
斗鱼作为个人直播平台,长期以来除了普遍存在的灰黑产,虚假流量也是流量风控的重灾区。本文将介绍图算法在斗鱼反作弊中的业务实践,主要内容包括:
斗鱼流量风控业务场景
斗鱼图算法体系
图算法风控建模
模型实战
斗鱼流量风控场景介绍
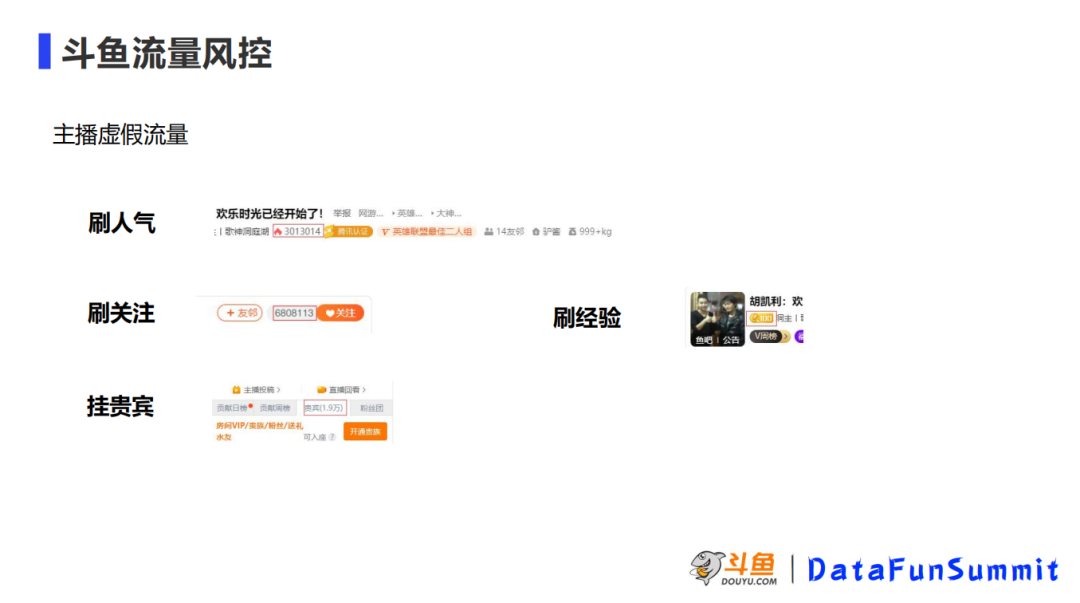
斗鱼的场景比较特殊,因为其风控业务面对的主体大部分是主播。对于主播,实际上会有一些虚假的流量,表面上看虚假流量可以提高主播的排面,实际上主播也可能会通过这些流量获得很多的利益。比如,在薪酬上或者榜单上都会有一定的体现。所以这一块的虚假流量是我们平台上相对的一个重灾区,这里列举了灰黑产刷的比较多的几块内容,一个就是主播的人气,一个是主播的关注,还有主播的经验,以及还有挂贵宾这几块。其他的斗鱼的场景,比如一些营销活动、拉新活动,实际上也是有相关的,这些则是所有平台上会共同面临的一些问题,这次分享主要就是怎样通过图算法去识别这种刷流量的黑产。
斗鱼图算法体系
这里从整体框架和算法演进的过程介绍斗鱼的图算法的体系。
1. 图算法整体架构
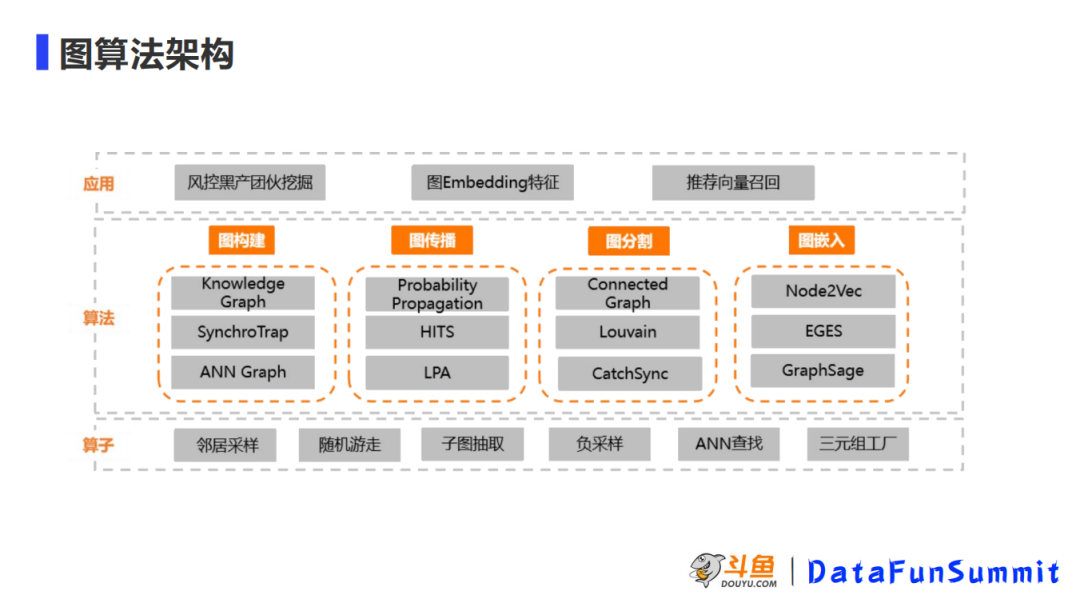
上图就是目前我们的图算法的整体架构。最底层是图的一些算子,这些算子包含图的最基本的一些操作,如邻居采样、随机游走和子图抽取等,我们在底层会做这些算子的开发和效率的优化,在有了这些算子之后,在算子上面就是一些标准的图算法,比如在图的构建这一块,现在有基于知识图谱的图的构建和基于行为同步性的图构建,还有通过 KNN 的方式去做临近图的构建。在图传播方面包括常用的标签传播算法,在图分割方面包括联通子图、高位子图和涉及发现的一些算法。在图嵌入方面主要是节点的插入,有基于拓扑结构的 Node2Vec、加入属性信息的 EGES、还有通过标签信息和随机性共同考虑去做的图剪辑的算法。现在图算法的应用在斗鱼场景主要就是风控这一块。风控这一块主要运用场景就是做黑产的团伙的挖掘。另外应用方向是会做一些图 Embedding,并将它的结果会作为特征去输入到下游的一些其他任务中。另外,在推荐场景下,我们也有一些图上推荐向量召回的应用。以上就是目前我们图算法的框架。
2. 斗鱼图算法的演进
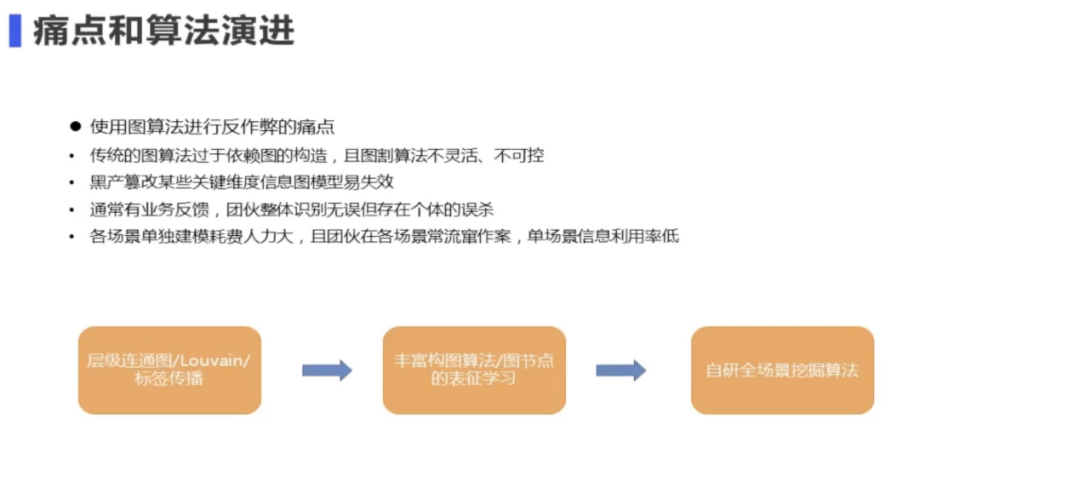
斗鱼图算法是从 2018 年开始做的,2018 年时实际上采用的是一些比较基础的图分割的算法。比如连通图、数据发现、标签传播等。这些算法在当时具有一定效果,但是在往后延伸之后,就发现这些传统的图算法存在一些问题,例如过于依赖图的构造,如果图没有建好或者图的信息被黑产篡改了,会严重影响算法的效果。第二个问题是在做图割的过程中这些算法比较简单。它们主要考虑的是节点与节点连接的紧密性,但实际上如果只根据这一点去做这图割,那么最终的结果是不可控的。常见的问题就是切出来的团伙,要么粒度过小,要么粒度过大,要么没法解释。所以在这个传统图算法做好之后,要去后置很多规则,这样的弊端就是我们会损失很多有问题的团伙,但只能抓住一些有明显问题的团伙。
基于以上问题,我们在 2019 年时一个方面去丰富构图方法,因为那之前的各种算法大多为直接的关联,如用户喜欢什么设备这种非常直接的关联,但丰富构图方法的主要目的是说去挖掘一些更隐性的关联。比如我们通过这种知识图谱的推理,从而去建立新的实体与实体之间的关联。或者采用一些相似度的方式去度量原本没有强关联的节点,然后我们给他一些虚拟的关联。所以通过丰富构图算法,可以建立更多的节点与节点之间的联系。相当于能纳入我们这个算法的节点会更多,另一点我们会去做一些图的表征学习。那么做图的表征学习其优势就在于相当于它的信息会更好的融合,而且我们能更方便的融入一些如节点的属性信息等,因此,我们不用只去依靠这个边的一些强度的信息。这样可以提高识别的覆盖率,但即便如此,我们还是绕不开图的构造的问题,即使用这种相似度的方式去构造一个图,但其业务含义并不强。另外如果采取这种表征学习,实际上在后续划分出的团伙后还是会面临可行性的问题。另外在这个阶段也会出现其他的问题,比如业务方反馈得到团伙整体没问题,但是会发现其中有少量个体和这个团体整体的特征有一些出入,而且这些个体可能是充值或者等级比较高的,那基本就是一个误杀,所以基于上面这几点,我们在 2020 年时候就去做了全场景团伙挖掘的算法。这个算法相当于我们把整个场景都串联起来了,而非单场景的,因为团伙的作案可能是多场景的一个流窜作案,那么单场景使用的信息必然就是一个单场景的信息使用。这样可以提高信息的整体使用效率。并且通过一些手段能够比较好地去避免一些明显的误杀,并且能够提供非常准确的可解释性。
所以后面在讲实践应用的时候,会具体讲自研的全场景挖掘算法,它具体是怎么做的。
图算法风控建模
1. 采用图算法做流量反作弊的优势
用图去做流量反作弊优势有这样几点,一方面如前面我们所说的斗鱼场景中有很多主播刷量的场景,这种就很可能是一个黑产团伙的行为,他需要在规定的时间内去完成这样一个任务。所以无论这个黑产如何去规避他的一些行为,这种聚集性和关键性是很难去逃脱的,除非他刷单的效率很低。此外只要是在规定时间内需要达到一定目标的话,他必然是一个频繁聚集的。关键性的操作就会很多,表现在图上就可以完美的去描述这样的一个特征,所以图跟黑产作案的特征是非常契合的。另外除了特征,图算法对新的攻击的抗性会比较高。因为图的特征它并不像统计的特征那么少,可能很快就会被黑产摸清楚是什么的指标或者阈值,图的拓扑结构就让人很难去发觉就是个究竟是哪一块操作被识别到了。所以用图来做流量反作弊的话是有很强的鲁棒性的。第三个方面就是图可以对关系数据做一些描述。关系数据不同于我们平常的一些统计数据,它实际上是有一些统计特征在里面的。除了图算法之外其他模型对关系数据的利用和处理都相对复杂一些。所以基于这三点,我们会选择图算法,作为流量反作弊的运用。
2. 图算法风控建模流程
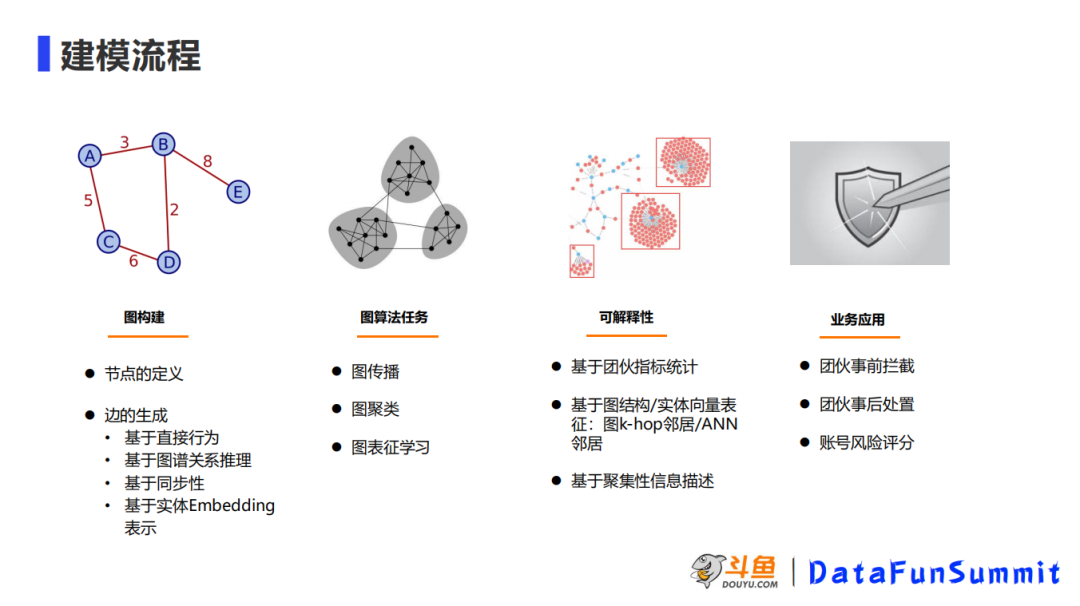
一般的图算法在风控场景的建模的流程可以分成四大块。
① 图构建
图构建有两个关键点,一个是定义节点。节点一定是我们需要挖掘的一些实体。最简单就是账号或者设备,当然在演进过程中也可以去加入一些虚拟的节点。也可以加一些和实体相关或者辅助识别的实体作为节点。边的生成也就是构图阶段,我们最初的生成方法是采取一些直接的行为,之后我们做了一些构图上的优化,所以边的生成方式有很多种。比如通过图谱关系的推理,实际上是基于现有的联系做推理,第二种是基于同步性,如果我们发现这两个实体在行为上具有非常强的一个时间上的同步性,那么我们也会认为这两个实体之间有一个边的关联。最后一种是基于实体 Embedding 表示,先对实体做 Embedding 表示,然后通过 ANN 的近似邻居的搜索把向量接近的节点去生成边。
图的构建方式是非常多样的,图的算法做异常挖掘在这一步实际上是最为重要的。定义好一个图就非常具有业务含义,然后也能跟黑产的作案方式相契合。那么后面的算法才会有一定的效果,否则后面做的再花哨也是没有用的。
② 图算法任务
图算法实际上要基于具体业务场景,做不同的图算法,第一种是做图的有监督学习,第二种是做图的无监督学习,这种在业务中更为可控的,因为作图的无监督学习,第一它不需要任何的标签的信息。第二它的可解释性比有监督学习的更好。所以图的无监督学习在我们场景中一般会去用于黑产团伙的发现。第三个是图表征学习,就是节点的 Embedding 向量,可以作为一个图的特征输入到账号的风险评估模型中去。
③ 可解释性
可解释性在风控领域非常重要,无论是误杀的排查,还是将模型交付给这个业务方的可信度。这里常见的有三种做法,第一种是去统计挖掘的团伙的一些统计指标,如白用户的占比、平均等级等。第二种是通过图结构/实体向量表征去做衍生特征例如在排查某个账号实体可以通过他的 k 阶的邻居节点,通过 k 阶邻居节点的信息去做统计,然后衍生节点的统计指标作为检验它的一个指标,这样就可以反映待排查的节点跟其他节点的关系。第三种是一个通过聚集性信息去描述,通过图做无监督的学习最后的落脚点还是在聚集性上,所以如果我们把聚集性这个信息详细的描述出来,那实际上无论懂不懂这个模型,都能一眼看出这个团伙是不是有问题?所以其实这个信息对可解释性来讲的话是非常重要的。比如这个团伙中有百分之多少的成员具有某一类相同的特征,或者是这一个团伙中有百分之多少的账号,他在某个时间段内有相同的行为,这种类似的行为描述。
④ 业务应用
业务应用现在团伙图这一块的团伙的应用主要有三大块。第一是团伙的事前拦截,在团伙有少量账号作案时根据识别的情况将团伙其他的账号做一个事前的拦截。第二块是团伙作案后的处置,第三块是做风险评分,图表征的 Embedding 向量会作为关系特征输入到风险评分中。
模型实战
1. 实战案例一:序列 x 图的团伙识别
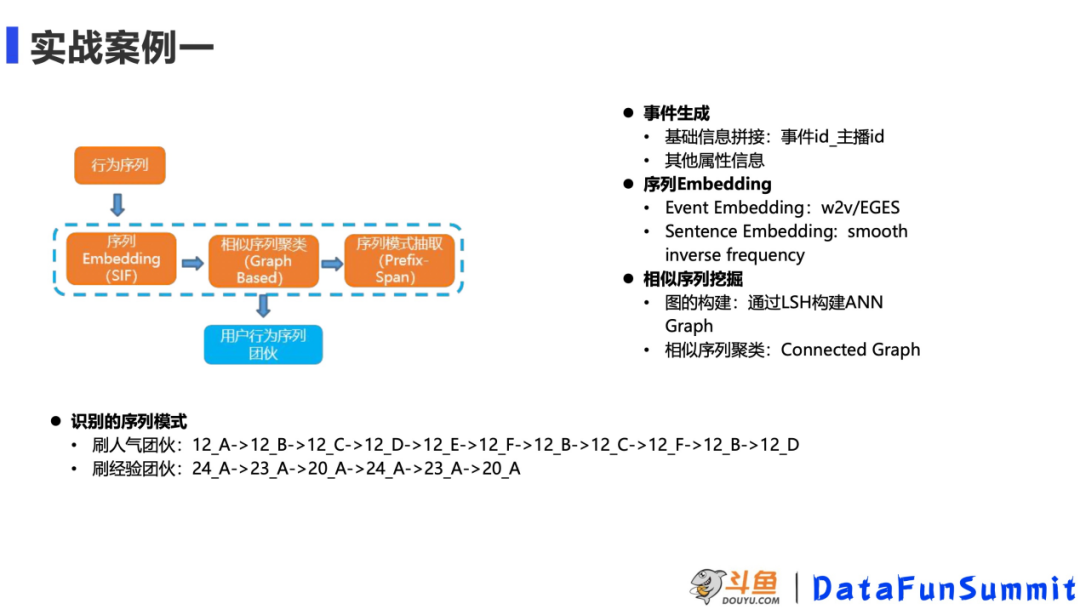
这个案例中将序列和图这两块做了联合的建模,去挖掘序列上有风险的团伙。生成系列的方式是事件基础信息的拼接,把这个事件的 id 和主播的 id 做一个拼接,作为序列的一个节点。然后把每个用户按这样的方式,根据时间戳做一个串联,在这生成了一个事件的行为序列。第二步是在这个基础上,做各个事件的 embedding,这里有两种方式,第一种 w2v,只考虑事件的前后信息,在不引入其他的信息。第二种是 EGES,可以添加一些别的属性信息,对于序列整体的 embedding,我们采用了 SIF 的方式,这种方法有两个优势,一个是调换序列中两个节点的顺序,结果不变,第二个是这种方法考虑了主成分分解的思想。在得到序列的向量表征之后我们将整个系列作为一个节点用 ANN 的方式做图的构建,最后通过连通子图的方式做相似系列的挖掘,挖掘好之后采取序列模式频繁拆取的方法最终可以将频繁的系列模式识别出来,以上图为例,我们识别出的刷人气的团伙在多个直播间来回观看,上图刷经验的团伙在同一个直播间内用了不同的方式来给主播刷经验。最终可以清楚的看到这些团伙是如何作案的。
2. 实战案例二:全场景刷量团伙挖掘
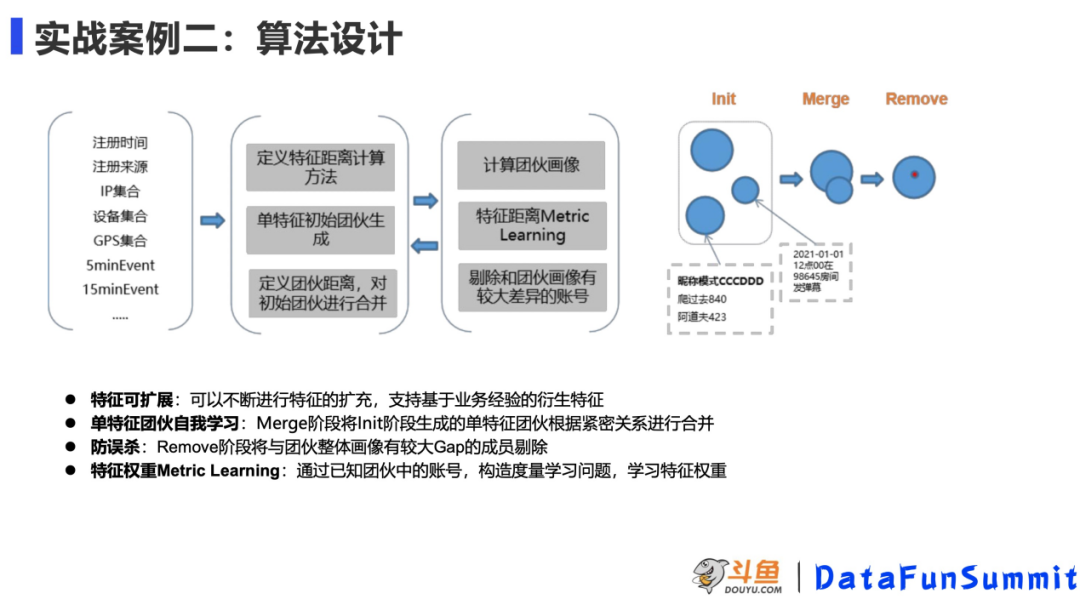
第二个例子是前面提到一个全场景团伙发现的模型,这个模型首先是会确定特征,第二步会先定义特征距离的计算方式,针对每一类特征给出一个距离计算的方式,之后我们会根据每个特征的不同取值的去生成单特征的初始团伙,这里的思想是把每个单特征生成的这个整体看成一个节点。然后我们会定义团伙的距离,把相近的团伙做一个合并生成一个新的团伙,之后,我们会去计算这个团伙的画像,团伙的画像是指团伙中一些指标的占比。比如一个注册来源,账号占比是 0.9,这个占比可以作为一个权重参与之后的计算,之后我们采取了 metric learning 的方式去度量特征的权重。然后我们会剔除与团伙发现差异比较大的账号。
小结一下,这个算法有四点比较重要,第一点是特征可扩展,可以不断的去生成一些新的特征。无论在业务上有什么样的经验,我们都可以迅速的把经验给加到模型里面去。第二点是单特征团伙可以做自我的学习,如之前所说的图算法应用在风控的一个难点就是构图比较难,这种方式避免了我们去强构图。通过自我学习,是在做一个自己学习的构图。第三点是防误杀,团伙中的一些成员跟团伙整体有一定的差异,整体是没有问题的,但是个别是有问题的。那这个时候我们通过这种防误杀的方式从团体中剔除从而解决这个问题。第四点是做了特征权重的 metric learning,这里我们用了度量学习的方式,我们会有会有一些已知的样本账号生成一个样本堆,如果在同样一个团伙中,那么这个样本堆相当于是一个正样本,如果是在不同的或者是我们做通过负采样生成的样本堆,那就是一个负样本,实际上如果这个权重学的好的话,那正样本的相似度会比较高。负样本堆的相似度会比较低,针对这个我们会去生成一个最优化问题,通过这个最优化问题去手写特征的权重。
总结
综上,我们将所有场景的信息纳入到一个模型中,不需要再针对单个场景去做建模。自我学习和防误杀的两个机制,保证了生成团伙的准确性,并且因为我们生成的团伙来源于基础特征,所以通过团伙的特征取值可以迅速的生成团伙的可解释性,最终相当于我们把从传统的图算法演化成了现在的形式,目前的形式在我们的业务中取得了非常显著的效果。
本文转载自:DataFunTalk(ID:dataFunTalk)
原文链接:图算法在斗鱼反作弊中的实践




