
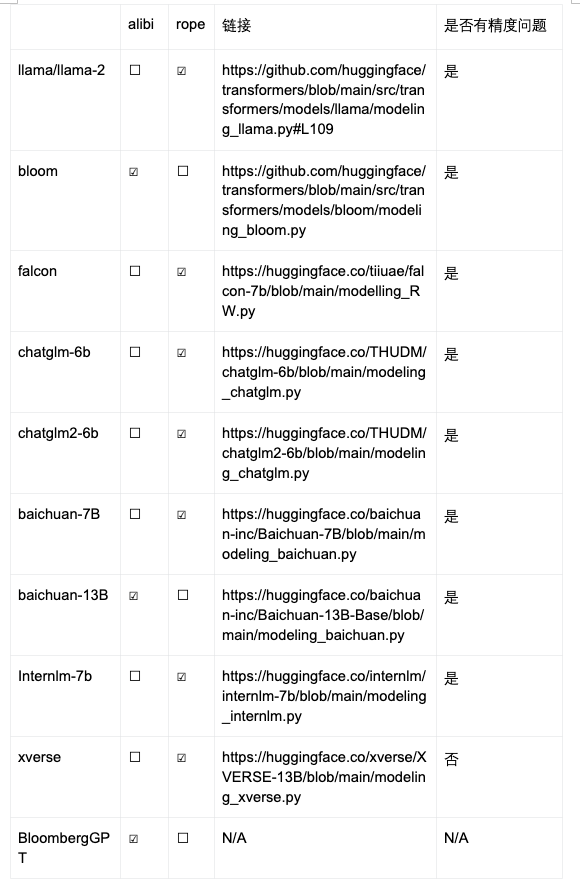
位置编码技术是一种能够让神经网络建模句子中 Token 位置信息的技术。在 Transformer 大行其道的时代,由于 Attention 结构无法建模每个 token 的位置信息,位置编码(Position Embedding)成为 Transformer 非常重要的一个组件。研究人员也提出了各种各样的位置编码方案来让网络建模位置信息,RoPE 和 Alibi 是目前最被广泛采纳的两种位置编码方案。
然而最近来自百川智能的研究发现,RoPE 和 Alibi 位置编码的主流实现在低精度(尤其是 bfloat16)下存在位置编码碰撞的 bug, 这可能会影响模型的训练和推理。而且目前大部分主流开源模型的实现都存在该问题,连 llama 官方代码也中招了。
还得从位置编码算法说起
为了弄清楚这个问题,得先从位置编码的算法原理说起,在 Transformer 结构中,所有 Attention Block 的输入都会先经过位置编码, 再输入网络进行后续处理。纯粹的 Attention 结构是无法精确感知到每个 token 的位置信息的,而对于语言的很多任务来说,语句的顺序对语义信息的影响是非常大的,为了建模 token 之间的位置关系,Transfomer 原始论文中引入位置编码来建模位置信息。
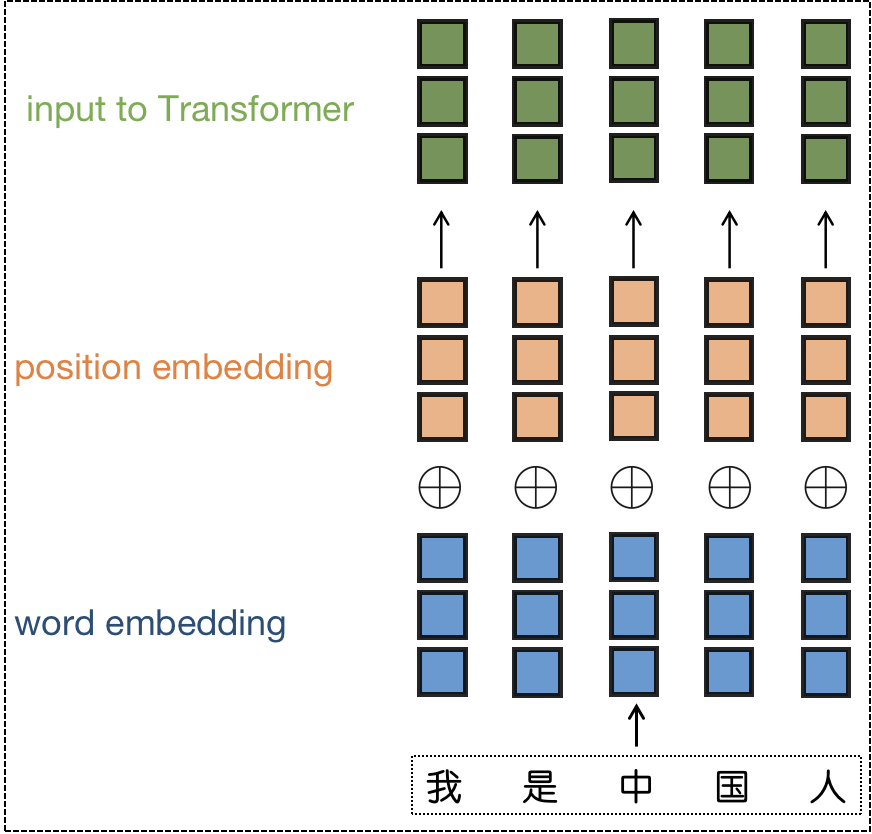
图 1-施加 Positon Embedding 示意图
为了让模型更好地建模句子的位置信息,研究人员提出了多种位置编码方案,Meta 开源的 llama 模型采用了 RoPE 方案,使得 RoPE 成为在开源社区被广泛采纳的一种位置编码方案。Alibi 编码也因为其良好的外推性也被广泛应用。
了解低精度下的位置编码碰撞之前,先来回顾一下相关算法原理
Sinusoidal 位置编码
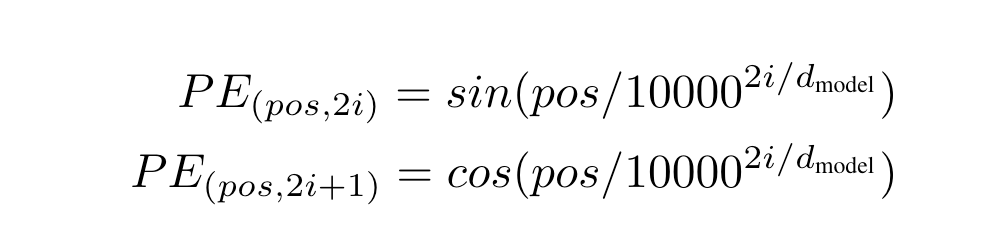
这是 Transformer 原始论文中提出的位置编码方法。它通过使用不同频率的正弦和余弦函数来为每个位置产生一个独特的编码。选择三角函数来生成位置编码有两个良好的性质:
1)编码相对位置信息,数学上可以证明 PE(pos+k) 可以被 PE(pos) 线性表示, 这意味着位置编码中蕴含了相对位置信息。
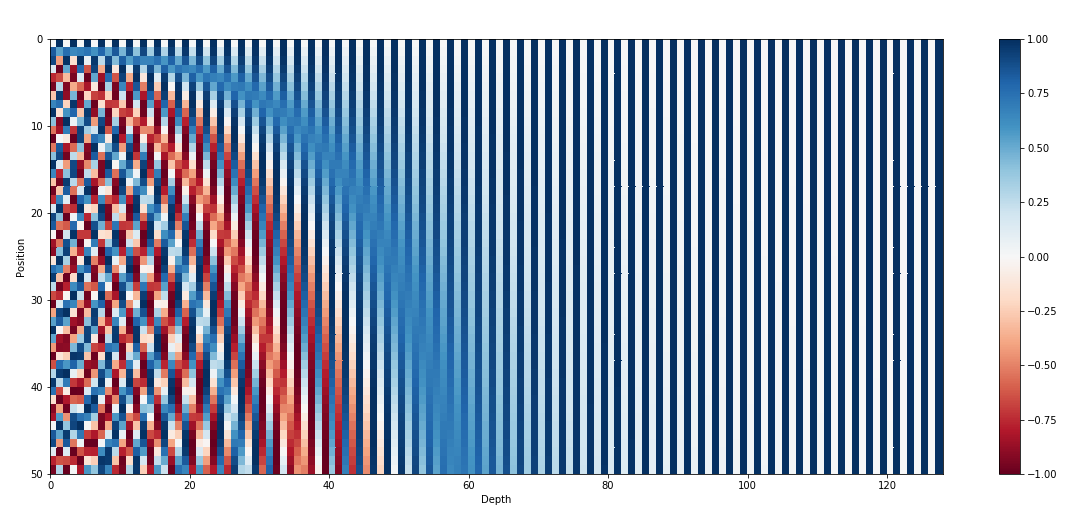
图 2-句子长度为 50 的位置编码,编码维度 128,每行代表一个 Position Embedding
2)远程衰减:不同位置的 position embedding 点乘结果会随着相对位置的增加而递减。
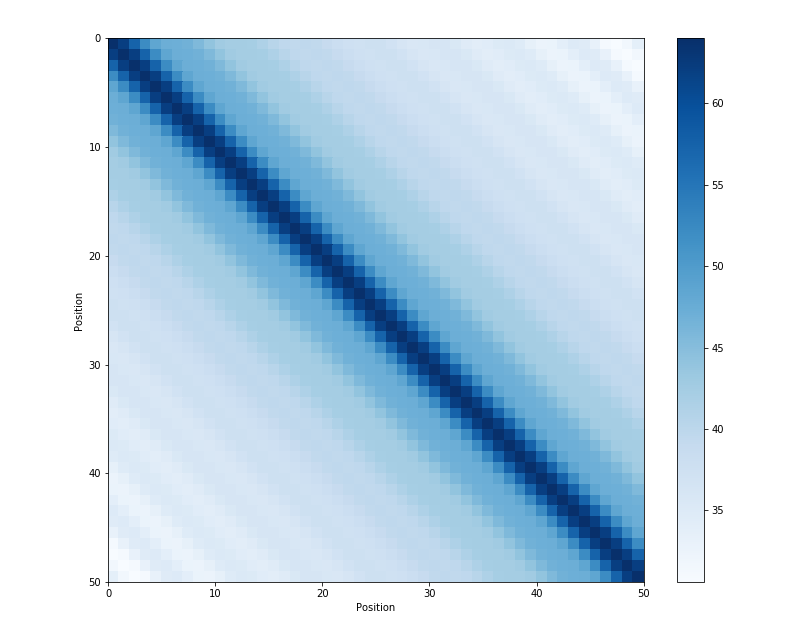
图 3-不同位置的位置编码点积可视化
RoPE
RoPE 是目前开源社区应用最广泛的一种位置编码方案, 通过绝对位置编码的方式实现相对位置编码,在引入相对位置信息的同时保持了绝对位置编码的优势(不需要像相对位置编码一样去操作 Attention matrix)。令 f_q, f_k 为 位置编码的函数,m 表示位置, x_m 表示该位置 token 对应的 Embedding,希望经过位置编码后的 Embedding 点积仅和相对位置有关,则可以有公式
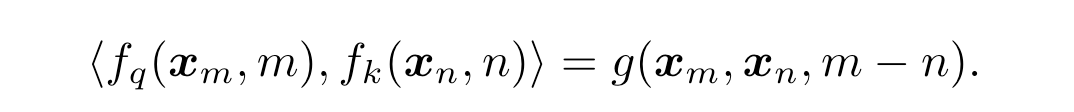
上面公式中 g 是某个函数,表示内积的结果只和 x_m 和 x_n 的值,以及二者位置的相对关系(m-n)有关在 2 维的情况下可以推导出(详细推导过程可参考原论文):
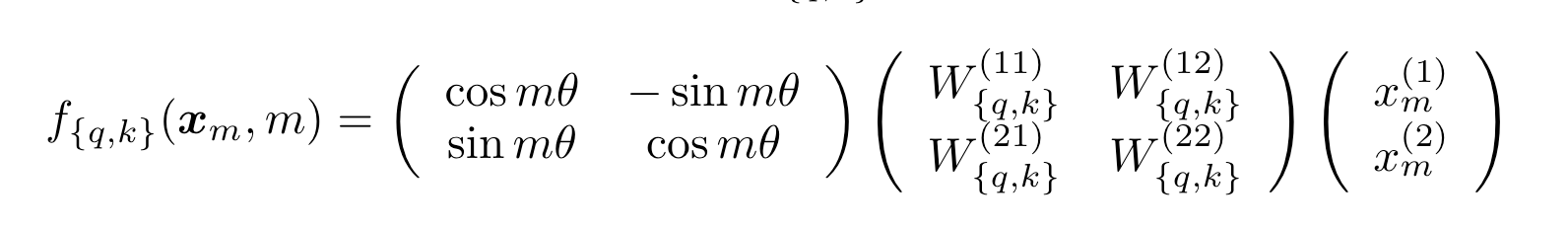
因为矩阵乘法线性累加的性质,可以拓展到多维的情况可得:
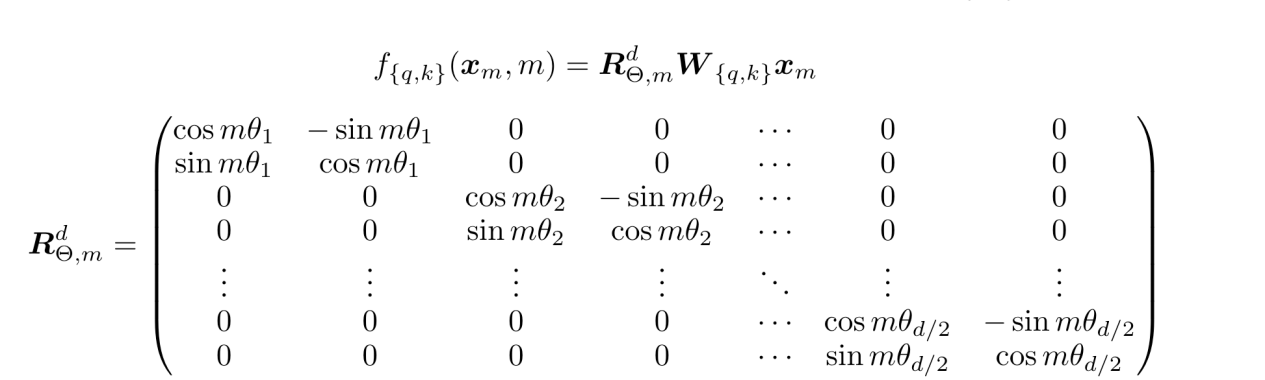
为了引入远程衰减的特性,Rope 中\theta 的选取选择了 Transformer 原始论文中 sinusoidal 公式。
Alibi
Alibi 是谷歌发表在 ICLR2022 的一篇工作,Alibi 主要解决了位置编码外推效果差的痛点,算法思想非常的简单,而且非常直观。与直接加在 Embedding 上的绝对位置编码不同,Alibi 的思想是在 Attention matrix 上施加一个与距离成正比的惩罚偏置,惩罚偏置随着相对距离的增加而增加。在具体实现时,对于每个 head 会有一个超参 m 来控制惩罚偏置随着相对距离增加的幅度(斜率)。
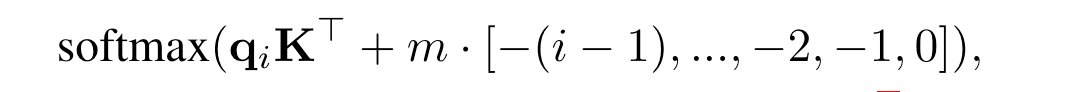

图 4-Alibi attention bias 示意图
论文结果显示 Alibi 极大的提升了模型的外推性能,16k token 的输入依然可以很好的支持
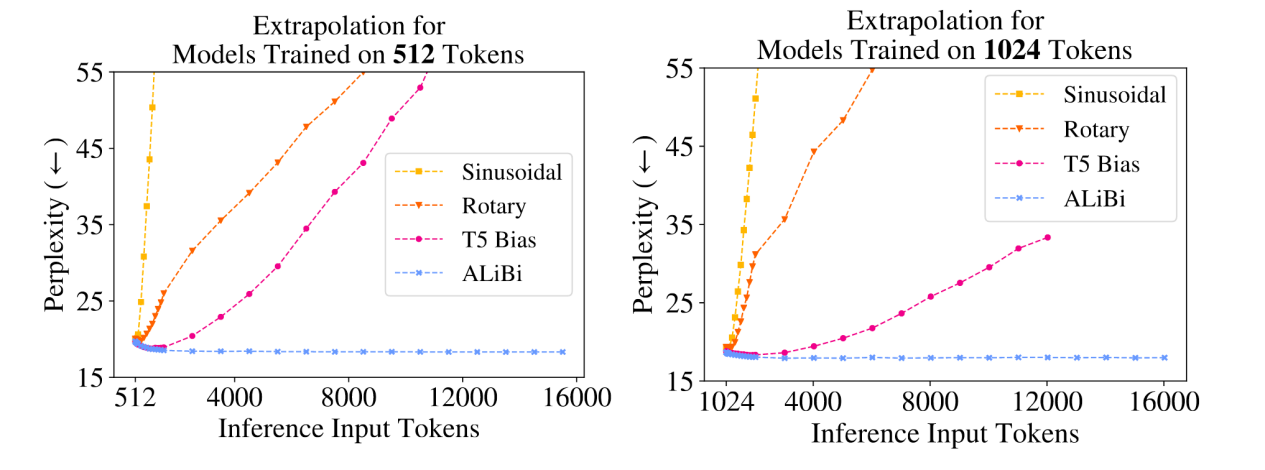
图 5-Alibi 外推效果对比
混合精度下位置编码的 bug
从上面的算法原理中,不管是 RoPE 的 cos(m \theta) 还是 alibi 的 i-1(m, i 代表 postion id), 都需要为每个位置生成一个整型的 position_id, 在上下文窗口比较大的时候,百川智能发现目前主流的位置编码实现在混合精度下都存在因为低精度(float16/bfloat16)浮点数表示精度不足导致位置编码碰撞的问题。尤其当模型训练(推理)时上下文长度越来越长,低精度表示带来的位置编码碰撞问题越来越严重,进而影响模型的效果,下面以 bfloat16 为例来说明这个 bug
浮点数表示精度
浮点数在计算机中表示由符号位(sign),指数位(exponent),尾数位(fraction) 三部分组成, 对于一个常规的数值表示,可以由如下公式来计算其代表的数值(其中 offset 是指数位的偏置):
(−1)sign∗2exponent−offset∗ 1.fraction
由公式可知,尾数位的长度决定了浮点数的表示精度。深度学习中常用的 float32/float16/bfloat16 内存中的表示分别如下图所示:
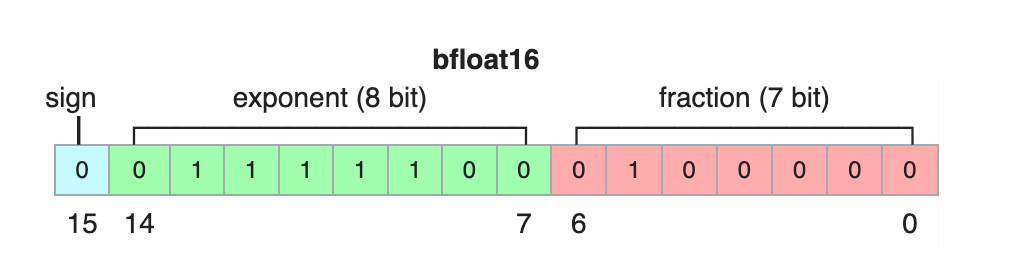
图 6-bfloat16 的表示格式
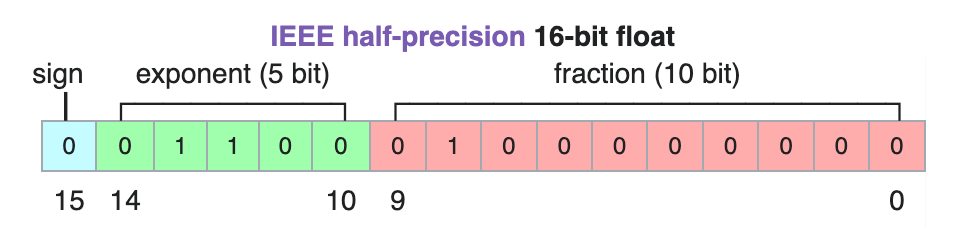
图 7-float16 的表示格式

图 8-float32 的表示格式
可以看到可以看到 float16 和 bfloat16 相比于 float32 都牺牲了表示的精度,后续以 bfloat16 为例说明位置编码中存在的问题(float16 同理)。 下表展示了 bfloat16 在不同数值范围(只截取整数部分)内的表示精度。
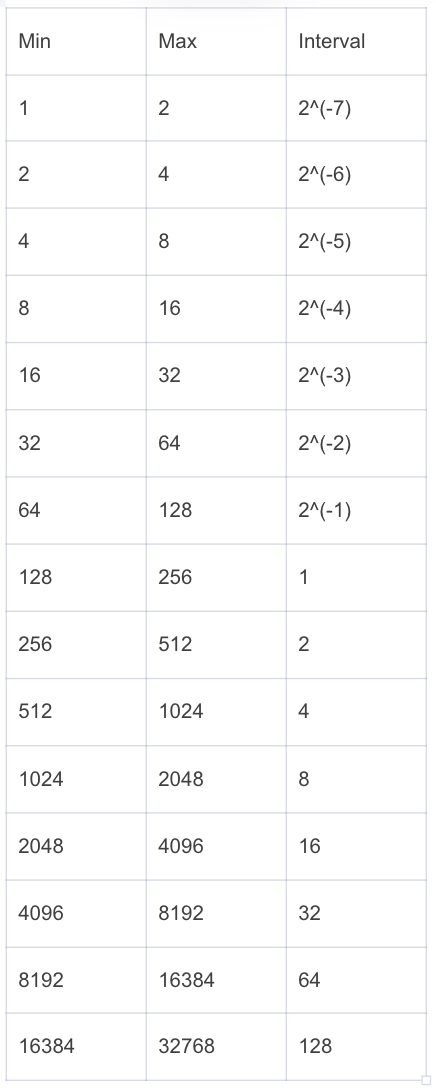
可以看到当整数范围超过 256,bfloat16 就无法精确表示每一个整数,我们可以用代码验证一下表示精度带来的问题
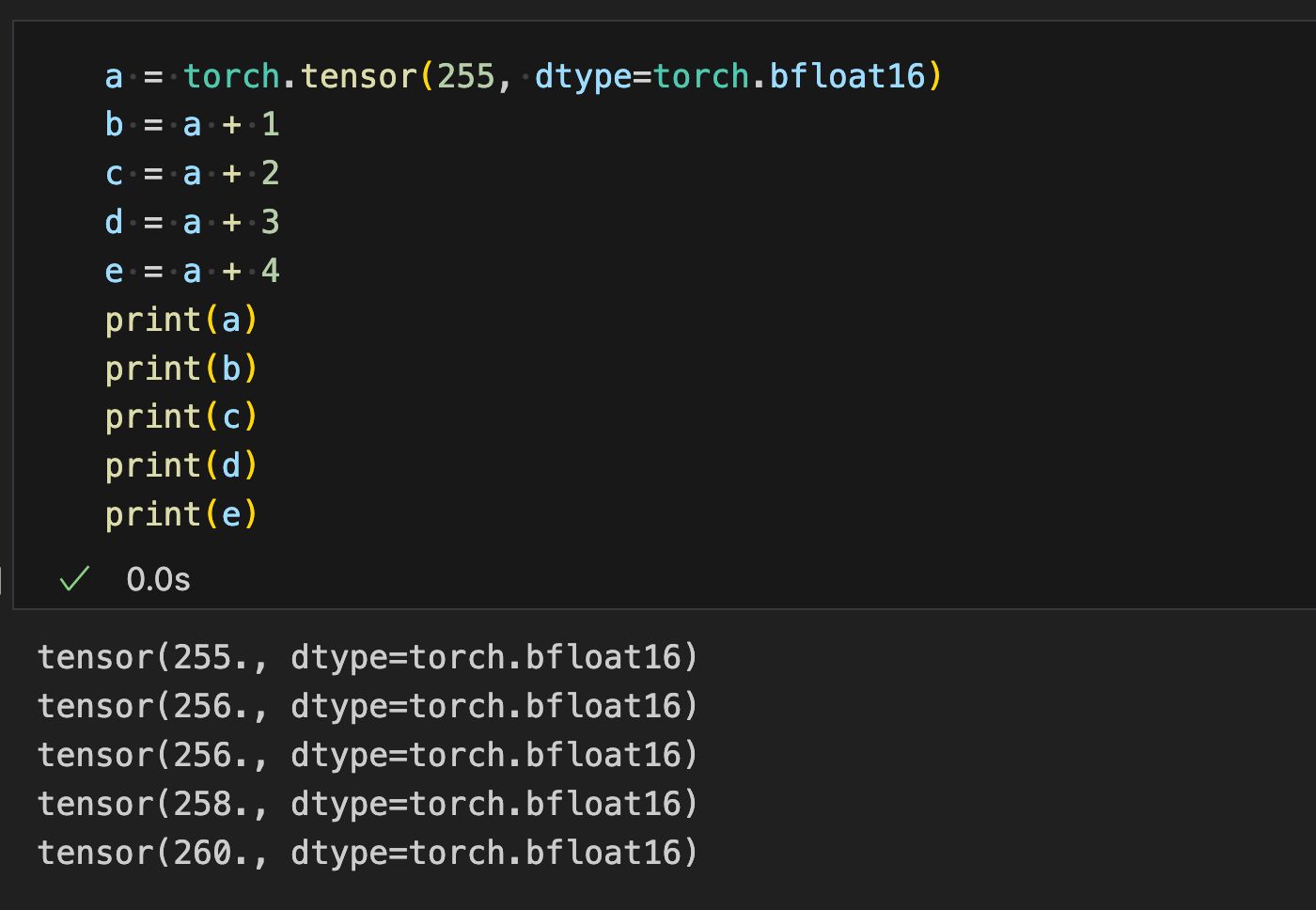
RoPE& Alibi 编码的问题
Meta 开源的 llama 模型采用了 RoPE 的位置编码方式,官方的实现(以及大部分的第三方 llama 系列模型)在 bfloat16 下存在精度问题带来的位置编码碰撞(不同位置的 token 在 bfloat16 下变成同一个数)。llama 官方代码如下:

上面第 18 行核心一句根据输入序列长度生成每个位置的 positonidx 在 bfloat16 下产生位置碰撞

在实际训练时如果开了 bfloat16,self.inv_freq 的 dtype 会被转为 bfloat16,我们可以通过简单的代码来看一下位置碰撞的问题

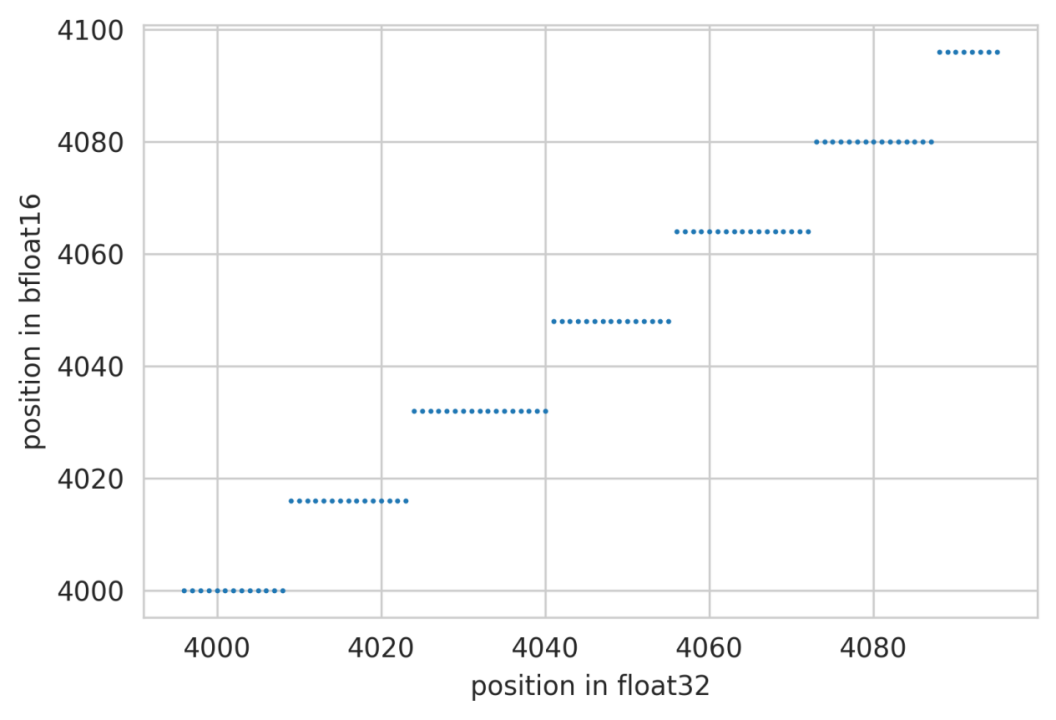
图 9-bfloat16 位置碰撞示意图
• 根据 bfloat16 的表示精度可知,训练(推理)时上下文长度越长,位置编码碰撞的情况越严重,长度为 8192 的上下文推理中,仅有大约 10%的 token 位置编码是精确的,好在位置编码碰撞有局域性的特质,只有若干个相邻的 token 才会共享同一个 positionEmbedding,在更大的尺度上,不同位置的 token 还是有一定的区分性。
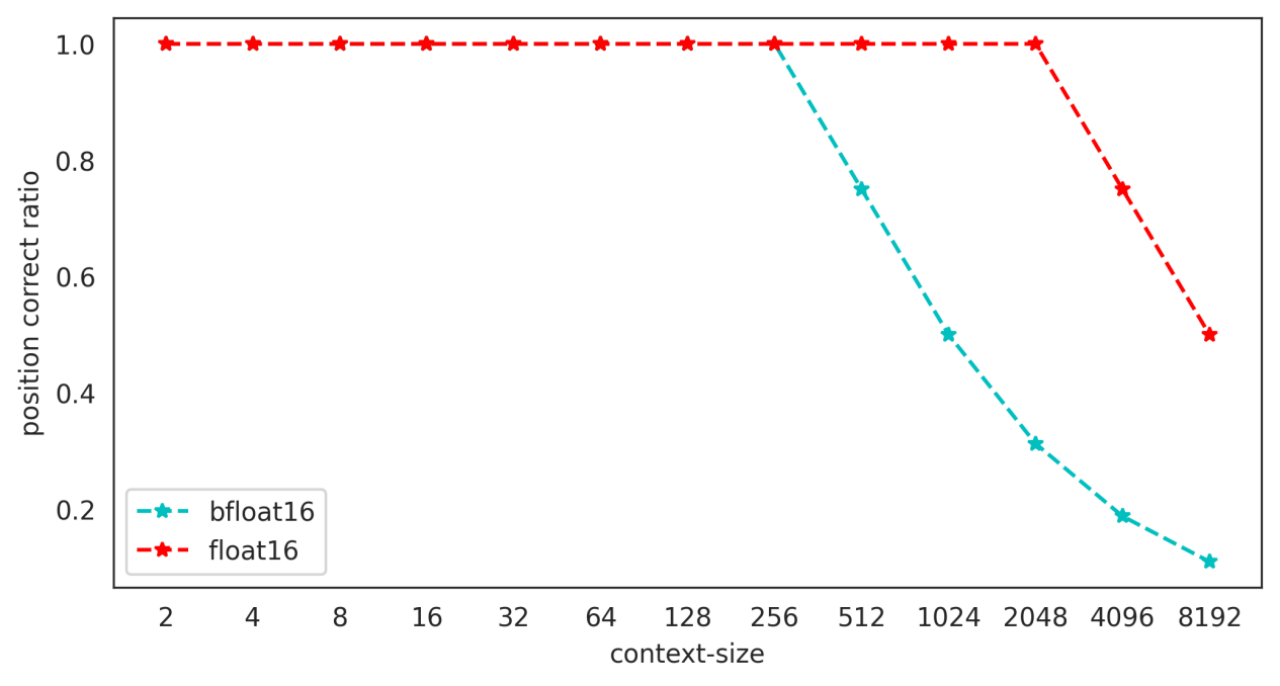
图 10-不同上下文窗口下位置编码精确 token 所占比例
除了 RoPE 位置编码方案,百川智能发现 Alibi 位置编码也存在上述问题,原因依然在于生成整数的位置索引时会在低精度下产生碰撞问题。
修复方案
RoPE 修复
○ RoPE 的修复相对简单,只需要保证在生成 position_id 的时候一定在 float32 的精度上即可。注意:
▪ float32 的 tensor register_buffer 后在训练时如果开启了 bfloat16,也会被转为 bfloat16

Alibi 修复
○ Alibi 位置编码修复思路和 RoPE 的修复思路一致,但因为 Alibi 的 attention bias 直接加在 attention matrix 上面,如果按照上面的修复思路,attention matrix 的类型必须和 attention bias 一致,导致整个 attention 的计算都在 float32 类型上计算,这会极大的拖慢训练速度
○ 目前主流的 attention 加速方法 flashattention 不支持 attention bias 参数, 而 xformers 要求 attention bias 类型必须与 query.dtype 相同,因此像 RoPE 那样简单的将 attention bias 类型提升到 float32 将会极大的拖慢训练速度
○ 针对该问题百川智能提出了一种新的 Alibi attention 方案, 整个 attention bias 依然在 bfloat16 类型上,类似于 sinusoidal 的远程衰减特质,我们尽量保证临近 token 位置编码的精确性,对于相对距离过远的的 token 我们则可以容忍其产生一定的位置碰撞。原本的 Alibi 实现则相反,相对距离越远的 token 表示越精确,相对距离越近的 token 则会碰撞
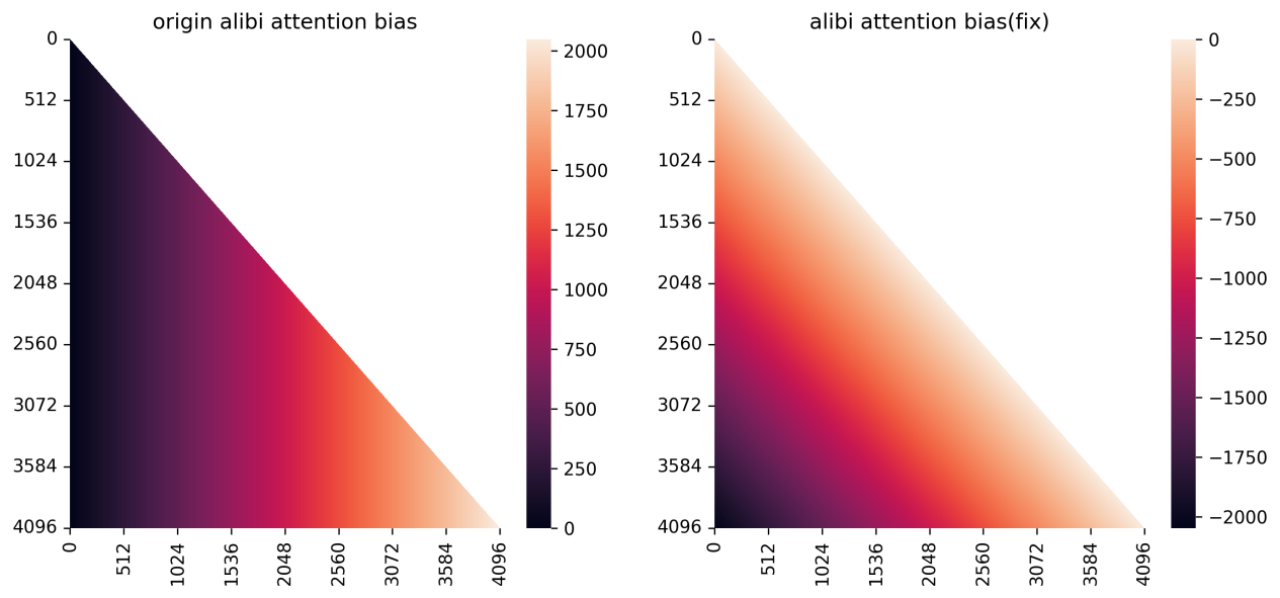
图 11-修复前后 alibi attention_bias 对照
修复效果
• 此处仅在推理阶段对位置编码的精度问题进行修复【注:训练阶段可能也存在问题,取决于训练的具体配置和方法】,可以看到:
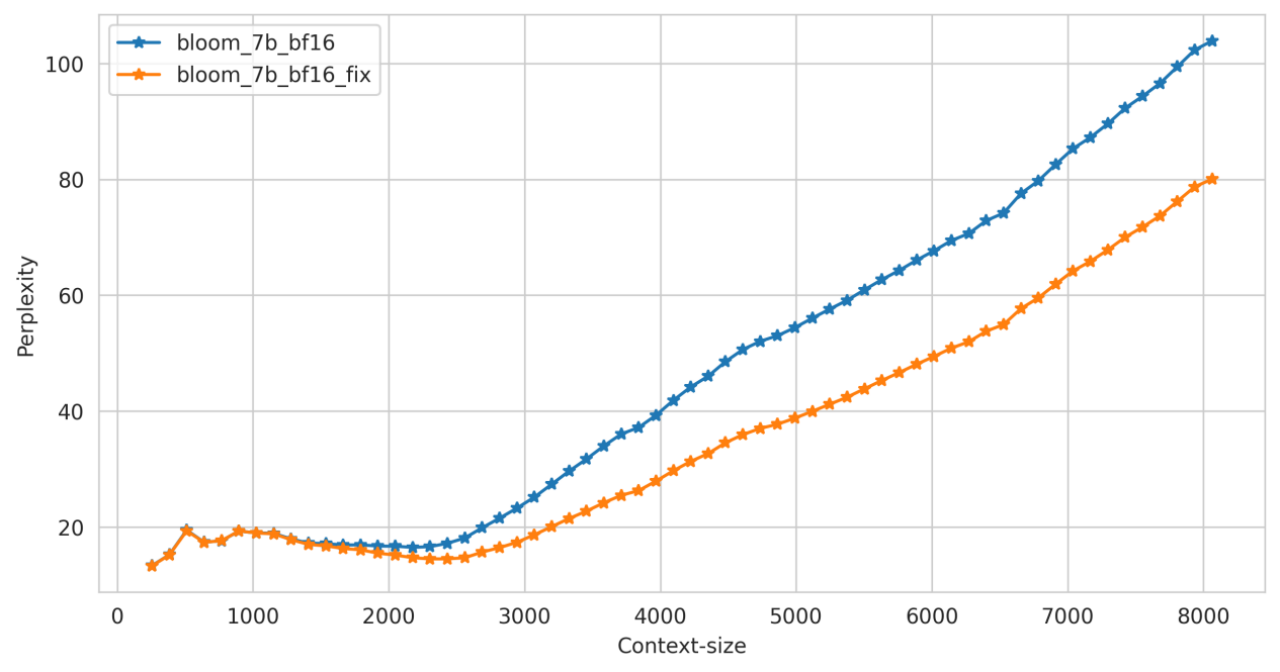
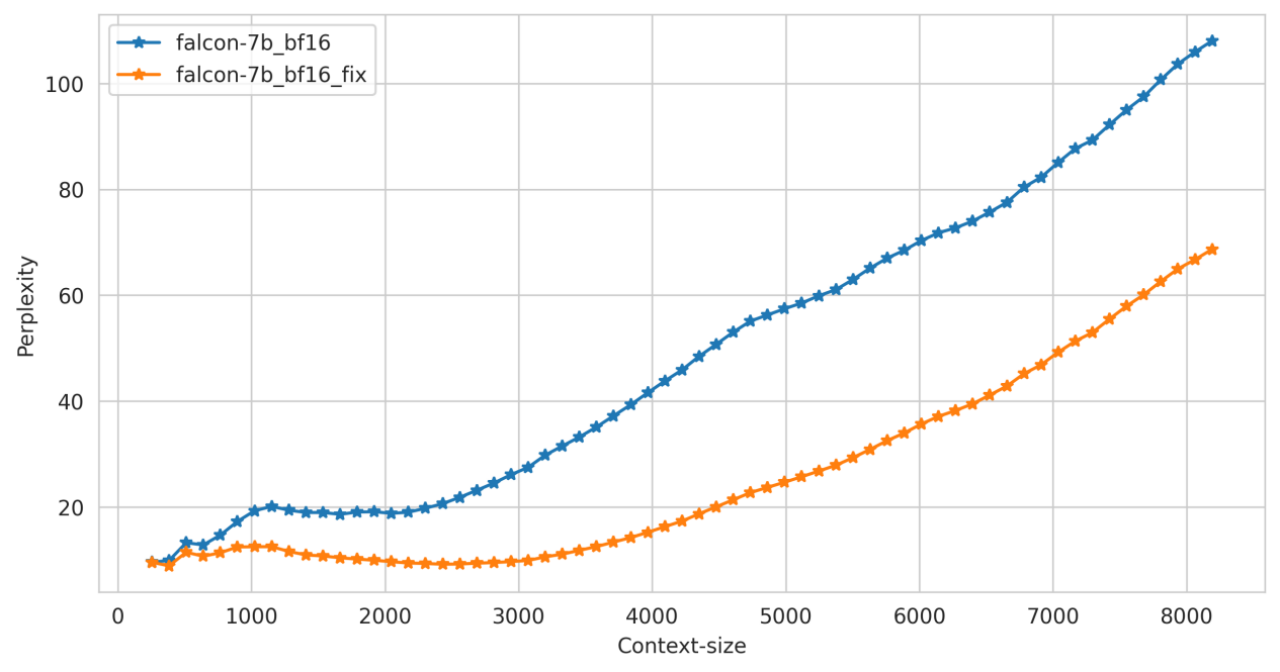
a. 在长上下文的推理中,模型的 ppl 要显著优于修复前的 ppl
b. Benchmark 上测试结果显示修复前后区别不大,可能是因为 benchmark 上测试文本长度有限,很少触发 Position embedding 的碰撞
Benchmark 对比
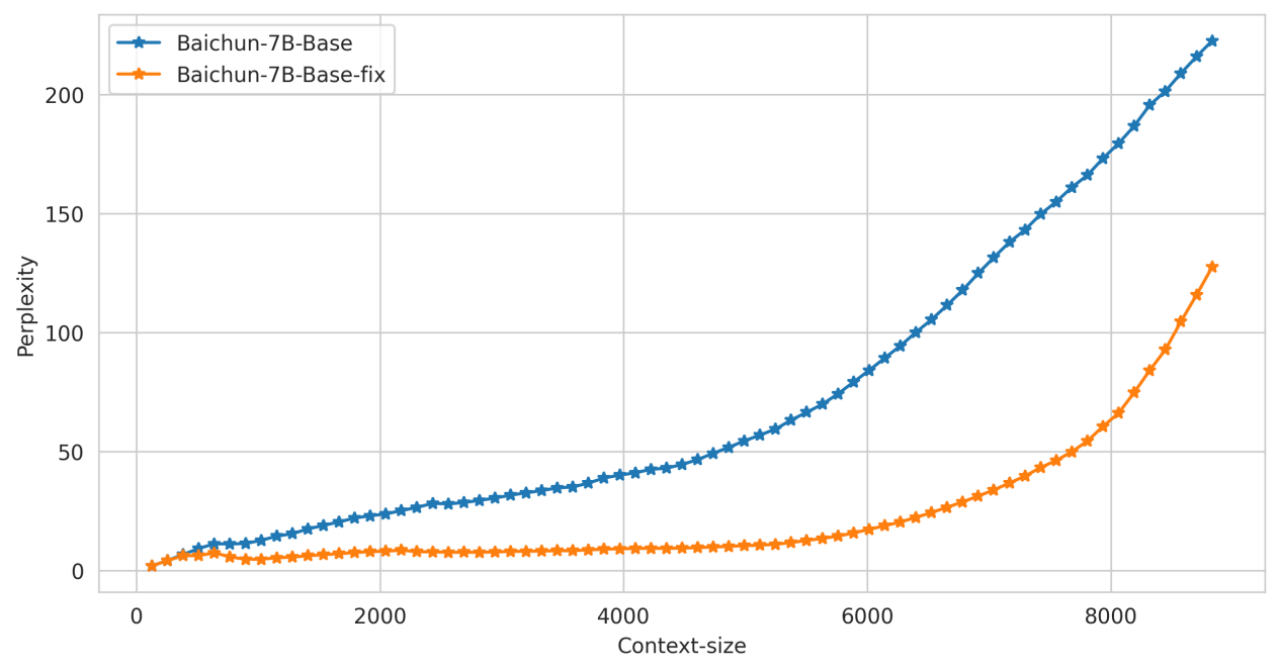
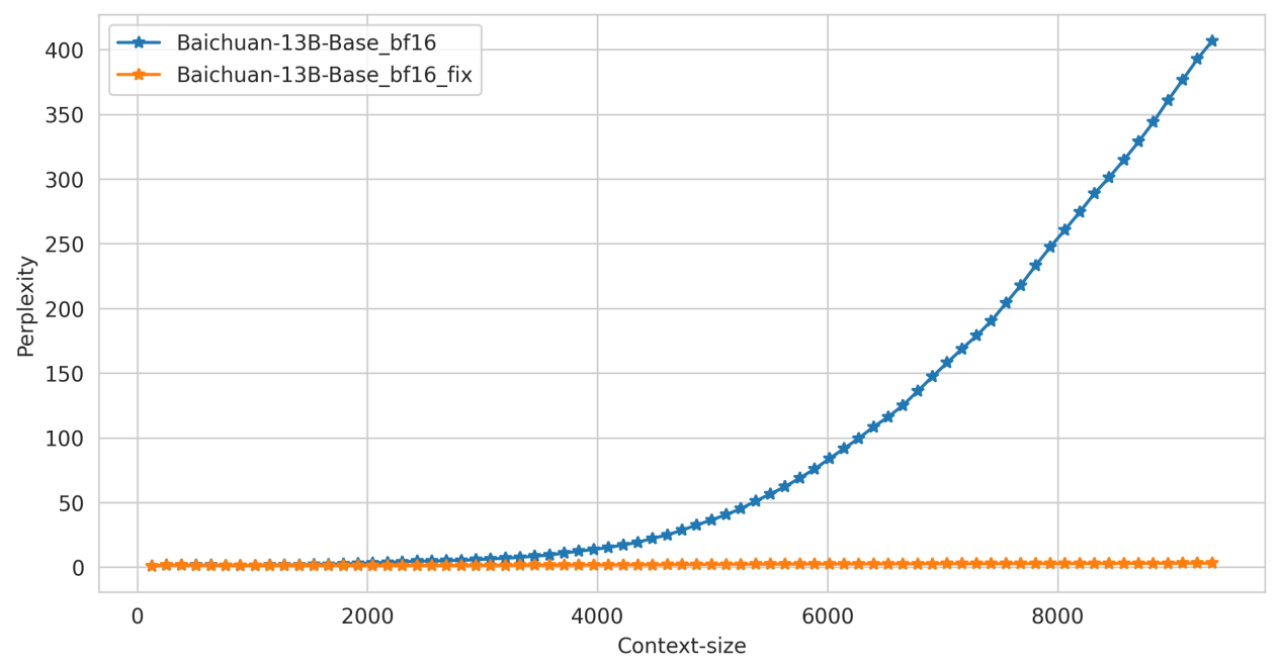
Perplexity 对比
在通用的文本数据上对修改前后模型在中英文文本上的困惑度进行测试,效果如下:
参考资料:
Dongxu Zhang, & Dong Wang. (2015). Relation Classification via Recurrent Neural Network.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, & Illia Polosukhin. (2023). Attention Is All You Need.
Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, & Ruslan Salakhutdinov. (2019). Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context.
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, & Peter J. Liu. (2020). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, & Guillaume Lample. (2023). LLaMA: Open and Efficient Foundation Language Models.
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, & Yunfeng Liu. (2022). RoFormer: Enhanced Transformer with Rotary Position Embedding.
Ofir Press, Noah A. Smith, & Mike Lewis. (2022). Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation.
Yutao Sun, Li Dong, Barun Patra, Shuming Ma, Shaohan Huang, Alon Benhaim, Vishrav Chaudhary, Xia Song, & Furu Wei. (2022). A Length-Extrapolatable Transformer.
https://kazemnejad.com/blog/transformer_architecture_positional_encoding/
Shouyuan Chen, Sherman Wong, Liangjian Chen, & Yuandong Tian. (2023). Extending Context Window of Large Language Models via Positional Interpolation.




