
“Kylin 的引入给我们带来了切实的好处, 现在整个报表分析的数据准备时间,从过去的 8 小时减少到 2 小时。”
——王颖卓, 中国银联数据服务团队负责人,Kylin 用户
金融机构在 BI 分析中遇到了哪些挑战?
首先简单介绍一下我们公司数据仓库的背景,2008 年公司开始建数据仓库,2009 年上线。这个数据仓库运转到现在已经有 10 个年头,采用的是比较传统标准的架构,数据仓库主体用的是 IBM DB2。
在 BI 这块我们引入了 Cognos 作为总的 BI 工具,当时,整个金融界都比较流行 Cognos。在这 10 年内,包括 Cognos 等一些其他商业版的多维分析工具,确实给企业分析带来了很大的便利。 时过境迁 , 现在到了大数据年代,数据量越来越大, Cognos 面临了一些挑战, 我们数据量的增长, 10 年间涨了 10 倍;在最近两三年,我们的业务量又更加迅猛地增长,这对数据分析的挑战是巨大的。

Cognos 从整个功能、架构上来讲, 都是基于单机版的,效率很低;因此我们在 Cognos 的基础上研发了一些工具,包括调度、Cube 刷新,Cube 访问等等,这其中申请的专利就有好几个。这些工具核心还是基于单机的运转,所以说在构建上它的扩展性不好,一个体现是,刷 Cube 的时间越来越长。
例如一些每日刷新的 Cube,业务分析用户需要基于这些日 Cube 要出当日报表, 但是鉴于现在的数据量和处理能力,很难在他们预期的时间内达到要求,我们技术团队的压力很大,做了很多工作,想了各种各样的办法在调优,但是收效仍然低于预期。
以上是我们用 Cognos 碰到的一些挑战,正是因为这个原因,我们在 2015 年在一个技术分享活动上,我们和 Apache Kylin 第一次触电。
Apache Kylin 的性能和价值
在下图可以看到,Kylin 各方面的性能和 Cognos 相比有了大幅的提高,这些数据都是实际中的一些例子。从使用资源来讲,大数据平台的资源还是比较富裕的,Kylin 整个架构比较强调读写分离,目前我们在 Kylin 上投了 20 多台机器进行 Cube 的构建和查询。
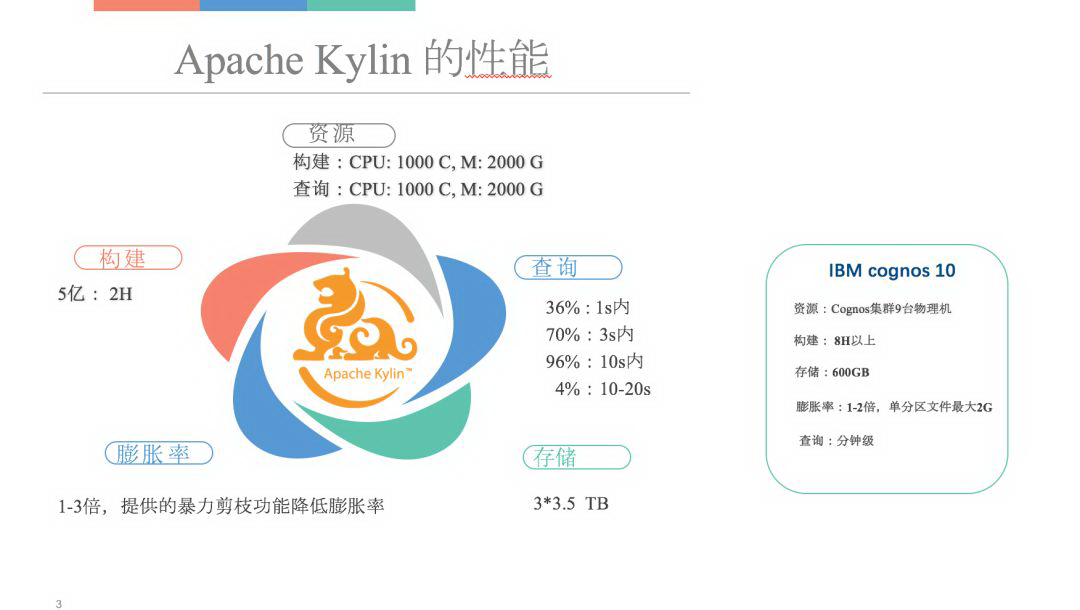
首先看一下查询,96%的查询在 10 秒之内返回;除非是非常大、复杂的条件可能要到 20 秒左右。 而以前我们的 Cognos 从打开到展示,拖拉拽建立一个基本的报表要接近一分钟,Kylin 对用户的体验和感受的提升是非常巨大的。
从整个构建性能上来讲, Kylin 相比于 Cognos 也有巨大的提升 。因为 Cognos 是单机,没有办法利用分布式集群资源,必须是一个比较独立的 Cognos 在跑,每天跑 8 个小时以上。Kylin 的构建是在整个大数据平台之上,跟其他的批量计算共享集群资源,这个时候基本上是两个小时左右,就可以把整个 Cube 构建出来。
膨胀率是一个关键点,在测试环境上,效果不是很好,有 10 倍以上的膨胀。当时我有点犹豫,问题出在什么地方?后来跟 Kylin 团队有一个深入的交流,发现是模拟的测试数据的特征和实际特征有出入。他们建议我们用较为真实的数据在测试一下,得到的结果表现要好一些,膨胀率大概是 3 倍。而且 3 倍还是因为后面会讲的高基维的引入引发了这点。
从膨胀率上来讲,有几点可以跟大家分享,一个是在测试环境做测试的时候,当时是因为模拟的一些数据的分布情况跟实际不是完全一致,引发了大量的膨胀率。另外一个 Kylin 的模型上确实是有一定的讲究,通过一些模型优化,我们确实有效地把 Kylin 的膨胀率控制在 3 倍以内。
从整体上来讲,通过对 Kylin 这个产品的引入,对我们带来的好处是非常多的。
现在整个的报表,以前 8 小时 Cube 现在 2 小时就可以出来,给我们的小伙伴的指标是每天早上 9 点钟之前,要把昨天所有的数据做完,用户能够访问到,这个指标现在基本上完全能够达到。
从访问来讲,基本上 96%在 10 秒之内,完全出乎用户的意料,用户进来谈笑之间数据就可以出来。
一些高基维的引入,进一步降低了我们开发压力、维护压力。
企业如何落地 Kylin
作为一个传统企业,引入 Apache Kylin 这样的开源软件,该怎么样引入? 这个是从我个人的角度给大家做一个分享,不一定完全对, 大家可以一起思考和讨论。 对于金融机构来说,去引入开源软件,追求的其实就是核心的四个字:自主可控。 其次有三个方面的因素需要考虑。
用户体验
引入 Kylin 非常大的一点原因,我们可以把整个 Cognos 分析报表架在 Apache Kylin 上, 用户仍旧可在 Cognos 上进行拖拉拽,后台使用 Kylin 进行查询,用户习惯得到了 100%原汁原味的保留 。我们服务的是用户,所以用户的体验、感受是非常关键的。
社区支持
原来用 IBM Cognos 的售后服务非常好,问题提出后,他们响应会非常快,邮件的方式或者是回访,他们会收集一堆的生产上的情况,一堆的报表。但是,问题还是没发完全解决。传统的商业产品,往往会面临这样的情况:态度非常好,但碰到一些具体问题快速解决的效率不高,另一方面用户间相互交流的途径较少,相互启发式的最优实践经验分享不够。
一个非常 Open 的开源软件,其实对于我们这样传统的金融机构来说,可谓是一个美好的毒药 。虽然都是开源的,社区也非常活跃,但是如果没有足够的开发人员、技术人员在里面的话,玩不转的。像现在大数据的社区非常活跃,多少企业在这个社区里有很好的主导权呢?从这个角度来讲,Kylin 这个社区对我们的帮助很大。这个社区很开放,同时 Kyligence 公司在这个社区里也起着一个很重要的主导权。我们提出的问题,社区里的朋友会跟我们做交流,Kyligence 公司也会以一个主要的代码贡献者的身份,提出很好的建议和意见 。
组件化
Kylin 越来越庞大,它可以是一个完整的产品,可以把它拿回来作为一个 BI 去用。我们在选 Kylin 的时候,更多的是看重它的组件化的特质。如果熟悉 Kylin 的应该知道,它既是一个产品也是一个计算组件,也有可以是一个存储组件。
我们没有把 Kylin 当成一个完整的产品,而是把它当做一个组件 。过去我们讲“Intel inside”,在构建我们自己的 BI 产品的时候,我有时候也说,"Kylin inside",我们看一下,什么叫做"Kylin inside"。
企业内部的大数据围绕着给用户服务,做 BI,和数据提取的体系架构。这一圈基本上是自营的一些组件、安全、任务执行、资源控制,任务监控、访问控制;底层是非常熟悉的一系列的大数据套件包括 MapReduce、Spark、Impala、HBase,包括 EDW,所以整个外围的一圈给包在一起,作为一个统一的解决方案提供给用户,用户可以通过各种方式去访问数据、使用数据做自己的分析。
所以说 Kylin inside,包括我们自营的 Tornado 数据加工服务,中间的 Kylin 作为一个比较核心的组件,是数据分析的支撑;同时还包括 Lightning 实时数据服务产品。
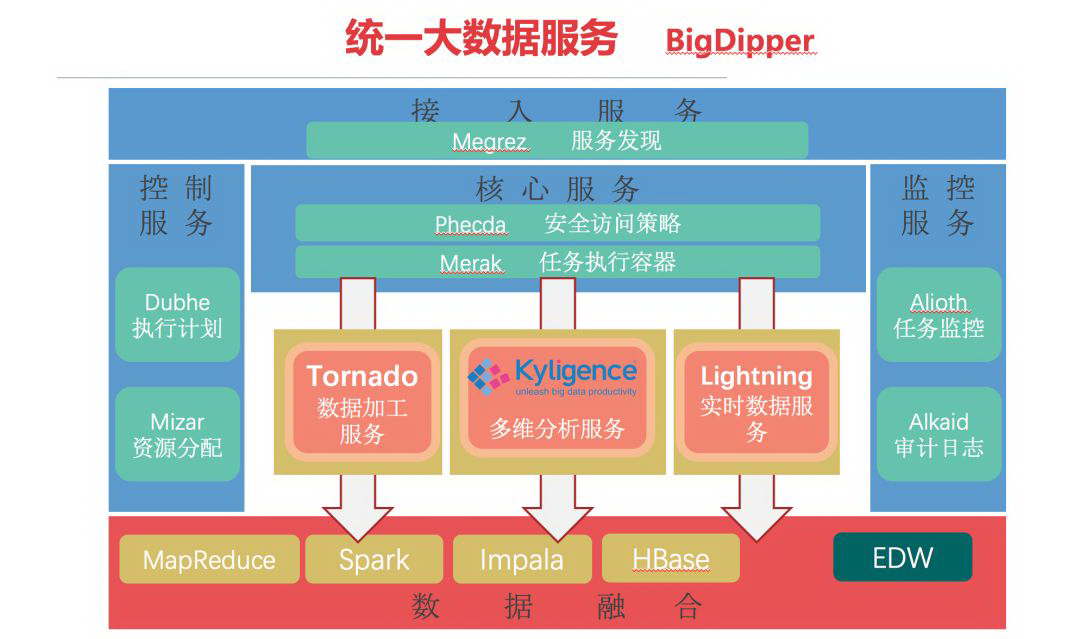
从这个角度来讲,我们并不是说简单的把 Kylin 当一个产品引入而是作为一个组件的形式赋能到我们产品上。
企业基于 Kylin 定制化 BI 开发
前面介绍一下为什么从 Cognos 移到 Kylin 上来,在这个过程中,我们重点考量的是哪些点。接下来,我会向大家介绍,针对 Kylin 的外围,我们做了哪些事情。
我们基于 Kylin 商业版本 Kyligence Enterprise 做了一些二次开发,我们选择企业版更看重的是商业服务。围绕着 Kylin,我们做了两方面的事情。最开始做数据时,基本上是以 Cognos 的方式在跑报表、数据。用户反馈,Cognos 太难了, 表结构不合理 。因此我们推出了多维分析,通过拖拉拽方式就能做。拖拉拽几年,用户就又开始抱怨了,天天拖拉拽,开发效率太低。我们有熟悉 Cognos 的人员,有做数据分析的人员,我们遇到的新问题是, 能不能开放一些 Cognos 的接口给分析人员去使用?基于这样的情况,我们两个都做。
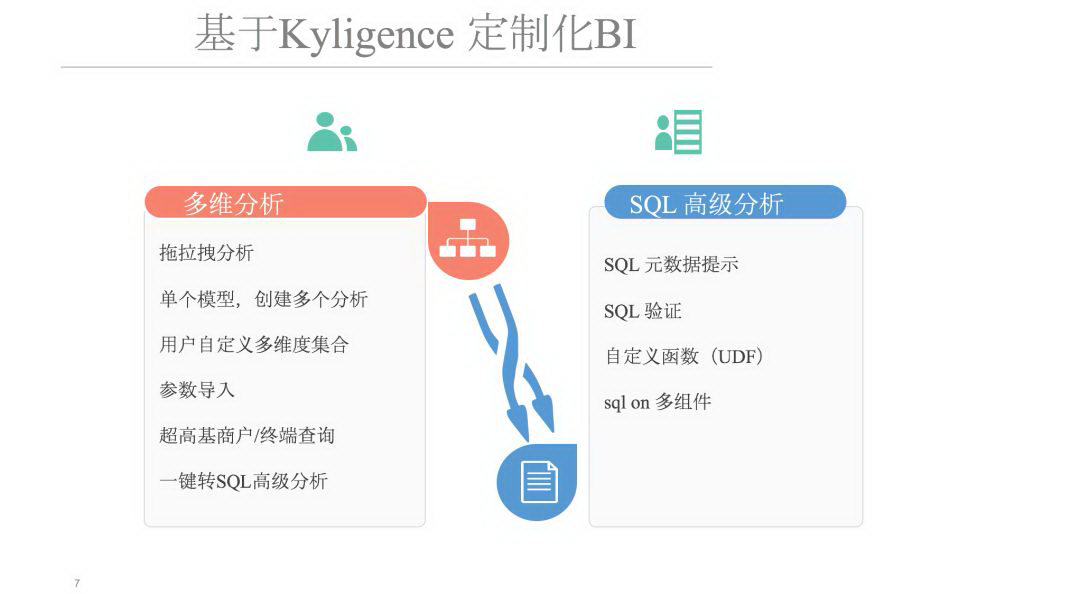
在多维分析之上,我们开发了一些工具,第一个简单的拖拉拽, 这个是仿照 Cognos 做的。后面有单个模型去创建多个分析。如果对这边有了解的话,用它做报表的话,Report 打开来,需要同时打开多个 Report,里面去搭载多个模型,按照现在的性能,一个模型下载下来,至少要半分钟,有的甚至是 1 分钟,所以说这个时候,无论对机器的影响,还是电脑本身,相当于电脑开多个浏览窗口,对电脑的压力都还是有的。所以说做了一个事情,单个模型,创建多个分析,包括用户自定义维度、参数和 SQL 之间的转换,在这边都做了一些开发 。
用户往往会说:我会写 SQL,但是不懂你们的模型。对这种情况,我们做了一个类似于 SDK 的工具,提示元数据,把表名、字段名弹出来,用户写 SQL,然后验证 SQL 等;怎样的 SQL 才能跑,是有自己的一些逻辑在里面的,包括自定义一些 UDF,有些时候直接把 UDF 传下去,可能传到 Kylin 里面,也有可能传到 Spark SQL 里面。有种情况也是,通过原生接口或者是 SQL 接口,或者是其他接口,把数据取过来在内存里,做二次处理加工,最终再给用户展现。像我们这个 SQL,不仅基于 Kylin,也会基于 Spark SQL 或者是 Impala 去执行。
怎么能让我们的多维分析相对比较平缓?或者说怎么让那些比较熟悉,或者是更加接受报表的用户,能够接受拖拉拽的这种形式?
我们会在上面加自定义集,去自定义很多业务的场景,比如,对于我们来讲,从业务上来说,定义公司不同的业务线, 从数据层面来讲,是有多个维度,甚至是维度里面不同位置的组合,去来代表这些业务场景和业务含义。那么这个时候如果从报表上来看,就是反应了公司不同业务条线的各类数据报表。
今天和大家分享了我们为什么开始使用 Kylin,Kylin 带给我们的价值,以及围绕着 Kylin 我们做了哪些开发集成工作,希望对大家有所帮助;社区里有面临相同问题、挑战的伙伴也可以跟我们进一步交流 。
Q&A
Q: 在使用 Kylin,不管是企业版还是商业版的过程中,有朋友碰到报表经常变换的情况,比如说已经构建好的 Cube,结果却发现指标需要变化,或者是维度需要增加,这个时候你们是怎么处理的?
A: 如果说真要变化,整个模型要重构,这个是没办法的。第一,基于多年 Cognos 的积累,我们整个模型相对成熟 。第二,Kylin 本身的能力值得认可,我们尽可能的会把更多的一些数据、维度放在模型里,例如把所有商户代码全构建进去,几百万、上千万的商户数据放在一起,怎么查、改,都逃脱不了这个范围,所以后面做了自定义数据集等 。所以有了 kylin 以后, 我们对这些业务需求就更加有信心, 能够帮助业务人员解决,尽可能的把我们能想象到的场景放进去,只要 Kylin 能承担得了性能上的压力,我们都尽量做在里面去,通过二次自定义的方式,去满足用户自定义的场景。
Q: 总共有多少数据量交给 Kylin 处理了?
A: 现在我们一天所有的交易有好几亿,我们还有季度的、年度的,所有的东西都会用 Kylin 去做。我们用 Kylin 去支撑几年的明细交易查询,总的数据量有几千亿了。 怎么样用 Kylin 支撑几千亿级的数据查询,我们现在是用 Hive 跑,几百万个出来跑 40 多个小时,整个集群全部被吃满,所以现在这也是我们面临的挑战,我们也在和 Kyligence 公司讨论,千亿级的数据怎么样通过 Kylin 的方式去做,我们计划在半个小时看看能不能跑出来,他们跟我们说很轻松,目前还在测试之中。
Q: 前面展示的报表工具是自研的吗?
A: 我们有一个 5 人团队,基于 Kylin 然后设计出来这么一个报表工具。
Q: Kylin 做的工作主要是对 Hive 查询的优化工作?
A: Kylin 是先把 Hive 元数据库拉入构建成底层的存储引擎,还有自己存储的格式。跟 Cognos 的机制比较像,元数据本身是放在数据库里面,或者是放在 Hive 里面,去访问数据库,然后把数据生成物理上的 Cube 文件,对 Cognos 来讲,是一些二级文件,对于 Kylin 来讲,两种都支持,开源社区版的话是基于 HBase,把数据塞在 HBase 里面。但是整个数据结构,跟你自己原始的数据结构是不一样的,是 Kylin 数据接口。但是那个膨胀率你看一下,确实有点高,看你的数据量是否能接受这个膨胀率。
Q: 膨胀率具体指的是什么?
A: 比如说你现在有 100 个 G 的数据,这个是元数据,一条一条原始数据。但是多维分析是很多个维度的交叉和组合。那么每一个维度都有可能作为你的访问,这个时候,理论上从数据模型上来讲,为了提高性能,要把每一种组合都计算出来,而且存下来。这个时候面临的组合的量,就不是几百亿或者是怎么样,那么它的存储相对来讲肯定比原始要大,但是大多少?开源社区用 HBase 去做的,商业版的话,有自己的存储引擎,而且还有一个增强的剪枝的功能,去判断哪些交叉维度是有效,哪些没有效,所以说在这上面做了一个处理。其实说白了,我觉得能量守恒,目的还是空间和时间,只是空间、时间能节约多少的问题。
Q: 如果使用 Tableau 软件,Kylin 是作为 Tableau 的一种数据源吗?
A: 对,可以让 Tableau 把 SQL 发给 Kylin,Kylin 做数据计算,结果给到 Tableau。
演讲完整视频
本文转载自公众号 apachekylin(ID:ApacheKylin)。
原文链接:




