
DeepSeek 开源周第二日,DeepSeek 发布来了 DeepEP,这是一个专为混合专家模型(Mixture-of-Experts, MoE)和专家并行(Expert Parallelism, EP)设计的通信库。它的特点是:
高效通信:提供了高吞吐量、低延迟的 GPU 通信功能(比如 MoE 中的分发和组合操作),还支持低精度计算(比如 FP8)。
优化带宽:针对 DeepSeek-V3 论文中的算法,优化了数据在不同硬件域(比如 NVLink 到 RDMA)之间的传输,适合训练和推理任务,还能控制 GPU 资源(SM)的使用。
低延迟推理:对推理任务特别优化,使用纯 RDMA 通信来减少延迟,还支持通信和计算重叠的技术,不占用额外 GPU 资源。
具体来讲,为了与 DeepSeek-V3 论文中提出的组限门控算法(group-limited gating algorithm)保持一致,DeepEP 提供了一组针对非对称域带宽转发优化的内核,例如从 NVLink 域转发数据到 RDMA 域。
DeepSeek 在 H800 这种硬件设备上(NVLink 数据传输通道最大传输速度约每秒 160GB)测试那些常规的内核程序。每一个 H800 设备都连接了一张 CX7 InfiniBand 型号的 400 Gb/s 的 RDMA 网卡(每卡最大传输速度每秒约 50GB)。

再按照 DeepSeek-V3/R1 这个预训练的方案来操作(每次处理数据批次里有 4096 个数据单元,隐藏层有 7168 个节点,分组是取前 4 组,专家模块选前 8 个,用 FP8 格式来分配数据,用 BF16 格式来整合数据 )。
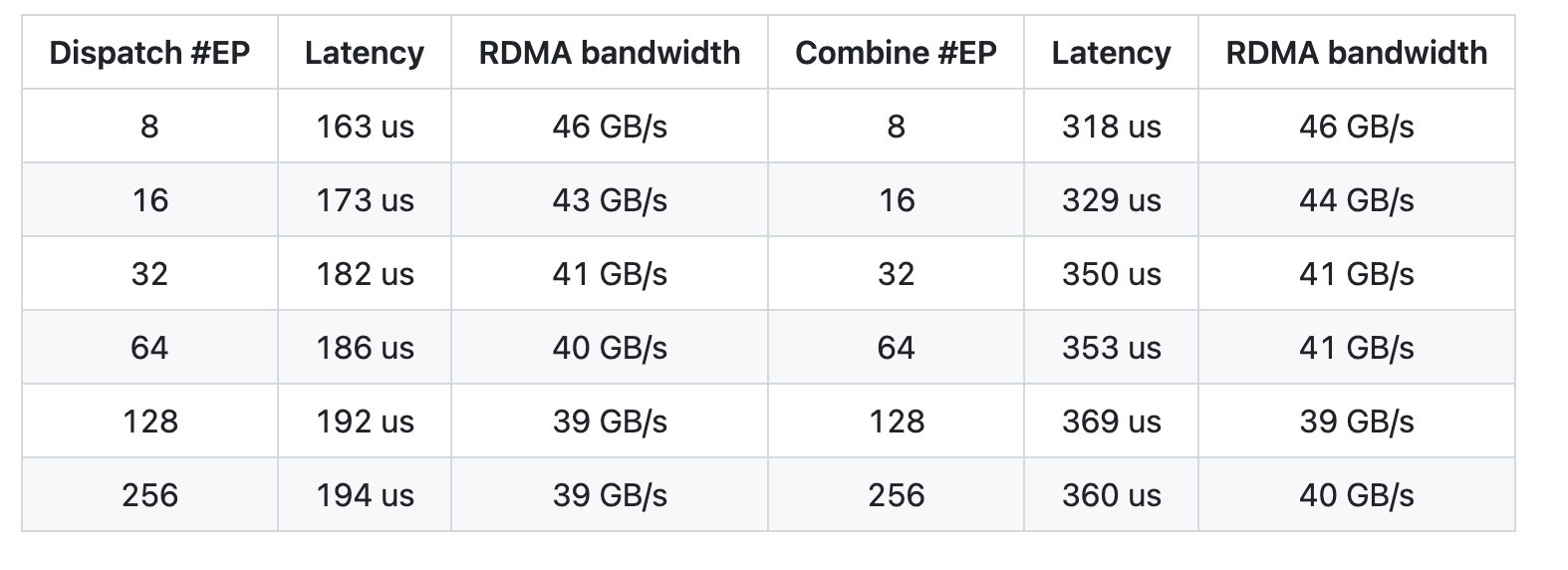
在 H800 上对低延迟内核进行测试时,每台 H800 都连接着一块 CX7 InfiniBand 400 Gb/s 的 RDMA 网卡(最大带宽约为 50 GB/s)。遵循 DeepSeek - V3/R1 的典型生产环境设置(每批次 128 个词元、7168 个隐藏单元、前 8 个专家、FP8 调度和 BF16 合并)。
值得一提的是,DeepSeek 还在 GitHub 上构建了单独的一个库,用于放置他们本周发布的所有开源库,项目地址:https://github.com/deepseek-ai/open-infra-index。
目前,DeepEP 需要的软硬件环境版本如下:
Hopper GPUs(以后可能支持更多架构或设备)
用于节点内通信的 NVLink
用于节点内通信的 RDMA 网络
Python 3.8 及更高版本
CUDA 12.3 及更高版本
PyTorch 2.1 及更高版本




