
本文最初发布于 Medium 网站,经原作者授权由 InfoQ 中文站翻译并分享。
决策树是一个经久不衰的话题。本文要做的是将一系列决策树组合成一个单一的预测模型;也就是说,我们将创建集成方法(Ensemble Methods)的模型。
决策树是准确度最高的预测模型之一。想象一下同时使用多棵树能把预测能力提高到多高的水平!
一些集成方法算法的预测能力超过了当今机器学习领域的一流高级深度学习模型。此外,Kaggle 参赛者广泛使用集成方法来应对数据科学挑战。
集成方法以相对较低的复杂性提供了更高水平的准确度。决策树模型和决策树组构建、理解和解释起来都很容易。我们将在另一篇文章中谈论宏伟的随机森林,因为它除了作为机器学习的模型外,还广泛用于执行变量选择!我们可以为机器学习模型的预测变量(predictor)选择最佳的候选变量。
Jupyter 笔记本
请查看Jupyter笔记本,了解我们接下来要介绍的构建机器学习模型的概念,也可以参阅我在Medium中写的其他数据科学文章和教程。
我们在本文中要做的是用 Python 构建一个决策树。实践中会有两棵树:一棵树基于熵,另一棵树基于基尼系数。
安装包
第一步是安装 pydot 和 Graphviz 包来查看决策树。如果没有这些包,我们就只有模型了——我们想更进一步,分别考虑用熵和基尼系数计算值的决策树。
命令!表示它将在操作系统上运行。它是一种快捷方式,所以我们不必离开 Jupyter 并打开终端。
!pip install --upgrade pydotRequirement already satisfied: pip in c:\users\anell\appdata\local\programs\python\python38\lib\site-packages (21.1.3)!pip install --upgrade graphvizRequirement already satisfied: graphviz in c:\users\anell\appdata\local\programs\python\python38\lib\site-packages (0.16)如果我们在 Windows 上安装 Graphviz 时遇到问题,可以在终端上运行!conda install python-Graphviz 命令。
#!pip install graphviz# You may need to run this command (CMD) for windows#!conda install python-graphviz# Documentation http://www.graphviz.orgGraphviz 是一个图形可视化包。计算图是一种具有节点和边的结构;也就是说,实际的决策树是一个计算图。
导入很多包
我们需要 Pandas 来创建 Datarame 格式的结构。我们将使用 DecisionTreeClassifier,即在 Scikit Learn 的树包中实现的决策树算法。另外,我们需要 export_graphviz 函数将决策树导出为 Graphviz 格式,然后使用 Graphviz 来可视化这个导出。
如果我们想看到这棵树,到这里它还没准备好!我们需要创建模型,以图格式导出模型,并使用 Graphviz 才能看到它。
# Importing packagesimport pandas as pdfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.tree import export_graphvizimport pydotimport graphviz创建数据集
接下来我们创建一个数据集,它实际上是一个字典列表。
# Creating a datasetinstances = [{'Best Friend': False, 'Species': 'Dog'},{'Best Friend': True, 'Species': 'Dog'},{'Best Friend': True, 'Species': 'Cat'},{'Best Friend': True, 'Species': 'Cat'},{'Best Friend': False, 'Species': 'Cat'},{'Best Friend': True, 'Species': 'Cat'},{'Best Friend': True, 'Species': 'Cat'},{'Best Friend': False, 'Species': 'Dog'},{'Best Friend': True, 'Species': 'Cat'},{'Best Friend': False, 'Species': 'Dog'},{'Best Friend': False, 'Species': 'Dog'},{'Best Friend': False, 'Species': 'Cat'},{'Best Friend': True, 'Species': 'Cat'},{'Best Friend': True, 'Species': 'Dog'}]转换为数据帧
我们来转换这些数据,将其格式化为 DataFrame。
# Turning the Dictionary into DataFramedf = pd.DataFrame(instances)df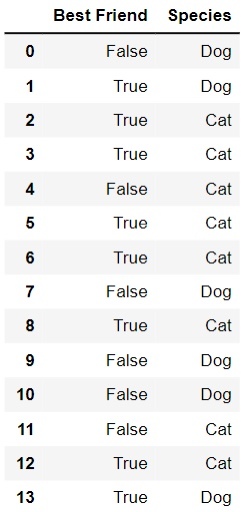
这样我们就有了一个 DataFrame,用它可以判断某个物种是否适合成为人类最好的朋友。一会儿我们将通过决策树进行分类。
拆分数据
接下来我们划分训练数据和测试数据。本例中我们使用 List Comprehension,根据括号内的条件将数据转换为 0 或 1:
# Preparing training and test dataX_train = [[1] if a else [0] for a in df['Best Friend']]y_train = [1 if d == 'Dog' else 0 for d in df['Species']]labels = ['Best Friend']print(X_train)[[0], [1], [1], [1], [0], [1], [1], [0], [1], [0], [0], [0], [1], [1]]print(y_train)[1, 1, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1]我们将输入数据和输出值转换为 0 或 1 的表示——机器学习算法处理数字是最擅长的。
这样,我们将值转换成了 X 输入值和目标 y 目标值,因为我们在一个循环结构中构造了变量 X。接下来,我们遍历 Best Friend 列的每个元素来表示输入变量,并将其放入变量 a 和变量 d 中。
我们使用代码将值转换为文本,并转换为数字表示以呈现给机器学习模型。
构建机器学习模型并非易事。它涉及不同领域的一系列知识,以及构成这一切基础的数学和统计学背景。此外,它还需要计算机编程知识和对我们正在研究的语言包、业务问题的知识、数据的预处理的理解。
也就是说,构建机器学习模型的过程涉及多个领域。到目前为止,我们已经准备好了数据,虽然我们还没有准备好测试数据来制作熵和基尼系数的模型。
我们不会在这里评估模型,所以不需要测试数据。因此,我们获取所有数据并将它们作为 X 和 y 的训练数据。
必须记住,如果我们评估模型,就需要测试数据。由于我们这里不会进行评估,因此我们只会使用训练数据,也就是整个数据集。
构建树模型
在这个阶段,我们已经构建了模型,其中第一阶段定义了 model_v1 对象,然后使用 model_v1.fit()训练模型。
model_v1 = DecisionTreeClassifier(max_depth = None,max_features = None,criterion = 'entropy',min_samples_leaf = 1,min_samples_split = 2)Python 是面向对象的编程。DecisionTreeClassifier 函数实际上是一个类,它创建该类的一个实例——一个对象。当我们调用 DecisionTreeClassifier 类时,它将依赖几个参数来定义要在 sklearn 文档中查询的算法行为。
我们在这里使用熵作为标准。至于我们未能指定的参数,算法都认为是默认的。

那么这个对象就会有方法和属性,fit()是应用于 model_v1 对象进行模型训练的方法:
# Presenting the data to the Classifiermodel_v1.fit(X_train, y_train)DecisionTreeClassifier(criterion='entropy')
创建变量
在这里,我们定义了一个名为 tree_model_v1 的变量,它位于我们现在所在的目录中。
# Setting the file name with the decision treefile = '/Doc/MachineLearning/Python/DecisionTree/tree_model_v1.dot'定义文件变量后,我们将调用从 model_v1 计算图中提取的 export_graphviz,即决策树。我们打开整个文件,并记录计算图的所有元素:
# Generating the decision tree graphexport_graphviz(model_v1, out_file = file, feature_names = labels)with open(file) as f:dot_graph = f.read()graphviz.Source(dot_graph)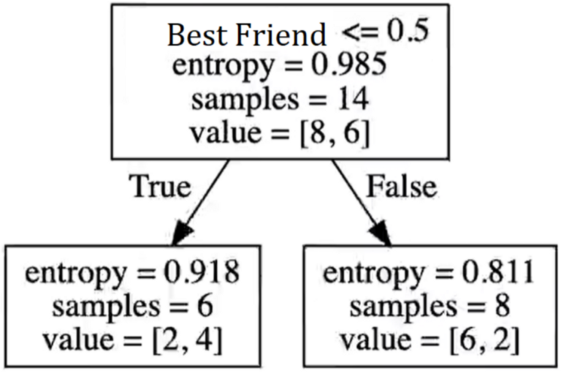
将点文件转换为 png
在上面,我们有了计算图格式的树。如果你想以 png 格式写入此树:
!dot -Tpng tree_model_v1.dot -o tree_model_v1.png演绎
层次结构的顶部是 Best Friend。在本例中我们只有一个变量。请注意,该算法计算的熵为 0.985,并且仍会计算其他集群的熵。
[8,6]的第一组和 14 个样本通过熵呈现出最高的信息增益。基于此,我们有了一个位于熵计算层次结构顶部的节点。
该算法遍历了所有数据示例,进行了熵计算,并找到了最佳组合——具有最高熵的属性到达顶部并创建了我们的决策树级别。
第二版模型
另一种方法是使用另一个标准代替基于熵的决策树创建相同的模型,我们将使用基尼系数。
要只使用基尼系数构建相同的树,就是要更改标准,删除标准参数:
model_v2 = DecisionTreeClassifier(max_depth = None,max_features = None,min_samples_leaf = 1,min_samples_split = 2)当我们移除标准参数时,算法会考虑应用基尼系数。我们有一个有趣的参数叫做 max_depth。在其中我们可以定义树的最大深度。在我们的例子里它没有意义,因为我们只有一个变量;但如果我们有几十个输入变量,max_depth 会很有用。
当我们有很多输入变量时,树的深度会很大,这会带来过拟合的问题。因此我们在构建模型时要定义树的深度。
由于我们有很多参数,找到构建算法的最佳参数组合是一项复杂的任务!在以自动化方式测试多个参数组合时,我们可以使用需要大量计算资源的交叉验证。
我们还有 min_samples_leaf 表示决策树的最低级别:叶节点所需的最小样本数,就是说它会考虑用多少次观察来构建决策树的最低节点。
最后,参数 min_samples_split 是拆分一个内部节点所需的最小样本数。在决策树中,我们有作为顶部的根节点、作为树基部的顶部节点,和中间节点。这样我们就可以简单地调整这些参数来定义如何构建所有节点。
训练基尼版本
# Presenting the data to the Classifiermodel_v2.fit(X_train, y_train)我们再次生成文件参数:
# Setting the file name with the decision treefile ='/User/Documents/MachineLearning/DecisionTree_tree_model_v1.dot''我们提取了模型的计算图:
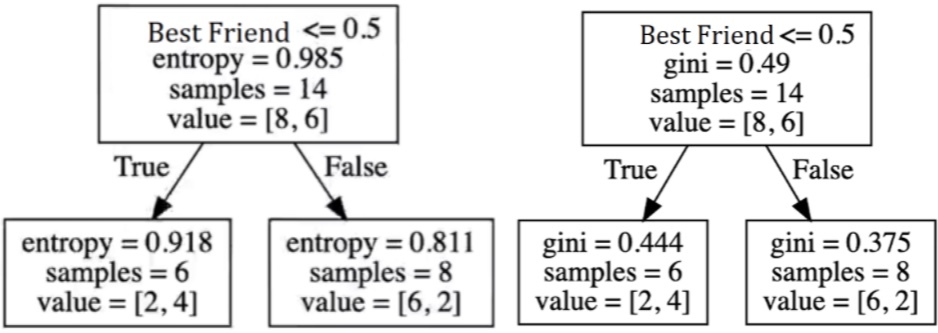
本文中我们用同样的方式创建了两颗树。我们分别使用了熵和基尼系数来计算。两棵树的区别在于用于定义节点组织的标准。它们没有高下之分,都可以很有趣,具体则取决于上下文、数据和业务问题。
我们建议创建同一模型的多个版本并评估最佳性能。
!dot -Tpng tree_model_v2.dot -o tree_model_v2.png最后,我们保存了决策树的出口。我希望这篇文章对你有所帮助。感谢你的阅读。
原文链接:
https://levelup.gitconnected.com/how-to-build-a-decision-tree-model-in-python-75f6f3af159d




