
2 月 23 日凌晨,月之暗面发布最新论文《Muon is Scalable for LLM Training》,并开源了 MoE 模型 Moonlight( MIT 许可证),模型激活参数仅需 3B。
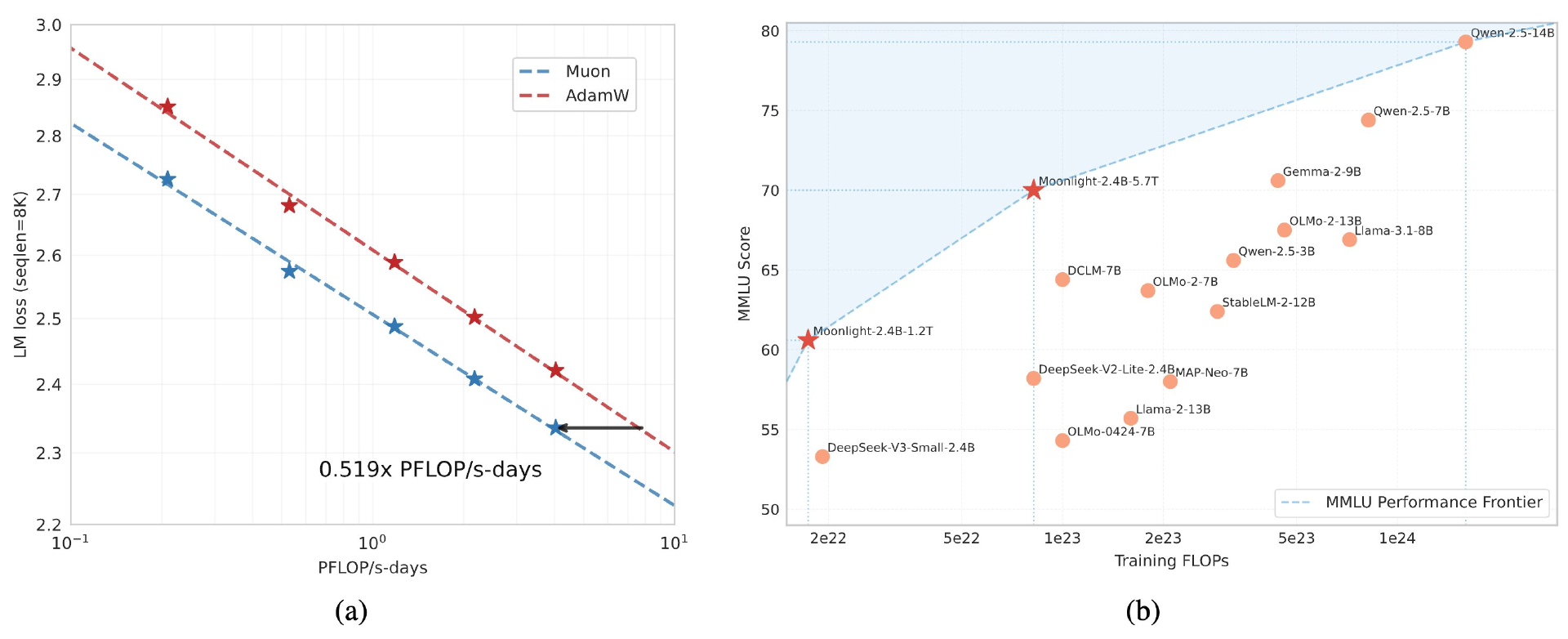
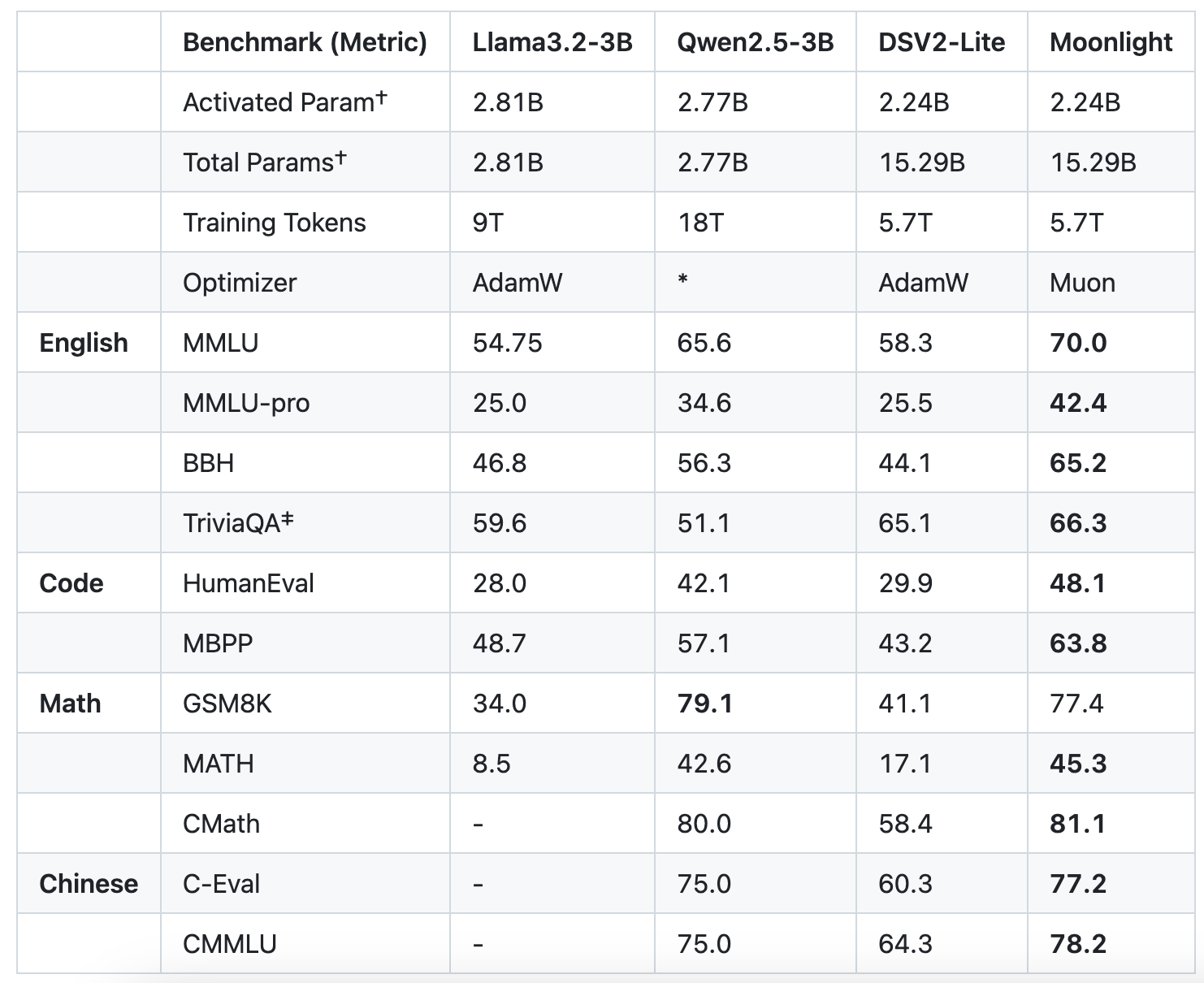
论文显示,月之暗面通过深度改造 Muon 优化器并将其运用于实际训练,证明了 Muon 在更大规模训练中的有效性,是 AdamW 训练效率的 2 倍且模型性能想相当。Moonlight 3B/16B MoE 模型使用 Muon 在 5.7T token 上进行训练,“以更少的 FLOP 和更好的性能推进帕累托前沿。”

月之暗面此次贡献主要在于:
Muon 有效扩展分析:月之暗面发现权重衰减在 Muon 的可扩展性中起着至关重要的作用。此外,团队提出通过参数级别更新尺度调整,保持不同矩阵和非矩阵参数之间的一致更新均方根(RMS)。这种调整显著提高了训练稳定性。
高效分布式实现:团队开发了一个基于 ZeRO-1 优化的 Muon 分布式版本,实现了最佳内存效率并降低了通信开销,同时保持算法的数学特性。
Scaling Law 验证:月之暗面进行了 Scaling Law 研究,比较了 Muon 与 AdamW 的性能,结果显示 Muon 具有更优的表现。根据 Scaling Law 结果,Muon 在性能上与 AdamW 训练的对比模型相当,但训练所需的 FLOP 仅约为 AdamW 的 52%。
对于月之暗面深夜发布开源模型的行为,有网友认为是在截胡 DeepSeek。2 月 21 日午间,DeepSeek 团队在 X 官方账号发布消息,下周将陆续完全开源 5 个代码库,为“开源周”(OpenSourceWeek)预热,以完全透明的方式分享研究进展。
根据媒体消息,QuestMobile 最新数据显示,DeepSeek App 以“零营销”姿态创造增长神话:上线至 2 月 9 日,累计下载量突破 1.1 亿次,周活跃用户最高触及 9700 万。这一成绩正在重塑行业竞争规则。
反观传统玩家的“重营销”策略遭遇寒冬。Kimi 过去一年投入近 9 亿元营销费用,每月营销预算高达 2 亿元,在小红书等平台大手笔投放,一度让 B 站"沦陷"。然而即便投入如此巨资,其日活规模仍未破千万,与 DeepSeek 短短数十天靠自然流量达到 3500 万日活形成鲜明对比。此外,豆包的投放规模据称是 Kimi 的数倍,Minimax 的 Talkie 在海外投入数千万美金,星野在国内市场也投入上亿元。
代码和实现:https://github.com/MoonshotAI/Moonlight
完整模型系列:https://huggingface.co/moonshotai
论文:https://github.com/MoonshotAI/Moonlight/blob/master/Moonlight.pdf




