
最近一段时间,中国大模型频频“刷屏”。
前脚,DeepSeek V3 用 557.6 万美元的训练成本给海外大模型上了一课,后脚,MiniMax 就用两个开源大模型拿下“铁王座”。
就在 MiniMax 宣布开源的前几日,黄仁勋在 CES 2025 上构造了一个 Agent 蓝图。可以说,Agent 作为大模型落地最有价值的路径,其潜力已经得到了全世界范围的广泛认可。
而中国大模型的频频“刷屏”,也将为 Agent 的落地和爆发提供更多可能性。
MiniMax:新晋的全球顶级开源模型
近日,MiniMax 宣布开源两款模型:基础语言大模型 MiniMax-Text-01 和视觉多模态大模型 MiniMax-VL-01。
这是 MiniMax 的开源首秀,一出手,就是两个“王炸”:MiniMax-Text-01 在 4560 亿参数的规模上实现了线性注意力创新架构,单次激活参数 459 亿;MiniMax-VL-01 在 MiniMax-Text-01 的基础上,使用了 5120 亿个视觉-语言 token 进行持续训练。
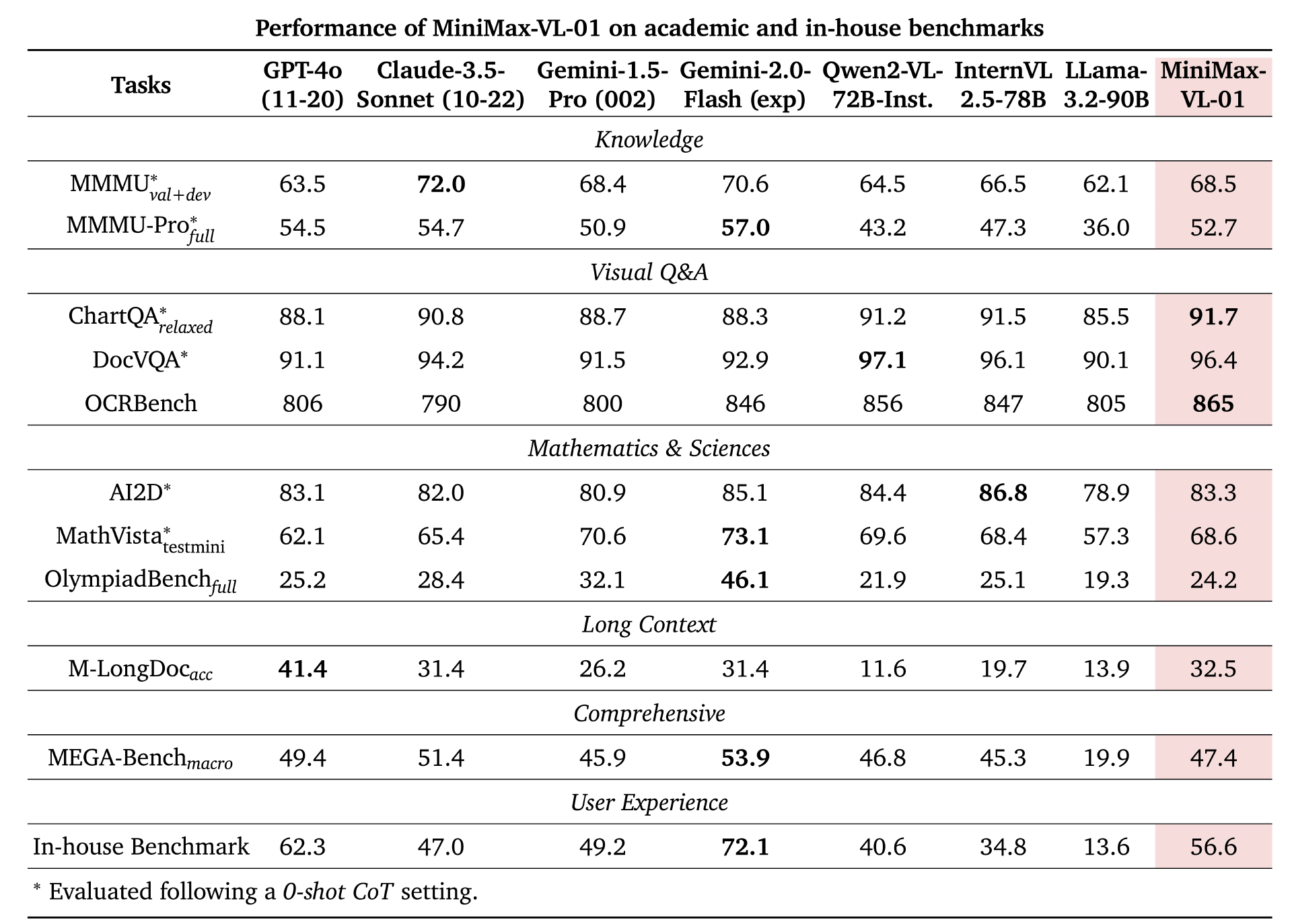
在与 GPT-4o、Claude-3.5-Sonnet 等海外顶尖模型的基准性能测试对比中,MiniMax 的这两款模型在多个核心任务中表现毫不逊色,甚至在某些任务上更胜一筹。

在 MMLU(一般知识测试)、IFEval(指令遵循)和 Arena-Hard(困难问题解答)任务类型中,MiniMax-Text-01 与其他顶尖模型不相上下;在 C-SimpleQA(简单问答)测试中,MiniMax-Text-01 更是超越了所有模型实现领跑。
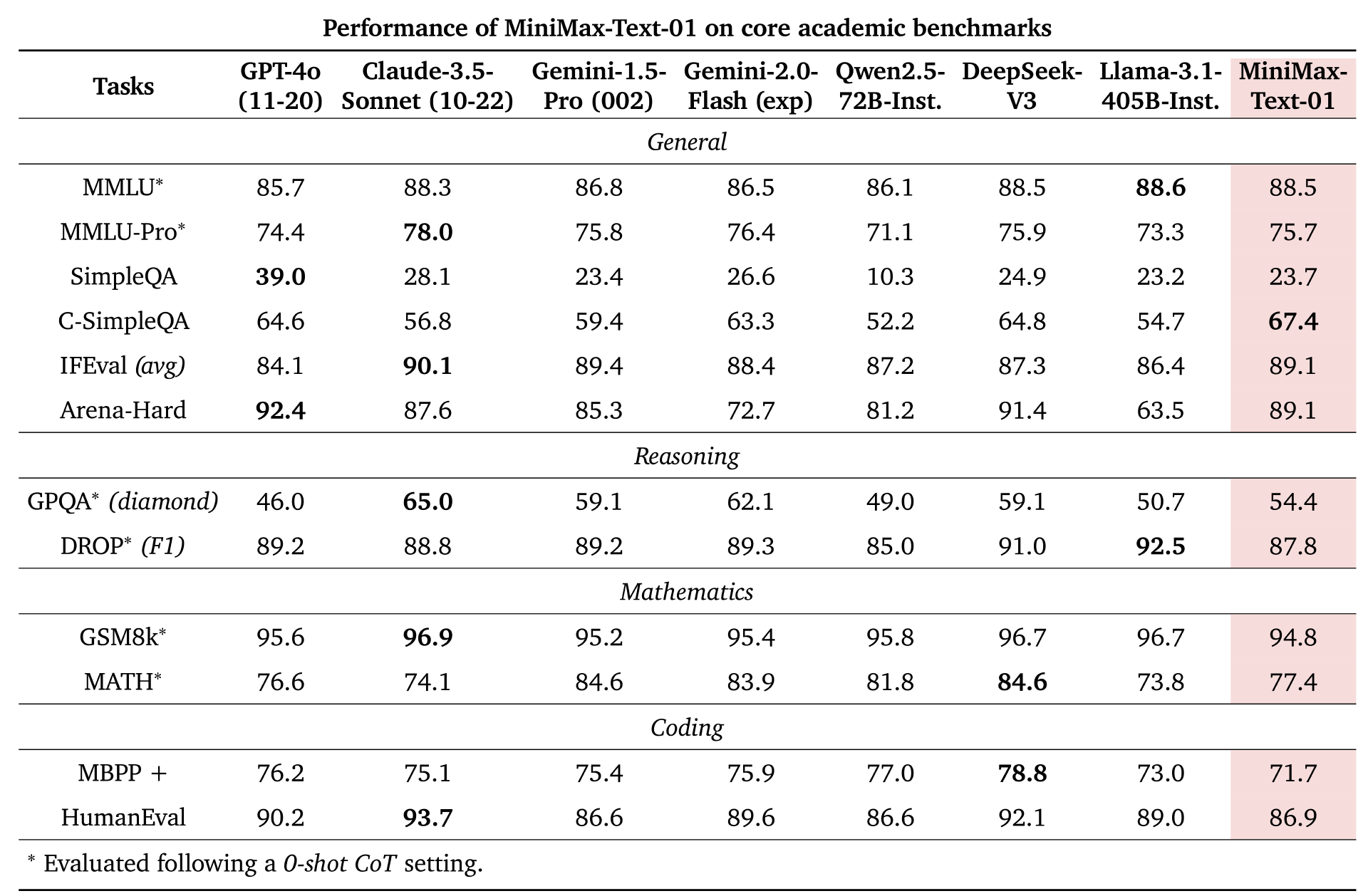
在综合性能比肩海外顶尖模型的基础上,MiniMax-Text-01 在长文本上带来了更大的惊喜。
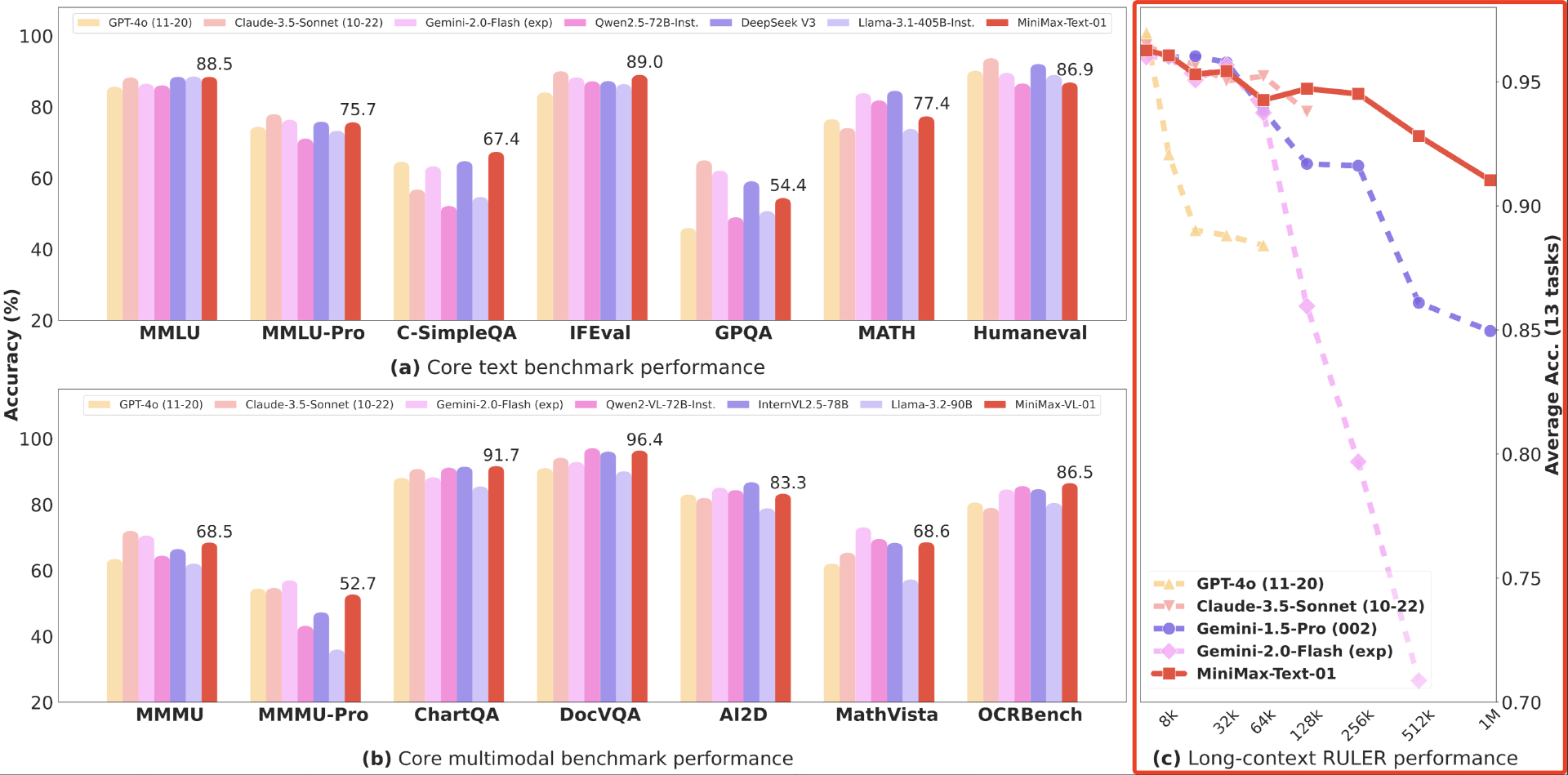
在长文任务的测试对比中,与包括长文最佳模型谷歌的 Gemini 在内的多款海外顶尖模型相比,随着上下文长度的增加,MiniMax-Text-01 的性能下降幅度最小。(详见上图右侧)
更“卷”的是,MiniMax-Text-01 支持最多 400 万个 token 的上下文输入。而谷歌的 Gemini 只提供处理 200 万 token 上下文的能力,其他大多数模型的上下文处理能力通常在十几万个 token 左右。这也意味着,MiniMax-Text-01 的上下文处理能力至少是大多数模型的 20 倍。
对于大模型而言,上下文是其理解及输出的关键。上下文越长,模型能够处理和理解的任务越长,同时,长上下文也能帮助模型解决复杂的多步骤问题(比如数学证明等复杂的推理任务),并提高生成内容的连贯性。此外,更长的上下文窗口也能减少信息丢失,提高生成信息的准确率。
这也是为什么 MiniMax 的 400 万 token 上下文窗口,让人十分惊喜——以 20 万 token 的上下文窗口可以一次性处理大约 35 万个汉字计算,400 万 token 上下文窗口可以处理 700 万个汉字。
700 万字是什么概念?7 部《哈利·波特》小说总字数是 108 万字, 700 万相当于 40 多部《哈利·波特》。
在追求卓越的性能的同时,大型模型的开发同样需要兼顾成本和资源消耗,这也是实现模型广泛应用和可持续发展的关键因素。
为了更好地平衡训练资源、推理资源和最终模型性能,MiniMax-Text-01 通过架构设计和优化,仅需 8 个 GPU 单卡、640GB 内存,便能在 FP8(8 位浮点数)精度下轻松处理长达 100 万个 token 的序列(将模型的总参数量限制在 5000 亿以内,确保在 8×80G 的配置下,使用 8 位量化技术时,能够对长达 100 万个 token 的序列进行单节点推理)。
而面对同样的推理任务,其他大模型可能需要配置 16 路 NVIDIA H100,显存 80GB。
这也使得 MiniMax-Text-01 在保持高性能的同时,实现了对资源的高效利用,大幅降低部署与运行的成本。
如果说这些只是 MiniMax 本次更新所呈现的开胃小菜,那么模型架构的革新无疑是这场盛宴中的主角 —— MiniMax 在模型中实现了新的线性注意力机制 Lightning Attention,这也是业内首次进行如此大规模的线性注意力模型开发。
要第一个吃螃蟹:Transformer Is Not Enough?
在架构层面,MiniMax 做出了一个大胆的创新:采用 MoE 方法,并尽可能使用新的线性注意力 Lightning Attention 代替标准 Transformer 中使用的传统 Softmax Attention。
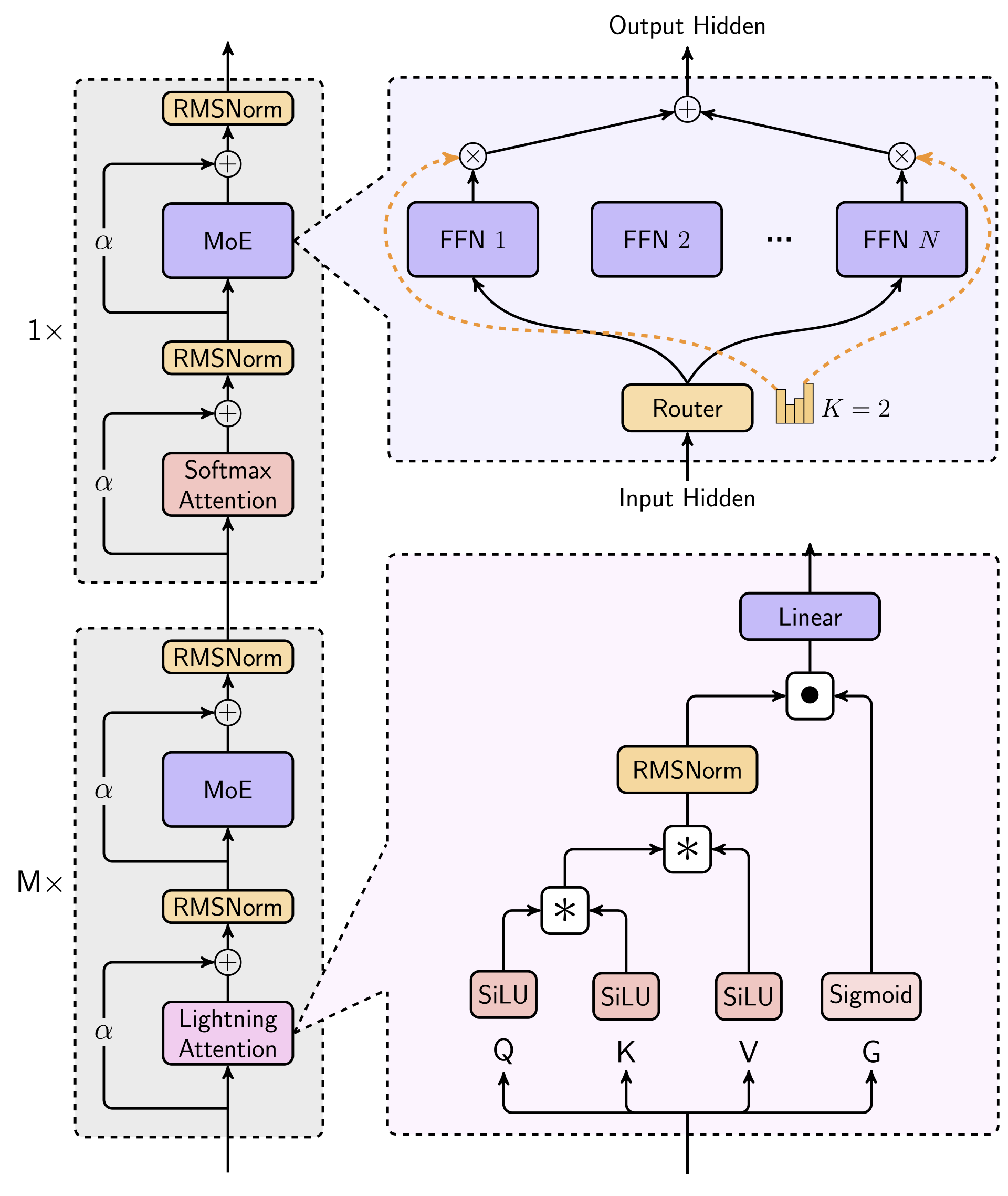
在注意力层设计上,MiniMax 在每 7 层 Lightning Attention 层后放置 1 层 Softmax Attention 层,总共 80 层。每个注意力模块由 64 个头组成,每个头的维度为 128。
这种设计巧妙地结合了两种注意力机制的优势,Lightning Attention 层可以减少计算复杂度,大大提高了模型处理长序列的能力,而 Softmax Attention 层则在关键节点上发挥作用,确保模型能够准确捕捉到重要的信息。两种注意力机制互相配合,使得 MiniMax 在处理长序列数据时,既保持了高效的计算速度,又确保了结果的准确性与可靠性。
这些创新,源于解决经典 Transformer 架构的固有问题——二次计算复杂性,即随着输入序列长度的增加,计算需求的增长速度远远超过硬件能力所能匹配的速度。
这也意味着,在基于 Transformer 的架构中,大模型的上下文窗口难以进一步扩展。
为此,研究人员曾提出各种方法来降低注意力机制的计算复杂性:稀疏注意力、长卷积、状态空间模型(Mamba 系列)以及线性 RNNs。尽管在理论上取得了突破,但这些创新在商业规模模型的实际应用中仍面临诸多挑战。
2019 年,Katharopoulos 等人提出线性注意力,随后,谷歌的 Performer、Facebook 的 Linformer 等进一步推动了线性注意力的发展。基于线性注意力机制,并通过引入局部敏感哈希(Locality Sensitive Hashing,LSH)算法,2023 年 7 月,OpenNLPLab 提出了新一代注意力机制 Lightning Attention,实现了对输入序列的高效编码和索引。在注意力计算过程中,能够将相似度高的序列进行分组,从而避免了传统注意力机制中对于每个序列都需要进行全局计算的问题。这种局部化的计算方式不仅降低了算力开销,还提高了建模精度。
此外,Lightning Attention 还具有无限序列长度的特点,它可以处理任意长度的输入序列,而不会受到传统注意力机制中固定长度限制的影响。这也意味着,Lightning Attention 在处理长文本等复杂数据时具备明显优势。
但在此之前,还未有任何一家大模型公司像 MiniMax 一样,进行过如此大规模的线性注意力模型开发。
背后的一个关键原因在于,当前的分布式训练和推理框架大多针对 Softmax Attention 进行了优化。而引入线性注意力机制,则意味着训练和推理系统需要重新设计。
为了将线性注意力机制扩展到商用模型级别,MiniMax 几乎对训练和推理系统进行了全面的重构。
一方面,MiniMax 使用专家并行(EP)和专家张量并行(ETP)实现了 MoE 中的 All-to-all 通讯,使框架能够支持训练和推理具有数千亿参数的模型,并且能够处理扩展至数百万 token 的上下文窗口,同时尽可能降低 GPU 间通信所带来的开销。
另一方面,为了促进上下文窗口的无限扩展,MiniMax 设计了变长环形注意力以减少计算中的冗余,并改进了线性注意力序列并行性(LASP)的版本,以充分利用设备的并行能力。此外,MiniMax 还为 Lightning Attention 推理实现了一套全面的 CUDA 内核,实现了在 Nvidia H20 上超过 75% 的模型浮点运算利用率(MFU)。
在架构设计和计算优化的基础上,MiniMax-Text-01 的预训练过程从策划一个多样化和高质量的语料库开始,这个过程包括了严格的数据清洗、基于奖励的质量提升以及更好的数据混合平衡,并通过系统的重复感知测试进行了验证。为了充分利用架构的长上下文处理能力,MiniMax 对超参数进行了深入的分析,并提出了一个三阶段的训练过程,成功地将上下文窗口扩展到了一百万个 token。在对齐阶段,MiniMax 通过精确调整的奖励维度和多阶段训练方法,特别是在处理长上下文和真实世界场景方面,有效地激励了模型的各种能力。
随后,MiniMax 通过整合一个轻量级的视觉 Transformer(ViT)模块,增强了语言模型的视觉能力,从而创建了视觉-语言模型 MiniMax-VL-01。
学术基准测试之外,为了进一步测试两个模型在实际用户体验中的表现,MiniMax 构建了一个基于真实数据的助手场景应用测试集,两个模型的表现依旧亮眼:
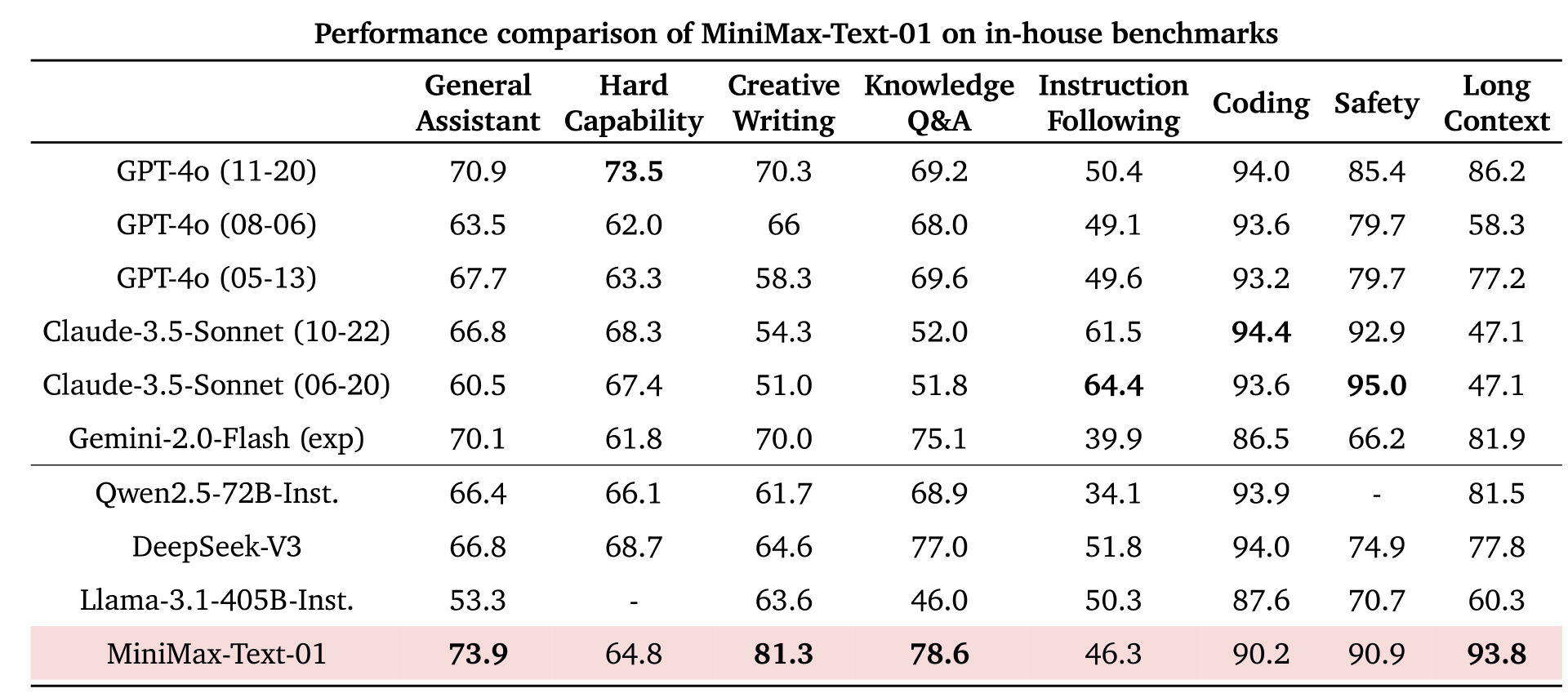
虽然 MiniMax-Text-01 和 MiniMax-VL-01 在绝大多数语言和视觉语言任务中表现出色,但在复杂编程任务方面,仍存在一定的局限性。
这主要是由于,预训练阶段编码的数据集数量并不多,MiniMax 未来会改进训练数据的选择,并完善继续训练程序,以提高下一个模型版本中的编程能力。
越来越卷的大模型上下文窗口,将加速 Agent 应用爆发
架构上的大胆创新让 MiniMax 成功跻身大模型性能第一梯队,也让其在长上下文处理能力上傲视群雄。
有心的人或许已经注意到,过去一年,大模型都不约而同地卷起了上下文窗口。
但围绕大模型上下文窗口的竞赛,并不是为了争夺“世界最长”,而是在追求更长上下文的同时,还能确保低延迟和高准确率,这对于模型在实际业务中的应用至关重要。更进一步而言,将长度与性能同时卷起来的上下文窗口,也能加速 Agent 应用落地——能同时处理更多的信息,也能提供更准确和连贯的输出。
在长文本的性能测评中,MiniMax 优势显著。
在 64k 输入级别的性能上,MiniMax-Text-01 与 GPT-4o、Claude-3.5-Sonnet 等顶尖模型对比不相上下,但从 128k 开始,MiniMax-Text-01 确立了明显优势,并且超越了所有基准模型。
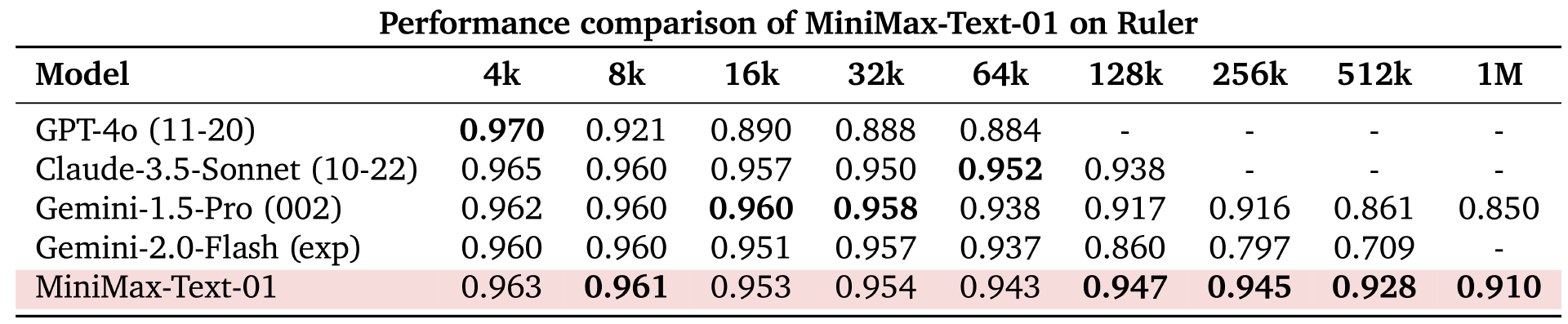
此外,MiniMax-Text-01 在 LongBench-V2 的长上下文推理任务中也表现出色,且无论是否有 CoT(Chain of Thought,思维链)推理的支持,MiniMax-Text-01 都能在处理长上下文理解任务时表现出的卓越的鲁棒性和稳定性。
这也归功于 MiniMax 半 RoPE(Rotary Positional Embedding,旋转位置嵌入)的混合架构以及为预训练和对齐精心调整的训练方案。这些创新的设计和训练策略增强了模型有效处理长序列的能力,使其能够在长上下文推理任务中保持高效和准确的性能。
在实际应用中,长上下文窗口能让大模型应对更复杂的任务。
比如,MiniMax-Text-01 可以从长上下文中学习一种“新”语言。

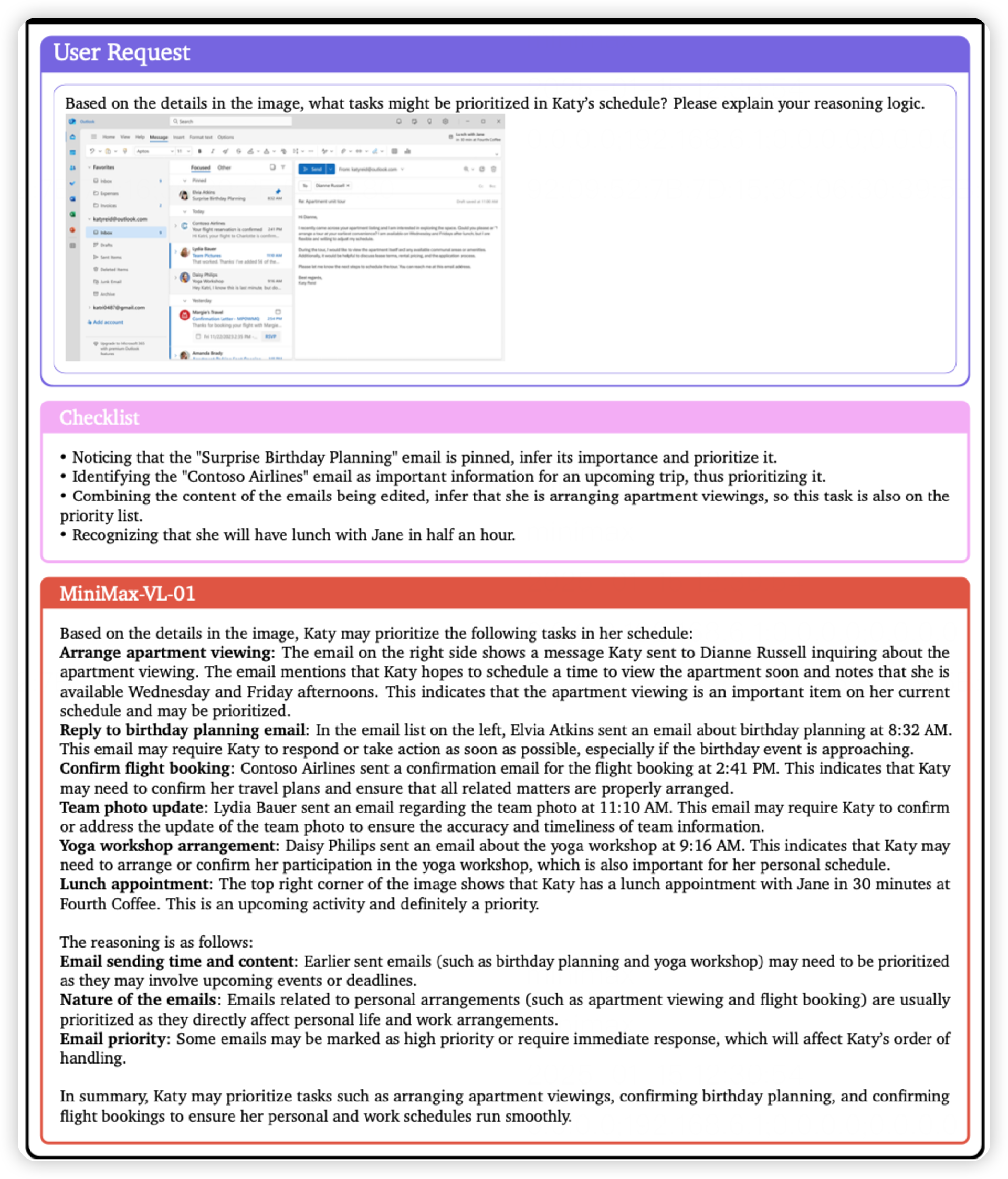
也可以在读完对话记录之后,提取信息安排日程表。
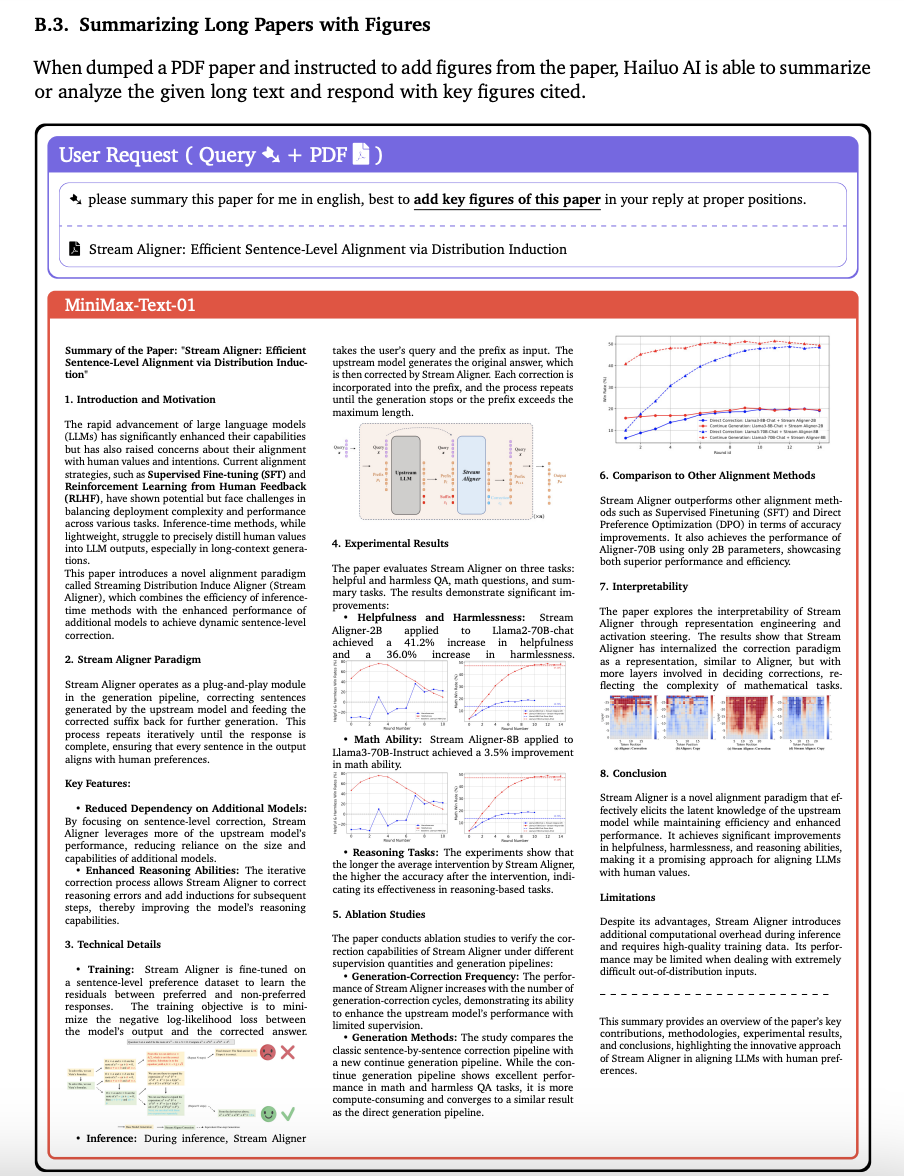
对于总结长篇论文这类任务更是不在话下。当用户上传一个 PDF 格式的长篇论文并指示添加论文中的图表时,MiniMax 基于自研的多模态大语言模型打造的 AI 伙伴“海螺 AI”能够总结或分析给定的长篇文本,并以引用的关键图表作为回应。
而这,也是智能客服、虚拟助手、内容创作、教育辅导等 Agent 所需要的。上下文窗口越长,Agent 越能充分理解用户的需求,处理用户的长对话历史,从而提供更加准确、个性化和连贯的服务。
这次开源,或许可以启发更多关于长上下文推理的研究,从而加速 Agent 时代的到来。
MiniMax 也计划在更现实的设置中增强长上下文检索,并在更广泛的任务中扩展长上下文推理的评估。而在计算效率方面,MiniMax 也希望将线性架构推向极致,希望能够完全弃用 Softmax Attention,实现无计算开销的无限上下文窗口。
在 MiniMax 身上有种务实的气质,他们所关注的性能指标都是为了实现大规模应用,而非追求表面的噱头。此次开源,公司也向全世界展现出了中国 AI 企业的创新精神和技术实力。从一年前采用 MoE 架构, 到此次实现业内首个大规模线性注意力架构,延续了其一贯的创新精神,从一定程度上甚至可以说是“意料之中”。
GitHub 链接:https://github.com/MiniMax-AI




