
Katalyst 是字节跳动开源的成本优化实践系统,致力于解决云原生场景下的资源不合理利用问题,为资源管理和成本优化提供解决方案。
来源 | KubeWharf 社区
项目 | github.com/kubewharf/katalyst-core
近日,Katalyst 社区完成了 0.4.0 版本发布。除了持续优化 QoS 能力之外,我们还在新版本中提供了可以独立在原生 Kubernetes 上使用的潮汐混部和资源超售能力。
和在离线常态混部一样,这些能力是字节跳动在不同业务场景中实现降本增效的技术手段,我们在抽象出标准化能力之后也进行了开源,期望这些能力可以帮助用户以更低的落地成本完成资源效能提升。
潮汐混部
背景
通过给应用分配差异化的 QoS 等级,Katalyst 可以基于资源隔离和动态调控能力实现在单机维度的在离线业务混部,即常态混部。这种混部模式虽然可以实现极致的资源效能提升,但是也增加了基础设施的复杂度。同时因为引入了例如 Reclaimed 资源这样的概念,要落地常态混部往往还需要做一些业务侧的适配。
为了让用户可以以更低的成本落地混部能力,在 v0.4.0 中,Katalyst 提供了潮汐混部(Tidal Colocation)功能。
技术解读
在潮汐混部中引入了潮汐节点池的概念,并且将集群中的节点划分为“在线”和“离线”两种类型。潮汐混部主要分为两个部分:
实例数管理:通过 HPA、CronHPA 等各种横向扩缩能力来管理在线业务的实例数,在夜间可以腾出资源给离线业务使用
潮汐节点池管理:Tidal Controller 基于设定好的策略对潮汐节点池中的节点做 binpacking,将腾出的资源折合成整机出让给离线业务
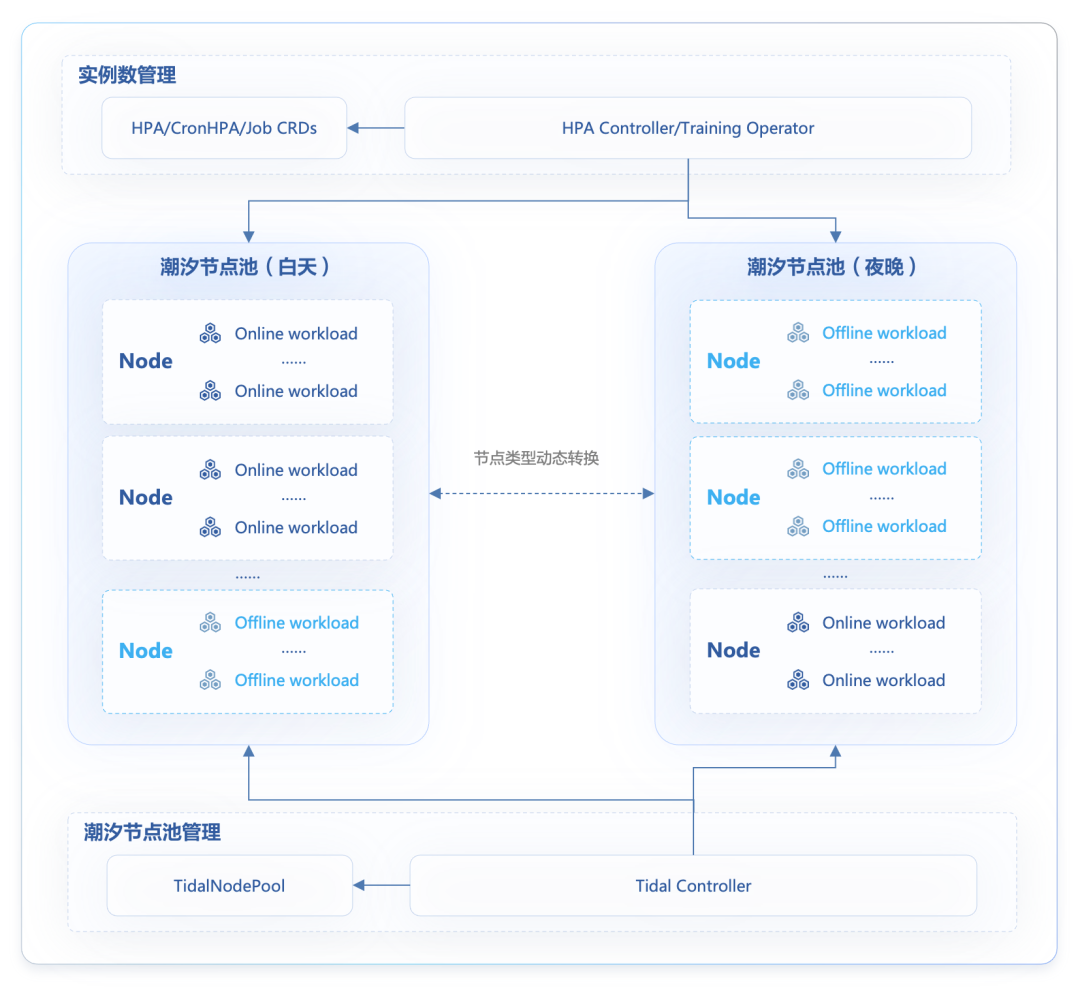
使用
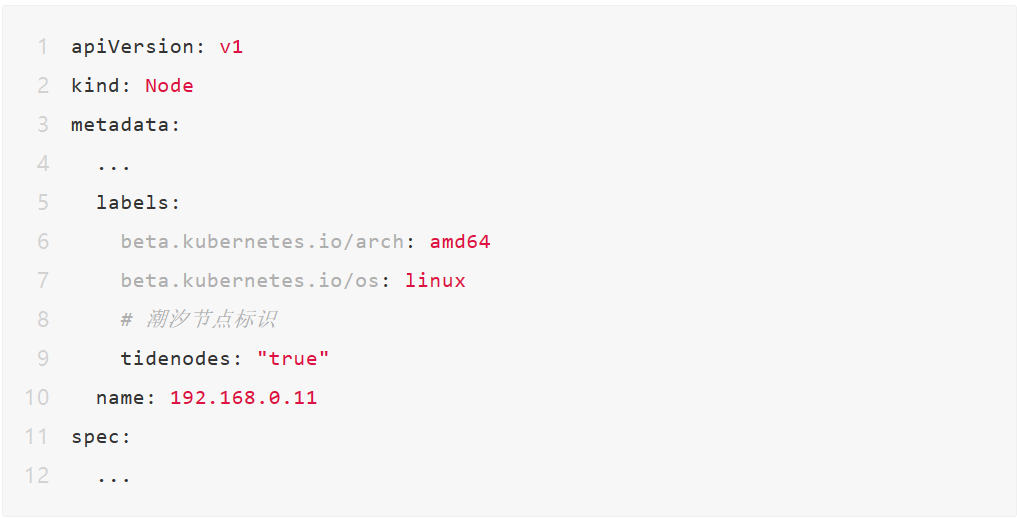
在集群中选取加入潮汐节点池的节点,并为节点打上某个 Label
2. 创建潮汐节点池配置

3. 潮汐控制器为节点打上对应的标签和污点,并且会根据各个节点的负载情况动态做 Binpacking 调整节点角色

部署在线离线业务,为应用打上相应标签和污点容忍,并配置 HPA 规则

在线超分
背景
在线业务的资源使用量往往会随着访问数量的波动而变化,具备明显的潮汐特性。为了确保业务的稳定性,用户通常会以峰值时消耗的资源量作为申请的依据,而且往往会有过度申请资源的倾向,这些资源会被浪费。
Katalyst 提供了在离线混部的能力作为解决上述问题的方式之一,但是在一些场景下,在离线混部可能不便于落地,比如:
负载类型比较单一,只有在线业务
业务方不愿意改变申请资源的协议来申请 Reclaimed 资源
在新版本中,Katalyst 针对在线业务场景,提供了一种简单的、对业务方无感的资源超分方案,便于用户快速提升资源利用率。
技术解读
Over-commit Webhook:劫持 kubelet 上报心跳的请求,并对 Allocatable 资源量进行放大
Over-commit Controller:超分配置管理
Katalyst Agent:通过干扰检测和驱逐,保障超分后节点的性能和稳定性;根据指标数据,计算并上报动态的超分比
Katalyst Scheduler:对需要绑核的 Pod 进行准入,避免超分导致实际无法绑核而启动失败
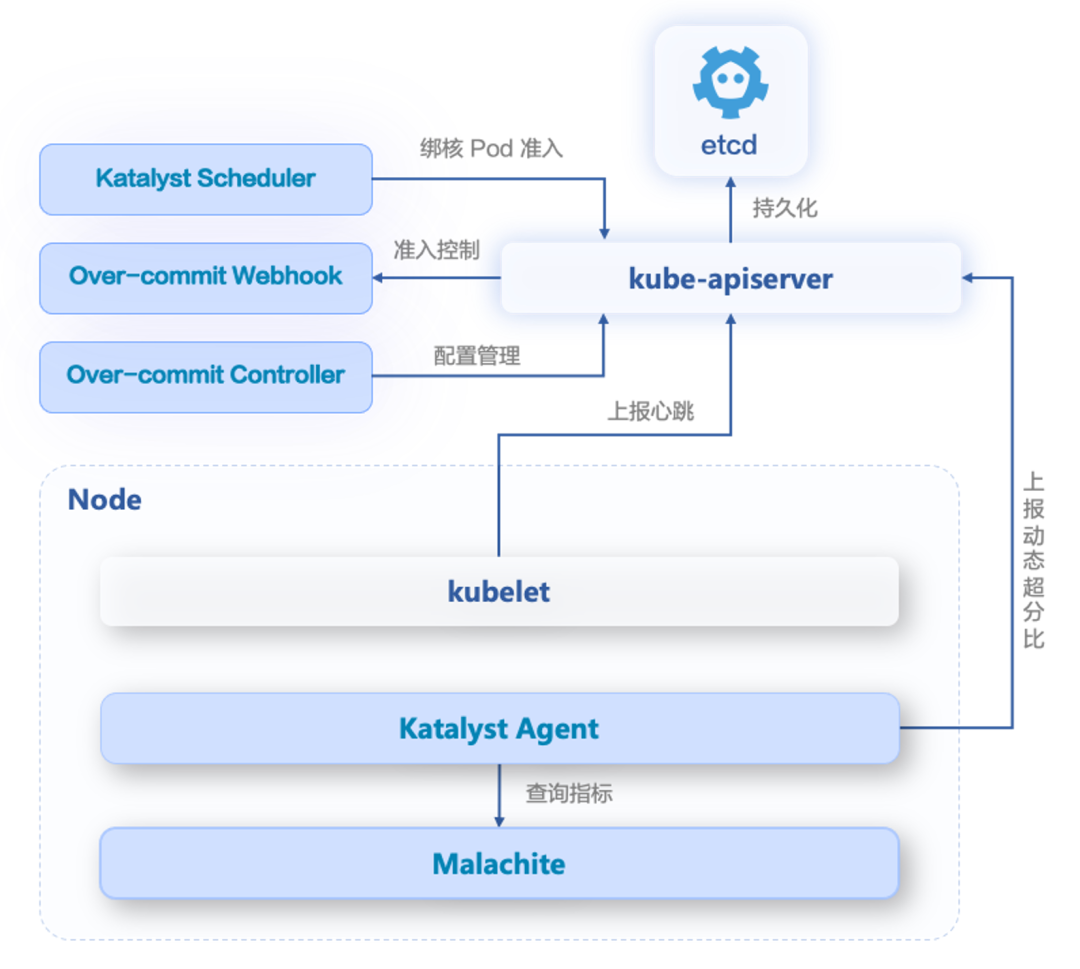
使用
为需要超分的节点池的节点打上 Label
2. 创建超分规则
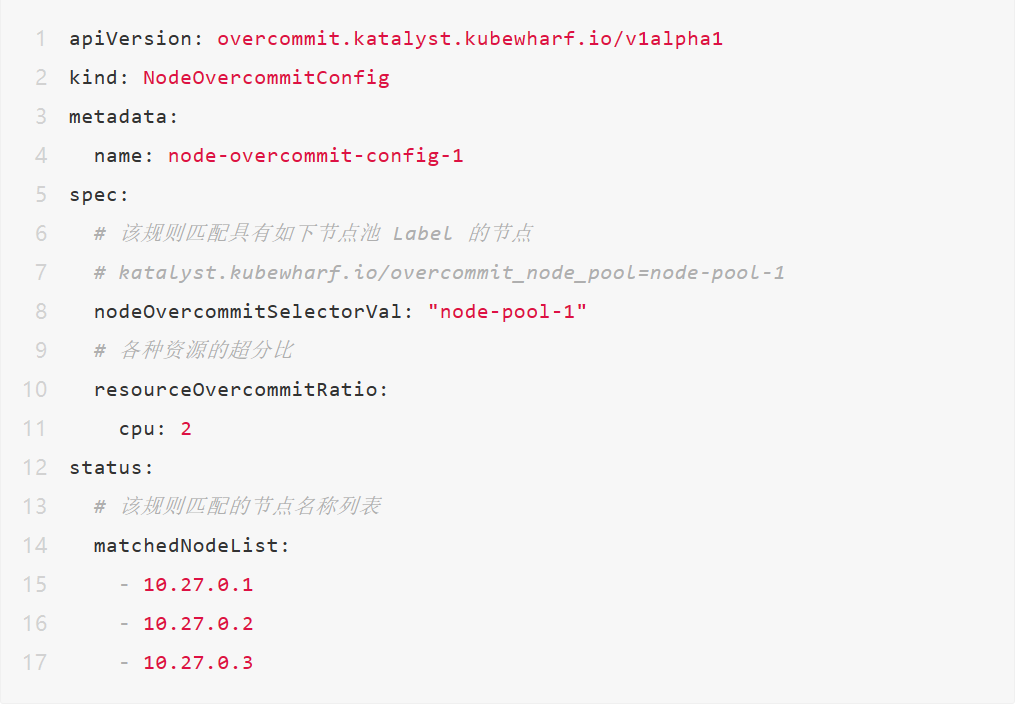
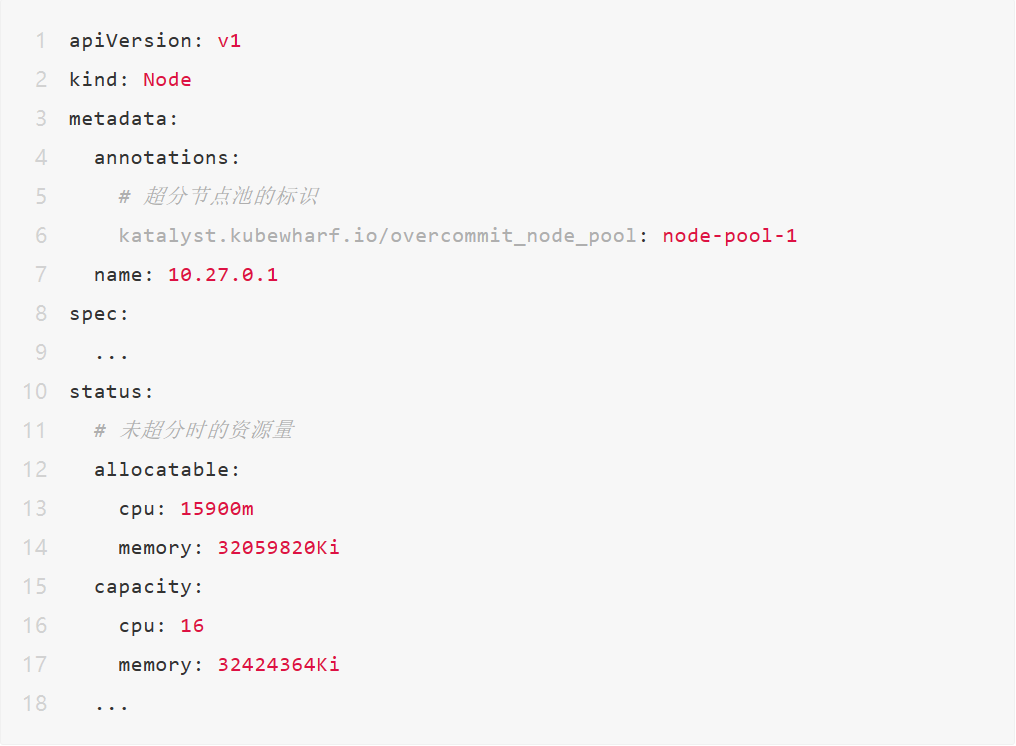
3. 观察 Node 对象,发现 Katalyst 将超分比、未超分时的资源量更新到 Annotation 中,并根据超分比对 Allocatable 和 Capacity 进行了放大

NUMA 粒度混部内存管控框架
背景
Katalyst 当前的混部策略只考虑整体机器的可用资源,导致离线任务在 NUMA 跨度申请内存时,内存容量和带宽在各 NUMA 间分布不均匀。这种情况下,当前的混部策略往往无法精确控制内存使用量,进而引起内存压力。
针对这种情况,我们提出了一种精细化的 NUMA 粒度内存管控框架,旨在通过 sysadvisor 计算 memory provisions,并与 qrm memory plugin 交互,实现更细致的 NUMA 内存管理。这将使 qrm memory plugin 能够根据 memory provisions 进行 NUMA 细粒度内存控制。
技术解读
在 Sysadvisor 的 Memory Plugin 中,我们引入了名为 memoryProvisioner 的插件,负责计算每个 NUMA 的内存供应逻辑。
为增强其可扩展性,我们设计了 ProvisionPolicy 接口,包含 Update 和 GetProvision 两个方法,分别用于定期更新内存供应量和获取 provision 建议。MemoryProvisioner 插件实现了 MemoryAdvisorPlugin 接口。
此策略基于 Memory Headroom 的 PolicyNUMAAware 策略,通过遍历每个物理 NUMA 及其 pod,计算每个 NUMA 的内存供应量。具体计算逻辑包括分析 NUMA Exclusive 设置,获取每个 NUMA 节点的空闲内存,并应用公式考虑 reclaimed cores、系统 scale_factor 和 reserved 内存,以实现更均衡的 NUMA 内存分配。
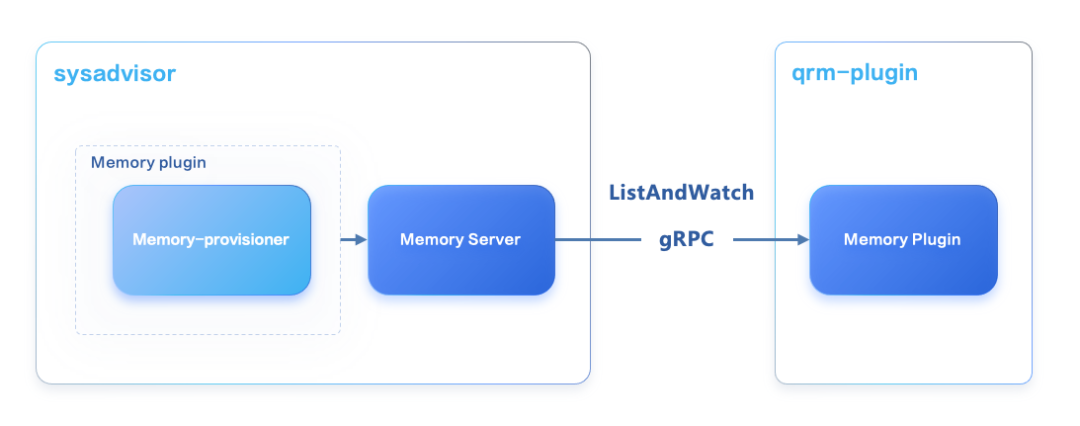
使用
katalyst-agent 添加了 memory-provision-policy 的启动参数,用于指定计算策略,默认是 canonical。用法如下:

支持 OOM 优先级作为 QoS 增强
背景
目前,Kubernetes 中 pod 的 OOM 优先级主要受其 QoS 级别与其对内存的申请量、使用量影响。然而,当前混部场景下,kubelet 原生的 oom_score_adj 计算策略已经不能很好的满足需求,例如:
需要给两个都映射到原生的 Burstable 级别的 shared_cores pods 设定 OOM 优先级
需要在两个原生都是 Guaranteed 级别的 dedicated_cores pod 和 shared_cores pod 之间设定 shared_cores pod 要早于 dedicated_cores pod OOM
此外,当前 kubelet 中提供的静态 oom_score_adj 计算机制,不支持 OOM 优先级的动态调整。因此 Katalyst 提供了一个关于 OOM 优先级的 QoS Enhancement,支持更加灵活地为 pods 设置 OOM 优先级。
技术解读
Katalyst 通过在内核添加 ebpf 的方式实现用户自定义的 OOM 策略注入,并在上层 qrm memory plugin 中完成用户定义策略的解析以及 OOM Priority 的配置下发。
使用
OOM Priority 信息通过 annotaion 在 pod 上进行指定

priorityValueInt 的取值越大表示优先级越高,并且取值范围受 pod 所指定的 QoS level 影响。
支持拓扑感知调度
背景
在搜索、广告、推荐、游戏、AI 分布式训练等业务场景下,用户对时延的敏感性较高,对容器在微拓扑级别的摆放方式存在要求。原生 K8s 的微拓扑管理能力存在一些局限,调度器不感知微拓扑,可能导致出现较多的因不满足 NUMA 亲和要求而造成的 Admit 失败。
因此,Katalyst 在 v0.4.0 实现了拓扑感知调度功能,支持两种模式:
Native 策略:兼容 K8s 原生的 NUMA 亲和和绑核策略
Dynamic 策略:混部场景下增强的绑核策略,对于 dedicated_cores QoS 级别,支持了 NUMA 亲和 (numa_binding) 以及 NUMA 独占 (numa_exclusive) 两种语义
其他
SysAdvisor 框架支持对接自定义业务模型,调优 rama provision policy 计算结果
QRM 支持设置整机和容器级别 TCP Memory 上限,缓解 TCP 内存满导致的丢包问题
Eviction 集成 RootFS 驱逐能力,定制排序策略和 QoS 级别驱逐阈值
KCMAS 优化存储数据结构和索引,支持多 tag 能力
ServiceProfilingDescriper (SPD) 支持服务维度的混部 baseline 和 per-pod 灰度能力
社区开发切换到基于 owner review 模式
基于超时实现死锁检测功能
新版本体验路径
请参考社区官方文档体验 Katalyst 潮汐混部和资源超分能力:
潮汐混部:gokatalyst.io/docs/user-guide/tidal-colocation/
资源超分:gokatalyst.io/docs/user-guide/resource-overcommitment/
感谢贡献者
在本次新版本的发布过程中,社区也迎来了不少新的贡献者,在此向他们的付出表示由衷感谢:
非常期待更多开发者和用户加入到 Katalyst 开源社区中,和我们一起交流和探讨在离线混部以及资源效能的相关话题。
如需火山引擎商务交流:

如需开源交流,添加字节跳动云原生小助手,加入云原生社群:

文章专题推荐:《字节跳动云原生创新实践与开源之路》




