
Yelp 公司 采用 Apache Beam 和 Apache Flink 重新设计了原来的数据流架构。该公司使用 Apache 数据流项目创建了统一而灵活的解决方案,取代了将交易数据流式传输到其分析系统(如 Amazon Redshift 和内部数据湖)的一组分散的数据管道。
Yelp 在两套不同的在线系统中管理业务实体(其平台中的主要数据实体之一)的属性。平台的旧版部分将业务属性存储在 MySQL 数据库中,而采用微服务架构的较新部分则使用 Cassandra 存储数据
在过去,该公司将数据从在线数据库流式传输到离线(分析)数据库的解决方案,是由上述管理业务属性的两个区域的一些独立数据管道组成的。该方案使用 MySQL 复制处理程序 从旧系统推送数据,使用 Cassandra 源连接器 从新系统推送数据。在这两种情况下,更新都发布到 Apache Kafka,而 Redshift 连接器负责将数据同步到相应的 Redshift 表。
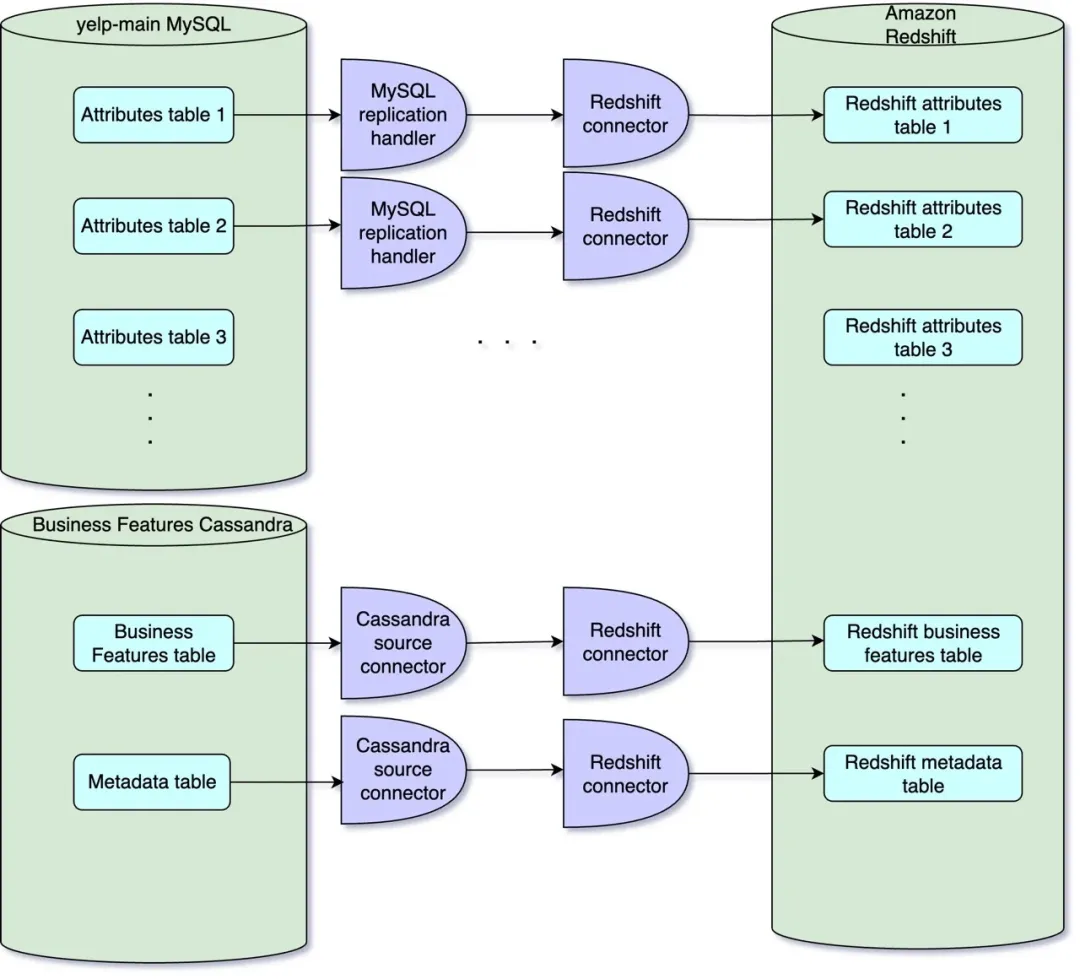
原有解决方案采用单独的数据管道,将数据从在线数据库流式传输到分析数据存储中,其封装性较弱,因为离线(分析)数据存储中的数据表与在线数据库中的对应表完全对应,使数据分析团队面临数据差异和数据准确性问题。此外,分析过程必须从多个表中收集数据,并将这些数据规范化为一致的格式。最后,由于在线和离线数据存储之间的表架构相同,对架构的更改必须在两处各自部署,从而带来了维护挑战。
Yelp 团队决定解决原有方案的这些问题,方法是将在线系统的内部实施细节抽象出来,并为使用分析数据存储的客户提供一致的体验。Yelp 高级数据工程师 Hakampreet Singh Pandher 解释了团队采用的方法:[...]
我们实施了一个统一的流,以一致且用户友好的格式提供所有相关的业务属性数据。这种方法可确保业务属性消费者无需处理业务属性和功能之间的细微差别,也无需了解它们的在线源数据库中数据存储的复杂性。
团队利用 Apache Beam 和 Apache Flink 作为分布式处理后端。Apache Beam 转换作业从旧版 MySQL 和较新的 Cassandra 表中获取数据,将数据转换为一致的格式并将其发布到单个统一的流中。工程师使用 Joinery Flink 作业 将业务属性数据与相应的元数据合并。另一项作业用于解决数据不一致的问题,最后在 Redshift Connector 和 Data Lake Connector 的帮助下,业务属性数据进入两个主要的离线数据存储中。

彻底改造流式架构的总体收益是让数据分析团队能够通过单一模式访问业务属性数据,这有助于数据发现,让数据消费更简单。该团队还利用 实体 - 属性 - 值(EAV)模型,将新业务属性纳入系统,同时减少维护开销。
原文链接:
Yelp Overhauls Its Streaming Architecture with Apache Beam and Apache Flink (https://www.infoq.com/news/2024/04/yelp-streaming-apache-beam-flink/)
声明:本文为 InfoQ 翻译,未经许可禁止转载。




