
美国时间 5 月 18 日,Google I/O 2021开发者大会正式开幕。去年,该会议因疫情取消,今年重新恢复并采用全程线上的形式,对所有开发者免费开放。在刚刚结束的主题演讲中,谷歌发布了 TPU V4 人工智能芯片、自然语言平台 LaMDA 以及一系列原有产品的更新升级。本文,我们将详细介绍谷歌搜索引入的多任务统一模型 MUM。
每天都有很多人使用谷歌来处理需要多步骤的各种任务,而人们在处理类似的复杂任务时平均会发出 8 个查询。如今,搜索引擎还没有成熟到可以像专家一样回答问题。但随着“多任务统一模型”(Multitask Unified Model,MUM)的出现,谷歌正在帮助解决这类复杂需求。因此,未来只需要较少的搜索就可以完成任务。
与 BERT 一样,MUM 同样基于 Transformer 架构,但是它的功能要强大 1000 倍。MUM 不仅可以理解语言,而且可以生成语言。MUM 同时用 75 种不同的语言进行了多项任务的训练,使其比以前的模型更全面地理解信息和世界知识。此外,MUM 是多模态的,因此它能够理解文本和图像中的信息,将来,还可以扩展到视频和音频等更多模态。
以徒步富士山的问题为例:MUM 可以理解你在比较两座山,因此海拔高度和路径信息可能是相关的。它还可以理解,就远足而言,“准备工作”可能包括诸如健身训练以及寻找合适的装备。
因为 MUM 能够基于其对这个世界的深刻理解来展现自己的见解,所以它可以强调,尽管两座山的海拔高度大致相同,但秋季是富士山的雨季,你可能需要一件防水夹克。MUM 也能为更深层次的探索提供有用的副主题:比如顶级装备或最佳训练练习,并提供一些网络上有用的文章、视频和图片的链接。

消除语言障碍
在获取信息时,语言可能是一个重要障碍。通过不同语言的知识迁移,MUM 有可能打破这些界限。它可以从那些不是用你的搜索语言写成的资料中学习,并且能帮助把这些相关信息发给你。
假设有一些关于富士山真正有用的信息是用日语写的;现在,如果你不用日语搜索,你很可能无法找到这些信息。然而,MUM 可以从不同语言的来源中迁移知识,并利用这些洞察力发现与你的首选语言最相关的结果。所以,在将来,当你搜索有关远足富士山的信息时,你可能会看到这样的结果:在何处能欣赏到富士山最美的风景、当地的温泉,以及受欢迎的纪念品商店……这些信息很容易用日语搜索就能找到。
理解不同类型的信息
多模态的 MUM 意味着它能够同时理解来自不同格式的信息,比如网页、图片等等。最终,你可能会拍一张登山靴的照片,然后问:“我能用它去爬富士山吗?”MUM 将会理解这张图片,并把它和你的问题联系在一起,让你知道你的靴子会很好用。之后,它会给你发一个博客网址,上面有推荐的装备列表。
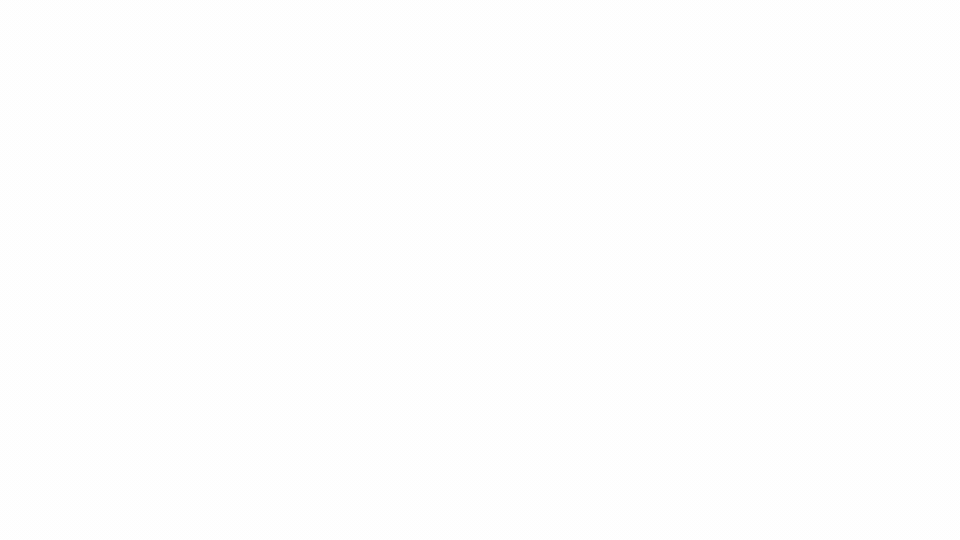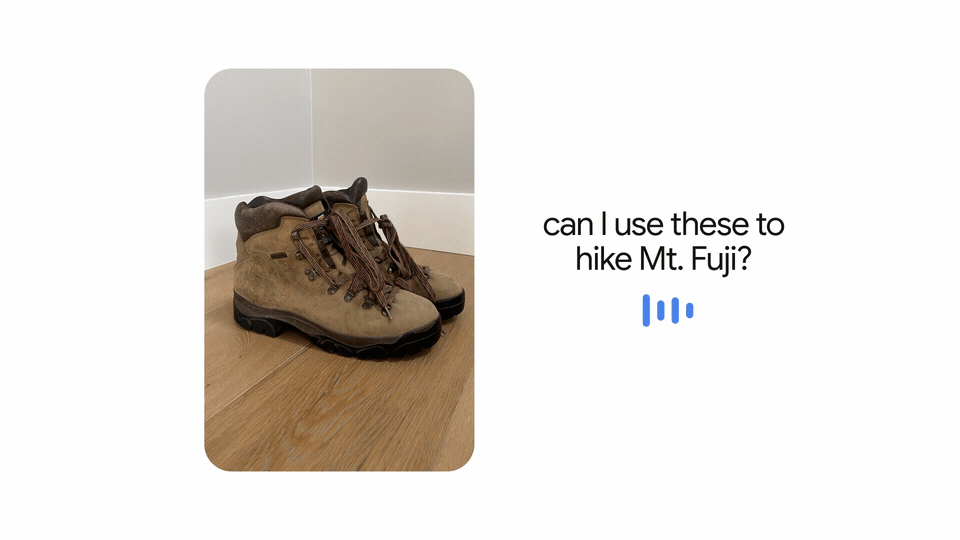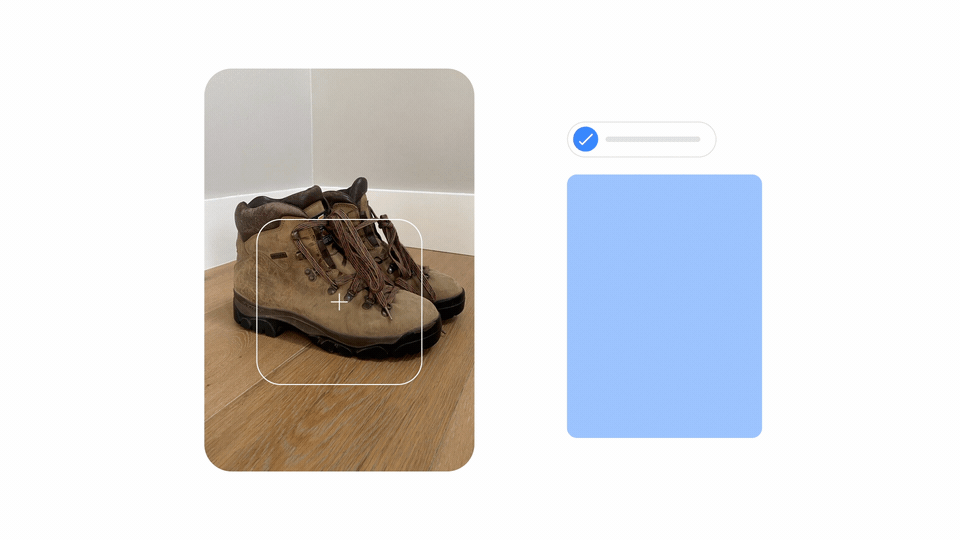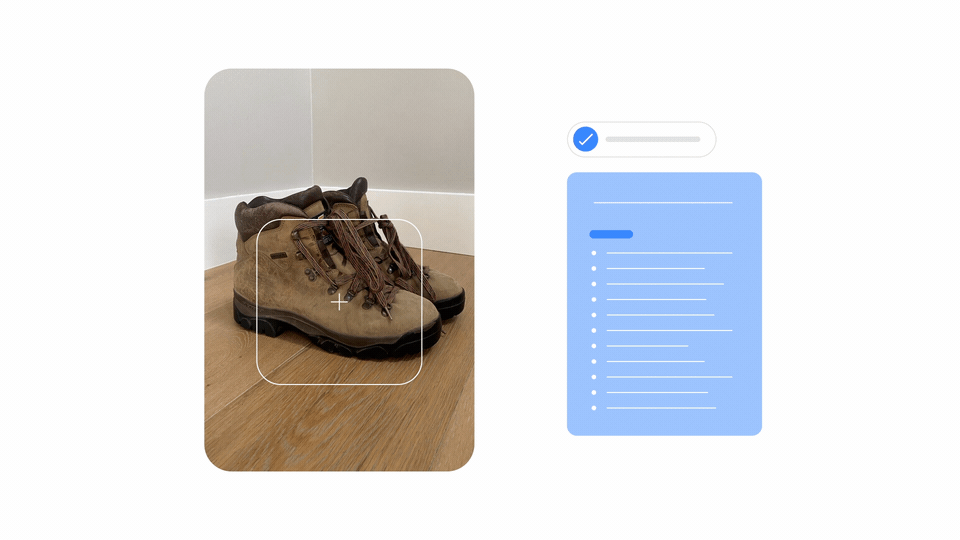
带着负责的态度把高级人工智能运用到搜索中
无论何时,当我们使用人工智能来使世界上的信息更容易获取时,我们都要负责任地这样做。对于谷歌搜索的每一项改进,我们都会进行严格的评估,以确保我们能提供更加相关和有用的结果。那些遵循我们《搜索质量评分准则》(Search Quality Rater Guidelines)的人类评分者,帮助我们了解我们的结果如何帮助人们找到信息。
就像我们已经仔细测试了 BERT 从 2019 年开始推出的许多应用一样, MUM 也会经历同样的过程,将这些模型应用于搜索。具体地说,为了避免在我们的系统中引入偏见,我们将寻找可能显示机器学习中偏见的模式。同时,我们也会运用最新的研究成果,比如如何减少 MUM 等训练系统的碳足迹,以确保搜寻工作尽可能高效。
今后数月甚至数年,我们将把 MUM 驱动的功能和改进带到我们的产品中。虽然我们仍处在 MUM 探索的初期,但这是一个重要的里程碑,将来谷歌能够理解人们自然地交流和解释信息的各种方式。
作者介绍:
Pandu Nayak,谷歌研究员兼搜索部门副总裁。
原文链接:




