
本文系火山引擎多云多活技术拆解系列文章的第三篇,将基于火山引擎的技术实践和客户服务经验,介绍如何在多云环境中实现高效、精准的流量调度,保障业务持续稳定。
来源 | 火山引擎云原生
云服务集中化风险正在成为大多数企业的共识。许多企业和机构现在面临这样的处境:一旦单个云服务商出现故障,将导致业务发生严重中断。——Gartner
容灾架构从最早期的单活形态(同城主备)发展到同城多活形态,再演化到异地多活,故障恢复的 RTO 不断缩短,服务可用性也在不断提升。随着容灾能力的提升,伴随的是更复杂的技术架构、更高的业务改造成本和更高昂的资源成本。
同城不同云厂商机房间的网络延时较短,数据库、缓存和消息等在数据容灾方面容易实现得多,所以建设同城多云多活架构是企业提升业务韧性最有效、最经济也是最务实的手段。而企业常见的业务系统架构包括接入层、应用层(计算层)和数据层,为了实现同城多云多活,我们需要在每一层都端到端地实现相应能力:
接入层:负责接收与处理外部请求,并将请求分发给相应的应用层进行处理。接入层是机房的流量入口,为实现多云多活,接入层应具备多云统一流量路由能力,以便在单云故障发生时,通过接入层切换入口流量;
应用层:负责具体的业务逻辑及功能实现,对数据进行计算和处理,提供给用户界面或其他系统调用。在多云多活架构下,应用部署架构由单云变为多云部署,多云服务发现、多云流量路由、多云故障隔离成为应用层在多云多活架构下需要解决的主要问题;
数据层:负责数据的存储和管理,通常通过数据库或其他数据存储技术来实现。在同城多活架构下,因网络条件较好,为避免数据不一致等问题,数据层通常采用单写多读的策略,为避免单云故障影响业务正常运行,数据层需提供多云数据单向同步、主备切换(回切)等能力。
本文是火山引擎多云多活技术拆解系列文章的第三篇(第一篇 | 第二篇),详细梳理了在不同服务发现架构下(如 Kubernetes service、注册中心如 Nacos 等),如何借助 API 网关、微服务流量治理等来实现应用流量的分级容灾和多云调度,从而使接入层和应用层具备多活能力。
多云流量调度场景
业务多云容灾场景按影响范围可以被分为单云故障、单云业务 Kubernetes 集群故障、单云服务级故障,不同级别故障的遭遇频次、恢复难度和流量调度方案也有所区别:
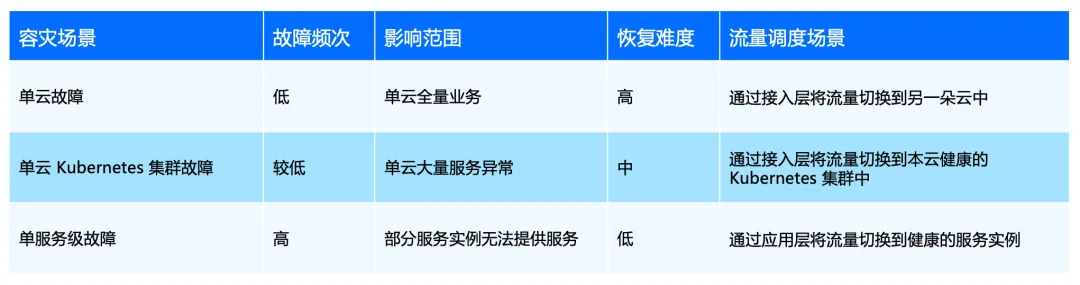
其中单云和 Kubernetes 集群级别的故障影响范围较大,需要能够在接入层快速完成从一朵云/一个 Kubernetes 集群到另一朵云/另一个 Kubernetes 集群的流量切换,因此通常需要人工介入切换流程,开展切换后效果的验证并执行流量回切。
单服务级故障受服务发布变更、代码缺陷、依赖的第三方服务/组件影响,故障出现频次较高,需要在应用层提供自动化故障检测和故障转移方案,避免依赖过多人工干预,以提高故障切换效率。
结合上述场景,企业在多云流量调度方案上需要纲目并举,根据接入层和应用层的容灾切换,提供多层次的流量调度能力。下面我们将基于火山引擎云原生团队的技术实践,分享在多云接入层和应用层的流量调度方案。
多云多活流量调度方案
在火山引擎的多云流量调度实践中,我们分别在接入层和应用层对服务发现、故障转移、限流降级等方面的能力做了增强,提供了一系列从字节跳动内部实践孵化而来的、能够与云原生/SpringCloud 等开源生态兼容的产品,如云原生 API 网关 APIG、微服务引擎 MSE ,以应对流量多活带来的挑战。
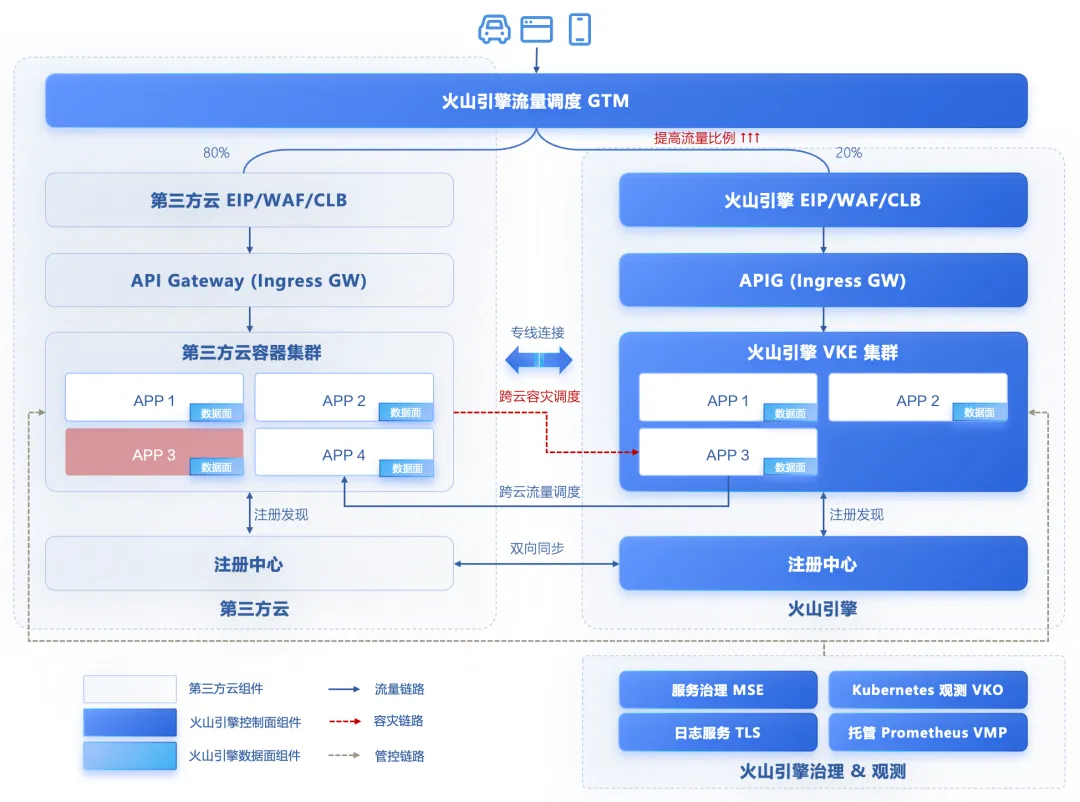
多云接入层流量调度
传统的多云接入层容灾切换会选择基于全局 DNS 切换不同入口的方案,但是 DNS 切换只能提供单云级别的故障切换能力,如果希望覆盖各个层次故障的场景,接入层需要进一步提供以下容灾能力:
出现单 Kubernetes 集群故障时,通过接入层将全部流量切换到对端集群;
出现单服务故障时,通过接入层将访问故障服务的流量切换到对端集群的健康服务中;
单 Kubernetes 集群故障和单服务故障切换能够实时生效。
而为了实现上述容灾能力,接入层组件需要具备如下关键特性:
多集群服务发现:为了提供集群级别故障切换的能力,接入层应掌握多集群全局的服务发现信息,即某个云上接入层组件不仅需要当前云后端服务地址,还需要能够感知其他云上的后端服务地址,需要接入层能够从多个 Kubernetes 集群获取 pod 地址。针对这个场景,火山引擎云原生 API 网关 APIG 支持导入多个 Kubernetes 集群,导入后会自动合并多个集群的相同 svc 的 pod IP。
同区域优先路由:接入层在日常状态下应将请求就近转发到和接入层网关同云同可用区的后端实例,主要原因是应用在不同云之间的部署比例会有差异,例如企业偏好在 A 云上部署生产集群,在 B 云上部署灾备集群,此时就不能将生产云环境的流量转发到灾备云环境上。在资源对等部署的场景下,为了降低跨云调用的延时,也应保证在本云内闭环调用。
故障自动转移:当任何一个集群或服务出现异常时,接入层应通过自动发现故障并将请求转移到健康的集群或服务当中,降低流量损失。针对这个场景,APIG 支持主动健康检查和熔断能力,可自动探测后端实例的健康状态、驱逐不健康的实例。
灵活路由策略:多云场景下接入层还应具备灵活的路由能力,例如指定的业务或请求访问特定的云上服务、将压测的流量导入到某个云上部署的压测环境中。接入层网关需要对比请求流量的特性,如压测 Header,判断是否应转发到本云的后端服务中,如果不匹配则将流量路由到相应云上的接入层网关,实现流量纠偏。
配置热更新:在出现单 Kubernetes 集群和单服务故障时,我们通常希望切换能够实时生效,而传统 Nginx 网关需要重新 reload 后配置才会生效,存在实时性问题。APIG 能够实时更新配置,不需要 reload 配置。
多云应用层流量调度
在流量进入应用层后,从多云容灾角度我们主要关注某个云上出现单服务的部分副本故障,如某个集群的副本因发布失败导致不可用时,能够进行自动化的故障转移,并在故障恢复后自动回切。
同时在业务多云部署的过程中,由于数据一致性、资源负载成本、业务迁移改造节奏等原因,部分业务只能单云集中化部署。对于这些单云部署的应用,还需要提供跨云服务调用能力,保证在各个云上能够访问到单云部署的服务。
为了实现上述流量调度能力,服务层组件通常需要具备如下关键能力:
多云服务注册信息打通:在业务多云部署后,首先确保应用在多云部署后能够互联互通,此时就需要能够打通多云间的服务发现:
多云注册中心双向同步:为了保证注册中心组件可靠性和数据一致性,一般会在单云本地部署注册中心。为了将多个云上的注册中心数据打通,业界一般会有注册中心同步和客户端多注册两类方案,其中多注册方案一般需要服务提供者首先进行多注册,然后才能被消费者调用,存在对接入顺序的要求,所以对于已经存在大规模存量业务的场景,我们更推荐使用注册中心双向同步方案——火山引擎微服务引擎 MSE 能通过独立的注册中心同步组件实现注册中心多云双向同步,保证单个云厂商的注册中心包含全量的服务发现信息;
多 Kubernetes 集群 svc 合并:由于 Kubernetes service 默认只能在本集群中进行服务发现,无法实现跨集群访问。为了实现多集群服务发现,就需要能够将多个 Kubernetes 集群相同 ns 下相同 service 合并为相同服务,保证通过服务名就可以访问到。针对这种情况,我们可以通过在 MSE 中统一 watch 多个 Kubernetes 集群 svc endpoint 变化,合并后下发到 pod 中,最终在进行服务发现时能够通过服务名获取到多个集群合并后的 pod 地址 ,达到统一 Kubernetes service 服务注册发现的效果。
跨云服务调用:对于单云部署的应用,为了保证在当前云上没有部署下游服务时,应用能够自动访问到对端云上部署的服务,我们就需要应用层能提供跨云服务调用能力。基于多云服务注册信息打通,我们可以全量获取到所有云上的 pod 地址,这时会遇到两种情形:在服务都使用 Underlay 网络的情况下,我们可以直接访问服务注册的 pod 地址进行跨云调用;在不能通过 Underlay 网络互相访问的情况下,MSE 会提供跨集群东西向网关,可以在识别到需要进行跨云调用时自动将请求转发到跨集群网关。
同可用区优先路由:除了部分单云部署的应用,在多云多活的场景中,大部分应用会在多云同时部署,此时就需要优先调用本云的下游服务。MSE 在进行服务路由时,消费方实例会将订阅的实例按地域进行分组并调整分配权重,优先将流量导至相同可用区的服务实例,通过配置微服务间的优先路由,大幅节省跨云的流量成本,同时改善服务调用延时。
自动 failover:在出现服务级别故障时,根据健康检测和熔断策略自动发现故障,将请求调用到健康实例,并在故障恢复后自动回切。MSE 能够在服务调用相同云厂商下游实例出现部分不可用的情况时,自动切换一定比例的流量至对端云厂商相同服务实例。同时在一定时间后自动探测故障是否恢复,恢复后将按比例逐步将流量切回原云厂商的服务实例。
限流兜底保护:如前文所述,在出现单云或单集群故障的场景下,接入层会将全部流量导入到对端,对于应用层而言,这意味需要处理远多于日常态的流量。为了避免在流量突增导致原本健康的实例过载,引发连锁故障,需要在工作负载级别引入限流能力,将超出限流阈值的流量丢弃,防止系统负载持续升高导致系统崩溃或无法响应。
无侵入接入:应用层和接入层最大的差异是流量调度能力需要尽可能接入所有业务系统才能达到预期效果。对于这个场景,社区的传统方案是引入额外的 SDK 并开发相应的代码逻辑,在业务侧推广阻力大,同时也面临升级维护困难的问题。MSE 治理中心支持无侵入 Java Agent 和 Sidecar 接入方式,用户仅需在 Deployment 引入 MSE 注解即可完成实例接入,无需代码改造,能极大降低业务迁移改造成本。
结语
通过引入上述方案,企业可以更好地应对流量多活,从而保障业务的稳定性。同时,火山引擎的多云容灾流量调度方案也能进一步帮助企业在对现有架构影响尽可能小的前提下,将业务平滑升级到多活架构:
多层次精准容灾流量调度,降低容灾切换成本。结合全局服务发现能力,火山引擎云原生 API 网关和微服务引擎能够实现集群和服务级故障容灾能力,提供自动/手动灵活容灾策略配置,将流量容灾调度控制到单云服务级范围,屏蔽容灾切换过程的业务感知,有效降低容灾切换成本;
业务无侵入流量治理增强,降低改造成本。提供异构语言(Java/Go/Python 等)、异构框架(SpringCloud/Dubbo/Kitex 等)应用通过 Java Agent/Sidecar 等方式无侵入接入,业务无需改造代码即可实现流量调度能力增强,极大降低业务改造成本,有效推动中大型企业的多云容灾架构落地进程;
提供灵活的限流降级策略,保障运行时业务稳定。借助火山引擎微服务引擎 MSE、云原生 API 网关丰富熔断限流策略,有效避免突发流量洪峰导致业务雪崩。
火山引擎云原生团队聚焦应用多云容灾架构专题联合云上多款 PaaS 产品构建多云资源分发、智能 DNS 切换、跨云流量调度、多云容灾观测、双向数据同步的一站式解决方案,致力于帮助客户构建多云应用发布、数据层同城高可用、中间件同城高可用、容灾平台构建、应用单元化改造最佳实践,在满足资源弹性伸缩的同时保障业务连续稳定。
相关链接
[1] 火山引擎: www.volcengine.com
[2] APIG:www.volcengine.com/product/apig
[3] MSE:www.volcengine.com/product/mse




