
几年前,行业内关于是否可以把数据库跑在 Kubernetes 上就不乏讨论。Google Cloud 解决方案架构师本杰明·古德(Benjamin Good)曾发文讨论了这件事情的可行性:想要讨论这个问题,开发者们需要先明确需要通过把数据库 Kubernetes 上解决什么问题,再来看下可行性。如今,业内不乏有将数据库跑在 Kubernetes 上的产品出现,火山引擎数据库系列产品也是其中之一。我们可以从火山引擎数据库产品出发,了解云时代大规模场景下数据库跑在 Kubernetes 之上有何不同。
为什么选择在 Kubernetes 之上跑数据库?
火山引擎存储 & 数据库产品解决方案架构师魏巍告诉 InfoQ,业内不少存算分离的数据库采用的是基于物理机或者虚拟机的方式进行部署,不管是 CPU、内存还是存储的调度方式都偏传统,而字节跳动的 veDB 完全基于 Kubernetes 进行部署。目前我们可以看到也有一些企业把数据库部署在 Kubernetes 上,只是更多是放在容器里了。
业内对于云原生数据库的理解有共同之处:面向应用,不再关注底层需要多少 CPU、内存等等,而是更关注应用的状态,比如是否高可用。这些就可以通过 Kubernetes 自带的 Operator 来实现。在魏巍看来,部署在 Kubernetes 上的数据库,比部署在虚拟机或者物理机上的数据库,云原生的程度更高一些。“我们完全是基于 Kubernetes 做了深度整合的数据库系统。”
魏巍提到的火山引擎跑在 Kubernetes 上的数据库产品,主要面向 OLTP 场景,包括关系型数据库 RDS、云原生数据库 veDB MySQL、缓存数据库 Redis、文档数据库 MongoDB、表格数据库 HBase 和图数据库 veGraph。
据他介绍,火山引擎数据库团队并不是从一开始就想要自研在 Kubernetes 上跑数据库的。内部在进行整体的数据库产品开发的时候秉承着这样的思路:最开始是效率优先,使用开源的产品来满足业务需求,后来发现因为字节跳动内部数据规模越来越大,尤其像 2021 年春晚红包雨活动时,使用开源的数据库产品无法满足业务需求,才开始在开源产品的基础上进行迭代和优化。可是新的问题又来了。由于开源产品的架构设计有自己的规则,有一部分的性能就无法进行优化。所以火山引擎数据库团队开始寻找其他的办法——从架构层面对数据库进行改造,比如云原生数据库 veDB MySQL,改造成计算、存储分离的架构,让整体的性能更高,峰值集群达到百万级别的 QPS。
2015 年到 2017 年间,火山引擎数据库处在相对初级的阶段,仅依赖人工和脚本的方式进行数据库管理运维,就足以满足业务量的需求;2018 年到 2021 年,火山引擎开始改造云原生数据库 veDB MySQL、缓存数据库 Redis 等。从今年年初开始,火山引擎开始在内部大规模推广自研的 veDB,融入了很多像 AI for DB 之类的技术,把之前 DBA 沉淀下来的经验,通过 AI 的方式,让系统自动优化和调整数据库系统。
火山引擎数据库团队在进行数据库技术产品优化时主要考虑两个关键点:其一是尽可能地提高资源利用率,实现降低成本的目的;其二是尽可能减少对客户在线业务产生影响。在魏巍看来,基于 Kubernetes 实现云原生化可以更细粒度的对资源进行管理,减少资源碎片,进而提高整体资源利用率,达到降低成本目的。同时,计算资源与存储资源可以借助 Kubernets 进行统一调度,可以更充分的释放云计算弹性的能力。火山引擎数据库团队也在向 serverless 方向发展,以上能力都是面向 serverless 的重要基础。
“数据库本身的体系类似,所以大家做的优化也是类似的。像我们的 veDB 也做了 log is database 分离,把一些 mysql 的内核进行非常大的改造,让它写数据的时候只写日志,而不会去刷新数据,这样就极大程度减少了网络开销,进而提升了整体的性能。”魏巍表示:“veDB 和原生的 Mysql 相比,基本上是原生 Mysql5-6 倍的性能。”云时代,业务大规模要求下数据库性能的大幅度提升,是火山引擎坚定了让数据库跑在 Kubernetes 上的信心。此外,阿里云、亚马逊云科技做数据库产品比较早,当时底层的技术依赖虚拟机和虚拟化,而火山引擎云数据库做得晚,赶上了 Kubernetes 发展的好时候。
跑在 Kubernetes 之上的数据库有何不同?
不过从技术角度看,其实 Kubernetes 整体来看对于数据库并不友好。根据 Google Cloud 解决方案架构师本杰明·古德的“数据库应该跑在什么环境中”思维导图,首先,跑在 Kubernetes 之上的数据库,相比跑在物理机、虚拟机环境的数据库更容易出现故障自动转移事件;其次,持续产生高工作负载的场景,无法控制并发量,对于跑在 Kubernetes 上的数据库也不友好,会导致数据库不受控。
Operator 的出现让数据库真正在 Kubernetes 上变得好用。云厂商可以通过扩展 Kubernetes API,使用 Operator 来实现数据库的运维能力和管理能力。对于非 Kubernetes 友好的数据库如 Mysql,就可以借助 Operator 来实现故障自动转移等;对于高工作负载高并发量的场景,数据库没有银弹,可以选择不同的数据库产品组合。
数据库跑在 Kubernetes 之上的好处也开始被看见,比如数据库实例资源的增加变得更简单、跨多云部署的兼容性更好、运维的复杂性更低……从架构视角看,魏巍认为部署在 Kubernetes 之上的数据库资源调度的粒度将更小。以前用虚拟机,至少需要一台虚拟机做调度,但是 Kubernetes 上以 Pods 为单位去做资源调度,由 Kubernetes 进行资源分配,提升了整体的资源利用率,也就降低了成本。“开一个虚拟机的时间和开一个 pod 的时间相比,肯定是 pod 的时间更短。这也是我们说火山引擎云数据库具备非常强弹性能力的重要原因之一。”魏巍谈道。
随着应用场景更加宽泛,Kubernetes 也会受限。对此,火山引擎专门配备了一个团队负责进行 Kubernetes 的优化和改造,让它能更好地满足大规模应用场景。同时,该团队还会负责云数据库和 Kubernetes 更充分的融合。“业内还没有哪个厂商这么大规模地把云数据库部署在 Kubernetes 上,火山引擎是第一家。”
目前,火山引擎数据库产品系统分为自研 veDB 和社区版优化两大类,还提供了一些生态工具 DTS。除了前文提到的云原生数据库 veDB MySQL,火山引擎缓存数据库 Redis 也与社区版 Redis 有很大不同。
社区版 Redis 采用无中心化的架构,底层节点之间使用的是 gossip 协议。这个协议导致一旦节点数过多时,会产生严重的网络风暴,导致整个集群的不稳定,并且也无法提升整体的容量规模。所以,火山引擎缓存数据库 Redis 采用字节跳动内部实践的 Achemy 架构,对社区版 Redis 的整体架构做了改造。
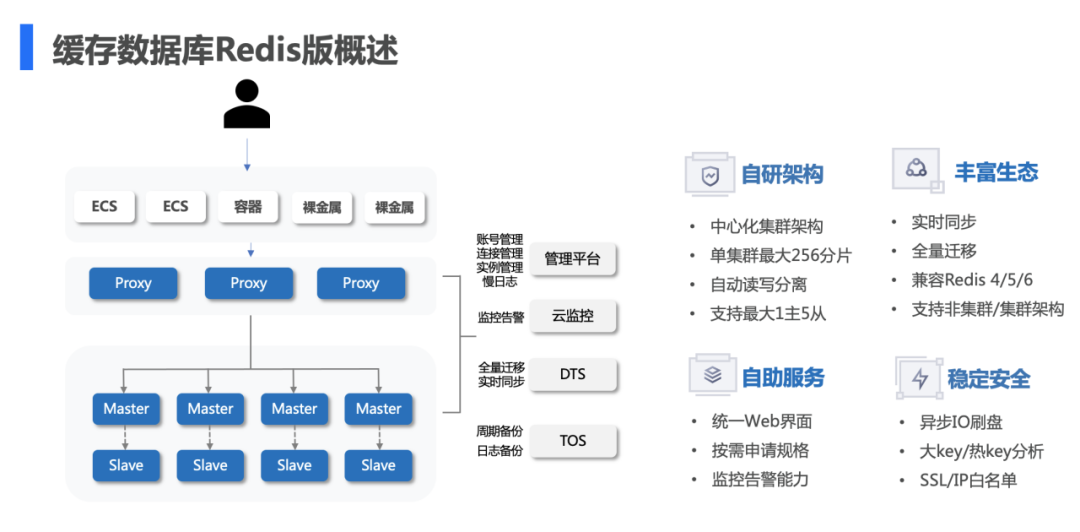
改造主要体现在 2 个方面。
其一,把社区版 Redis 的架构从无中心化转变为中心化。通过引入集群组件 config server,对整个 Redis 集群做元数据的管控,这样就可以避免 gossip 协议通信引起的网络风暴。
其二,Achemy 架构分为三层,第一层是 proxy,第二层是 config server 进行元数据管理,第三层是 server 层用于真正存储数据。这三层架构让字节跳动的 Redis 可以支持上千的节点分片,让 Redis 的集群规模变得非常大。
“其实最开始字节跳动也是在用开源的版本,也没有想直接从架构角度推倒重来,只是对于规则协议进行优化来提高节点数量,但是做下来发现投入产出比低,面对不断上涨的业务量也不是长久之计,毕竟社区开源版的 Redis 可能没有预估到如今如此大规模的场景。”魏巍谈道,过去大家专注在数据库本身的优化工作,现在上云之后,其实可以借助云的能力优化数据库的架构,让数据库的性能和稳定性整体从云的维度得到一个比较大的提升。
火山引擎图数据库 veGraph 是火山引擎自研的产品,类似 Achemy 架构,以属性图为基础结构数据,提供了海量关系的数据存储和毫秒级的在线查询服务,广泛应用于社交网络、欺诈检测、推荐引擎、知识图谱等场景。“比如抖音和头条里,你给哪个文章或者视频点赞,你的好友也能看到这条文章或者视频,其实就是借助了图数据库的这种关系分析能力。也是因为业务量大,所以开源的图数据库满足不了抖音头条这种大规模海量数据的要求。”
魏巍表示:“我们自研的图数据库 veGraph 可以做到万亿条边。如果两个人是好友关系,这一条好友关系就被称作是一条边。不仅规模可以达到万亿条边,单集群已经可以达到亿级别的 QPS 性能水平。”这里底层的技术支撑和 Redis 类似,通过分层拆开不同的组件,分别对每个组件进行集群化处理,三层集群共同对外提供服务能力,所以可以达到万亿条边的数据量,整体 QPS 达到亿级别。
云数据库的未来方向
“云厂商提供的云数据库应该做到简单易用,安全稳定,极致弹性,高性价比。把客户 DBA 需要做的事情都做了,而且要做的更多,做的更好。”在魏巍看来,DBA 应该有更高的价值,应该和业务开发走得再近一些,才能让业务和数据库更好地结合。“开发如何建索引这个事情很多企业的 DBA 都会遇到。一旦出现问题,大家会发现开发同学索引建得不好,SQL 语句写得不好。其实,可以让 DBA 同学提前介入到开发工作中,这些事情完全可以避免,让 SQL 语句更加高效,进而让业务可以用更少地资源去做更多的事情。”魏巍解释道。
业务视角下,云数据库未来的重点方向在于能否稳定支撑企业业务运转的同时降低使用成本,所以从技术角度看,无论是哪一家云厂商,未来都会在底层技术上做更多的优化,并在上层打造一个更加稳定的平台来供企业客户长久、安心地使用数据库产品。




