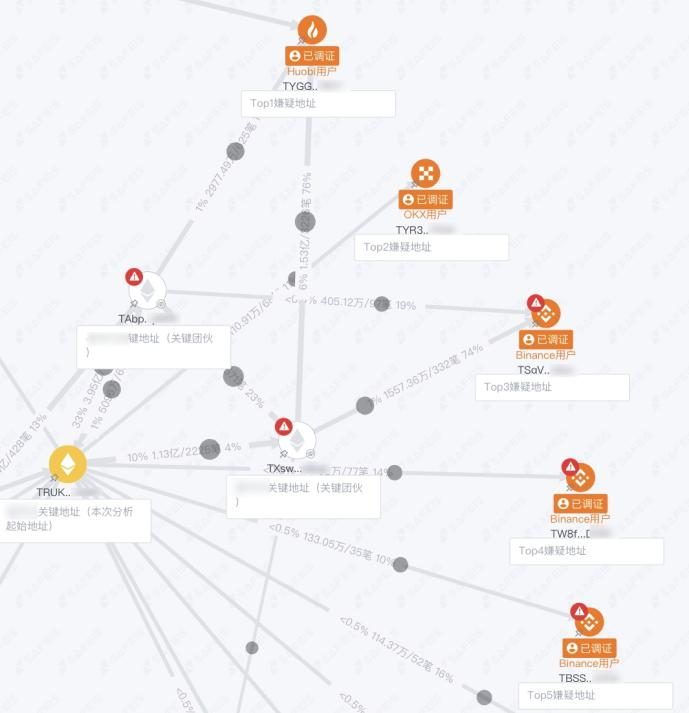
图 6:调用模型功能计算资金关联高的涉案地址
机器学习模型在涉币资金分析中的优势和效果
机器学习模型可以自动快速处理和分析海量链上数据,减少人工参与的需求,极大提高效率。模型可以突破人类能够处理的信息极限,分析范围可覆盖到数十万的下游节点,并自动从数据中提取有用的特征,同时综合考虑多种特征进行分析,如统计特征、图特征等,进而提供相较于单纯依赖人工分析更为全面和准确的分析结果。最后,模型的决策基于数据和算法,如此避免了人工由于能力、经验参差不齐或主观判断等因素造成的结果不稳定。
功能上线后,我们与几位资深分析师合作,将模型投入到新案件的实战中验证效果。针对每个起始线索地址,我们用模型计算出 Top30 的可疑涉案地址,相关度从高到低排列。同时由分析师自行通过人工分析,再对比双方结果。
侦查案件对准确性与时效性的要求很高,关键在于快速找到一定数量的高质量线索进行突破,而无需费时找齐所有涉案线索,因此我们在评估中重点关注准确率,忽略了召回率。由于网络复杂,人工也难以穷尽所有节点,评估召回率则异常困难。
从准确率来看,模型计算的 Top3 中,有 60%左右的地址与人工分析的结果匹配,准确率符合预期;此外,另有 15%的地址,没有通过人工找到,但经验证后发现相关度很高,这部分是模型的增量价值,可以发现人力难以察觉的信息。
模型功能开发难点攻坚
在模型的开发过程中,我们遇到以下主要难点:
1. 源数据查询性能压力。
随着模型搜索分析覆盖的范围增加(深入到 5 层就有几十万个地址节点、千万级别的交易数据),导致查询性能压力剧增,对性能优化和分析策略提出较高要求。
对此,我们优化了 SQL 查询逻辑,首先基于对案件特点的理解,合理设置了数据查询的限制条件,尽可能在数据源头提前筛除信息价值不高的数据。此外,我们还建立了精简高效的临时表,从根本上改进了查询性能。
2. 特征计算压力。
在获取了几十万个地址节点、千万级别的交易数据后,需要构建出网状图,并且需根据这些数据计算出上百个特征,包括统计特征和图特征,这使得数据处理和分析计算量巨大。
对此,我们引入了 Numpy 矩阵计算库和 Networkx 图特征计算库。通过此类高效的计算库,我们实现了高达 10 倍的计算速度提升。
3. 不断挖掘新特征,提升模型效果。
仅使用传统的交易数据的统计特征,已很难达到理想效果,需要根据案件特征,来发掘更多的高质量特征,以提高模型的推断能力。
对此,我们引入了图特征,通过将网络拓扑结构与数据融合,为模型提供了更多的高价值信息。此外,根据资深分析师的经验,地址之间 gas fee 的流通也是其潜在关系的重要特征,在增加这一关键特征后,模型效果也得到了较大提升。
未来:模型迭代方向
目前,我们仍在积极与资深分析师团队展开密切合作,试图将该模型更多用于实战,并在实践中探索改进点。未来,我们探索的主要方向是挖掘寻找更多特征,提高模型的准确性和泛化能力,同时形成更完整的规则进行判断,以帮助构建更强大的模型。
模型产品优化后,鉴于更多用户的持续使用,并给模型结果进行评分,我们进而可以拿到更多有价值的标注数据,用来优化特征计算,优化机器学习方法,进一步迭代模型,提高模型性能与质量,赋能数智执法产品,从而为用户提供更好的需求服务。




